 力扣刷题
力扣刷题
# 算法
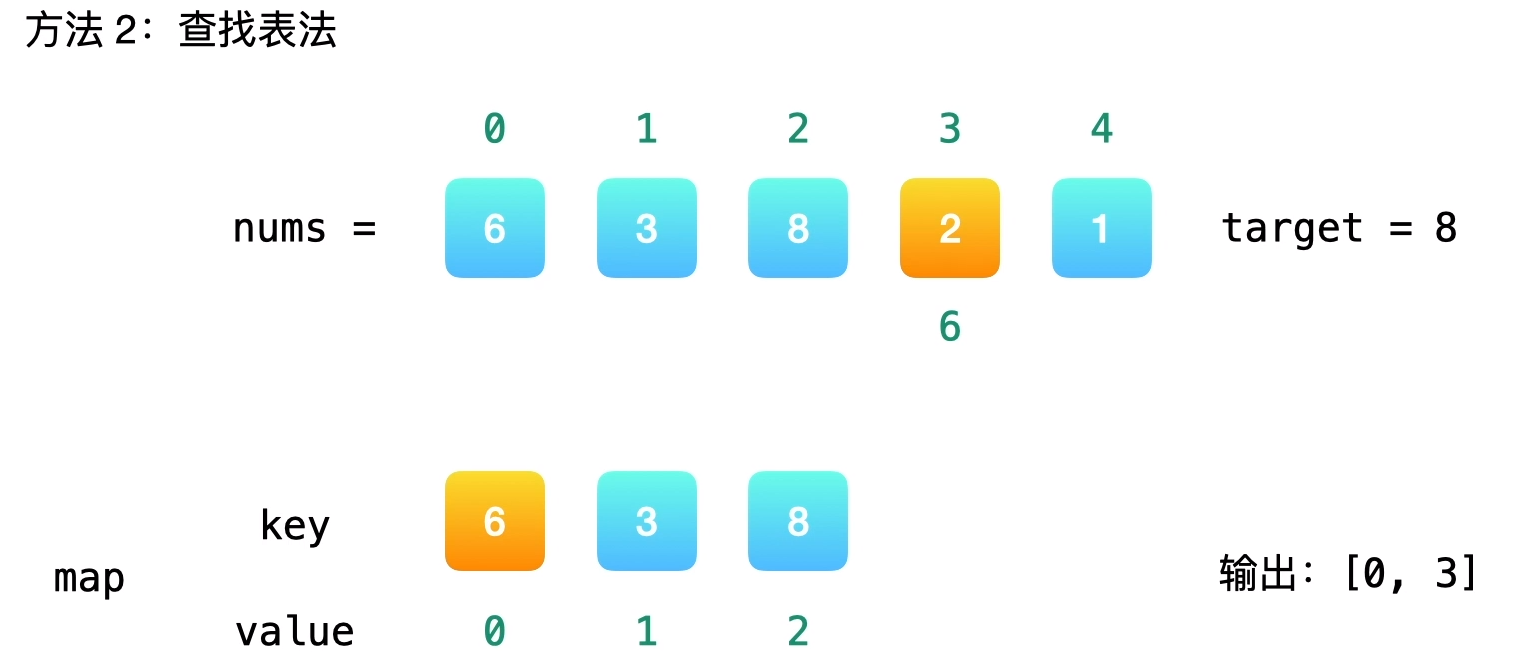
# 1. 两数之和 (opens new window)
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
2
3
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
2
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
2
提示:
2 <= nums.length <= 104-109 <= nums[i] <= 109-109 <= target <= 109- 只会存在一个有效答案
**进阶:**你可以想出一个时间复杂度小于 O(n2) 的算法吗?
/**
* 暴力破解法
* @param nums
* @param target
* @return
*/
public int[] twoSum1(int[] nums, int target) {
int len = nums.length;
for (int i = 0; i < len - 1; i++) {
for (int j = i+1; j < len; j++) {
if (nums[i] + nums[j] == target) {
return new int[]{i,j};
}
}
}
throw new IllegalArgumentException("No two sum solution");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public int[] twoSum(int[] nums, int target) {
int len = nums.length;
HashMap<Integer,Integer> hashMap = new HashMap<>(len-1);
hashMap.put(nums[0],0);
for (int i = 1; i < len; i++) {
if (hashMap.containsKey(target - nums[i])) {
return new int[]{ hashMap.get(target - nums[i]), i};
}
hashMap.put(nums[i], i);
}
throw new IllegalArgumentException("No two sum solution");
}
2
3
4
5
6
7
8
9
10
11
12
# 9.回文数
给你一个整数 x ,如果 x 是一个回文整数,返回 true ;否则,返回 false 。
回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
- 例如,
121是回文,而123不是。
示例 1:
输入:x = 121
输出:true
2
示例 2:
输入:x = -121
输出:false
解释:从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。
2
3
示例 3:
输入:x = 10
输出:false
解释:从右向左读, 为 01 。因此它不是一个回文数。
2
3
提示:
-231 <= x <= 231 - 1
static boolean isPalindrome(int x) {
String regStr = String.valueOf(x);
StringBuffer reverse = new StringBuffer(regStr).reverse();
if (regStr.equals(reverse.toString())) {
return true;
} else {
return false;
}
}
2
3
4
5
6
7
8
9
方法二:
static boolean isPalindrome1(int x) {
// 负数和10的整数倍不会是回文数
if(x < 0 || (x % 10 == 0 && x != 0)) {
return false;
}
int revertedNumber = 0;
while (x > revertedNumber) {
revertedNumber = revertedNumber * 10 + x % 10;
x /= 10;
}
// 针对奇位数和偶位数的数字,分别判断是否为回文
return x == revertedNumber || x == revertedNumber / 10;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 13.罗马数字转整数
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
2
3
4
5
6
7
8
例如, 罗马数字 2 写做 II ,即为两个并列的 1 。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。
示例 1:
输入: s = "III"
输出: 3
2
示例 2:
输入: s = "IV"
输出: 4
2
示例 3:
输入: s = "IX"
输出: 9
2
示例 4:
输入: s = "LVIII"
输出: 58
解释: L = 50, V= 5, III = 3.
2
3
示例 5:
输入: s = "MCMXCIV"
输出: 1994
解释: M = 1000, CM = 900, XC = 90, IV = 4.
2
3
提示:
1 <= s.length <= 15s仅含字符('I', 'V', 'X', 'L', 'C', 'D', 'M')- 题目数据保证
s是一个有效的罗马数字,且表示整数在范围[1, 3999]内 - 题目所给测试用例皆符合罗马数字书写规则,不会出现跨位等情况。
- IL 和 IM 这样的例子并不符合题目要求,49 应该写作 XLIX,999 应该写作 CMXCIX 。
- 关于罗马数字的详尽书写规则,可以参考 罗马数字 - Mathematics (opens new window)。
static int romanToInt(String s) {
int length = s.length();
int[] nums = new int[length];
int num = 0;
for (int i = 0; i < length; i++) {
switch(s.charAt(i)) {
case 'M': num = 1000; break;
case 'D': num = 500; break;
case 'C': num = 100; break;
case 'L': num = 50; break;
case 'X': num = 10; break;
case 'V': num = 5; break;
case 'I': num = 1; break;
}
nums[i] = num;
}
// 若较小的数字在较大的数字前面就加负号
int rtn = 0;
for (int i = 0; i < nums.length; i++) {
if(i < nums.length -1 && nums[i] < nums[i+1]) {
nums[i] = - nums[i];
}
rtn += nums[i];
}
return rtn;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
解法2:
public int romanToInt2(String s) {
s = s.replace("IV","a");
s = s.replace("IX","b");
s = s.replace("XL","c");
s = s.replace("XC","d");
s = s.replace("CD","e");
s = s.replace("CM","f");
int res = 0;
for (int i = 0; i < s.length(); i++) {
res += getValue(s.charAt(i));
}
return res;
}
public int getValue(char c) {
switch(c) {
case 'I': return 1;
case 'V': return 5;
case 'X': return 10;
case 'L': return 50;
case 'C': return 100;
case 'D': return 500;
case 'M': return 1000;
case 'a': return 4;
case 'b': return 9;
case 'c': return 40;
case 'd': return 90;
case 'e': return 400;
case 'f': return 900;
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 14.最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入:strs = ["flower","flow","flight"]
输出:"fl"
2
示例 2:
输入:strs = ["dog","racecar","car"]
输出:""
解释:输入不存在公共前缀。
2
3
提示:
1 <= strs.length <= 2000 <= strs[i].length <= 200strs[i]仅由小写英文字母组成
解法一:
static String longestCommonPrefix(String[] strs) {
int k = 0;
//公共前缀比所有字符串都短,随便选一个先
String s = strs[0];
for (String string: strs) {
while(!string.startsWith(s)) {
if (s.length() == 0) return "";
// 公共前缀不匹配就让它变短
s=s.substring(0,s.length()-1);
}
}
return s;
}
2
3
4
5
6
7
8
9
10
11
12
13
解法二:
// 方法二,横向扫描
// 思路分析:第一个和第二个相比求出最长前缀,然后整个最长前缀再和后面的字符串相比得到新的最长前缀
static String longestCommonPrefix2(String[] strs) {
// 如果是空字符字符串数字直接返回空
if (strs.length==0 || strs == null) return "";
// 第一个字符串设为默认前缀
String prefix = strs[0];
int count = strs.length;
for (int i = 1; i < count; i++) {
prefix = lcp(prefix, strs[i]);
if(prefix.length() == 0) {
break;
}
}
return prefix;
}
static String lcp(String str1,String str2) {
int length = str1.length() > str2.length() ? str2.length() : str1.length();
int index = 0;
while (index < length && (str1.charAt(index) == str2.charAt(index))) {
index++;
}
return str1.substring(0,index);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
解法三:
// 方法三,纵向扫描
static String longestCommonPrefix3(String[] strs) {
if (strs.length == 0 ) return "";
int length = strs[0].length();
int count = strs.length;;
for (int i = 0; i < length; i++) {
char c = strs[0].charAt(i);
for (int j = 1; j < count; j++) {
if (i == strs[j].length() || strs[j].charAt(i) != c) {
return strs[0].substring(0,i);
}
}
}
return strs[0];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
解法四:
// 方法四 分治法
static String longestCommonPrefix4(String[] strs) {
if( strs == null || strs.length == 0) {
return "";
} else {
return longestCommonPrefix(strs,0,strs.length-1);
}
}
static String longestCommonPrefix(String[] strs, int start,int end) {
if(start == end) {
return strs[start];
} else {
int mid = (end - start) / 2 + start;
String lcpLeft = longestCommonPrefix(strs,start,mid);
String lcpRight = longestCommonPrefix(strs,mid+1,end);
return lcp(lcpLeft,lcpRight);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
解法五:
// 方法五 二分查找
static String longestCommonPrefix5(String[] strs) {
if(strs == null || strs.length == 0) {
return "";
}
int minLength = Integer.MAX_VALUE;
// 求出最小的字符长度(公共前缀的长度肯定小于等于这个长度)
for (String str: strs) {
minLength = Math.min(minLength, str.length());
}
int low = 0, high = minLength;
while( low < high) {
int mid = (high - low +1) / 2;
if(isCommonPrefix(strs, mid)) {
low = mid;
} else {
high = mid - 1;
}
}
return strs[0].substring(0, low);
}
private static boolean isCommonPrefix(String[] strs, int length) {
String str0 = strs[0].substring(0, length);
int count = strs.length;
for (int i = 1; i < count; i++) {
String str = strs[i];
for (int j = 0; j < length; j++) {
if (str0.charAt(j) != str.charAt(j)) {
return false;
}
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 20.有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
示例 1:
输入:s = "()"
输出:true
2
示例 2:
输入:s = "()[]{}"
输出:true
2
示例 3:
输入:s = "(]"
输出:false
2
提示:
1 <= s.length <= 104s仅由括号'()[]{}'组成
public static boolean isValid(String s) {
int length = s.length();
if (length == 0) {
return true;
}
Stack<Character> stack = new Stack<>();
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (c == '(' || c == '[' || c == '{') {
stack.push(c);
}else {
if(stack.size() > 0) {
if (c == ')' && stack.lastElement() == '(') {
stack.pop();
}else if (c == '}' && stack.lastElement() == '{') {
stack.pop();
}else if (c == ']' && stack.lastElement() == '[') {
stack.pop();
} else {
// 没有匹配就入栈
stack.push(c);
}
} else {
stack.push(c);
}
}
}
if (stack.size() == 0) {
return true;
} else {
return false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
官方答案:
public boolean isValid2(String s) {
int n = s.length();
if( n%2 == 1) {
return false;
}
HashMap<Character, Character> map = new HashMap<Character, Character>(){
{
put(')', '(');
put(']', '[');
put('}', '{');
}
};
LinkedList<Character> statck = new LinkedList<>();
for (int i = 0; i < n; i++) {
char ch = s.charAt(i);
if (map.containsKey(ch)) {
// 如果是右括号
if (statck.isEmpty() || statck.peek() != map.get(ch)) {
return false;
}
statck.pop();
}else {
// 左括号直接入栈
statck.push(ch);
}
}
return statck.isEmpty();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 21.合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:

输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
2
示例 2:
输入:l1 = [], l2 = []
输出:[]
2
示例 3:
输入:l1 = [], l2 = [0]
输出:[0]
2
提示:
- 两个链表的节点数目范围是
[0, 50] -100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
解法1:
public class ListNode {
int val;
ListNode next;
ListNode() {}
ListNode(int val) { this.val = val; }
ListNode(int val, ListNode next) { this.val = val; this.next = next; }
}
// 方法一: 递归
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
if (list1 == null) {
return list2;
}else if (list2 == null) {
return list1;
} else if (list1.val < list2.val) {
list1.next = mergeTwoLists(list1.next, list2);
return list1;
} else {
list2.next = mergeTwoLists(list1, list2.next);
return list2;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
解法二:
// 方法二: 暴力破解
public ListNode mergeTwoLists2(ListNode list1, ListNode list2) {
ListNode prehead = new ListNode(-1);
ListNode prev = prehead;
while(list1 != null && list2 != null) {
if(list1.val <= list2.val) {
prev.next = list1;
list1 = list1.next;
} else {
prev.next = list2;
list2 = list2.next;
}
prev = prev.next;
}
// 合并后 l1 和 l2 最多只有一个还未被合并完,我们直接将链表末尾指向未合并完的链表即可
prev.next = list1 == null ? list2 : list1;
return prehead.next;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 26.删除有序数组中的重复项
给你一个 升序排列 的数组 nums ,请你** 原地 (opens new window)** 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。
由于在某些语言中不能改变数组的长度,所以必须将结果放在数组nums的第一部分。更规范地说,如果在删除重复项之后有 k 个元素,那么 nums 的前 k 个元素应该保存最终结果。
将最终结果插入 nums 的前 k 个位置后返回 k 。
不要使用额外的空间,你必须在 原地 (opens new window)修改输入数组 并在使用 O(1) 额外空间的条件下完成。
判题标准:
系统会用下面的代码来测试你的题解:
int[] nums = [...]; // 输入数组
int[] expectedNums = [...]; // 长度正确的期望答案
int k = removeDuplicates(nums); // 调用
assert k == expectedNums.length;
for (int i = 0; i < k; i++) {
assert nums[i] == expectedNums[i];
}
2
3
4
5
6
7
8
9
如果所有断言都通过,那么您的题解将被 通过。
示例 1:
输入:nums = [1,1,2]
输出:2, nums = [1,2,_]
解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
2
3
示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4]
输出:5, nums = [0,1,2,3,4]
解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。
2
3
public int removeDuplicates(int[] nums) {
int n = nums.length;
if( n == 0) {
return 0;
}
int fast = 1,slow = 1;
while(fast < n ){
// 后面的和前面的不相等
if (nums[fast] != nums[fast-1]) {
nums[slow] = nums[fast];
slow++;
}
fast++;
}
return slow;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 27.移除元素
给你一个数组 nums 和一个值 val,你需要 原地 (opens new window) 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 (opens new window)修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以**「引用」**方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝
int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
2
3
4
5
6
7
8
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
2
3
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,4,0,3]
解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
2
3
public static int removeElement(int[] nums, int val) {
int n = nums.length;
int left = 0;
for (int right = 0; right < n; right++) {
if (nums[right] != val){
nums[left] = nums[right];
left++;
}
}
return left;
}
2
3
4
5
6
7
8
9
10
11
// 方法一优化
public static int removeElement2(int[] nums, int val) {
int left = 0;
int right = nums.length;
while (left <right) {
if (nums[left] == val) {
nums[left] = nums[right - 1];
right--;
} else {
left++;
}
}
return left;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 35.搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
示例 1:
输入: nums = [1,3,5,6], target = 5
输出: 2
2
示例 2:
输入: nums = [1,3,5,6], target = 2
输出: 1
2
示例 3:
输入: nums = [1,3,5,6], target = 7
输出: 4
2
public int searchInsert(int[] nums, int target) {
// 二分查找
int left = 0, right = nums.length - 1 ;
while (left <= right){
int mid = left + ((right - left) >> 1);
if (target <= nums[mid]) {
right = mid - 1;
} else {
left = mid + 1;
}
}
return left;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 58.最后一个单词的长度
给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。
单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。
示例 1:
输入:s = "Hello World"
输出:5
解释:最后一个单词是“World”,长度为5。
2
3
示例 2:
输入:s = " fly me to the moon "
输出:4
解释:最后一个单词是“moon”,长度为4。
2
3
示例 3:
输入:s = "luffy is still joyboy"
输出:6
解释:最后一个单词是长度为6的“joyboy”。
2
3
提示:
1 <= s.length <= 104s仅有英文字母和空格' '组成s中至少存在一个单词
我的答案
public static int lengthOfLastWord(String s) {
// 去掉两边的空白
String nesString = s.trim();
int last = nesString.length();
for (int i = last-1; i >= 0; i--) {
if (nesString.charAt(i)==' '){
return last - i - 1;
}
}
return last;
}
2
3
4
5
6
7
8
9
10
11
官方答案:
public static int lengthOfLastWord1(String s) {
int index = s.length() - 1;
// 去掉最右边的空字符
while (s.charAt(index) == ' ') {
index --;
}
int wordLength = 0;
while (index >=0 && s.charAt(index) != ' '){
wordLength ++;
index--;
}
return wordLength;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 66.加一
给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
输入:digits = [1,2,3]
输出:[1,2,4]
解释:输入数组表示数字 123。
2
3
示例 2:
输入:digits = [4,3,2,1]
输出:[4,3,2,2]
解释:输入数组表示数字 4321。
2
3
示例 3:
输入:digits = [0]
输出:[1]
2
提示:
1 <= digits.length <= 1000 <= digits[i] <= 9
public static int[] plusOne(int[] digits) {
int n = digits.length;
for (int i = n - 1; i >= 0; --i) {
// 找到最左边的非9
if (digits[i] != 9) {
++digits[i];
// 最后一位不是9,这个不会执行
for (int j = i + 1; j < n; ++j) {
digits[j] = 0;
}
return digits;
}
}
// digits 中所有的元素均为 9
int[] ans = new int[n + 1];
ans[0] = 1;
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 67.二进制求和
给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。
示例 1:
输入:a = "11", b = "1"
输出:"100"
2
示例 2:
输入:a = "1010", b = "1011"
输出:"10101"
2
提示:
1 <= a.length, b.length <= 104a和b仅由字符'0'或'1'组成- 字符串如果不是
"0",就不含前导零
public static String addBinary(String a, String b) {
StringBuffer ans = new StringBuffer();
int aLength = a.length();
int bLength = b.length();
int n = Math.max(aLength, bLength), carry = 0;
for (int i = 0; i< n; i++) {
if (i < aLength) {
carry += a.charAt(a.length() - i - 1) - '0';
}
if (i < bLength) {
carry += b.charAt(b.length()- i - 1) - '0';
}
ans.append((char)(carry % 2 + '0'));
carry /= 2;
}
if (carry > 0) ans.append('1');
return ans.reverse().toString();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 69.x 的平方根
给你一个非负整数 x ,计算并返回 x 的 算术平方根 。
由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。
**注意:**不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。
示例 1:
输入:x = 4
输出:2
2
示例 2:
输入:x = 8
输出:2
解释:8 的算术平方根是 2.82842..., 由于返回类型是整数,小数部分将被舍去。
2
3
解法1:
// 袖珍计算器算法
public static int mySqrt(int x) {
if (x == 0 ){
return 0;
}
int ans = (int)Math.exp(0.5*Math.log(x));
return (long)(ans +1) * (ans + 1) <= x ? ans + 1 : ans;
}
2
3
4
5
6
7
8
解法2:
// 方法二: 二分查找
public static int mySqrt1(int x) {
int left = 0, right = x, ans = -1;
while (left <= right) {
int mid = left +((right - left) >> 1);
if ((long) mid * mid <= x) {
ans = mid;
left = mid + 1;
} else {
right = mid - 1;
}
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 70.爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
示例 1:
输入:n = 2
输出:2
解释:有两种方法可以爬到楼顶。
1. 1 阶 + 1 阶
2. 2 阶
2
3
4
5
示例 2:
输入:n = 3
输出:3
解释:有三种方法可以爬到楼顶。
1. 1 阶 + 1 阶 + 1 阶
2. 1 阶 + 2 阶
3. 2 阶 + 1 阶
2
3
4
5
6
解法1:递归会超出时间限制。(可以利用数组存储下,每次计算的值,防止重复计算)
public static int climbStairs(int n) {
if(n == 1) {
return 1;
} else if (n == 2 ){
return 2;
}else {
// n-1代表最后一步是一步,n-2代表最后一步是两步
return climbStairs(n-1) + climbStairs(n-2);
}
}
2
3
4
5
6
7
8
9
10
解法2:
public static int climbStairs2(int n) {
int p = 0, q = 0, r = 1;
for (int i = 1; i <= n; i++) {
p = q;
q = r;
r = p + q;
}
return r;
}
2
3
4
5
6
7
8
9
# 83.删除排序链表中的重复元素
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:
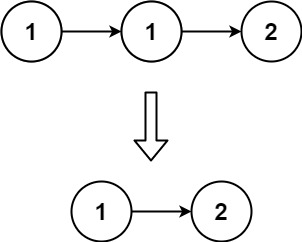
输入:head = [1,1,2]
输出:[1,2]
2
示例 2:

输入:head = [1,1,2,3,3]
输出:[1,2,3]
2
public ListNode deleteDuplicates(ListNode head) {
if (head == null) {
return head;
}
ListNode cur = head;
while (cur.next != null) {
if (cur.val == cur.next.val) {
cur.next = cur.next.next;
} else {
cur = cur.next;
}
}
return head;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 88.合并两个有序数组
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
**注意:**最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
输出:[1,2,2,3,5,6]
解释:需要合并 [1,2,3] 和 [2,5,6] 。
合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。
2
3
4
示例 2:
输入:nums1 = [1], m = 1, nums2 = [], n = 0
输出:[1]
解释:需要合并 [1] 和 [] 。
合并结果是 [1] 。
2
3
4
示例 3:
输入:nums1 = [0], m = 0, nums2 = [1], n = 1
输出:[1]
解释:需要合并的数组是 [] 和 [1] 。
合并结果是 [1] 。
注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。
2
3
4
5
自己写的,借助辅助空间
// 借助辅助空间 时间复杂度o(m+n) 空间复杂度o(n)
public static void merge(int[] nums1, int m, int[] nums2, int n) {
int[] arr = new int[m+n];
int i = 0, j = 0, k = 0;
while (i< m && j < n) {
if (nums1[i]<= nums2[j]) {
arr[k++] = nums1[i++];
} else {
arr[k++] = nums2[j++];
}
}
while (i < m) {
arr[k++] = nums1[i++];
}
while (j < n) {
arr[k++] = nums2[j++];
}
System.arraycopy(arr,0,nums1,0,k);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// 答案方法1 时间复杂度0(log(m+n))
public static void merge1(int[] nums1, int m, int[] nums2, int n) {
for (int i = 0; i != n; i++) {
nums1[m + i] = nums2[i];
}
Arrays.sort(nums1);
}
2
3
4
5
6
7
// 答案方法2 双指针法 时间复杂度 o(m+n) 空间复杂度 o(m+n)
public static void merge2(int[] nums1, int m, int[] nums2, int n) {
int p1 = 0, p2 = 0;
int[] sorted = new int[m+n];
int cur;
while (p1 < m || p2 < n) {
if (p1 == m) {
cur = nums2[p2++];
} else if (p2 == n) {
cur = nums1[p1++];
} else if (nums1[p1] < nums2[p2]) {
cur = nums1[p1++];
} else {
cur = nums2[p2++];
}
sorted[p1+p2-1] = cur;
}
for (int i = 0; i != m + n ; i++) {
nums1[i] = sorted[i];
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 方法3 逆向双指针 时间复杂度 o(m+n) 空间复杂度 o(1)
public static void merge3(int[] nums1, int m, int[] nums2, int n) {
int p1 = m - 1, p2 = n - 1;
int tail = m + n - 1;
int cur;
while(p1 >= 0 || p2 >= 0) {
if (p1 == -1) {
cur = nums2[p2--];
} else if (p2 == -1) {
cur = nums1[p1--];
} else if (nums1[p1] > nums2[p2]) {
cur = nums1[p1--];
} else {
cur = nums2[p2--];
}
nums1[tail--] = cur;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 94.二叉树的中序遍历
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:

输入:root = [1,null,2,3]
输出:[1,3,2]
2
示例 2:
输入:root = []
输出:[]
2
示例 3:
输入:root = [1]
输出:[1]
2
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
// 方法1: 递归
public List<Integer> inorderTraversal(TreeNode root) {
ArrayList<Integer> list = new ArrayList<>();
inorder(root,list);
return list;
}
public void inorder(TreeNode root, List<Integer> list) {
if (root == null) {
return;
}
inorder(root.left,list);
list.add(root.val);
inorder(root.right,list);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
// 方式2:迭代
public List<Integer> inorderTraversal2(TreeNode root) {
ArrayList<Integer> list = new ArrayList<>();
// Deque是一个双端队列
// Deque<TreeNode> stk = new LinkedList<>();
// 也可以换成栈
Stack<TreeNode> stk = new Stack<>();
while (root != null || !stk.isEmpty()) {
// 左子树全部入栈
while (root != null) {
stk.push(root);
root = root.left;
}
root = stk.pop();
list.add(root.val);
// 最左下结点的右子树
root = root.right;
}
return list;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 101.对称二叉树
给你一个二叉树的根节点 root , 检查它是否轴对称。
示例 1:

输入:root = [1,2,2,3,4,4,3]
输出:true
2
示例 2:
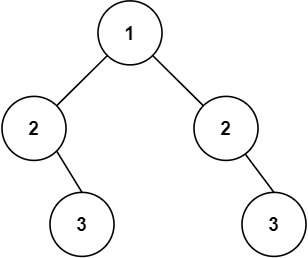
输入:root = [1,2,2,null,3,null,3]
输出:false
2
public boolean isSymmetric(TreeNode root) {
return check(root,root);
}
public boolean check(TreeNode p, TreeNode q) {
if(p == null && q == null) {
return true;
} else if( p == null || q== null) {
return false;
} else {
return p.val == q.val && check(p.left,q.right) && check(p.right,q.left);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
迭代
public boolean isSymmetric1(TreeNode root) {
return check1(root,root);
}
public boolean check1(TreeNode p,TreeNode q) {
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(p);
queue.offer(q);
while (!queue.isEmpty()) {
p = queue.poll();
q = queue.poll();
if (p == null && q == null) {
continue;
}
if ((p == null || q == null) || (p.val != q.val)) {
return false;
}
queue.offer(p.left);
queue.offer(q.right);
queue.offer(p.right);
queue.offer(q.left);
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 104.二叉树的最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
2
3
4
5
返回它的最大深度 3 。
// 递归
public int maxDepth(TreeNode root) {
if (root == null) {
return 0;
} else {
int leftHeight = maxDepth(root.left);
int rightHeight = maxDepth(root.right);
return Math.max(leftHeight,rightHeight) + 1;
}
}
2
3
4
5
6
7
8
9
10
// 迭代
public int maxDepth2(TreeNode root) {
if (root == null){
return 0;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
int ans = 0;
while (!queue.isEmpty()) {
int size = queue.size();
while (size > 0) {
TreeNode p = queue.poll();
if (p.left != null) {
queue.offer(p.left);
}
if (p.right != null) {
queue.offer(p.right);
}
size--;
}
ans++;
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 108.将有序数组转换为二叉搜索树
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
示例 1:

输入:nums = [-10,-3,0,5,9]
输出:[0,-3,9,-10,null,5]
解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案:
2
3
示例 2:

输入:nums = [1,3]
输出:[3,1]
解释:[1,null,3] 和 [3,1] 都是高度平衡二叉搜索树。
2
3
提示:
1 <= nums.length <= 104-104 <= nums[i] <= 104nums按 严格递增 顺序排列
public TreeNode sortedArrayToBST(int[] nums) {
return helper(nums, 0, nums.length - 1);
}
public TreeNode helper(int[] nums, int left, int right) {
if (left > right) {
return null;
}
// 总是选择中间位置左边的数字作为根节点
int mid = (left + right) / 2;
TreeNode root = new TreeNode(nums[mid]);
root.left = helper(nums, left, mid - 1);
root.right = helper(nums, mid+1,right);
return root;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 110.平衡二叉树
给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为:
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:true
2
示例 2:

输入:root = [1,2,2,3,3,null,null,4,4]
输出:false
2
示例 3:
输入:root = []
输出:true
2
提示:
- 树中的节点数在范围
[0, 5000]内 -104 <= Node.val <= 104
// 这种会重复计算height
public boolean isBalanced(TreeNode root) {
if (root == null) {
return true;
} else {
return Math.abs(height(root.left) - height(root.right)) <= 1 && isBalanced(root.left) && isBalanced(root.right);
}
}
public int height(TreeNode root) {
if (root == null) {
return 0;
}else {
return 1 + Math.max(height(root.left),height(root.right));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public boolean isBalanced1(TreeNode root) {
return balanced(root) >= 0;
}
public int balanced(TreeNode root) {
if (root == null) {
return 0;
}
int leftHeight = balanced(root.left);
int rightHeight = balanced(root.right);
if (leftHeight == -1 || rightHeight == -1 || Math.abs(leftHeight - rightHeight) > 1) {
return -1;
} else {
return Math.max(leftHeight, rightHeight) + 1;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 111.二叉树的最小深度
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
**说明:**叶子节点是指没有子节点的节点。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:2
2
示例 2:
输入:root = [2,null,3,null,4,null,5,null,6]
输出:5
2
提示:
- 树中节点数的范围在
[0, 105]内 -1000 <= Node.val <= 1000
自己写的解法:
// 迭代
public int minDepth(TreeNode root) {
if (root == null) {
return 0;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
int ans = 1;
while (!queue.isEmpty()) {
int size = queue.size();
// 一层一层遍历
while (size > 0) {
TreeNode p = queue.poll();
size--;
// 如果p是叶子结点,直接返回
if (p.left == null && p.right == null) {
return ans;
}
if (p.left != null) {
queue.offer(p.left);
}
if (p.right != null) {
queue.offer(p.right);
}
}
ans++;
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
官方解法1:
// 递归
public int minDepth1(TreeNode root) {
if (root == null) {
return 0;
}
if (root.left == null && root.right == null) {
return 1;
}
int min_depth = Integer.MAX_VALUE;
if (root.left != null) {
min_depth = Math.min(minDepth1(root.left), min_depth);
}
if (root.right != null) {
min_depth = Math.min(minDepth1(root.right), min_depth);
}
return min_depth + 1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
官方解法2:
class QueueNode {
TreeNode node;
int depth;
public QueueNode(TreeNode node, int depth) {
this.node = node;
this.depth = depth;
}
}
public int minDepth2(TreeNode root) {
if (root == null) {
return 0;
}
Queue<QueueNode> queue = new LinkedList<>();
queue.offer(new QueueNode(root,1));
while (!queue.isEmpty()) {
QueueNode nodeDepth = queue.poll();
TreeNode node = nodeDepth.node;
int depth = nodeDepth.depth;
if (node.left == null && node.right == null) {
return depth;
}
if (node.left != null) {
queue.offer(new QueueNode(node.left,depth+1));
}
if (node.right != null) {
queue.offer(new QueueNode(node.right,depth+1));
}
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 112.路径总和
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
叶子节点 是指没有子节点的节点。
示例 1:

输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true
解释:等于目标和的根节点到叶节点路径如上图所示。
2
3
示例 2:

输入:root = [1,2,3], targetSum = 5
输出:false
解释:树中存在两条根节点到叶子节点的路径:
(1 --> 2): 和为 3
(1 --> 3): 和为 4
不存在 sum = 5 的根节点到叶子节点的路径。
2
3
4
5
6
示例 3:
输入:root = [], targetSum = 0
输出:false
解释:由于树是空的,所以不存在根节点到叶子节点的路径。
2
3
public boolean hasPathSum(TreeNode root, int targetSum) {
if( root == null) {
return false;
}
LinkedList<TreeNode> queNode = new LinkedList<>();
LinkedList<Integer> queVal = new LinkedList<>();
queNode.offer(root);
queVal.offer(root.val);
while (!queNode.isEmpty()) {
TreeNode now = queNode.poll();
Integer temp = queVal.poll();
if (now.left == null && now.right == null) {
if (temp == targetSum) {
return true;
}
continue;
}
if (now.left != null) {
queNode.offer(now.left);
queVal.offer(now.left.val + temp);
}
if (now.right != null) {
queNode.offer(now.right);
queVal.offer(now.right.val + temp);
}
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
//方法二 递归
public boolean hasPathSum1(TreeNode root, int sum) {
if (root == null) {
return false;
}
if (root.left == null && root.right== null) {
return sum == root.val;
}
return hasPathSum1(root.left, sum - root.val) || hasPathSum1(root.right, sum- root.val);
}
2
3
4
5
6
7
8
9
10
# 118.杨辉三角
给定一个非负整数 *numRows,*生成「杨辉三角」的前 numRows 行。
在「杨辉三角」中,每个数是它左上方和右上方的数的和。

示例 1:
输入: numRows = 5
输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]
2
示例 2:
输入: numRows = 1
输出: [[1]]
2
public static List<List<Integer>> generate(int numRows) {
List<List<Integer>> lists = new ArrayList<>();
for (int i = 0; i < numRows; i++) {
ArrayList<Integer> list = new ArrayList<>();
for (int j = 0; j <= i; j++) {
if (j == 0 || j == i) {
list.add(1);
}else {
list.add(lists.get(i-1).get(j-1) + lists.get(i-1).get(j));
}
}
lists.add(list);
}
return lists;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 119.杨辉三角 II
给定一个非负索引 rowIndex,返回「杨辉三角」的第 rowIndex 行。
在「杨辉三角」中,每个数是它左上方和右上方的数的和。
示例 1:
输入: rowIndex = 3
输出: [1,3,3,1]
2
示例 2:
输入: rowIndex = 0
输出: [1]
2
示例 3:
输入: rowIndex = 1
输出: [1,1]
2
public static List<Integer> getRow(int rowIndex) {
ArrayList<Integer> list = new ArrayList<>();
Queue<Integer> queue = new LinkedList<>();
if (rowIndex == 0) {
list.add(1);
}else if (rowIndex == 1) {
list.add(1);
list.add(1);
} else {
queue.offer(1);
queue.offer(1);
for (int i = 2; i < rowIndex +1 ; i++) {
queue.offer(1);
for (int j = 0; j <= i-2; j++) {
int a = queue.poll();
int b = queue.peek();
queue.offer(a+b);
}
queue.poll();
queue.offer(1);
}
}
list.addAll(queue);
return list;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// 答案方法1
// 采取获取全部行杨辉三角的形式
// 优化1 设置一个列表来保存前一行数据
// 优化2
public static List<Integer> getRow2(int rowIndex) {
// List<List<Integer>> lists = new ArrayList<List<Integer>>();
ArrayList<Integer> pre = new ArrayList<>();
for (int i = 0; i <= rowIndex; i++) {
ArrayList<Integer> list = new ArrayList<>();
for (int j = 0; j <= i ; j++) {
if (j ==0 || j== i) {
list.add(1);
} else {
list.add(pre.get(j-1) +pre.get(j));
}
}
pre = list;
// lists.add(list);
}
// return lists.get(rowIndex);
return pre;
}
// 进一步优化,只用一个数组
public List<Integer> getRow3(int rowIndex) {
ArrayList<Integer> row = new ArrayList<>();
row.add(1);
for (int i = 1; i <=rowIndex ; i++) {
row.add(0);
for (int j = i; j > 0 ; j--) {
row.set(j, row.get(j) + row.get(j-1));
}
}
return row;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34

// 官方解法二
public List<Integer> getRow4(int rowIndex) {
ArrayList<Integer> row = new ArrayList<>();
row.add(1);
for (int i = 1; i < rowIndex; i++) {
row.add((int) ((long) row.get(i-1) * (rowIndex - i + 1) / i));
}
return row;
}
2
3
4
5
6
7
8
9
# 121.买卖股票的最佳时机
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
2
3
4
示例 2:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
2
3
public int maxProfit2(int prices[]) {
int minprice = Integer.MAX_VALUE;
int maxprofit = 0;
for (int i = 0; i < prices.length; i++) {
if (prices[i] < minprice) {
minprice = prices[i];
}else if (prices[i] - minprice > maxprofit) {
maxprofit = prices[i] - minprice;
}
}
return maxprofit;
}
2
3
4
5
6
7
8
9
10
11
12
// 这种方法超时了
public static int maxProfit(int[] prices) {
int maxProfit = 0;
for (int i = 0; i < prices.length - 1; i++) {
int max = max(prices, i+1);
if (prices[i] > max) {
continue;
} else {
if (maxProfit < max - prices[i]) {
maxProfit = max - prices[i];
}
}
}
return maxProfit;
}
public static int max(int[] arr, int start) {
int max = arr[start];
for (int i = start + 1; i < arr.length; i++) {
if (max < arr[i]) {
max = arr[i];
}
}
return max;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 125.验证回文串
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。
字母和数字都属于字母数字字符。
给你一个字符串 s,如果它是 回文串 ,返回 true ;否则,返回 false 。
示例 1:
输入: s = "A man, a plan, a canal: Panama"
输出:true
解释:"amanaplanacanalpanama" 是回文串。
2
3
示例 2:
输入:s = "race a car"
输出:false
解释:"raceacar" 不是回文串。
2
3
示例 3:
输入:s = " "
输出:true
解释:在移除非字母数字字符之后,s 是一个空字符串 "" 。
由于空字符串正着反着读都一样,所以是回文串。
2
3
4
public static boolean isPalindrome(String s) {
if (s == null || s.length() == 0 || s.trim().length() == 0) {
return true;
}
StringBuffer stringBuffer = new StringBuffer();
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (48 <= c && c <= 57) { // 数字
stringBuffer.append(c);
}else if (65 <= c && c <= 90) { // 大写字母
char a = (char)(c+32);
stringBuffer.append(a);
} else if (97 <= c && c <=122) { // 小写字母
stringBuffer.append(c);
} else {
continue;
}
}
if (stringBuffer.toString().equals(stringBuffer.reverse().toString())) {
return true;
} else {
return false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// 答案方法1
public boolean isPalindrome2(String s) {
StringBuffer stringBuffer = new StringBuffer();
int length = s.length();
for (int i = 0; i < length; i++) {
char ch = s.charAt(i);
if (Character.isLetterOrDigit(ch)) {
stringBuffer.append(Character.toLowerCase(ch));
}
}
return stringBuffer.toString().equals(stringBuffer.reverse().toString());
}
2
3
4
5
6
7
8
9
10
11
12
13
// 答案方法2 双指针
public boolean isPalindrome3(String s) {
int n = s.length();
int left = 0, right = n-1;
while (left < right) {
while (left < right && !Character.isLetterOrDigit(s.charAt(left))) {
left++;
}
while (left < right && !Character.isLetterOrDigit(s.charAt(right))) {
right--;
}
if (left < right) {
if (Character.toLowerCase(s.charAt(left)) != Character.toLowerCase(s.charAt(right))) {
return false;
}
left++;
right--;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 136.只出现一次的数字
给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。
示例 1 :
输入:nums = [2,2,1]
输出:1
2
示例 2 :
输入:nums = [4,1,2,1,2]
输出:4
2
示例 3 :
输入:nums = [1]
输出:1
2
// 位运算,异或相同为0,相异为1,0和任何数异或都是本身
public static int singleNumber(int[] nums) {
int result = 0;
for (int i = 0; i < nums.length; i++) {
result = result^nums[i];
}
return result;
}
2
3
4
5
6
7
8
public static int singleNumber2(int[] nums) {
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
if (map.containsKey(nums[i])) {
Integer integer = map.get(nums[i]);
integer++;
map.put(nums[i],integer);
} else {
map.put(nums[i],1);
}
}
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
if (entry.getValue() == 1) {
return entry.getKey();
}
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 141.环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:

输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
2
3
示例 2:

输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
2
3
示例 3:

输入:head = [1], pos = -1
输出:false
解释:链表中没有环。
2
3
public boolean hasCycle(ListNode head) {
HashSet<ListNode> listNodes = new HashSet<>();
while (head != null) {
// add会先判断存不存在该元素
if (!listNodes.add(head)) {
return true;
}
head = head.next;
}
return false;
}
2
3
4
5
6
7
8
9
10
11
// 双向链表
public boolean hasCycle2(ListNode head) {
if (head == null || head.next == null) {
return false;
}
ListNode slow = head;
ListNode fast = head.next;
while (slow != fast) {
if (fast == null || fast.next == null) {
return false;
}
// 慢指针移动一步,快指针移动两步
slow = slow.next;
fast = fast.next.next;
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 144.二叉树的前序遍历
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
示例 1:
输入:root = [1,null,2,3]
输出:[1,2,3]
2
示例 2:
输入:root = []
输出:[]
2
示例 3:
输入:root = [1]
输出:[1]
2
示例 4:

输入:root = [1,2]
输出:[1,2]
2
示例 5:

输入:root = [1,null,2]
输出:[1,2]
2
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
preorder(root, list);
return list;
}
public void preorder(TreeNode root, List list) {
if (root == null) {
return;
}
list.add(root.val);
preorder(root.left,list);
preorder(root.right,list);
}
2
3
4
5
6
7
8
9
10
11
12
13
迭代
// 方法二 迭代
public List<Integer> preorderTraversal2(TreeNode root) {
ArrayList<Integer> res = new ArrayList<>();
if (root == null ) {
return res;
}
Deque<TreeNode> stack = new LinkedList<>();
TreeNode node = root;
while (!stack.isEmpty() || node != null) {
while(node != null) {
res.add(node.val);
stack.push(node);
node = node.left;
}
node = stack.pop();
node = node.right;
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 160.相交链表
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交**:**

题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal- 相交的起始节点的值。如果不存在相交节点,这一值为0listA- 第一个链表listB- 第二个链表skipA- 在listA中(从头节点开始)跳到交叉节点的节点数skipB- 在listB中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例 1:

输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
— 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
2
3
4
5
6
示例 2:

输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at '2'
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
2
3
4
5
示例 3:

输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
2
3
4
5
提示:
listA中节点数目为mlistB中节点数目为n1 <= m, n <= 3 * 1041 <= Node.val <= 1050 <= skipA <= m0 <= skipB <= n- 如果
listA和listB没有交点,intersectVal为0 - 如果
listA和listB有交点,intersectVal == listA[skipA] == listB[skipB]
// 哈希表
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
HashSet<ListNode> visited = new HashSet<>();
ListNode temp = headA;
while (temp != null) {
visited.add(temp);
temp = temp.next;
}
temp = headB;
while(temp != null) {
if (visited.contains(temp)) {
return temp;
}
temp = temp.next;
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 双指针 原理,就相当于遍历完遍历完A,在遍历B。 遍历完B再遍历A。两者相交之处在同一个位置
// 例如 A 1 3 5
// B 4 3 5
// 遍历完A,在遍历B 1 3 5 4 3 5
// 遍历完B再遍历A 4 3 5 1 3 5
// 也就是说相交,相交的部位是相同的。 则A+B B+A长度相同,且最后几位都是相交的部位
public ListNode getIntersectionNode2(ListNode headA, ListNode headB) {
if(headA == null || headB == null) {
return null;
}
ListNode pA = headA, pB = headB;
while(pA != pB) {
if (pA == null) {
pA = headB;
} else {
pA = pA.next;
}
if (pB == null) {
pB = headA;
} else {
pB= pB.next;
}
}
return pA;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 168. Excel表列名称
给你一个整数 columnNumber ,返回它在 Excel 表中相对应的列名称。
例如:
A -> 1
B -> 2
C -> 3
...
Z -> 26
AA -> 27
AB -> 28
...
2
3
4
5
6
7
8
示例 1:
输入:columnNumber = 1
输出:"A"
2
示例 2:
输入:columnNumber = 28
输出:"AB"
2
示例 3:
输入:columnNumber = 701
输出:"ZY"
2
示例 4:
输入:columnNumber = 2147483647
输出:"FXSHRXW"
2
提示:
1 <= columnNumber <= 231 - 1
public static String convertToTitle(int columnNumber) {
StringBuffer stringBuffer = new StringBuffer();
while (columnNumber != 0) {
columnNumber --;
stringBuffer.append((char)((columnNumber % 26) + 'A'));
columnNumber /= 26;
}
return stringBuffer.reverse().toString();
}
2
3
4
5
6
7
8
9
# 169.多数元素
给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
输入:nums = [3,2,3]
输出:3
2
示例 2:
输入:nums = [2,2,1,1,1,2,2]
输出:2
2
提示:
n == nums.length1 <= n <= 5 * 104-109 <= nums[i] <= 109
**进阶:**尝试设计时间复杂度为 O(n)、空间复杂度为 O(1) 的算法解决此问题。
public static int majorityElement(int[] nums) {
Arrays.sort(nums);
return nums[nums.length/2];
}
2
3
4
// 利用哈希表来统计每个元素的出现次数
public static int majorityElement2(int[] nums) {
HashMap<Integer, Integer> hashMap = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
if (hashMap.containsKey(nums[i])) {
int a = hashMap.get(nums[i]);
a++;
hashMap.put(nums[i],a);
} else {
hashMap.put(nums[i], 1);
}
}
for (Map.Entry<Integer, Integer> entry : hashMap.entrySet()) {
int key = entry.getKey();
int value = entry.getValue();
if (value > nums.length/2) {
return key;
}
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 随机化
private static int randRange(Random rand, int min, int max) {
return rand.nextInt(max - min) + min;
}
private static int countOccurences(int[] nums, int num) {
int count = 0;
for (int i = 0; i < nums.length; i++) {
if (nums[i] == num) {
count++;
}
}
return count;
}
public static int majorityElement3(int[] nums) {
Random rand = new Random();
int majorityCount = nums.length / 2;
while(true) {
int candidate = nums[randRange(rand,0, nums.length)];
if (countOccurences(nums, candidate) > majorityCount) {
return candidate;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// 分治
private int countInRange(int[] nums,int num,int low, int high) {
int count = 0;
for (int i = low; i <= high; i++) {
if (nums[i] == num) {
count++;
}
}
return count;
}
public int majorityElementRec(int[] nums,int low, int high) {
if (low == high) {
return nums[low];
}
int mid = (high - low) / 2 +low; // 中位数
int left = majorityElementRec(nums, low, mid);
int right = majorityElementRec(nums, mid + 1, high);
if (left == right) {
return left;
}
int leftCount = countInRange(nums, left, low, high);
int rightCount = countInRange(nums, right, low, high);
return leftCount > rightCount ? left : right;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
public int majorityElement4(int[] nums) {
int count = 0;
Integer candidate = null;
for (int num : nums) {
if (count == 0){
candidate = num;
}
count += (num == candidate) ? 1 : -1;
}
return candidate;
}
2
3
4
5
6
7
8
9
10
11
12
# 171.Excel 表列序号
给你一个字符串 columnTitle ,表示 Excel 表格中的列名称。返回 该列名称对应的列序号 。
例如:
A -> 1
B -> 2
C -> 3
...
Z -> 26
AA -> 27
AB -> 28
...
2
3
4
5
6
7
8
示例 1:
输入: columnTitle = "A"
输出: 1
2
示例 2:
输入: columnTitle = "AB"
输出: 28
2
示例 3:
输入: columnTitle = "ZY"
输出: 701
2
public static int titleToNumber(String columnTitle) {
int n = columnTitle.length();
int k =0;
int result = 0;
for (int i = n-1; i >= 0; i--) {
int a = columnTitle.charAt(i) - 'A' + 1;
result = result + (int)Math.pow(26, k) * a;
k++;
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
// 减少幂运算次数
public static int titleToNumber2(String columnTitle) {
int n = columnTitle.length();
int mlitiple = 1;
int result = 0;
for (int i = n-1; i >= 0; i--) {
int a = columnTitle.charAt(i) - 'A' + 1;
result = result + mlitiple * a;
mlitiple *= 26;
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
# 190.颠倒二进制位
颠倒给定的 32 位无符号整数的二进制位。
提示:
- 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。
- 在 Java 中,编译器使用二进制补码 (opens new window)记法来表示有符号整数。因此,在 示例 2 中,输入表示有符号整数
-3,输出表示有符号整数-1073741825。
示例 1:
输入:n = 00000010100101000001111010011100
输出:964176192 (00111001011110000010100101000000)
解释:输入的二进制串 00000010100101000001111010011100 表示无符号整数 43261596,
因此返回 964176192,其二进制表示形式为 00111001011110000010100101000000。
2
3
4
示例 2:
输入:n = 11111111111111111111111111111101
输出:3221225471 (10111111111111111111111111111111)
解释:输入的二进制串 11111111111111111111111111111101 表示无符号整数 4294967293,
因此返回 3221225471 其二进制表示形式为 10111111111111111111111111111111 。
2
3
4
提示:
- 输入是一个长度为
32的二进制字符串
# 191.位1的个数
编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 '1' 的个数(也被称为汉明重量 (opens new window))。
提示:
- 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。
- 在 Java 中,编译器使用二进制补码 (opens new window)记法来表示有符号整数。因此,在上面的 示例 3 中,输入表示有符号整数
-3。
示例 1:
输入:00000000000000000000000000001011
输出:3
解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。
2
3
示例 2:
输入:00000000000000000000000010000000
输出:1
解释:输入的二进制串 00000000000000000000000010000000 中,共有一位为 '1'。
2
3
示例 3:
输入:11111111111111111111111111111101
输出:31
解释:输入的二进制串 11111111111111111111111111111101 中,共有 31 位为 '1'。
2
3
提示:
- 输入必须是长度为
32的 二进制串 。
解法一: 循环遍历每一位
// 方法一 循环检查二进制位
// 00000000000000000000000000001011
// 00000000000000000000000000000001
public int hammingWeight(int n) {
int res = 0;
for (int i = 0; i < 32; i++) {
if ((n & (1 << i)) != 0) {
res++;
}
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
解法二: n与n-1相与会去掉二进制位的一个1
// 方法二 位运算优化
// 00000000000000000000000000001011 (n)
// 00000000000000000000000000001010 (n-1)
// 00000000000000000000000000001010 n & n-1 两者相与会去掉一个1
// 00000000000000000000000000001001 // n-1
public int hammingWeight2(int n) {
int res = 0;
while(n != 0) {
n &= n-1;
res++;
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 202.快乐数
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」 定义为:
- 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
- 然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
- 如果这个过程 结果为 1,那么这个数就是快乐数。
如果 n 是 快乐数 就返回 true ;不是,则返回 false 。
示例 1:
输入:n = 19
输出:true
解释:
12 + 92 = 82
82 + 22 = 68
62 + 82 = 100
12 + 02 + 02 = 1
2
3
4
5
6
7
示例 2:
输入:n = 2
输出:false
2
解法一:借助hash表,判断结果是否已经存在
public static boolean isHappy(int n) {
HashSet<Integer> integers = new HashSet<>();
integers.add(n);
while (n != 1) {
n = result(n);
if (integers.contains(n)) {
return false;
}else {
integers.add(n);
}
}
return true;
}
// 求各个位数平方之和
public static int result (int n) {
int result = 0;
while (n != 0) {
int a = n%10;
result += a*a;
n /= 10;
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
解法二: 利用快慢指针,判断链表是否存在环 (慢指针走一步,快指针走两步)
// 快慢指针
public boolean isHappy2(int n) {
int slowRunner = n;
int fastERunner = result(n);
while (fastERunner != 1 && slowRunner != fastERunner) {
// 慢指针走一步,快指针走两步
slowRunner = result(slowRunner);
fastERunner = result(result(fastERunner));
}
return fastERunner == 1;
}
2
3
4
5
6
7
8
9
10
11
# 203.移除链表元素
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:

输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
2
示例 2:
输入:head = [], val = 1
输出:[]
2
示例 3:
输入:head = [7,7,7,7], val = 7
输出:[]
2
解法一:递归
// 方法一 递归
public ListNode removeElements(ListNode head, int val) {
if (head == null) {
return null;
}
head.next = removeElements(head.next, val);
return head.val == val ? head.next : head;
}
2
3
4
5
6
7
8
9
10
解法二: 迭代
// 方法二 迭代
public ListNode removeElements2(ListNode head, int val) {
ListNode dummyHead = new ListNode(0);
dummyHead.next = head;
ListNode temp = dummyHead;
while (temp.next != null) {
if (temp.next.val == val) {
temp.next = temp.next.next;
} else {
temp = temp.next;
}
}
return dummyHead.next;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 205.同构字符串
给定两个字符串 s 和 t ,判断它们是否是同构的。
如果 s 中的字符可以按某种映射关系替换得到 t ,那么这两个字符串是同构的。
每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相同字符只能映射到同一个字符上,字符可以映射到自己本身。
示例 1:
输入:s = "egg", t = "add"
输出:true
2
示例 2:
输入:s = "foo", t = "bar"
输出:false
2
示例 3:
输入:s = "paper", t = "title"
输出:true
2
public boolean isIsomorphic(String s, String t) {
HashMap<Character, Character> s2t = new HashMap<>();
HashMap<Character, Character> t2s = new HashMap<>();
int len = s.length();
for (int i = 0; i < len; i++) {
char x = s.charAt(i), y = t.charAt(i);
if ((s2t.containsKey(x) && s2t.get(x) != y) ||(t2s.containsKey(y) &&t2s.get(y) != x) ) {
return false;
}
s2t.put(x,y);
t2s.put(y,x);
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 206.反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:

输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
2
示例 2:

输入:head = [1,2]
输出:[2,1]
2
示例 3:
输入:head = []
输出:[]
2
提示:
- 链表中节点的数目范围是
[0, 5000] -5000 <= Node.val <= 5000
解法一,利用栈实现反转
public static ListNode reverseList(ListNode head) {
if(head == null) {
return null;
}
Stack<ListNode> stack = new Stack<>();
ListNode p = head;
while (p!= null) {
stack.push(p);
p = p.next;
}
ListNode listNode = new ListNode();
ListNode l = listNode;
int n = stack.size();
for (int i = 0; i < n; i++) {
ListNode q = stack.pop();
q.next = null;
l.next = q;
l = q;
}
return listNode.next;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
解法二: 迭代
public ListNode reverseList2 (ListNode head) {
ListNode prev = null;
ListNode curr = head;
while(curr != null) {
ListNode next = curr.next;
curr.next = prev;
prev = curr;
curr = next;
}
return prev;
}
2
3
4
5
6
7
8
9
10
11
解法三: 递归
// 方法二 递归
/**
* 以链表1->2->3->4->5举例
* @param head
* @return
*/
public ListNode reverseList3(ListNode head) {
if (head == null || head.next == null) {
/*
直到当前节点的下一个节点为空时返回当前节点
由于5没有下一个节点了,所以此处返回节点5
*/
return head;
}
//递归传入下一个节点,目的是为了到达最后一个节点
// 返回的始终是原链表的最后一个结点
ListNode newHead = reverseList3(head.next);
/*
第一轮出栈,head为5,head.next为空,返回5
第二轮出栈,head为4,head.next为5,执行head.next.next=head也就是5.next=4,
把当前节点的子节点的子节点指向当前节点
此时链表为1->2->3->4<->5,由于4与5互相指向,所以此处要断开4.next=null
此时链表为1->2->3->4<-5
返回节点5
第三轮出栈,head为3,head.next为4,执行head.next.next=head也就是4.next=3,
此时链表为1->2->3<->4<-5,由于3与4互相指向,所以此处要断开3.next=null
此时链表为1->2->3<-4<-5
返回节点5
第四轮出栈,head为2,head.next为3,执行head.next.next=head也就是3.next=2,
此时链表为1->2<->3<-4<-5,由于2与3互相指向,所以此处要断开2.next=null
此时链表为1->2<-3<-4<-5
返回节点5
第五轮出栈,head为1,head.next为2,执行head.next.next=head也就是2.next=1,
此时链表为1<->2<-3<-4<-5,由于1与2互相指向,所以此处要断开1.next=null
此时链表为1<-2<-3<-4<-5
返回节点5
出栈完成,最终头节点5->4->3->2->1
*/
head.next.next = head;
head.next = null;
return newHead;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42


# 217.存在重复元素
给你一个整数数组 nums 。如果任一值在数组中出现 至少两次 ,返回 true ;如果数组中每个元素互不相同,返回 false 。
示例 1:
输入:nums = [1,2,3,1]
输出:true
2
示例 2:
输入:nums = [1,2,3,4]
输出:false
2
示例 3:
输入:nums = [1,1,1,3,3,4,3,2,4,2]
输出:true
2
解法一: 排序
// 方法一 排序
public static boolean containsDuplicate(int[] nums) {
Arrays.sort(nums);
int n = nums.length;
for (int i = 0; i < n-1; i++) {
if (nums[i] == nums[i+1]) {
return true;
}
}
return false;
}
2
3
4
5
6
7
8
9
10
11
解法二:哈希表
// 方法二:哈希表
public static boolean containsDuplicate2(int[] nums) {
HashSet<Object> set = new HashSet<>();
for (int x : nums) {
if (!set.add(x)) {
return true;
}
}
return false;
}
2
3
4
5
6
7
8
9
10
# 219.存在重复元素 II
给你一个整数数组 nums 和一个整数 k ,判断数组中是否存在两个 不同的索引 i 和 j ,满足 nums[i] == nums[j] 且 abs(i - j) <= k 。如果存在,返回 true ;否则,返回 false 。
示例 1:
输入:nums = [1,2,3,1], k = 3
输出:true
2
示例 2:
输入:nums = [1,0,1,1], k = 1
输出:true
2
示例 3:
输入:nums = [1,2,3,1,2,3], k = 2
输出:false
2
解法一: 哈希表
public static boolean containsNearbyDuplicate(int[] nums, int k) {
HashMap<Integer, Integer> hashMap = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
if (hashMap.containsKey(nums[i])) {
int j = hashMap.get(nums[i]);
if (i - j <= k) {
return true;
}else {
hashMap.put(nums[i],i);
}
}else {
hashMap.put(nums[i],i);
}
}
return false;
}
// 答案方法一
public boolean containsNearbyDuplicate2(int[] nums, int k) {
HashMap<Integer, Integer> map = new HashMap<>();
int length = nums.length;
for (int i = 0; i < length; i++) {
int num = nums[i];
if (map.containsKey(num) && i - map.get(num) <= k) {
return true;
}
map.put(num, i);
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
解法二:滑动窗口
// 方法二 滑动窗口
public boolean containsNearbyDuplicate3(int[] nums, int k) {
HashSet<Integer> set = new HashSet<>();
int length = nums.length;
for (int i = 0; i < length; i++) {
if (i > k) {
set.remove(nums[i-k-1]);
}
if (!set.add(nums[i])) {
return true;
}
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 225.用队列实现栈
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。
实现 MyStack 类:
void push(int x)将元素 x 压入栈顶。int pop()移除并返回栈顶元素。int top()返回栈顶元素。boolean empty()如果栈是空的,返回true;否则,返回false。
解法一:两个队列
// 方法一 两个队列
class MyStack {
Queue<Integer> queue1;
Queue<Integer> queue2; // 辅助队列
public MyStack() {
queue1 = new LinkedList<>();
queue2 = new LinkedList<>();
}
public void push(int x) {
queue2.offer(x);
while (!queue1.isEmpty()) {
queue2.offer(queue1.poll());
}
Queue<Integer> temp = queue1;
queue1 = queue2;
queue2 = temp;
}
public int pop() {
return queue1.poll();
}
public int top() {
return queue1.peek();
}
public boolean empty() {
return queue1.isEmpty();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
解法二:一个队列
// 方法二 一个队列
class MyStack2 {
Queue<Integer> queue;
public MyStack2() {
queue = new LinkedList<>();
}
public void push(int x) {
int n = queue.size();
queue.offer(x);
for (int i = 0; i < n; i++) {
queue.offer(queue.poll());
}
}
public int pop() {
return queue.poll();
}
public int top() {
return queue.peek();
}
public boolean empty() {
return queue.isEmpty();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 226.翻转二叉树
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
示例 1:
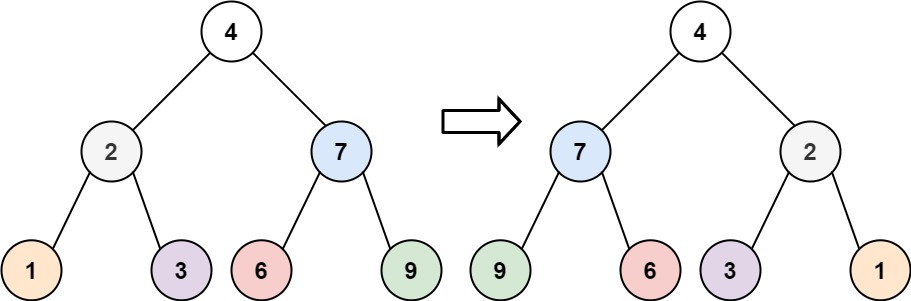
输入:root = [4,2,7,1,3,6,9]
输出:[4,7,2,9,6,3,1]
2
示例 2:
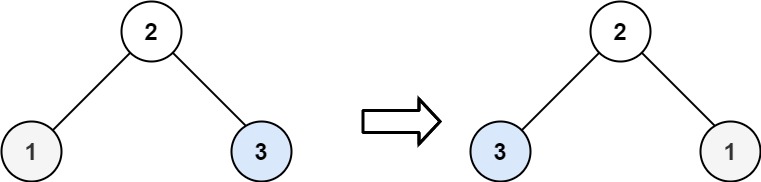
输入:root = [2,1,3]
输出:[2,3,1]
2
示例 3:
输入:root = []
输出:[]
2
// 方法一 递归
public TreeNode invertTree(TreeNode root) {
if (root == null) {
return null;
}
TreeNode left = invertTree(root.left);
TreeNode right = invertTree(root.right);
root.left = right;
root.right = left;
return root;
}
public TreeNode invertTree2(TreeNode root) {
dfs(root);
return root;
}
private void dfs(TreeNode root) {
if (root == null) {
return;
}
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
dfs(root.left);
dfs(root.right);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 228.汇总区间
给定一个 无重复元素 的 有序 整数数组 nums 。
返回 恰好覆盖数组中所有数字 的 最小有序 区间范围列表 。也就是说,nums 的每个元素都恰好被某个区间范围所覆盖,并且不存在属于某个范围但不属于 nums 的数字 x 。
列表中的每个区间范围 [a,b] 应该按如下格式输出:
"a->b",如果a != b"a",如果a == b
示例 1:
输入:nums = [0,1,2,4,5,7]
输出:["0->2","4->5","7"]
解释:区间范围是:
[0,2] --> "0->2"
[4,5] --> "4->5"
[7,7] --> "7"
2
3
4
5
6
示例 2:
输入:nums = [0,2,3,4,6,8,9]
输出:["0","2->4","6","8->9"]
解释:区间范围是:
[0,0] --> "0"
[2,4] --> "2->4"
[6,6] --> "6"
[8,9] --> "8->9"
2
3
4
5
6
7
public List<String> summaryRanges(int[] nums) {
ArrayList<String> ret = new ArrayList<>();
int i = 0;
int n = nums.length;
while (i < n) {
int low = i;
i++;
while (i < n && nums[i] == nums[i-1] + 1) {
i++;
}
int high = i - 1;
StringBuffer temp = new StringBuffer(Integer.toString(nums[low]));
if (low < high) {
temp.append("->");
temp.append(Integer.toString(nums[high]));
}
ret.add(temp.toString());
}
return ret;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 231.2 的幂
给你一个整数 n,请你判断该整数是否是 2 的幂次方。如果是,返回 true ;否则,返回 false 。
如果存在一个整数 x 使得 n == 2x ,则认为 n 是 2 的幂次方。
示例 1:
输入:n = 1
输出:true
解释:20 = 1
2
3
示例 2:
输入:n = 16
输出:true
解释:24 = 16
2
3
示例 3:
输入:n = 3
输出:false
2
示例 4:
输入:n = 4
输出:true
2
示例 5:
输入:n = 5
输出:false
2
解法一:自己写
public static boolean isPowerOfTwo(int n) {
if (n == 1) {
return true;
}
if (n == 0) {
return false;
}
while (n != 1){
if (n % 2 != 0) {
return false;
}
n = n/2;
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
解法二:二进制表示
// 一个数 nnn 是 222 的幂,当且仅当 nnn 是正整数,并且 nnn 的二进制表示中仅包含 1 个 1。
public static boolean isPowerOfTwo2(int n) {
return n > 0 && (n & (n-1)) == 0;
}
2
3
4
解法三:
// 方法二:判断是否为最大 222 的幂的约数
// 在题目给定的 323232 位有符号整数的范围内,最大的 222 的幂为 230=10737418242^{30} = 10737418242
static final int BIG = 1 << 30;
public boolean isPowerOfTwo3(int n) {
return n > 0 && BIG % n == 0;
}
2
3
4
5
6
7
# 232.用栈实现队列
请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
实现 MyQueue 类:
void push(int x)将元素 x 推到队列的末尾int pop()从队列的开头移除并返回元素int peek()返回队列开头的元素boolean empty()如果队列为空,返回true;否则,返回false
说明:
- 你 只能 使用标准的栈操作 —— 也就是只有
push to top,peek/pop from top,size, 和is empty操作是合法的。 - 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
示例 1:
输入:
["MyQueue", "push", "push", "peek", "pop", "empty"]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 1, 1, false]
解释:
MyQueue myQueue = new MyQueue();
myQueue.push(1); // queue is: [1]
myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue)
myQueue.peek(); // return 1
myQueue.pop(); // return 1, queue is [2]
myQueue.empty(); // return false
2
3
4
5
6
7
8
9
10
11
12
13
class MyQueue {
Deque<Integer> inStack;
Deque<Integer> outStack;
public MyQueue() {
inStack = new ArrayDeque<>();
outStack = new ArrayDeque<>();
}
public void push(int x) {
inStack.push(x);
}
public int pop() {
if (outStack.isEmpty()) {
in2out();
}
return outStack.pop();
}
public int peek() {
if (outStack.isEmpty()) {
in2out();
}
return outStack.peek();
}
public boolean empty() {
return inStack.isEmpty() &&outStack.isEmpty();
}
private void in2out() {
while (! inStack.isEmpty()) {
outStack.push(inStack.pop());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 234.回文链表
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
示例 1:

输入:head = [1,2,2,1]
输出:true
2
示例 2:

输入:head = [1,2]
输出:false
2
// 方法一:将值复制到数组中后用双指针法
public boolean isPalindrome(ListNode head) {
ArrayList<Integer> list = new ArrayList<>();
while(head != null) {
list.add(head.val);
head = head.next;
}
int start = 0;
int end = list.size()-1;
while (start < end) {
if (list.get(start) != list.get(end)) {
return false;
}
start++;
end--;
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 方法二: 递归
ListNode frontPoint;
public boolean isPalindrome2(ListNode head) {
frontPoint = head;
return recursivelyCheck(head);
}
private boolean recursivelyCheck(ListNode currentNode) {
if (currentNode != null) {
if (!recursivelyCheck(currentNode.next)) {
return false;
}
if (currentNode.val != frontPoint.val) {
return false;
}
frontPoint = frontPoint.next;
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 方法三:快慢指针
public boolean isPalindrome3(ListNode head) {
if (head == null) {
return true;
}
// 找到前半部分链表的尾结点并反转后半部分链表
ListNode firstHalfEnd = endOfFirstHalf(head);
ListNode secondHalfStart = reverseList(firstHalfEnd.next);
// 判断是否回文
ListNode p1 = head;
ListNode p2 = secondHalfStart;
boolean result = true;
while (result && p2 != null) {
if (p1.val != p2.val) {
result = false;
}
p1 = p1.next;
p2 = p2.next;
}
// 还原链表并返回结果
firstHalfEnd.next = reverseList(secondHalfStart);
return result;
}
private ListNode reverseList(ListNode head) {
ListNode prev = null;
ListNode curr = head;
while(curr != null) {
ListNode nextTemp = curr.next;
curr.next = prev;
prev = curr;
curr = nextTemp;
}
return prev;
}
private ListNode endOfFirstHalf(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while (fast.next != null && fast.next.next != null) {
fast = fast.next.next;
slow = slow.next;
}
return slow;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 242. 有效的字母异位词
给定两个字符串 *s* 和 *t* ,编写一个函数来判断 *t* 是否是 *s* 的字母异位词。
**注意:**若 *s* 和 *t* 中每个字符出现的次数都相同,则称 *s* 和 *t* 互为字母异位词。
示例 1:
输入: s = "anagram", t = "nagaram"
输出: true
2
示例 2:
输入: s = "rat", t = "car"
输出: false
2
public static boolean isAnagram(String s, String t) {
if (s== null || t == null) {
return true;
}
if (s.length() != t.length()) {
return false;
}
HashMap<Character, Integer> map1 = new HashMap<>();
HashMap<Character, Integer> map2 = new HashMap<>();
for (int i = 0; i < s.length(); i++) {
if (map1.containsKey(s.charAt(i))) {
int value = map1.get(s.charAt(i));
value ++;
map1.put(s.charAt(i), value);
}else {
map1.put(s.charAt(i), 1);
}
}
for (int i = 0; i < t.length(); i++) {
if (map2.containsKey(t.charAt(i))) {
int value = map2.get(t.charAt(i));
value ++;
map2.put(t.charAt(i), value);
}else {
map2.put(t.charAt(i), 1);
}
}
for (Map.Entry<Character, Integer> entry : map1.entrySet()) {
Character key = entry.getKey();
int value = entry.getValue();
if (!map2.containsKey(key) || value != map2.get(key)) {
return false;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
// 方法一:排序
public boolean isAnagram2(String s, String t) {
if (s.length() != t.length()) {
return false;
}
char[] str1 = s.toCharArray();
char[] str2 = t.toCharArray();
Arrays.sort(str1);
Arrays.sort(str2);
return Arrays.equals(str1, str2);
}
// 方法二: 哈希表
public boolean isAnagram3(String s, String t) {
if (s.length() != t.length()) {
return false;
}
HashMap<Character, Integer> table = new HashMap<>();
for (int i = 0; i < s.length(); i++) {
char ch = s.charAt(i);
table.put(ch,table.getOrDefault(ch, 0) + 1);
}
for (int i = 0; i < t.length(); i++) {
char ch = t.charAt(i);
table.put(ch, table.getOrDefault(ch, 0) - 1);
if (table.get(ch) < 0) {
return false;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 257.二叉树的所有路径
给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。
叶子节点 是指没有子节点的节点。
示例 1:
输入:root = [1,2,3,null,5]
输出:["1->2->5","1->3"]
2
示例 2:
输入:root = [1]
输出:["1"]
2
// 方法一:深度优先搜索
public List<String> binaryTreePaths(TreeNode root) {
ArrayList<String> paths = new ArrayList<>();
constructPaths(root, "", paths);
return paths;
}
public void constructPaths(TreeNode root, String path, List<String> paths) {
if (root != null) {
StringBuffer stringBuffer = new StringBuffer(path);
stringBuffer.append(Integer.toString(root.val));
if (root.left == null && root.right == null) { // 当前节点是叶子节点
paths.add(stringBuffer.toString()); // 把路径加入到答案中
} else {
stringBuffer.append("->"); // 当前节点不是叶子结点,继续递归遍历
constructPaths(root.left, stringBuffer.toString(), paths);
constructPaths(root.right, stringBuffer.toString(), paths);
}
}
}
// 方法二: 广度优先搜索
public List<String> binaryTreePaths2(TreeNode root) {
ArrayList<String> paths = new ArrayList<>();
if (root == null) {
return paths;
}
LinkedList<TreeNode> nodeQueue = new LinkedList<>();
LinkedList<String> pathQueue = new LinkedList<>();
nodeQueue.offer(root);
pathQueue.offer(Integer.toString(root.val));
while (!nodeQueue.isEmpty()) {
TreeNode node = nodeQueue.poll();
String path = pathQueue.poll();
if (node.left == null && node.right == null) {
paths.add(path);
} else {
if (node.left != null) {
nodeQueue.offer(node.left);
pathQueue.offer(new StringBuffer(path).append("->").append(node.left.val).toString());
}
if (root.right != null) {
nodeQueue.offer(node.right);
pathQueue.offer(new StringBuffer(path).append("->").append(node.right.val).toString());
}
}
}
return paths;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 258.各位相加
给定一个非负整数 num,反复将各个位上的数字相加,直到结果为一位数。返回这个结果。
示例 1:
输入: num = 38
输出: 2
解释: 各位相加的过程为:
38 --> 3 + 8 --> 11
11 --> 1 + 1 --> 2
由于 2 是一位数,所以返回 2。
2
3
4
5
6
示例 1:
输入: num = 0
输出: 0
2
public static int addDigits(int num) {
while (true) {
num = qiuhe(num);
if (num < 10) {
return num;
}
}
}
public static int qiuhe(int n) {
int result = 0;
while (n != 0) {
result += n % 10;
n/=10;
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16


public int addDigits2(int num) {
return (num-1) % 9 +1;
}
2
3
# 263.丑数
丑数 就是只包含质因数 2、3 和 5 的正整数。
给你一个整数 n ,请你判断 n 是否为 丑数 。如果是,返回 true ;否则,返回 false 。
示例 1:
输入:n = 6
输出:true
解释:6 = 2 × 3
2
3
示例 2:
输入:n = 1
输出:true
解释:1 没有质因数,因此它的全部质因数是 {2, 3, 5} 的空集。习惯上将其视作第一个丑数。
2
3
示例 3:
输入:n = 14
输出:false
解释:14 不是丑数,因为它包含了另外一个质因数 7 。
2
3
public boolean isUgly(int n) {
if( n <= 0 ) {
return false;
}
int[] factors = {2,3,5};
for (int factor : factors) {
while (n % factor == 0) {
n /= factor;
}
}
return n == 1;
}
2
3
4
5
6
7
8
9
10
11
12
# 268.丢失的数字
给定一个包含 [0, n] 中 n 个数的数组 nums ,找出 [0, n] 这个范围内没有出现在数组中的那个数。
示例 1:
输入:nums = [3,0,1]
输出:2
解释:n = 3,因为有 3 个数字,所以所有的数字都在范围 [0,3] 内。2 是丢失的数字,因为它没有出现在 nums 中。
2
3
示例 2:
输入:nums = [0,1]
输出:2
解释:n = 2,因为有 2 个数字,所以所有的数字都在范围 [0,2] 内。2 是丢失的数字,因为它没有出现在 nums 中。
2
3
示例 3:
输入:nums = [9,6,4,2,3,5,7,0,1]
输出:8
解释:n = 9,因为有 9 个数字,所以所有的数字都在范围 [0,9] 内。8 是丢失的数字,因为它没有出现在 nums 中。
2
3
示例 4:
输入:nums = [0]
输出:1
解释:n = 1,因为有 1 个数字,所以所有的数字都在范围 [0,1] 内。1 是丢失的数字,因为它没有出现在 nums 中。
2
3
public static int missingNumber(int[] nums) {
int n = nums.length;
int[] t = new int[n+1];
for (int i = 0; i < n; i++) {
t[nums[i]] = 1;
}
for (int i = 0; i < n+1; i++) {
if (t[i] == 0) {
return i;
}
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
解法一:排序
public int missingNumber2(int[] nums) {
Arrays.sort(nums);
int n = nums.length;
for (int i = 0; i < n; i++) {
if (nums[i] != i) {
return i;
}
}
return n;
}
2
3
4
5
6
7
8
9
10
解法二:哈希表
public int missingNumber3(int[] nums) {
HashSet<Integer> set = new HashSet<>();
int n = nums.length;
for (int i = 0; i < n; i++) {
set.add(nums[i]);
}
int missing = -1;
for (int i = 0; i <= n; i++) {
if (!set.contains(i)) {
missing = i;
break;
}
}
return missing;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
解法三:位运算
public int missingNumber4(int[] nums) {
int xor = 0;
int n = nums.length;
for (int i = 0; i < n; i++) {
xor ^= nums[i];
}
for (int i = 0; i <=n ; i++) {
xor ^= i;
}
return xor;
}
2
3
4
5
6
7
8
9
10
11
# 283.移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
示例 1:
输入: nums = [0,1,0,3,12]
输出: [1,3,12,0,0]
2
示例 2:
输入: nums = [0]
输出: [0]
2
自己写的答案:
public static void moveZeroes(int[] nums) {
int n = nums.length;
for (int i = 0; i < n-1; i++) {
if (nums[i] == 0) {
if (!IsZero(nums,i)) { // 如果后面不是全都都是零
int t = nums[i];
for (int j = i; j < n -1 ; j++) {
nums[j] = nums[j+1];
}
nums[n-1] = t;
i = -1; // 需要重头再开始
}
}
}
}
// 判断是不是全为0
public static Boolean IsZero(int[] nums, int start) {
for (int i = start; i < nums.length; i++) {
if (nums[i] != 0) {
return false;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
官方答案:(双指针,左指针左边均为非零数,右指针左边直到左指针处均为0)
// 答案解法
public void moveZeroes2(int[] nums) {
int n = nums.length, left = 0, right = 0;
while (right < n) {
if (nums[right] != 0) {
swap(nums,left, right);
left++;
}
right++;
}
}
public void swap(int[] nums, int left, int right) {
int temp = nums[left];
nums[left] = nums[right];
nums[right] = temp;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 278.第一个错误的版本
你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。
假设你有 n 个版本 [1, 2, ..., n],你想找出导致之后所有版本出错的第一个错误的版本。
你可以通过调用 bool isBadVersion(version) 接口来判断版本号 version 是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。
示例 1:
输入:n = 5, bad = 4
输出:4
解释:
调用 isBadVersion(3) -> false
调用 isBadVersion(5) -> true
调用 isBadVersion(4) -> true
所以,4 是第一个错误的版本。
2
3
4
5
6
7
示例 2:
输入:n = 1, bad = 1
输出:1
2
二分查找法,提高效率
// 二分查找法
public int firstBadVersion2(int n) {
int left = 1, right = n;
while (left < right) {
int mid = left + ((right-left) / 2);
if (!isBadVersion(mid)) {
left = mid+1; // 答案在区间 [mid+1, right] 中
} else {
right = mid; // 答案在区间 [left, mid] 中
}
}
return left;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 290.单词规律
给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。
这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 s 中的每个非空单词之间存在着双向连接的对应规律。
示例1:
输入: pattern = "abba", s = "dog cat cat dog"
输出: true
2
示例 2:
输入:pattern = "abba", s = "dog cat cat fish"
输出: false
2
示例 3:
输入: pattern = "aaaa", s = "dog cat cat dog"
输出: false
2
自己写的解法
public static boolean wordPattern(String pattern, String s) {
HashMap<Character, String> map = new HashMap<>();
String[] strs = s.split(" ");
int n = strs.length;
if (n != pattern.length()) {
return false;
}
for (int i = 0; i < n; i++) {
char key = pattern.charAt(i);
if (map.containsKey(key)) {
if (!strs[i].equals(map.get(key))) {
return false;
}
}else {
// 也不能包含相同的value
if (map.containsValue(strs[i])) {
return false;
}
map.put(key, strs[i]);
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
答案方法以及答案方法改进
// 答案方法
public boolean wordPattern2(String pattern, String str) {
HashMap<String, Character> str2ch = new HashMap<>();
HashMap<Character, String> ch2str = new HashMap<>();
int m =str.length();
int i = 0;
for (int p = 0; p < pattern.length(); p++) {
char ch = pattern.charAt(p);
if (i >= m) {
return false;
}
int j = i;
while (j < m && str.charAt(j) != ' ') {
j++;
}
String temp = str.substring(i,j);
if (str2ch.containsKey(temp) && str2ch.get(temp) != ch) {
return false;
}
if (ch2str.containsKey(ch) && !temp.equals(ch2str.get(ch))) {
return false;
}
str2ch.put(temp, ch);
ch2str.put(ch, temp);
i = j + 1;
}
return i >= m;
}
// 答案方法改进
public boolean wordPattern3(String pattern, String s) {
HashMap<String, Character> str2ch = new HashMap<>();
HashMap<Character, String> ch2str = new HashMap<>();
String[] strs = s.split(" ");
int n = strs.length;
if (n != pattern.length()) {
return false;
}
for (int i = 0; i < n; i++) {
char ch = pattern.charAt(i);
String str = strs[i];
if (str2ch.containsKey(str) && str2ch.get(str) != ch) {
return false;
}
if (ch2str.containsKey(ch) && !str.equals(ch2str.get(ch))) {
return false;
}
str2ch.put(str,ch);
ch2str.put(ch,str);
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 303.区域和检索 - 数组不可变
给定一个整数数组 nums,处理以下类型的多个查询:
- 计算索引
left和right(包含left和right)之间的nums元素的 和 ,其中left <= right
实现 NumArray 类:
NumArray(int[] nums)使用数组nums初始化对象int sumRange(int i, int j)返回数组nums中索引left和right之间的元素的 总和 ,包含left和right两点(也就是nums[left] + nums[left + 1] + ... + nums[right])
示例 1:
输入:
["NumArray", "sumRange", "sumRange", "sumRange"]
[[[-2, 0, 3, -5, 2, -1]], [0, 2], [2, 5], [0, 5]]
输出:
[null, 1, -1, -3]
解释:
NumArray numArray = new NumArray([-2, 0, 3, -5, 2, -1]);
numArray.sumRange(0, 2); // return 1 ((-2) + 0 + 3)
numArray.sumRange(2, 5); // return -1 (3 + (-5) + 2 + (-1))
numArray.sumRange(0, 5); // return -3 ((-2) + 0 + 3 + (-5) + 2 + (-1))
2
3
4
5
6
7
8
9
10
11
// 方法一:前缀和
class NumArray {
int[] sums;
public NumArray(int[] nums) {
int n = nums.length;
sums = new int[n+1];
for (int i = 0; i < n; i++) {
sums[i+1] = sums[i] + nums[i];
}
}
public int sumRange(int i, int j) {
return sums[j+1] - sums[i];
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 338.比特位计数
给你一个整数 n ,对于 0 <= i <= n 中的每个 i ,计算其二进制表示中 1 的个数 ,返回一个长度为 n + 1 的数组 ans 作为答案。
示例 1:
输入:n = 2
输出:[0,1,1]
解释:
0 --> 0
1 --> 1
2 --> 10
2
3
4
5
6
示例 2:
输入:n = 5
输出:[0,1,1,2,1,2]
解释:
0 --> 0
1 --> 1
2 --> 10
3 --> 11
4 --> 100
5 --> 101
2
3
4
5
6
7
8
9
public static int[] countBits(int n) {
int[] arr = new int[n+1];
for (int i = 0; i <= n; i++) {
arr[i] = countNumber(i);
}
return arr;
}
public static int countNumber(int n) {
int count = 0;
while (n != 0) {
n = n & (n-1);
count++;
}
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15

// 答案解法二:动态规划-最高有效位
public int[] countBits2(int n) {
int[] bits = new int[n+1];
int highBit = 0;
for (int i = 1; i <=n ; i++) {
if ((i & (i-1)) == 0) { // 是不是2的倍数,2的倍数就会多个1
highBit = i;
}
bits[i] = bits[i-highBit] + 1;
}
return bits;
}
2
3
4
5
6
7
8
9
10
11
12

// 答案解法三:动态规划-最低有效位
public int[] countBits3(int n) {
int[] bits = new int[n + 1];
for (int i = 1; i <= n; i++) {
bits[i] = bits[i >> 1] + (i&1);
}
return bits;
}
2
3
4
5
6
7
8

// 答案解法四:动态规划-最低设置位
public int[] countBits4(int n) {
int[] bits = new int[n + 1];
for (int i = 1; i <= n; i++) {
bits[i] = bits[i& (i-1)] + 1;
}
return bits;
}
2
3
4
5
6
7
8
# 342.4的幂
给定一个整数,写一个函数来判断它是否是 4 的幂次方。如果是,返回 true ;否则,返回 false 。
整数 n 是 4 的幂次方需满足:存在整数 x 使得 n == 4x
示例 1:
输入:n = 16
输出:true
2
示例 2:
输入:n = 5
输出:false
2
示例 3:
输入:n = 1
输出:true
2
public static boolean isPowerOfFour(int n) {
if (n <= 0) {
return false;
}
while (n != 1) {
if (n % 4 != 0) {
return false;
}
n = n / 4;
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12

// 答案方法一:二进制表示中1的位置
public boolean isPowerOfFour2(int n) {
// n & (n-1)) == 0 表示2的幂次方
// 10101010101010101010101010101010
return n > 0 && (n & (n-1)) == 0 && (n & 0xaaaaaaaa) == 0;
}
2
3
4
5
6
7
8
// 答案方法二: 取模性质
public boolean isPowerOfFour3(int n) {
return n > 0 && (n & (n-1)) == 0 && (n % 3 == 1);
}
2
3
4
# 344.反转字符串
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须**原地 (opens new window)修改输入数组**、使用 O(1) 的额外空间解决这一问题。
示例 1:
输入:s = ["h","e","l","l","o"]
输出:["o","l","l","e","h"]
2
示例 2:
输入:s = ["H","a","n","n","a","h"]
输出:["h","a","n","n","a","H"]
2
public static void reverseString(char[] s) {
int n = s.length;
for (int i = 0; i < n/2; i++) {
char t = s[i];
s[i] = s[n-i-1];
s[n-i-1] = t;
}
}
2
3
4
5
6
7
8
# 349.两个数组的交集
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
2
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
解释:[4,9] 也是可通过的
2
3
自己写的解法
public static int[] intersection(int[] nums1, int[] nums2) {
ArrayList<Integer> list = new ArrayList<>();
HashSet<Integer> integers = new HashSet<>();
for (int i = 0; i < nums1.length; i++) {
integers.add(nums1[i]);
}
for (int i = 0; i < nums2.length; i++) {
if (integers.contains(nums2[i])) {
if (!list.contains(nums2[i])) {
list.add(nums2[i]);
}
}
}
int n = list.size();
int[] arr = new int[n];
for (int i = 0; i < n; i++) {
arr[i] = list.get(i);
}
return arr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// 答案解法:两个集合
// 答案方法一:两个集合
public int[] intersection2(int[] nums1, int[] nums2) {
HashSet<Integer> set1 = new HashSet<>();
HashSet<Integer> set2 = new HashSet<>();
for (int num: nums1) {
set1.add(num);
}
for (int num: nums2) {
set2.add(num);
}
return getIntersection(set1, set2);
}
public int[] getIntersection(Set<Integer> set1, Set<Integer> set2) {
if (set1.size() > set2.size()) {
// 长度小的放前面
return getIntersection(set2,set1);
}
HashSet<Integer> intersectionSet = new HashSet<>();
for (int num: set1) {
if (set2.contains(num)) {
intersectionSet.add(num);
}
}
int[] intersection = new int[intersectionSet.size()];
int index = 0;
for (int num : intersectionSet) {
intersection[index++] = num;
}
return intersection;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// 答案解法二:排序加双指针
public int[] intersection3(int[] nums1, int[] nums2) {
Arrays.sort(nums1);
Arrays.sort(nums2);
int length1 = nums1.length, length2 = nums2.length;
int[] intersection = new int[length1 + length2];
int index = 0,index1 = 0, index2 = 0;
while (index1 < length1 && index2 < length2) {
int num1 = nums1[index1], num2 = nums2[index2];
if (num1 == num2) {
// 保证加入元素的唯一性
if (index == 0 || num1 != intersection[index-1]) {
intersection[index++] = num1;
}
index1++;
index2++;
} else if (num1 < num2) {
index1++;
} else {
index2++;
}
}
return Arrays.copyOfRange(intersection,0, index);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 350.两个数组的交集 II
给你两个整数数组 nums1 和 nums2 ,请你以数组形式返回两数组的交集。返回结果中每个元素出现的次数,应与元素在两个数组中都出现的次数一致(如果出现次数不一致,则考虑取较小值)。可以不考虑输出结果的顺序。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2,2]
2
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[4,9]
2
public static int[] intersection(int[] nums1, int[] nums2) {
Arrays.sort(nums1);
Arrays.sort(nums2);
int length1 = nums1.length, length2 = nums2.length;
int[] intersection = new int[length1 + length2];
int index = 0,index1 = 0, index2 = 0;
while (index1 < length1 && index2 < length2) {
int num1 = nums1[index1], num2 = nums2[index2];
if (num1 == num2) {
intersection[index++] = num1;
index1++;
index2++;
} else if (num1 < num2) {
index1++;
} else {
index2++;
}
}
return Arrays.copyOfRange(intersection,0, index);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// 方法一: 哈希表
public int[] intersect(int[] nums1,int[] nums2) {
if (nums1.length > nums2.length) {
return intersect(nums2, nums1);
}
HashMap<Integer, Integer> map = new HashMap<>();
for (int num : nums1) {
int count = map.getOrDefault(num, 0) + 1;
map.put(num, count);
}
int [] intersection = new int[nums1.length];
int index = 0;
for(int num : nums2) {
int count = map.getOrDefault(num, 0);
if (count > 0) {
intersection[index++] = num;
count--;
if (count > 0) {
map.put(num, count);
} else {
map.remove(num);
}
}
}
return Arrays.copyOfRange(intersection,0, index);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 367.有效的完全平方数
给定一个 正整数 num ,编写一个函数,如果 num 是一个完全平方数,则返回 true ,否则返回 false 。
进阶:不要 使用任何内置的库函数,如 sqrt 。
示例 1:
输入:num = 16
输出:true
2
示例 2:
输入:num = 14
输出:false
2
public static boolean isPerfectSquare(int num) {
int x = (int) Math.sqrt(num);
if (x*x == num) {
return true;
}else {
return false;
}
}
2
3
4
5
6
7
8
//解法二:暴力破解
// 方法二: 暴力破解 (会超时)
public boolean isPerfectSquare2(int num) {
long x = 1, square = 1;
while (square <= num) {
if (square == num) {
return true;
}
x++;
square = x*x;
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
// 解法三:二分查找
// 方法三: 二分查找
public boolean isPerfectSquare3(int num) {
int left = 0, right = num;
while (left <= right) {
int mid = left + (right - left) / 2;
long square = mid*mid;
if (square < num) {
left = mid+1;
}else if (square > num){
right = mid-1;
}else {
return true;
}
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 383.赎金信
给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。
如果可以,返回 true ;否则返回 false 。
magazine 中的每个字符只能在 ransomNote 中使用一次。
示例 1:
输入:ransomNote = "a", magazine = "b"
输出:false
2
示例 2:
输入:ransomNote = "aa", magazine = "ab"
输出:false
2
示例 3:
输入:ransomNote = "aa", magazine = "aab"
输出:true
2
public static boolean canConstruct(String ransomNote, String magazine) {
if (ransomNote.length() > magazine.length() ) {
return false;
}
HashMap<Character, Integer> map = new HashMap<>();
for (int i = 0; i < magazine.length(); i++) {
char ch = magazine.charAt(i);
Integer value = map.getOrDefault(ch, 0) + 1;
map.put(ch, value);
}
for (int i = 0; i < ransomNote.length(); i++) {
char ch = ransomNote.charAt(i);
map.put(ch, map.getOrDefault(ch, 0) - 1);
if (map.get(ch) < 0) {
return false;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
答案解法:
// 答案方法:字符统计
public boolean canConstruct2(String ransomNote, String magazine) {
if (ransomNote.length() > magazine.length()) {
return false;
}
int[] cnt = new int[26];
for (char c : magazine.toCharArray()) {
cnt[c-'a']++;
}
for (char c : ransomNote.toCharArray()) {
cnt[c - 'a']--;
if (cnt[c - 'a'] < 0) {
return false;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 387.字符串中的第一个唯一字符
给定一个字符串 s ,找到 它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回 -1 。
示例 1:
输入: s = "leetcode"
输出: 0
2
示例 2:
输入: s = "loveleetcode"
输出: 2
2
示例 3:
输入: s = "aabb"
输出: -1
2
public int firstUniqChar(String s) {
HashMap<Character, Integer> map = new LinkedHashMap<>();
for (char ch : s.toCharArray()) {
map.put(ch, map.getOrDefault(ch, 0) + 1);
}
// Set<Map.Entry<Character, Integer>> entries = map.entrySet();
// for (Map.Entry entry : entries) {
// if ((Integer) entry.getValue() == 1) {
// return s.indexOf((char)entry.getKey());
// }
// }
for (int i = 0; i < s.length(); i++) {
if (map.get(s.charAt(i)) == 1) {
return i;
}
}
return -1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 389.找不同
给定两个字符串 s 和 t ,它们只包含小写字母。
字符串 t 由字符串 s 随机重排,然后在随机位置添加一个字母。
请找出在 t 中被添加的字母。
示例 1:
输入:s = "abcd", t = "abcde"
输出:"e"
解释:'e' 是那个被添加的字母。
2
3
示例 2:
输入:s = "", t = "y"
输出:"y"
2
public static char findTheDifference(String s, String t) {
HashMap<Character, Integer> map = new HashMap<>();
for (int i = 0; i < s.length(); i++) {
char ch = s.charAt(i);
map.put(ch,map.getOrDefault(ch, 0) + 1);
}
for (int i = 0; i < t.length(); i++) {
char ch = t.charAt(i);
map.put(ch, map.getOrDefault(ch, 0) - 1);
if (map.get(ch) < 0) {
return ch;
}
}
return t.charAt(0);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 答案解法一:计数
// 答案方法一:计数
public char findTheDifference1(String s,String t) {
int[] cnt = new int[26];
for (int i = 0; i < s.length(); i++) {
char ch = s.charAt(i);
cnt[ch - 'a']++;
}
for (int i = 0; i < t.length(); i++) {
char ch = t.charAt(i);
cnt[ch -'a']--;
if (cnt[ch - 'a'] < 0) {
return ch;
}
}
return ' ';
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// 答案解法二:求和
// 答案方法二:求和
public char findTheDifference2(String s,String t) {
int as = 0, at = 0;
for (int i = 0; i < s.length(); i++) {
as += s.charAt(i);
}
for (int i = 0; i < t.length(); i++) {
at+= t.charAt(i);
}
return (char) (at - as);
}
2
3
4
5
6
7
8
9
10
11
// 答案解法三:位运算
与找单独的一个数字,其他数字都是成对出现的问题相似
// 答案方法三: 位运算 (转化为只出现一次的数字问题,其他都是成对出现的)
public char findTheDifference3(String s, String t) {
int ret = 0;
for (int i = 0; i < s.length(); i++) {
ret ^= s.charAt(i);
}
for (int i = 0; i < t.length(); i++) {
ret ^= t.charAt(i);
}
return (char) ret;
}
2
3
4
5
6
7
8
9
10
11
# 392.判断子序列
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
进阶:
如果有大量输入的 S,称作 S1, S2, ... , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
示例 1:
输入:s = "abc", t = "ahbgdc"
输出:true
2
示例 2:
输入:s = "axc", t = "ahbgdc"
输出:false
2
public static boolean isSubsequence(String s, String t) {
if (s.length() == 0) {
return true;
}
int n = s.length(), k = 0;
for (int i = 0; i < t.length(); i++) {
if (s.charAt(k) == t.charAt(i)) {
k++;
if (k == n) {
return true;
}
}
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 答案解法一:双指针
// 答案方法一:双指针
public boolean isSubsequence1(String s,String t) {
int n = s.length(), m = t.length();
int i = 0, j = 0;
while (i < n && j < m) {
if (s.charAt(i) == t.charAt(j)) {
i++;
}
j++;
}
return i == n;
}
2
3
4
5
6
7
8
9
10
11
12
// 答案解法二:动态规划


// 答案方法二:动态规划
public boolean isSubsequence2(String s, String t) {
int n = s.length(), m = t.length();
int[][] f = new int[m+1][26];
for (int i = 0; i < 26; i++) {
f[m][i] = m;
}
for (int i = m-1; i >= 0; i--) {
for (int j = 0; j < 26; j++) {
if (t.charAt(i) == j + 'a')
f[i][j] = i;
else
f[i][j] = f[i+1][j];
}
}
int add = 0;
for (int i = 0; i < n; i++) {
if (f[add][s.charAt(i) - 'a'] == m) {
return false;
}
add = f[add][s.charAt(i) - 'a'] + 1;
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 401.二进制手表
二进制手表顶部有 4 个 LED 代表 小时(0-11),底部的 6 个 LED 代表 分钟(0-59)。每个 LED 代表一个 0 或 1,最低位在右侧。
- 例如,下面的二进制手表读取
"3:25"。

给你一个整数 turnedOn ,表示当前亮着的 LED 的数量,返回二进制手表可以表示的所有可能时间。你可以 按任意顺序 返回答案。
小时不会以零开头:
- 例如,
"01:00"是无效的时间,正确的写法应该是"1:00"。
分钟必须由两位数组成,可能会以零开头:
- 例如,
"10:2"是无效的时间,正确的写法应该是"10:02"。
示例 1:
输入:turnedOn = 1
输出:["0:01","0:02","0:04","0:08","0:16","0:32","1:00","2:00","4:00","8:00"]
2
示例 2:
输入:turnedOn = 9
输出:[]
2
// 方法一:枚举时分
public static List<String> readBinaryWatch(int turnedOn) {
ArrayList<String> ans = new ArrayList<>();
for (int h = 0; h < 12; h++) {
for (int m = 0; m < 60; m++) {
if (Integer.bitCount(h) + Integer.bitCount(m) == turnedOn) {
ans.add(h + ":" + (m <10 ? "0" : "") + m);
}
}
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
// 方法二: 二进制枚举
public static List<String> readBinaryWatch2(int turnedOn) {
ArrayList<String> ans = new ArrayList<>();
for (int i = 0; i < 1024; i++) {
int h = i >> 6, m = i & 63; // 用位运算取出低6位和高4位
if (h < 12 && m < 60 && Integer.bitCount(i) == turnedOn) {
ans.add(h + ":" + (m <10 ? "0" : "") + m);
}
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
# 404.左叶子之和
给定二叉树的根节点 root ,返回所有左叶子之和。
示例 1:
输入: root = [3,9,20,null,null,15,7]
输出: 24
解释: 在这个二叉树中,有两个左叶子,分别是 9 和 15,所以返回 24
2
3
示例 2:
输入: root = [1]
输出: 0
2
解法1: 深度优先搜索
public int sumOfLeftLeaves(TreeNode root) {
return root != null ? dfs(root) : 0;
}
public int dfs(TreeNode node) {
int ans = 0;
if (node.left != null) {
// 如果左子树是叶子结点,就加上,否则继续向下寻找左叶子结点
ans += isLeaveNode(node.left) ? node.left.val : dfs(node.left);
}
if (node.right != null && !isLeaveNode(node.right)) {
ans += dfs(node.right);
}
return ans;
}
// 判断是不是叶子结点
public boolean isLeaveNode(TreeNode node) {
return node.left == null && node.right == null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
解法2:广度优先搜索
public int sumOfLeftLeaves(TreeNode root) {
if (root == null) {
return 0;
}
LinkedList<TreeNode> queue = new LinkedList<>();
queue.offer(root);
int ans = 0;
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
if (node.left != null) {
if (isLeaveNode(node.left)) {
ans += node.left.val;
} else {
queue.offer(node.left);
}
}
if (node.right != null) {
if (!isLeaveNode(node.right)) {
queue.offer(node.right);
}
}
}
return ans;
}
// 判断是不是叶子结点
public boolean isLeaveNode(TreeNode node) {
return node.left == null && node.right == null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 405.数字转换为十六进制数
给定一个整数,编写一个算法将这个数转换为十六进制数。对于负整数,我们通常使用 补码运算 (opens new window) 方法。
注意:
- 十六进制中所有字母(
a-f)都必须是小写。 - 十六进制字符串中不能包含多余的前导零。如果要转化的数为0,那么以单个字符
'0'来表示;对于其他情况,十六进制字符串中的第一个字符将不会是0字符。 - 给定的数确保在32位有符号整数范围内。
- 不能使用任何由库提供的将数字直接转换或格式化为十六进制的方法。
示例 1:
输入:
26
输出:
"1a"
2
3
4
5
示例 2:
输入:
-1
输出:
"ffffffff"
2
3
4
5
// 位运算
public static String toHex(int num) {
if(num == 0) {
return "0";
}
StringBuffer sb = new StringBuffer();
for (int i = 7; i >= 0; i--) {
// 0xf=0000 0000 0000 0000 0000 0000 0000 1111
int val = (num >> (4*i)) & 0xf; // 可以得到二进制的前四位,也就是十六进制的第一位
if (sb.length() > 0 || val > 0) { // 为了保证前缀不为0
char digit = val < 10 ? (char) ('0' + val) : (char) ('a' + val - 10);
sb.append(digit);
}
}
return sb.toString();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 409.最长回文串
给定一个包含大写字母和小写字母的字符串 s ,返回 通过这些字母构造成的 最长的回文串 。
在构造过程中,请注意 区分大小写 。比如 "Aa" 不能当做一个回文字符串。
示例 1:
输入:s = "abccccdd"
输出:7
解释:
我们可以构造的最长的回文串是"dccaccd", 它的长度是 7。
2
3
4
示例 2:
输入:s = "a"
输入:1
2
示例 3:
输入:s = "aaaaaccc"
输入:7
2
// 给定一个包含大写字母和小写字母的字符串 s ,返回 通过这些字母构造成的 最长的回文串 。
// 在一个回文串中,只有最多一个字符出现了奇数次,其余的字符都出现偶数次。
public int longestPalindrome(String s) {
int[] count = new int[128];
int length = s.length();
for (int i = 0; i < length; i++) {
char c = s.charAt(i);
count[c] ++;
}
int ans = 0;
for (int v : count) {
ans += v/2*2; // 如果v是奇数个,就先取最大的偶数个
if (v % 2 == 1 && ans % 2 == 0) { // v为奇数 ans为偶数
ans++;
}
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public static int longestPalindrome2(String s) {
int[] count = new int[52]; // 只记录a-z A-Z
int length = s.length();
for (int i = 0; i < length; i++) {
char c = s.charAt(i);
if ((c <= 'z') && (c >= 'a')) {
int key = c-'a';
count[key]++;
} else {
int key = c-'A'+26;
count[key]++;
}
}
int res = 0,odd_mark = 0; // odd_mark用来标记是否有奇数个字母
for (int i = 0; i < 52; i++) {
res += count[i];
if (count[i] % 2 == 1) { // 如果是奇数个,就减去一个,并且标记一下
res--;
odd_mark = 1;
}
}
if (odd_mark == 1) {
res++; // 只需要加一个就行了
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 414.第三大的数
给你一个非空数组,返回此数组中 第三大的数 。如果不存在,则返回数组中最大的数。
示例 1:
输入:[3, 2, 1]
输出:1
解释:第三大的数是 1 。
2
3
示例 2:
输入:[1, 2]
输出:2
解释:第三大的数不存在, 所以返回最大的数 2 。
2
3
示例 3:
输入:[2, 2, 3, 1]
输出:1
解释:注意,要求返回第三大的数,是指在所有不同数字中排第三大的数。
此例中存在两个值为 2 的数,它们都排第二。在所有不同数字中排第三大的数为 1 。
2
3
4
public int thirdMax(int[] nums) {
Arrays.sort(nums);
reverse(nums);
int k = 1;
// 1 2 3 4
for (int i = 1; i < nums.length; i++) {
if (nums[i] != nums[i-1]) {
k++;
}
if (k == 3) {
return nums[i];
}
}
// 没有第三大的数就返回最大的数
return nums[0];
}
public void reverse(int[] nums) {
int left = 0, right = nums.length - 1;
while (left < right) {
int t = nums[left];
nums[left] = nums[right];
nums[right] = t;
left++;
right--;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// 方法二: 有序集合
public int thirdMax(int[] nums) {
TreeSet<Integer> integers = new TreeSet<>();
for(int num : nums) {
integers.add(num);
if (integers.size() > 3) {
integers.remove(integers.first());
}
}
return integers.size() == 3 ? integers.first() : integers.last();
}
2
3
4
5
6
7
8
9
10
11
// 方法三: 一次遍历
public int thirdMax(int[] nums) {
long a = Long.MIN_VALUE, b = Long.MIN_VALUE, c = Long.MIN_VALUE;
for (long num : nums) {
if (num > a) { // 把 a换成最大的,b第二大,c第三大
c = b;
b = a;
a = num;
} else if (a > num && num > b) {
c = b;
b = num;
} else if (b > num && num > c) {
c = num;
}
}
return c == Long.MIN_VALUE ? (int) a : (int) c;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 415.字符串相加
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和并同样以字符串形式返回。
你不能使用任何內建的用于处理大整数的库(比如 BigInteger), 也不能直接将输入的字符串转换为整数形式。
示例 1:
输入:num1 = "11", num2 = "123"
输出:"134"
2
示例 2:
输入:num1 = "456", num2 = "77"
输出:"533"
2
示例 3:
输入:num1 = "0", num2 = "0"
输出:"0"
2
public String addStrings(String num1, String num2) {
int n1 = num1.length();
int n2 = num2.length();
if (n1 > n2) {
return addStrings(num2, num1);
}
String newNum1 = "";
for (int i = 0; i < n2-n1; i++) {
newNum1 += "0";
}
newNum1 += num1;
StringBuffer stringBuffer = new StringBuffer();
int plus = 0; // 代表进位
for (int i = n2-1; i >= 0 ; i--) {
int a = Integer.parseInt(newNum1.charAt(i)+"");
int b = Integer.parseInt(num2.charAt(i)+"");
int c = a+b + plus;
if (c >= 10) {
stringBuffer.append(c - 10);
plus = 1;
}else {
stringBuffer.append(c);
plus = 0;
}
}
if (plus == 1) {
stringBuffer.append(1);
}
return stringBuffer.reverse().toString();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
答案解法:
public String addStrings(String num1, String num2) {
int i = num1.length() - 1, j = num2.length() - 1, add = 0;
StringBuffer ans = new StringBuffer();
while (i >= 0 || j >= 0 || add != 0) {
int x = i >= 0 ? num1.charAt(i) - '0' : 0;
int y = j >= 0 ? num2.charAt(j) - '0' : 0;
int result = x + y +add;
ans.append(result % 10);
add = result/10;
i--;
j--;
}
ans.reverse();
return ans.toString();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 434.字符串中的单词数
统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。
请注意,你可以假定字符串里不包括任何不可打印的字符。
示例:
输入: "Hello, my name is John"
输出: 5
解释: 这里的单词是指连续的不是空格的字符,所以 "Hello," 算作 1 个单词。
2
3
public int countSegments(String s) {
int count = 0;
for (int i = 0; i <s.length() ; i++) {
if ((i == 0 || s.charAt(i-1) == ' ') && s.charAt(i) != ' ') {
count++;
}
}
return count;
}
2
3
4
5
6
7
8
9
public int countSegments2(String s) {
s = s.trim();
if(s.length() == 0){
return 0;
}
String[] a = s.split("\\s+");
return a.length;
}
2
3
4
5
6
7
8
# 441.排列硬币
你总共有 n 枚硬币,并计划将它们按阶梯状排列。对于一个由 k 行组成的阶梯,其第 i 行必须正好有 i 枚硬币。阶梯的最后一行 可能 是不完整的。
给你一个数字 n ,计算并返回可形成 完整阶梯行 的总行数。
示例 1:

输入:n = 5
输出:2
解释:因为第三行不完整,所以返回 2 。
2
3
示例 2:
输入:n = 8
输出:3
解释:因为第四行不完整,所以返回 3 。
2
3
// 方法一 二分查找
// 等差数列求和公式 s = n*(n+1)/2
public static int arrangeCoins(int n) {
int left = 1, right = n;
while (left < right) {
int mid = (right - left + 1 )/ 2 + left;
if ((long)mid * (mid + 1) <= (long) 2 * n) {
left = mid;
}else {
right = mid - 1;
}
}
return left;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 448.找到所有数组中消失的数字
给你一个含 n 个整数的数组 nums ,其中 nums[i] 在区间 [1, n] 内。请你找出所有在 [1, n] 范围内但没有出现在 nums 中的数字,并以数组的形式返回结果。
示例 1:
输入:nums = [4,3,2,7,8,2,3,1]
输出:[5,6]
2
示例 2:
输入:nums = [1,1]
输出:[2]
2
public static List<Integer> findDisappearedNumbers(int[] nums) {
int n = nums.length;
int[] arr = new int[n+1];
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < n; i++) {
arr[nums[i]] = 1;
}
for (int i = 1; i <= n; i++) {
if (arr[i] == 0){
list.add(i);
}
}
return list;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
// 答案解法

public List<Integer> findDisappearedNumbers2(int[] nums) {
int n = nums.length;
for(int num : nums) {
int x = (num - 1 ) % n;
nums[x] += n;
}
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < n; i++) {
if (nums[i] <= n) {
list.add(i+1);
}
}
return list;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 455.分发饼干
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
示例 1:
输入: g = [1,2,3], s = [1,1]
输出: 1
解释:
你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。
虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。
所以你应该输出1。
2
3
4
5
6
示例 2:
输入: g = [1,2], s = [1,2,3]
输出: 2
解释:
你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。
你拥有的饼干数量和尺寸都足以让所有孩子满足。
所以你应该输出2.
2
3
4
5
6
public static int findContentChildren(int[] g, int[] s) {
Arrays.sort(g);
Arrays.sort(s);
int Glength = g.length,Slength = s.length,i=0,j=0;
int count = 0;
while (i < Glength && j < Slength) {
if (g[i] <= s[j]) {
count++;
i++;
j++;
}else {
j++;
}
}
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 459.重复的子字符串
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
示例 1:
输入: s = "abab"
输出: true
解释: 可由子串 "ab" 重复两次构成。
2
3
示例 2:
输入: s = "aba"
输出: false
2
示例 3:
输入: s = "abcabcabcabc"
输出: true
解释: 可由子串 "abc" 重复四次构成。 (或子串 "abcabc" 重复两次构成。)
2
3
// 方法一 枚举
public boolean repeatedSubstringPattern(String s) {
int n = s.length();
for (int i = 1; i * 2 <= n; i++) {
if (n % i == 0){ // n为i的倍数
boolean match= true;
for (int j = i; j < n; j++) {
if (s.charAt(j) != s.charAt(j-i)) {
match = false;
break;
}
}
if (match) {
return true;
}
}
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 461.汉明距离
两个整数之间的 汉明距离 (opens new window) 指的是这两个数字对应二进制位不同的位置的数目。
给你两个整数 x 和 y,计算并返回它们之间的汉明距离。
示例 1:
输入:x = 1, y = 4
输出:2
解释:
1 (0 0 0 1)
4 (0 1 0 0)
↑ ↑
上面的箭头指出了对应二进制位不同的位置。
2
3
4
5
6
7
示例 2:
输入:x = 3, y = 1
输出:1
2
public static int hammingDistance(int x, int y) {
int count = 0;
for (int i = 0; i < 32; i++) {
if (((x >> i & 1) ^ (y>> i & 1)) == 1) {
count ++;
}
}
return count;
}
2
3
4
5
6
7
8
9
答案解法 一:使用内置函数,计算二进制中1的个数
// 方法一:内置位计数功能
public int hammingDistance2(int x, int y) {
return Integer.bitCount(x ^ y);
}
2
3
4
答案解法 二:移位实现位计数
// 方法二:移位实现位计数
public int hammingDistance3(int x, int y) {
int s = x ^ y ,ret = 0;
while (s != 0) {
ret += s&1;
s>>=1;
}
return ret;
}
2
3
4
5
6
7
8
9
public int hammingDistance4(int x, int y) {
int s = x ^ y, ret = 0; // 相同为0,相异为1
while (s != 0) {
s &= s - 1; //每次会去掉一个1
ret++;
}
return ret;
}
2
3
4
5
6
7
8
# 463.岛屿的周长
给定一个 row x col 的二维网格地图 grid ,其中:grid[i][j] = 1 表示陆地, grid[i][j] = 0 表示水域。
网格中的格子 水平和垂直 方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰好有一个岛屿(或者说,一个或多个表示陆地的格子相连组成的岛屿)。
岛屿中没有“湖”(“湖” 指水域在岛屿内部且不和岛屿周围的水相连)。格子是边长为 1 的正方形。网格为长方形,且宽度和高度均不超过 100 。计算这个岛屿的周长。
示例 1:

输入:grid = [[0,1,0,0],[1,1,1,0],[0,1,0,0],[1,1,0,0]]
输出:16
解释:它的周长是上面图片中的 16 个黄色的边
2
3
示例 2:
输入:grid = [[1]]
输出:4
2
示例 3:
输入:grid = [[1,0]]
输出:4
2
public static int islandPerimeter(int[][] grid) {
int count = 0;
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[i].length; j++) {
if (grid[i][j] == 1){
count +=4;
// 判断左边有没有盒子
if (j >= 1 && grid[i][j-1] == 1) {
count -= 1;
}
// 判断右边有没有盒子
if (j < grid[i].length - 1 && grid[i][j+1] == 1) {
count -= 1;
}
// 判断上边有没有盒子
if ( i >= 1 && grid[i-1][j] == 1) {
count -= 1;
}
// 判断下边有没有盒子
if (i < grid.length - 1 && grid[i+1][j] == 1) {
count -= 1;
}
}
}
}
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
方法一:迭代
static int[] dx = {0,1,0,-1};
static int[] dy = {1,0,-1,0};
//两个竖起来相加, 分别是下边,右边,左边,上边
public int islandPerimeter2(int[][] grid) {
int n = grid.length, m = grid[0].length;
int ans = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (grid[i][j] == 1) {
int cnt = 0;
for(int k = 0; k < 4; k++) {
int tx = i + dx[k];
int ty = j + dy[k];
// tx < 0,代表是最左边的,tx >= n 最右边
// ty < 0,代表最上边,ty >= m 代表最下边
if (tx < 0 || tx >=n || ty < 0 || ty >= m || grid[tx][ty] == 0) {
cnt += 1;
}
}
ans += cnt;
}
}
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
方法二:深度优先搜索
static int[] dx = {0,1,0,-1};
static int[] dy = {1,0,-1,0};
//两个竖起来相加, 分别是下边,右边,左边,上边
// 答案解法二:深度优先搜索
public int islandPerimeter3(int[][] grid) {
int n = grid.length, m = grid[0].length;
int ans = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (grid[i][j] == 1) {
ans += dfs(i, j, grid, n ,m);
}
}
}
return ans;
}
public int dfs(int x, int y, int[][] grid, int n, int m){
if ( x < 0 || x >= n || y < 0 || y >= m || grid[x][y] == 0) {
return 1;
}
if (grid[x][y] == 2) {
return 0;
}
grid[x][y] = 2;
int res = 0;
for (int i = 0; i < 4; i++) {
int tx = x + dx[i];
int ty = y + dy[i];
res += dfs(tx,ty,grid,n,m);
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 476.数字的补数
对整数的二进制表示取反(0 变 1 ,1 变 0)后,再转换为十进制表示,可以得到这个整数的补数。
- 例如,整数
5的二进制表示是"101",取反后得到"010",再转回十进制表示得到补数2。
给你一个整数 num ,输出它的补数。
示例 1:
输入:num = 5
输出:2
解释:5 的二进制表示为 101(没有前导零位),其补数为 010。所以你需要输出 2 。
2
3
示例 2:
输入:num = 1
输出:0
解释:1 的二进制表示为 1(没有前导零位),其补数为 0。所以你需要输出 0 。
2
3
public static int findComplement(int num) {
String bin_num = Integer.toBinaryString(num);
StringBuffer stringBuffer = new StringBuffer();
for (int i = 0; i < bin_num.length(); i++) {
int c = bin_num.charAt(i) - '0';
if (c == 1) {
stringBuffer.append(0);
}else {
stringBuffer.append(1);
}
}
return Integer.parseInt(stringBuffer.toString(),2);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
答案解法:位运算
// 答案解法:位运算
// 例如,num的二进制是101,找对最高位的1(第二位),那么mask就是二进制的 (1000(1在第三位) - 1)二进制相减111
// 本质就是这个数的二进制为和长度相等的二进制位全为1的数异或,就是相反
public int findComplement2(int num) {
int highbit = 0;
for (int i = 1; i <=30 ; i++) {
if (num >= 1 << i) {
highbit = i;
} else {
break;
}
}
// 101
// mask = 1000 -1 0111
int mask = highbit == 30 ? 0x7fffffff : (1 << (highbit + 1)) - 1;
// 与二进制位全是1的异或相当于取反
return num ^ mask;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 482.密钥格式化
给定一个许可密钥字符串 s,仅由字母、数字字符和破折号组成。字符串由 n 个破折号分成 n + 1 组。你也会得到一个整数 k 。
我们想要重新格式化字符串 s,使每一组包含 k 个字符,除了第一组,它可以比 k 短,但仍然必须包含至少一个字符。此外,两组之间必须插入破折号,并且应该将所有小写字母转换为大写字母。
返回 重新格式化的许可密钥。
示例 1:
输入:S = "5F3Z-2e-9-w", k = 4
输出:"5F3Z-2E9W"
解释:字符串 S 被分成了两个部分,每部分 4 个字符;
注意,两个额外的破折号需要删掉。
2
3
4
示例 2:
输入:S = "2-5g-3-J", k = 2
输出:"2-5G-3J"
解释:字符串 S 被分成了 3 个部分,按照前面的规则描述,第一部分的字符可以少于给定的数量,其余部分皆为 2 个字符。
2
3
public static String licenseKeyFormatting(String s, int k) {
int count = 0, m = s.length();
StringBuffer stringBuffer = new StringBuffer();
for (int i = 0; i < m; i++) {
char c = s.charAt(i);
if(c == '-') {
count++;
}else {
if ('a' <= c &&c <= 'z') {
stringBuffer.append((char)(c - 32));
}else {
stringBuffer.append(c);
}
}
}
int n = stringBuffer.length();
if (n <= k) {
return stringBuffer.toString();
}
int d = n % k;
if (d != 0) {
stringBuffer.insert(d, '-');
d++; // 加1的原因,字符串中加了一个字符
}
for (int i = d+k; i < n + n/k-1; i+=k) {
stringBuffer.insert(i,'-');
i++;
}
return stringBuffer.toString();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
答案解法:
public String licenseKeyFaormatting(String s, int k) {
StringBuffer ans = new StringBuffer();
int cnt = 0;
for (int i = s.length() - 1; i >= 0 ; i--) {
if (s.charAt(i) != '-') {
cnt++;
ans.append(Character.toUpperCase(s.charAt(i)));
if (cnt % k == 0) {
ans.append("-");
}
}
}
if (ans.length() > 0 &&ans.charAt(ans.length() -1) == '-') {
ans.deleteCharAt(ans.length() - 1);
}
return ans.reverse().toString();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 485.最大连续 1 的个数
相关企业
给定一个二进制数组 nums , 计算其中最大连续 1 的个数。
示例 1:
输入:nums = [1,1,0,1,1,1]
输出:3
解释:开头的两位和最后的三位都是连续 1 ,所以最大连续 1 的个数是 3.
2
3
示例 2:
输入:nums = [1,0,1,1,0,1]
输出:2
2
public int findMaxConsecutiveOnes(int[] nums) {
int maxCount = 0, count = 0;
int n = nums.length;
for (int i = 0; i < n; i++) {
if (nums[i] == 1) {
count ++;
}else {
maxCount = Math.max(maxCount, count);
count = 0;
}
}
maxCount = Math.max(maxCount, count);
return maxCount;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 492.构造矩形
作为一位web开发者, 懂得怎样去规划一个页面的尺寸是很重要的。 所以,现给定一个具体的矩形页面面积,你的任务是设计一个长度为 L 和宽度为 W 且满足以下要求的矩形的页面。要求:
- 你设计的矩形页面必须等于给定的目标面积。
- 宽度
W不应大于长度L,换言之,要求L >= W。 - 长度
L和宽度W之间的差距应当尽可能小。
返回一个 数组 [L, W],其中 L 和 W 是你按照顺序设计的网页的长度和宽度。
示例1:
输入: 4
输出: [2, 2]
解释: 目标面积是 4, 所有可能的构造方案有 [1,4], [2,2], [4,1]。
但是根据要求2,[1,4] 不符合要求; 根据要求3,[2,2] 比 [4,1] 更能符合要求. 所以输出长度 L 为 2, 宽度 W 为 2。
2
3
4
示例 2:
输入: area = 37
输出: [37,1]
2
示例 3:
输入: area = 122122
输出: [427,286]
2
public int[] constructRectangle(int area) {
int w = (int)Math.sqrt(area);
while (area % w != 0) {
--w;
}
return new int[]{area / w, w};
}
2
3
4
5
6
7
# 495.提莫攻击
在《英雄联盟》的世界中,有一个叫 “提莫” 的英雄。他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态。
当提莫攻击艾希,艾希的中毒状态正好持续 duration 秒。
正式地讲,提莫在 t 发起发起攻击意味着艾希在时间区间 [t, t + duration - 1](含 t 和 t + duration - 1)处于中毒状态。如果提莫在中毒影响结束 前 再次攻击,中毒状态计时器将会 重置 ,在新的攻击之后,中毒影响将会在 duration 秒后结束。
给你一个 非递减 的整数数组 timeSeries ,其中 timeSeries[i] 表示提莫在 timeSeries[i] 秒时对艾希发起攻击,以及一个表示中毒持续时间的整数 duration 。
返回艾希处于中毒状态的 总 秒数。
示例 1:
输入:timeSeries = [1,4], duration = 2
输出:4
解释:提莫攻击对艾希的影响如下:
- 第 1 秒,提莫攻击艾希并使其立即中毒。中毒状态会维持 2 秒,即第 1 秒和第 2 秒。
- 第 4 秒,提莫再次攻击艾希,艾希中毒状态又持续 2 秒,即第 4 秒和第 5 秒。
艾希在第 1、2、4、5 秒处于中毒状态,所以总中毒秒数是 4 。
2
3
4
5
6
示例 2:
输入:timeSeries = [1,2], duration = 2
输出:3
解释:提莫攻击对艾希的影响如下:
- 第 1 秒,提莫攻击艾希并使其立即中毒。中毒状态会维持 2 秒,即第 1 秒和第 2 秒。
- 第 2 秒,提莫再次攻击艾希,并重置中毒计时器,艾希中毒状态需要持续 2 秒,即第 2 秒和第 3 秒。
艾希在第 1、2、3 秒处于中毒状态,所以总中毒秒数是 3 。
2
3
4
5
6
public static int findPoisonedDuration(int[] timeSeries, int duration) {
int count = 0;
for (int i = 0; i < timeSeries.length - 1; i++) {
if (timeSeries[i+1] - timeSeries[i] >= duration) {
count += duration;
}else {
count += timeSeries[i+1] - timeSeries[i];
}
}
count += duration;
return count;
}
2
3
4
5
6
7
8
9
10
11
12
//答案解法
public int findPoisonedDuration2(int[] timeSeries, int duration) {
int ans = 0;
int expired = 0;
for (int i = 0; i < timeSeries.length; i++) {
if (timeSeries[i] >= expired) {
ans += duration;
} else {
ans += timeSeries[i] +duration - expired;
}
expired = timeSeries[i] + duration; // 技能效果消失时间
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 496.下一个更大元素
nums1 中数字 x 的 下一个更大元素 是指 x 在 nums2 中对应位置 右侧 的 第一个 比 x 大的元素。
给你两个 没有重复元素 的数组 nums1 和 nums2 ,下标从 0 开始计数,其中nums1 是 nums2 的子集。
对于每个 0 <= i < nums1.length ,找出满足 nums1[i] == nums2[j] 的下标 j ,并且在 nums2 确定 nums2[j] 的 下一个更大元素 。如果不存在下一个更大元素,那么本次查询的答案是 -1 。
返回一个长度为 nums1.length 的数组 ans 作为答案,满足 ans[i] 是如上所述的 下一个更大元素 。
示例 1:
输入:nums1 = [4,1,2], nums2 = [1,3,4,2].
输出:[-1,3,-1]
解释:nums1 中每个值的下一个更大元素如下所述:
- 4 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。
- 1 ,用加粗斜体标识,nums2 = [1,3,4,2]。下一个更大元素是 3 。
- 2 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。
2
3
4
5
6
示例 2:
输入:nums1 = [2,4], nums2 = [1,2,3,4].
输出:[3,-1]
解释:nums1 中每个值的下一个更大元素如下所述:
- 2 ,用加粗斜体标识,nums2 = [1,2,3,4]。下一个更大元素是 3 。
- 4 ,用加粗斜体标识,nums2 = [1,2,3,4]。不存在下一个更大元素,所以答案是 -1 。
2
3
4
5
提示:
1 <= nums1.length <= nums2.length <= 10000 <= nums1[i], nums2[i] <= 104nums1和nums2中所有整数 互不相同nums1中的所有整数同样出现在nums2中
public static int[] nextGreaterElement(int[] nums1, int[] nums2) {
int n = nums1.length, m = nums2.length,j;
int[] arr = new int[n];
for (int i = 0; i < n; i++) {
int a = nums1[i];
int k = 0;
boolean flag = false;
for (j = 0; j < nums2.length; j++) {
if (a == nums2[j]) {
k = j;
flag = true;
}
if (flag && nums2[j] > a && j > k) {
arr[i] = nums2[j];
break;
}
}
if (j == nums2.length) {
arr[i] = -1;
}
}
return arr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
答案方法一: 暴力
public int[] nextGreaterElement2(int[] nums1, int[] nums2) {
int m = nums1.length, n = nums2.length;
int[] res = new int[m];
for (int i = 0; i < m; i++) {
int j = 0;
// 先找到这个数
while (j < n && nums2[j] != nums1[i]) {
j++;
}
int k = j + 1;
while (k < n && nums2[k] < nums1[i]) {
k++;
}
res[i] = k < n ? nums2[k] : -1;
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
答案方法二:单调栈+哈希表
// 方法二:单调栈 + 哈希表
public int[] nextGreaterElement3(int[] nums1, int[] nums2) {
HashMap<Integer, Integer> map = new HashMap<>();
Deque<Integer> stack = new ArrayDeque<>();
// 计算 nums2中每个元素右边的第一个更大的值;
for (int i = nums2.length - 1; i >= 0 ; i--) {
int num = nums2[i];
while (!stack.isEmpty() &&num >= stack.peek()) {
stack.pop();
}
map.put(num, stack.isEmpty() ? -1 : stack.peek());
stack.push(num);
}
int [] res = new int[nums1.length];
for (int i = 0; i < nums1.length; i++) {
res[i] = map.get(nums1[i]);
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 500.键盘行
给你一个字符串数组 words ,只返回可以使用在 美式键盘 同一行的字母打印出来的单词。键盘如下图所示。
美式键盘 中:
- 第一行由字符
"qwertyuiop"组成。 - 第二行由字符
"asdfghjkl"组成。 - 第三行由字符
"zxcvbnm"组成。

示例 1:
输入:words = ["Hello","Alaska","Dad","Peace"]
输出:["Alaska","Dad"]
2
示例 2:
输入:words = ["omk"]
输出:[]
2
示例 3:
输入:words = ["adsdf","sfd"]
输出:["adsdf","sfd"]
2
public static String[] findWords(String[] words) {
ArrayList<String> arrayList = new ArrayList<>();
String str1 = "qwertyuiop";
String str2 = "asdfghjkl";
String str3 = "zxcvbnm";
for (String str: words) {
int count = 1, n =str.length();
if (n > 0) {
if (str1.indexOf(str.charAt(0)) != -1 || str1.indexOf(Character.toLowerCase(str.charAt(0))) != -1) {
for (int i = 1; i < n; i++) {
if (str1.indexOf(str.charAt(i)) != -1 || str1.indexOf(Character.toLowerCase(str.charAt(i))) != -1) {
count ++;
}else {
break;
}
}
if (count == n) {
arrayList.add(str);
}
}else if (str2.indexOf(str.charAt(0)) != -1 || str2.indexOf(Character.toLowerCase(str.charAt(0))) != -1) {
for (int i = 1; i < n; i++) {
if (str2.indexOf(str.charAt(i)) != -1 || str2.indexOf(Character.toLowerCase(str.charAt(i))) != -1) {
count ++;
}else {
break;
}
}
if (count == n) {
arrayList.add(str);
}
}else if (str3.indexOf(str.charAt(0)) != -1 || str3.indexOf(Character.toLowerCase(str.charAt(0))) != -1) {
for (int i = 1; i < n; i++) {
if (str3.indexOf(str.charAt(i)) != -1 || str3.indexOf(Character.toLowerCase(str.charAt(i))) != -1) {
count ++;
}else {
break;
}
}
if (count == n) {
arrayList.add(str);
}
}
}
}
return arrayList.toArray(new String[arrayList.size()]);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
答案解法:
public String[] findWords2(String[] words) {
ArrayList<String> arrayList = new ArrayList<>();
// abcdefg每个字母所占的行号
String rowIndex = "12210111011122000010020202";
for (String word : words) {
boolean isValid = true;
char idx = rowIndex.charAt(Character.toLowerCase(word.charAt(0)) - 'a');
for (int i = 0; i < word.length(); i++) {
if (rowIndex.charAt(Character.toLowerCase(word.charAt(i)) - 'a') != idx) {
isValid = false;
break;
}
}
if (isValid) {
arrayList.add(word);
}
}
return arrayList.toArray(new String[arrayList.size()]);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 501.二叉搜索树中的众数
给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数 (opens new window)(即,出现频率最高的元素)。
如果树中有不止一个众数,可以按 任意顺序 返回。
假定 BST 满足如下定义:
- 结点左子树中所含节点的值 小于等于 当前节点的值
- 结点右子树中所含节点的值 大于等于 当前节点的值
- 左子树和右子树都是二叉搜索树
示例 1:

输入:root = [1,null,2,2]
输出:[2]
2
示例 2:
输入:root = [0]
输出:[0]
2

int base, count, maxCount;
List<Integer> answer = new ArrayList<>();
public int[] findMode(TreeNode root) {
dfs(root);
int[] mode = new int[answer.size()];
for (int i = 0; i < answer.size(); i++) {
mode[i] = answer.get(i);
}
return mode;
}
// 二叉搜索树中序遍历是一个有序序列
public void dfs(TreeNode o) {
if (o == null) {
return;
}
dfs(o.left);
update(o.val);
dfs(o.right);
}
public void update(int x) {
if (x == base) {
count++;
} else {
count = 1;
base = x;
}
if (count == maxCount) {
answer.add(base);
}
if (count > maxCount) {
maxCount = count;
answer.clear();;
answer.add(base);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 504.七进制数
给定一个整数 num,将其转化为 7 进制,并以字符串形式输出。
示例 1:
输入: num = 100
输出: "202"
2
示例 2:
输入: num = -7
输出: "-10"
2
public String convertToBase7(int num) {
if (num == 0) {
return "0";
}
boolean negative = num < 0;
num = Math.abs(num);
StringBuffer digits = new StringBuffer();
while (num > 0) {
digits.append(num % 7);
num/=7;
}
if (negative) {
digits.append('-');
}
return digits.reverse().toString();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 506.相对名次
给你一个长度为 n 的整数数组 score ,其中 score[i] 是第 i 位运动员在比赛中的得分。所有得分都 互不相同 。
运动员将根据得分 决定名次 ,其中名次第 1 的运动员得分最高,名次第 2 的运动员得分第 2 高,依此类推。运动员的名次决定了他们的获奖情况:
- 名次第
1的运动员获金牌"Gold Medal"。 - 名次第
2的运动员获银牌"Silver Medal"。 - 名次第
3的运动员获铜牌"Bronze Medal"。 - 从名次第
4到第n的运动员,只能获得他们的名次编号(即,名次第x的运动员获得编号"x")。
使用长度为 n 的数组 answer 返回获奖,其中 answer[i] 是第 i 位运动员的获奖情况。
示例 1:
输入:score = [5,4,3,2,1]
输出:["Gold Medal","Silver Medal","Bronze Medal","4","5"]
解释:名次为 [1st, 2nd, 3rd, 4th, 5th] 。
2
3
示例 2:
输入:score = [10,3,8,9,4]
输出:["Gold Medal","5","Bronze Medal","Silver Medal","4"]
解释:名次为 [1st, 5th, 3rd, 2nd, 4th] 。
2
3
public String[] findRelativeRanks(int[] score) {
int n = score.length;
String[] desc = {"Gold Medal", "Silver Medal", "Bronze Medal"};
int[][] arr = new int[n][2];
for (int i = 0; i < n; i++) {
arr[i][0] = score[i];
arr[i][1] = i;
}
Arrays.sort(arr, (a,b) -> b[0] - a[0]);
String[] ans = new String[n];
for (int i = 0; i < n; i++) {
if (i >= 3) {
ans[arr[i][1]] = Integer.toString(i+1);
} else {
ans[arr[i][1]] = desc[i];
}
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 507.完美数
对于一个 正整数,如果它和除了它自身以外的所有 正因子 之和相等,我们称它为 「完美数」。
给定一个 整数 n, 如果是完美数,返回 true;否则返回 false。
示例 1:
输入:num = 28
输出:true
解释:28 = 1 + 2 + 4 + 7 + 14
1, 2, 4, 7, 和 14 是 28 的所有正因子。
2
3
4
示例 2:
输入:num = 7
输出:false
2
public static boolean checkPerfectNumber(int num) {
int res = 0;
for (int i = 1; i < num; i++) {
if (num % i == 0) {
res += i;
}
}
return num==res;
}
public boolean checkPerfectNumber2(int num) {
if (num == 1) {
return false;
}
int sum = 1;
for (int d = 2; d * d <= num ; d++) {
if (num % d == 0) {
sum += d;
if (d * d < num) {
sum += num / d;
}
}
}
return sum == num;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 509.斐波那契数
斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0,F(1) = 1
F(n) = F(n - 1) + F(n - 2),其中 n > 1
2
给定 n ,请计算 F(n) 。
示例 1:
输入:n = 2
输出:1
解释:F(2) = F(1) + F(0) = 1 + 0 = 1
2
3
示例 2:
输入:n = 3
输出:2
解释:F(3) = F(2) + F(1) = 1 + 1 = 2
2
3
示例 3:
输入:n = 4
输出:3
解释:F(4) = F(3) + F(2) = 2 + 1 = 3
2
3
public int fib(int n) {
if (n == 0) {
return 0;
}else if (n == 1) {
return 1;
}else {
return fib(n-1) + fib(n-2);
}
}
// 答案解法一:动态规划
public int fib2(int n) {
if (n < 2) {
return n;
}
int p = 0, q = 0, r = 1;
for (int i = 2; i <= n; i++) {
p = q;
q = r;
r = p + q;
}
return r;
}
// 答案解法二:矩阵快速幂
public int fib3(int n) {
if (n < 2) {
return n;
}
int [][] q = {{1,1}, {1,0}};
int [][] res = pow(q, n - 1);
return res[0][0];
}
public int[][] pow(int[][] a, int n) {
int[][] ret = {{1,0},{0,1}};
while (n > 0) {
if ((n & 1) == 1) {
ret = multiply(ret, a);
}
n >>= 1;
a = multiply(a, a);
}
return ret;
}
public int[][] multiply(int[][] a, int[][] b) {
int[][] c = new int[2][2];
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
c[i][j] = a[i][0] * b[0][j] + a[i][1] * b[1][j];
}
}
return c;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 520.检测大写字母
我们定义,在以下情况时,单词的大写用法是正确的:
- 全部字母都是大写,比如
"USA"。 - 单词中所有字母都不是大写,比如
"leetcode"。 - 如果单词不只含有一个字母,只有首字母大写, 比如
"Google"。
给你一个字符串 word 。如果大写用法正确,返回 true ;否则,返回 false 。
示例 1:
输入:word = "USA"
输出:true
2
示例 2:
输入:word = "FlaG"
输出:false
2
public static boolean detectCapitalUse(String word) {
// 若第一个字母为小写,则需要额外判断第2个字母是否为小写
if(word.length() >= 2 && Character.isLowerCase(word.charAt(0)) && Character.isUpperCase(word.charAt(1))) {
return false;
}
// 无论第一个字母是否大写,其他字母都必须与第2个字母的大小相同
for (int i = 2; i < word.length(); i++) {
// 异或相同为0, 相异为1
if (Character.isLowerCase(word.charAt(i)) ^ Character.isLowerCase(word.charAt(1))) {
return false;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 521.最长特殊序列 Ⅰ
给你两个字符串 a 和 b,请返回 这两个字符串中 最长的特殊序列 的长度。如果不存在,则返回 -1 。
「最长特殊序列」 定义如下:该序列为 某字符串独有的最长子序列(即不能是其他字符串的子序列) 。
字符串 s 的子序列是在从 s 中删除任意数量的字符后可以获得的字符串。
- 例如,
"abc"是"aebdc"的子序列,因为删除"a***e***b***d\***c"中斜体加粗的字符可以得到"abc"。"aebdc"的子序列还包括"aebdc"、"aeb"和""(空字符串)。
示例 1:
输入: a = "aba", b = "cdc"
输出: 3
解释: 最长特殊序列可为 "aba" (或 "cdc"),两者均为自身的子序列且不是对方的子序列。
2
3
示例 2:
输入:a = "aaa", b = "bbb"
输出:3
解释: 最长特殊序列是 "aaa" 和 "bbb" 。
2
3
示例 3:
输入:a = "aaa", b = "aaa"
输出:-1
解释: 字符串 a 的每个子序列也是字符串 b 的每个子序列。同样,字符串 b 的每个子序列也是字符串 a 的子序列。
2
3
public int findLUSlength(String a, String b) {
return !a.equals(b) ? Math.max(a.length(), b.length()) : -1;
}
2
3
# 530.二叉搜索树的最小绝对差
给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。
差值是一个正数,其数值等于两值之差的绝对值。
示例 1:

输入:root = [4,2,6,1,3]
输出:1
2
示例 2:

输入:root = [1,0,48,null,null,12,49]
输出:1
2
int pre;
int ans;
public int getMinimumDifference(TreeNode root) {
ans = Integer.MAX_VALUE;
pre = -1;
dfs(root);
return ans;
}
public void dfs(TreeNode root) {
if (root == null) {
return;
}
dfs(root.left);
if (pre == -1) {
pre = root.val;
} else {
ans = Math.min(ans, root.val - pre);
pre = root.val;
}
dfs(root.right);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 541.反转字符串 II
给定一个字符串 s 和一个整数 k,从字符串开头算起,每计数至 2k 个字符,就反转这 2k 字符中的前 k 个字符。
- 如果剩余字符少于
k个,则将剩余字符全部反转。 - 如果剩余字符小于
2k但大于或等于k个,则反转前k个字符,其余字符保持原样。
示例 1:
输入:s = "abcdefg", k = 2
输出:"bacdfeg"
2
示例 2:
输入:s = "abcd", k = 2
输出:"bacd"
2
public static String reverseStr(String s, int k) {
int length = s.length();
int k1 = length % (2*k); // 剩余字符个数
int end = length - k1;
char[] chars = s.toCharArray();
for (int i = 0; i < end / (2*k); i++) {
reverse(chars, 2*i*k,(2*i+1)*k-1);
}
if (k1 < k) { // 剩余字符小于k个,剩余字符全部反转
reverse(chars, end, length-1);
}else { // 反转前k个字符
reverse(chars, end, end+k-1);
}
return new String(chars);
}
// 反转字符串
public static void reverse( char[] s, int start, int end){
while (start < end) {
char c = s[start];
s[start] = s[end];
s[end] = c;
start++;
end--;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
答案解法:
// 反转字符串
public static void reverse( char[] s, int start, int end){
while (start < end) {
char c = s[start];
s[start] = s[end];
s[end] = c;
start++;
end--;
}
}
// 答案解法:
public String reverseStr2(String s, int k) {
int n = s.length();
char[] arr = s.toCharArray();
for (int i = 0; i < n; i += 2* k) {
reverse(arr, i,Math.min(i+k, n) -1);
}
return new String(arr);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 543.二叉树的直径
给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
示例 : 给定二叉树
1
/ \
2 3
/ \
4 5
2
3
4
5
返回 3, 它的长度是路径 [4,2,1,3] 或者 [5,2,1,3]。
**注意:**两结点之间的路径长度是以它们之间边的数目表示。
int ans;
public int diameterOfBinaryTree(TreeNode root) {
ans = 1;
depth(root);
return ans - 1;
}
public int depth(TreeNode node) {
if (node == null) {
return 0; // 访问到空节点,返回0
}
int L = depth(node.left); // 左儿子为根的子树的深度
int R = depth(node.right); // 右儿子为根的子树的深度
ans = Math.max(ans, L+R+1);
return Math.max(L,R) + 1; //返回该节点为根的子树的深度
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 551.学生出勤记录 I
给你一个字符串 s 表示一个学生的出勤记录,其中的每个字符用来标记当天的出勤情况(缺勤、迟到、到场)。记录中只含下面三种字符:
'A':Absent,缺勤'L':Late,迟到'P':Present,到场
如果学生能够 同时 满足下面两个条件,则可以获得出勤奖励:
- 按 总出勤 计,学生缺勤(
'A')严格 少于两天。 - 学生 不会 存在 连续 3 天或 连续 3 天以上的迟到(
'L')记录。
如果学生可以获得出勤奖励,返回 true ;否则,返回 false 。
示例 1:
输入:s = "PPALLP"
输出:true
解释:学生缺勤次数少于 2 次,且不存在 3 天或以上的连续迟到记录。
2
3
示例 2:
输入:s = "PPALLL"
输出:false
解释:学生最后三天连续迟到,所以不满足出勤奖励的条件。
2
3
public static boolean checkRecord(String s) {
int A_count = 0;
int L_count = 0;
for (int i = 0; i < s.length(); i++) {
if (s.charAt(i) == 'A') {
A_count++;
}
if (A_count >= 2) {
return false;
}
if (i < s.length() -1 && s.charAt(i) == s.charAt(i+1) && s.charAt(i) == 'L') {
L_count++;
}else {
L_count = 0;
}
if (L_count >= 2) {
return false;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
答案解法:
// 答案解法:
public boolean checkRecord2(String s) {
int absents = 0, lates = 0;
int n = s.length();
for (int i = 0; i < n; i++) {
char c = s.charAt(i);
if (c == 'A') {
absents++;
if (absents >= 2) {
return false;
}
}
if (c == 'L') {
lates ++;
if (lates >= 3) {
return false;
}
}else {
lates = 0;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 557.反转字符串中的单词 III
给定一个字符串 s ,你需要反转字符串中每个单词的字符顺序,同时仍保留空格和单词的初始顺序。
示例 1:
输入:s = "Let's take LeetCode contest"
输出:"s'teL ekat edoCteeL tsetnoc"
2
示例 2:
输入: s = "God Ding"
输出:"doG gniD"
2
public static String reverseWords(String s) {
char[] chars = s.toCharArray();
int j = 0;
for (int i = 0; i < chars.length; i++) {
if (chars[i] == ' ') {
reverse(chars, j, i-1);
j = i+1;
}
}
// 只有一个单词时候的逆转和最后一个单词的逆转
if (j == 0 || j < chars.length) {
reverse(chars, j, chars.length-1);
}
return new String(chars);
}
public static void reverse(char[] s, int left, int right) {
while (left < right) {
char c = s[left];
s[left] = s[right];
s[right] = c;
left++;
right--;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
答案解法:
// 答案解法一: 使用额外空间
public String reverseWords2(String s) {
StringBuffer ret = new StringBuffer();
int length = s.length();
int i = 0;
while (i < length) {
int start = i;
while (i < length && s.charAt(i) != ' ') {
i++;
}
// 逆序添加
for (int j = start; j < i; j++) {
ret.append(s.charAt(start + i -1 - j));
}
while (i < length && s.charAt(i) == ' ') {
i++;
ret.append(' ');
}
}
return ret.toString();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 559.N 叉树的最大深度
给定一个 N 叉树,找到其最大深度。
最大深度是指从根节点到最远叶子节点的最长路径上的节点总数。
N 叉树输入按层序遍历序列化表示,每组子节点由空值分隔(请参见示例)。
示例 1:

输入:root = [1,null,3,2,4,null,5,6]
输出:3
2
示例 2:
输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
输出:5
2
方法一:深度优先搜索
// 方法一: 深度优先搜索
public int maxDepth(Node root) {
if (root == null) {
return 0;
}
int maxChildDepth = 0;
List<Node> children = root.children;
for (Node node : children) {
int childDepth = maxDepth(node);
maxChildDepth = Math.max(maxChildDepth, childDepth);
}
return maxChildDepth + 1;
}
2
3
4
5
6
7
8
9
10
11
12
13
方法二:广度优先搜索
// 方法二:广度优先搜索
public int maxDepth2(Node root) {
if (root == null) {
return 0;
}
Queue<Node> queue = new LinkedList<>();
queue.offer(root);
int ans = 0;
while (!queue.isEmpty()) {
int size = queue.size();
while (size > 0) {
Node node = queue.poll();
List<Node> children = node.children;
for (Node child : children) {
queue.offer(child);
}
size--;
}
ans++;
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 561.数组拆分
给定长度为 2n 的整数数组 nums ,你的任务是将这些数分成 n 对, 例如 (a1, b1), (a2, b2), ..., (an, bn) ,使得从 1 到 n 的 min(ai, bi) 总和最大。
返回该 最大总和 。
示例 1:
输入:nums = [1,4,3,2]
输出:4
解释:所有可能的分法(忽略元素顺序)为:
1. (1, 4), (2, 3) -> min(1, 4) + min(2, 3) = 1 + 2 = 3
2. (1, 3), (2, 4) -> min(1, 3) + min(2, 4) = 1 + 2 = 3
3. (1, 2), (3, 4) -> min(1, 2) + min(3, 4) = 1 + 3 = 4
所以最大总和为 4
2
3
4
5
6
7
示例 2:
输入:nums = [6,2,6,5,1,2]
输出:9
解释:最优的分法为 (2, 1), (2, 5), (6, 6). min(2, 1) + min(2, 5) + min(6, 6) = 1 + 2 + 6 = 9
2
3
public static int arrayPairSum(int[] nums) {
Arrays.sort(nums);
int sum = 0;
for (int i = 0; i < nums.length; i+=2) {
sum += nums[i];
}
return sum;
}
2
3
4
5
6
7
8
# 563.二叉树的坡度
给你一个二叉树的根节点 root ,计算并返回 整个树 的坡度 。
一个树的 节点的坡度 定义即为,该节点左子树的节点之和和右子树节点之和的 差的绝对值 。如果没有左子树的话,左子树的节点之和为 0 ;没有右子树的话也是一样。空结点的坡度是 0 。
整个树 的坡度就是其所有节点的坡度之和。
示例 1:

输入:root = [1,2,3]
输出:1
解释:
节点 2 的坡度:|0-0| = 0(没有子节点)
节点 3 的坡度:|0-0| = 0(没有子节点)
节点 1 的坡度:|2-3| = 1(左子树就是左子节点,所以和是 2 ;右子树就是右子节点,所以和是 3 )
坡度总和:0 + 0 + 1 = 1
2
3
4
5
6
7
示例 2:

输入:root = [4,2,9,3,5,null,7]
输出:15
解释:
节点 3 的坡度:|0-0| = 0(没有子节点)
节点 5 的坡度:|0-0| = 0(没有子节点)
节点 7 的坡度:|0-0| = 0(没有子节点)
节点 2 的坡度:|3-5| = 2(左子树就是左子节点,所以和是 3 ;右子树就是右子节点,所以和是 5 )
节点 9 的坡度:|0-7| = 7(没有左子树,所以和是 0 ;右子树正好是右子节点,所以和是 7 )
节点 4 的坡度:|(3+5+2)-(9+7)| = |10-16| = 6(左子树值为 3、5 和 2 ,和是 10 ;右子树值为 9 和 7 ,和是 16 )
坡度总和:0 + 0 + 0 + 2 + 7 + 6 = 15
2
3
4
5
6
7
8
9
10
示例 3:

输入:root = [21,7,14,1,1,2,2,3,3]
输出:9
2
// 方法一: 深度优先搜索
int ans = 0;
public int findTilt(TreeNode root) {
dfs(root);
return ans;
}
public int dfs(TreeNode node) {
if (node == null) {
return 0;
}
int sumLeft = dfs(node.left);
int sumRight = dfs(node.right);
ans += Math.abs(sumLeft-sumRight);
return sumLeft + sumRight + node.val;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 566.重塑矩阵
在 MATLAB 中,有一个非常有用的函数 reshape ,它可以将一个 m x n 矩阵重塑为另一个大小不同(r x c)的新矩阵,但保留其原始数据。
给你一个由二维数组 mat 表示的 m x n 矩阵,以及两个正整数 r 和 c ,分别表示想要的重构的矩阵的行数和列数。
重构后的矩阵需要将原始矩阵的所有元素以相同的 行遍历顺序 填充。
如果具有给定参数的 reshape 操作是可行且合理的,则输出新的重塑矩阵;否则,输出原始矩阵。
示例 1:

输入:mat = [[1,2],[3,4]], r = 1, c = 4
输出:[[1,2,3,4]]
2
示例 2:

输入:mat = [[1,2],[3,4]], r = 2, c = 4
输出:[[1,2],[3,4]]
2
public int[][] matrixReshape(int[][] mat, int r, int c) {
int m = mat.length;
int n = mat[0].length;
if (m*n != r*c) {
return mat;
}
int[][] ans = new int[r][c];
for (int i = 0; i < m*n; i++) {
ans[i / c][i % c] = mat[i / n][i % n];
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
# 572.另一棵树的子树
给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。
二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所有后代节点。tree 也可以看做它自身的一棵子树。
示例 1:

输入:root = [3,4,5,1,2], subRoot = [4,1,2]
输出:true
2
示例 2:
输入:root = [3,4,5,1,2,null,null,null,null,0], subRoot = [4,1,2]
输出:false
2
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
return dfs(root , subRoot);
}
public boolean dfs(TreeNode root, TreeNode subRoot) {
if (root == null) {
return false;
}
return check(root,subRoot) || dfs(root.left, subRoot) || dfs(root.right, subRoot);
}
public boolean check(TreeNode root, TreeNode subRoot) {
if (root == null && subRoot == null) {
return true;
}
if (root== null || subRoot == null || root.val != subRoot.val) {
return false;
}
return check(root.left, subRoot.left) && check(root.right, subRoot.right);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 另外两种解法
// todo
# 575.分糖果
Alice 有 n 枚糖,其中第 i 枚糖的类型为 candyType[i] 。Alice 注意到她的体重正在增长,所以前去拜访了一位医生。
医生建议 Alice 要少摄入糖分,只吃掉她所有糖的 n / 2 即可(n 是一个偶数)。Alice 非常喜欢这些糖,她想要在遵循医生建议的情况下,尽可能吃到最多不同种类的糖。
给你一个长度为 n 的整数数组 candyType ,返回: Alice 在仅吃掉 n / 2 枚糖的情况下,可以吃到糖的 最多 种类数。
示例 1:
输入:candyType = [1,1,2,2,3,3]
输出:3
解释:Alice 只能吃 6 / 2 = 3 枚糖,由于只有 3 种糖,她可以每种吃一枚。
2
3
示例 2:
输入:candyType = [1,1,2,3]
输出:2
解释:Alice 只能吃 4 / 2 = 2 枚糖,不管她选择吃的种类是 [1,2]、[1,3] 还是 [2,3],她只能吃到两种不同类的糖。
2
3
示例 3:
输入:candyType = [6,6,6,6]
输出:1
解释:Alice 只能吃 4 / 2 = 2 枚糖,尽管她能吃 2 枚,但只能吃到 1 种糖。
2
3
提示:
n == candyType.length2 <= n <= 104n是一个偶数-105 <= candyType[i] <= 105
public static int distributeCandies(int[] candyType) {
int n = candyType.length;
int count = 1;
Arrays.sort(candyType);
for (int i = 0; i < n - 1; i++) {
if (candyType[i] != candyType[i+1]) {
count++;
}
}
return n / 2 <= count ? n/2 : count;
}
2
3
4
5
6
7
8
9
10
11
//答案解法
// 答案解法:
public int distributeCandies2(int[] candyType) {
HashSet<Integer> set = new HashSet<>();
for (int candy:candyType) {
set.add(candy);
}
return Math.min(set.size(),candyType.length/2);
}
2
3
4
5
6
7
8
# 589.N 叉树的前序遍历
给定一个 n 叉树的根节点 root ,返回 其节点值的 前序遍历 。
n 叉树 在输入中按层序遍历进行序列化表示,每组子节点由空值 null 分隔(请参见示例)。
示例 1:
输入:root = [1,null,3,2,4,null,5,6]
输出:[1,3,5,6,2,4]
2
示例 2:
输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
输出:[1,2,3,6,7,11,14,4,8,12,5,9,13,10]
2
提示:
- 节点总数在范围
[0, 104]内 0 <= Node.val <= 104- n 叉树的高度小于或等于
1000
// 方法一:递归
public List<Integer> preorder(Node root) {
List<Integer> res = new ArrayList<>();
helper(root, res);
return res;
}
public void helper(Node root, List<Integer> res) {
if (root == null) {
return;
}
res.add(root.val);
for (Node ch : root.children) {
helper(ch, res);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 方法二:迭代
public List<Integer> preorder2(Node root) {
ArrayList<Integer> res = new ArrayList<>();
if (root == null) {
return res;
}
ArrayDeque<Node> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()) {
Node node = stack.pop();
res.add(node.val);
for (int i = node.children.size() - 1; i >= 0 ; i--) {
stack.push(node.children.get(i));
}
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
\590. N 叉树的后序遍历
简单
273
相关企业
给定一个 n 叉树的根节点 root ,返回 其节点值的 后序遍历 。
n 叉树 在输入中按层序遍历进行序列化表示,每组子节点由空值 null 分隔(请参见示例)。
示例 1:
输入:root = [1,null,3,2,4,null,5,6]
输出:[5,6,3,2,4,1]
2
示例 2:
输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
输出:[2,6,14,11,7,3,12,8,4,13,9,10,5,1]
2
方法一:递归
// 方法一:递归
public List<Integer> postorder(Node root) {
ArrayList<Integer> list = new ArrayList<>();
dfs(root, list);
return list;
}
public void dfs(Node root, ArrayList<Integer> list) {
if (root == null) {
return;
}
for (Node node : root.children) {
dfs(node,list);
}
list.add(root.val);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
方法二:迭代
// 方法二:迭代
public List<Integer> postorder2(Node root) {
ArrayList<Integer> list = new ArrayList<>();
if (root == null) {
return list;
}
ArrayDeque<Node> stack = new ArrayDeque<>();
HashSet<Node> visited = new HashSet<>();
stack.push(root);
while (! stack.isEmpty()) {
// 取出栈顶元素
Node node = stack.peek();
/**如果当前节点为叶子结点或者当前节点的子节点已经遍历过*/
if (node.children.size() == 0 || visited.contains(node)) {
stack.pop();
list.add(node.val);
continue;
}
for (int i = node.children.size() - 1; i >= 0 ; i--) {
stack.push(node.children.get(i));
}
visited.add(node);
}
return list;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 594.最长和谐子序列
和谐数组是指一个数组里元素的最大值和最小值之间的差别 正好是 1 。
现在,给你一个整数数组 nums ,请你在所有可能的子序列中找到最长的和谐子序列的长度。
数组的子序列是一个由数组派生出来的序列,它可以通过删除一些元素或不删除元素、且不改变其余元素的顺序而得到。
示例 1:
输入:nums = [1,3,2,2,5,2,3,7]
输出:5
解释:最长的和谐子序列是 [3,2,2,2,3]
2
3
示例 2:
输入:nums = [1,2,3,4]
输出:2
2
示例 3:
输入:nums = [1,1,1,1]
输出:0
2
方法一:枚举
public int findLHS(int[] nums) {
Arrays.sort(nums);
int begin = 0;
int res = 0;
for (int end = 0; end < nums.length; end++) {
while (nums[end] - nums[begin] > 1) {
begin ++;
}
if (nums[end] - nums[begin] == 1) {
res = Math.max(res, end - begin + 1);
}
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
方法二:哈希表
public int findLHS2(int[] nums) {
HashMap<Integer, Integer> cnt = new HashMap<>();
int res = 0;
for (int num : nums) {
cnt.put(num, cnt.getOrDefault(num, 0) + 1);
}
for (int key : cnt.keySet()) {
if (cnt.containsKey(key + 1)) {
res = Math.max(res,cnt.get(key) + cnt.get(key+1));
}
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 598.范围求和 II
给你一个 m x n 的矩阵 M ,初始化时所有的 0 和一个操作数组 op ,其中 ops[i] = [ai, bi] 意味着当所有的 0 <= x < ai 和 0 <= y < bi 时, M[x][y] 应该加 1。
在 执行完所有操作后 ,计算并返回 矩阵中最大整数的个数 。
示例 1:

输入: m = 3, n = 3,ops = [[2,2],[3,3]]
输出: 4
解释: M 中最大的整数是 2, 而且 M 中有4个值为2的元素。因此返回 4。
2
3
示例 2:
输入: m = 3, n = 3, ops = [[2,2],[3,3],[3,3],[3,3],[2,2],[3,3],[3,3],[3,3],[2,2],[3,3],[3,3],[3,3]]
输出: 4
2
示例 3:
输入: m = 3, n = 3, ops = []
输出: 9
2
// 会超出内存限制
public static int maxCount(int m, int n, int[][] ops) {
int[][] M = new int[m][n];
int max = 0;
for (int i = 0; i < ops.length; i++) {
int a = ops[i][0], b = ops[i][1];
for (int j = 0; j < M.length; j++) {
for (int k = 0; k < M[j].length; k++) {
if (j < a && k < b) {
M[j][k] += 1;
if (M[j][k] > max) {
max = M[j][k];
}
}
}
}
}
int count = 0;
for (int j = 0; j < M.length; j++) {
for (int k = 0; k < M[j].length; k++) {
if (M[j][k] == max) {
count++;
}
}
}
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
///答案解法
// 答案解法:
public int maxCount2(int m, int n, int[][] ops) {
int mina = m, minb = n;
for (int[] op : ops) {
mina = Math.min(mina, op[0]);
minb = Math.min(minb,op[1]);
}
return mina * minb;
}
2
3
4
5
6
7
8
9
# 599.两个列表的最小索引总和
假设 Andy 和 Doris 想在晚餐时选择一家餐厅,并且他们都有一个表示最喜爱餐厅的列表,每个餐厅的名字用字符串表示。
你需要帮助他们用最少的索引和找出他们共同喜爱的餐厅。 如果答案不止一个,则输出所有答案并且不考虑顺序。 你可以假设答案总是存在。
示例 1:
输入: list1 = ["Shogun", "Tapioca Express", "Burger King", "KFC"],list2 = ["Piatti", "The Grill at Torrey Pines", "Hungry Hunter Steakhouse", "Shogun"]
输出: ["Shogun"]
解释: 他们唯一共同喜爱的餐厅是“Shogun”。
2
3
示例 2:
输入:list1 = ["Shogun", "Tapioca Express", "Burger King", "KFC"],list2 = ["KFC", "Shogun", "Burger King"]
输出: ["Shogun"]
解释: 他们共同喜爱且具有最小索引和的餐厅是“Shogun”,它有最小的索引和1(0+1)。
2
3
提示:
1 <= list1.length, list2.length <= 10001 <= list1[i].length, list2[i].length <= 30list1[i]和list2[i]由空格' '和英文字母组成。list1的所有字符串都是 唯一 的。list2中的所有字符串都是 唯一 的。
public static String[] findRestaurant(String[] list1, String[] list2) {
ArrayList<String> arrayList = new ArrayList<>();
HashMap<String, Integer> map = new HashMap<>();
for (int i = 0; i < list1.length; i++) {
map.put(list1[i],i);
}
int min = list1.length + list2.length - 2;
for (int i = 0; i < list2.length; i++) {
if (map.containsKey(list2[i])) {
if (map.get(list2[i]) + i < min) {
min = map.get(list2[i]) + i;
}
}
}
for (int i = 0; i < list2.length; i++) {
if (map.containsKey(list2[i]) && map.get(list2[i]) + i == min) {
arrayList.add(list2[i]);
}
}
return arrayList.toArray(new String[arrayList.size()]);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 答案解法
// 答案解法
public String[] findRestaurant2(String[] list1, String[] list2) {
HashMap<String, Integer> index = new HashMap<>();
for (int i = 0; i < list1.length; i++) {
index.put(list1[i], i);
}
ArrayList<String> ret = new ArrayList<>();
int indexSum = Integer.MAX_VALUE;
for (int i = 0; i < list2.length; i++) {
if (index.containsKey(list2[i])) {
int j = index.get(list2[i]);
if ( i + j < indexSum) {
ret.clear();
ret.add(list2[i]);
indexSum = i+j;
} else if (i + j == indexSum) {
ret.add(list2[i]);
}
}
}
return ret.toArray(new String[ret.size()]);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
\606. 根据二叉树创建字符串
简单
359
相关企业
给你二叉树的根节点 root ,请你采用前序遍历的方式,将二叉树转化为一个由括号和整数组成的字符串,返回构造出的字符串。
空节点使用一对空括号对 "()" 表示,转化后需要省略所有不影响字符串与原始二叉树之间的一对一映射关系的空括号对。
示例 1:
输入:root = [1,2,3,4]
输出:"1(2(4))(3)"
解释:初步转化后得到 "1(2(4)())(3()())" ,但省略所有不必要的空括号对后,字符串应该是"1(2(4))(3)" 。
2
3
示例 2:
输入:root = [1,2,3,null,4]
输出:"1(2()(4))(3)"
解释:和第一个示例类似,但是无法省略第一个空括号对,否则会破坏输入与输出一一映射的关系。
2
3
//解法一:递归
//方法一: 递归
public String tree2str(TreeNode root) {
if(root == null) {
return "";
}
if (root.left == null && root.right == null) {
return Integer.toString(root.val);
}
if (root.right == null) {
return new StringBuffer().append(root.val).append("(").append(tree2str(root.left)).append(")").toString();
}
return new StringBuffer().append(root.val).append("(").append(tree2str(root.left)).append(")(").append(tree2str(root.right)).append(")").toString();
}
2
3
4
5
6
7
8
9
10
11
12
13
//解法二:迭代
// 方法二: 迭代
public String tree2str2(TreeNode root) {
StringBuffer ans = new StringBuffer();
Deque<TreeNode> stack = new ArrayDeque<>();
stack.push(root);
HashSet<TreeNode> visited = new HashSet<>();
while (!stack.isEmpty()) {
TreeNode node = stack.peek();
if (!visited.add(node)) {
if (node != root) {
ans.append(")");
}
stack.pop();
} else {
if (node != root) {
ans.append("(");
}
ans.append(node.val);
if (node.left == null && node.right != null) {
ans.append("()");
}
if (node.right != null) {
stack.push(node.right);
}
if (node.left != null) {
stack.push(node.left);
}
}
}
return ans.toString();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 617.合并二叉树
给你两棵二叉树: root1 和 root2 。
想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
返回合并后的二叉树。
注意: 合并过程必须从两个树的根节点开始。
示例 1:

输入:root1 = [1,3,2,5], root2 = [2,1,3,null,4,null,7]
输出:[3,4,5,5,4,null,7]
2
示例 2:
输入:root1 = [1], root2 = [1,2]
输出:[2,2]
2
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
if (root1 == null) {
return root2;
}
if (root2 == null) {
return root1;
}
TreeNode merged = new TreeNode(root1.val + root2.val);
merged.left = mergeTrees(root1.left, root2.left);
merged.right = mergeTrees(root1.right, root2.right);
return merged;
}
2
3
4
5
6
7
8
9
10
11
12
public TreeNode mergeTrees2(TreeNode root1, TreeNode root2) {
if (root1 == null) {
return root2;
}
if (root2 == null) {
return root1;
}
TreeNode merged = new TreeNode(root1.val + root2.val);
Queue<TreeNode> queue = new LinkedList<>();
Queue<TreeNode> queue1 = new LinkedList<>();
Queue<TreeNode> queue2 = new LinkedList<>();
queue.offer(merged);
queue1.offer(root1);
queue2.offer(root2);
while (!queue1.isEmpty() && ! queue2.isEmpty()) {
TreeNode node = queue.poll(),node1 = queue1.poll(),node2 = queue2.poll();
TreeNode left1 = node1.left, right1 = node1.right,left2 = node2.left, right2 = node2.right;
if (left1 != null || left2!= null) {
if (left1 != null && left2 != null) {
TreeNode left = new TreeNode(left1.val + left2.val);
node.left = left;
queue.offer(left);
queue1.offer(left1);
queue2.offer(left2);
} else if (left1 != null) {
node.left = left1;
} else if (left2 != null) {
node.left = left2;
}
}
if (right1 != null || right2 != null) {
if (right1 != null && right2 != null) {
TreeNode right = new TreeNode(right1.val + right2.val);
node.right = right;
queue.offer(right);
queue1.offer(right1);
queue2.offer(right2);
} else if (right1 != null) {
node.right = right1;
} else {
node.right = right2;
}
}
}
return merged;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# 628.三个数的最大乘积
给你一个整型数组 nums ,在数组中找出由三个数组成的最大乘积,并输出这个乘积。
示例 1:
输入:nums = [1,2,3]
输出:6
2
示例 2:
输入:nums = [1,2,3,4]
输出:24
2
示例 3:
输入:nums = [-1,-2,-3]
输出:-6
2
提示:
3 <= nums.length <= 104-1000 <= nums[i] <= 1000
public int maximumProduct(int[] nums) {
//如果数组中全是非负数,则排序后最大的三个数相乘即为最大乘积;如果全是非正数,则最大的三个数相乘同样也为最大乘积。
//如果数组中有正数有负数,则最大乘积既可能是三个最大正数的乘积,也可能是两个最小负数(即绝对值最大)与最大正数的乘积。
Arrays.sort(nums);
int n = nums.length;
return Math.max(nums[0]*nums[1]*nums[n-1], nums[n-1]*nums[n-2]*nums[n-3]);
}
2
3
4
5
6
7
// 线性扫描
// 方法二:线性扫描
public int maxinumProduct2(int[] nums) {
// 最小的和第二小的
int min1 = Integer.MAX_VALUE, min2 = Integer.MAX_VALUE;
// 最大的,第二大的和第三大的
int max1 = Integer.MIN_VALUE, max2 = Integer.MIN_VALUE, max3 = Integer.MIN_VALUE;
for (int x : nums) {
if (x < min1) {
min2 = min1;
min1 = x;
}else if (x < min2) {
min2 = x;
}
if (x > max1) {
max3 = max2;
max2 = max1;
max1 = x;
}else if ( x > max2) {
max3 = max2;
max2 = x;
}else if ( x > max3) {
max3 = x;
}
}
return Math.max(min1 * min2 * max1, max1 * max2 * max3);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 637.二叉树的层平均值
给定一个非空二叉树的根节点 root , 以数组的形式返回每一层节点的平均值。与实际答案相差 10-5 以内的答案可以被接受。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:[3.00000,14.50000,11.00000]
解释:第 0 层的平均值为 3,第 1 层的平均值为 14.5,第 2 层的平均值为 11 。
因此返回 [3, 14.5, 11] 。
2
3
4
示例 2:

输入:root = [3,9,20,15,7]
输出:[3.00000,14.50000,11.00000]
2
提示:
- 树中节点数量在
[1, 104]范围内 -231 <= Node.val <= 231 - 1
// 广度优先搜索
public List<Double> averageOfLevels(TreeNode root) {
if (root == null) {
return null;
}
List<Double> doubles = new ArrayList<>();
Queue<TreeNode> queue = new ArrayDeque<>();
queue.offer(root);
while ( ! queue.isEmpty()) {
Double sum = 0.0;
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
sum += node.val;
TreeNode left = node.left, right = node.right;
if (left != null) {
queue.offer(left);
}
if (right != null) {
queue.offer(right);
}
}
doubles.add(sum / size );
}
return doubles;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 643.子数组最大平均数 I
给你一个由 n 个元素组成的整数数组 nums 和一个整数 k 。
请你找出平均数最大且 长度为 k 的连续子数组,并输出该最大平均数。
任何误差小于 10-5 的答案都将被视为正确答案。
示例 1:
输入:nums = [1,12,-5,-6,50,3], k = 4
输出:12.75
解释:最大平均数 (12-5-6+50)/4 = 51/4 = 12.75
2
3
示例 2:
输入:nums = [5], k = 1
输出:5.00000
2
// 会超出内存限制
public static double findMaxAverage(int[] nums, int k) {
Double max = new Double(Integer.MIN_VALUE);
for (int i = 0; i < nums.length - k + 1; i++) {
Double sum = 0.0;
for (int j = i; j < i+k; j++) {
sum += nums[j];
}
if (sum / k > max) {
max = sum / k;
}
}
return max;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
滑动窗口
// 答案解法:滑动窗口
public double findMaxAverage2(int[] nums, int k) {
int sum = 0;
int n = nums.length;
for (int i = 0; i < k; i++) {
sum += nums[i];
}
int maxSum = sum;
for (int i = k; i < n; i++) {
sum = sum - nums[i - k] + nums[i];
maxSum = Math.max(maxSum, sum);
}
return 1.0*maxSum / k;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 645.错误的集合
集合 s 包含从 1 到 n 的整数。不幸的是,因为数据错误,导致集合里面某一个数字复制了成了集合里面的另外一个数字的值,导致集合 丢失了一个数字 并且 有一个数字重复 。
给定一个数组 nums 代表了集合 S 发生错误后的结果。
请你找出重复出现的整数,再找到丢失的整数,将它们以数组的形式返回。
示例 1:
输入:nums = [1,2,2,4]
输出:[2,3]
2
示例 2:
输入:nums = [1,1]
输出:[1,2]
2
public static int[] findErrorNums(int[] nums) {
int[] res = new int[2];
HashMap<Integer, Integer> hashMap = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
hashMap.put(nums[i],hashMap.getOrDefault(nums[i],0) + 1);
}
for (int i = 1; i <= nums.length; i++) {
if (hashMap.containsKey(i)) {
if (hashMap.get(i) == 2) {
res[0] = i;
}
}else {
res[1] = i;
}
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
排序
// 排序
public int[] findErrorNums2(int[] nums) {
int[] errorNums = new int[2];
int n = nums.length;
Arrays.sort(nums);
int prev = 0;
for (int i = 0; i < n; i++) {
int curr = nums[i];
if (curr == prev) {
errorNums[0] = prev;
}else if (curr - prev > 1) {
errorNums[1] = prev + 1;
}
prev = curr;
}
if (nums[n-1] != n) {
errorNums[1] = n;
}
return errorNums;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 653.两数之和 IV - 输入二叉搜索树
给定一个二叉搜索树 root 和一个目标结果 k,如果二叉搜索树中存在两个元素且它们的和等于给定的目标结果,则返回 true。
示例 1:
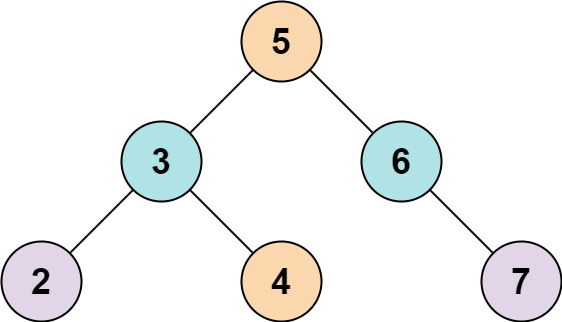
输入: root = [5,3,6,2,4,null,7], k = 9
输出: true
2
示例 2:
输入: root = [5,3,6,2,4,null,7], k = 28
输出: false
2
深度优先搜索
HashSet<Integer> set = new HashSet<>();
public boolean findTarget(TreeNode root, int k) {
if (root == null) {
return false;
}
if (set.contains(k - root.val)) {
return true;
}
set.add(root.val);
return findTarget(root.left,k) || findTarget(root.right, k);
}
2
3
4
5
6
7
8
9
10
11
广度优先搜索
// 广度优选搜索
public boolean findTarget2(TreeNode root, int k) {
HashSet<Integer> set = new HashSet<>();
ArrayDeque<TreeNode> queue = new ArrayDeque<>();
queue.offer(root);
while (! queue.isEmpty()) {
TreeNode node = queue.poll();
if (set.contains(k - node.val)) {
return true;
}
set.add(node.val);
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 661.图片平滑器
图像平滑器 是大小为 3 x 3 的过滤器,用于对图像的每个单元格平滑处理,平滑处理后单元格的值为该单元格的平均灰度。
每个单元格的 平均灰度 定义为:该单元格自身及其周围的 8 个单元格的平均值,结果需向下取整。(即,需要计算蓝色平滑器中 9 个单元格的平均值)。
如果一个单元格周围存在单元格缺失的情况,则计算平均灰度时不考虑缺失的单元格(即,需要计算红色平滑器中 4 个单元格的平均值)。

给你一个表示图像灰度的 m x n 整数矩阵 img ,返回对图像的每个单元格平滑处理后的图像 。
示例 1:
输入:img = [[1,1,1],[1,0,1],[1,1,1]]
输出:[[0, 0, 0],[0, 0, 0], [0, 0, 0]]
解释:
对于点 (0,0), (0,2), (2,0), (2,2): 平均(3/4) = 平均(0.75) = 0
对于点 (0,1), (1,0), (1,2), (2,1): 平均(5/6) = 平均(0.83333333) = 0
对于点 (1,1): 平均(8/9) = 平均(0.88888889) = 0
2
3
4
5
6
示例 2:
输入: img = [[100,200,100],[200,50,200],[100,200,100]]
输出: [[137,141,137],[141,138,141],[137,141,137]]
解释:
对于点 (0,0), (0,2), (2,0), (2,2): floor((100+200+200+50)/4) = floor(137.5) = 137
对于点 (0,1), (1,0), (1,2), (2,1): floor((200+200+50+200+100+100)/6) = floor(141.666667) = 141
对于点 (1,1): floor((50+200+200+200+200+100+100+100+100)/9) = floor(138.888889) = 138
2
3
4
5
6
提示:
m == img.lengthn == img[i].length1 <= m, n <= 2000 <= img[i][j] <= 255
public int[][] imageSmoother(int[][] img) {
int m = img.length;
int n = img[0].length;
int[][] results = new int[m][n];
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
int sum = 0;
int count = 0;
for (int x = i-1; x <= i+1; x++) {
for (int y = j-1; y <= j+1; y++) {
if (x >=0 && x < m && y >=0 && y < n ) {
sum+=img[x][y];
count++;
}
}
}
results[i][j] = sum / count;
}
}
return results;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 671.二叉树中第二小的节点
给定一个非空特殊的二叉树,每个节点都是正数,并且每个节点的子节点数量只能为 2 或 0。如果一个节点有两个子节点的话,那么该节点的值等于两个子节点中较小的一个。
更正式地说,即 root.val = min(root.left.val, root.right.val) 总成立。
给出这样的一个二叉树,你需要输出所有节点中的 第二小的值 。
如果第二小的值不存在的话,输出 -1 。
示例 1:

输入:root = [2,2,5,null,null,5,7]
输出:5
解释:最小的值是 2 ,第二小的值是 5 。
2
3
示例 2:

输入:root = [2,2,2]
输出:-1
解释:最小的值是 2, 但是不存在第二小的值。
2
3
提示:
- 树中节点数目在范围
[1, 25]内 1 <= Node.val <= 231 - 1- 对于树中每个节点
root.val == min(root.left.val, root.right.val)
int ans;int rootValue;
// 二叉树根节点的值即为所有节点中的最小值。
public int findSecondMinimumValue(TreeNode root) {
ans = -1;
rootValue = root.val;
dfs(root);
return ans;
}
public void dfs(TreeNode node) {
if (node == null) {
return;
}
if (ans != -1 && node.val >= ans) {
return;
}
if (node.val > rootValue) {
ans = node.val;
}
dfs(node.left);
dfs(node.right);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 674.最长连续递增序列
给定一个未经排序的整数数组,找到最长且 连续递增的子序列,并返回该序列的长度。
连续递增的子序列 可以由两个下标 l 和 r(l < r)确定,如果对于每个 l <= i < r,都有 nums[i] < nums[i + 1] ,那么子序列 [nums[l], nums[l + 1], ..., nums[r - 1], nums[r]] 就是连续递增子序列。
示例 1:
输入:nums = [1,3,5,4,7]
输出:3
解释:最长连续递增序列是 [1,3,5], 长度为3。
尽管 [1,3,5,7] 也是升序的子序列, 但它不是连续的,因为 5 和 7 在原数组里被 4 隔开。
2
3
4
示例 2:
输入:nums = [2,2,2,2,2]
输出:1
解释:最长连续递增序列是 [2], 长度为1。
2
3
public static int findLengthOfLCIS(int[] nums) {
int n = nums.length;
int count = 1;
int max = 0;
for (int i = 0; i < n; i++) {
if ( i+1 < n && nums[i] < nums[i+1]) {
count++;
}else {
count = 1;
}
if (count > max) {
max = count;
}
}
return max;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
答案解法:
// 答案解法:
public int findLengthOfLCIS2(int[] nums) {
int ans = 0;
int n = nums.length;
int start = 0;
for (int i = 0; i < n; i++) {
if (i > 0 && nums[i] <= nums[i-1]) {
start = i;
}
ans = Math.max(ans, i - start + 1);
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 680.验证回文串 II
给你一个字符串 s,最多 可以从中删除一个字符。
请你判断 s 是否能成为回文字符串:如果能,返回 true ;否则,返回 false 。
示例 1:
输入:s = "aba"
输出:true
2
示例 2:
输入:s = "abca"
输出:true
解释:你可以删除字符 'c' 。
2
3
示例 3:
输入:s = "abc"
输出:false
2
public boolean validPalindrome(String s) {
int low = 0, high = s.length() - 1;
while (low < high) {
char c1 = s.charAt(low), c2 = s.charAt(high);
if (c1 == c2) {
++low;
--high;
} else {
return validPalindrome(s, low, high -1) || validPalindrome(s, low +1, high);
}
}
return true;
}
public boolean validPalindrome(String s, int low, int high){
for (int i = low, j = high; i < j; ++i,--j) {
char c1 = s.charAt(i), c2 = s.charAt(j);
if (c1 != c2) {
return false;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 682.棒球比赛
你现在是一场采用特殊赛制棒球比赛的记录员。这场比赛由若干回合组成,过去几回合的得分可能会影响以后几回合的得分。
比赛开始时,记录是空白的。你会得到一个记录操作的字符串列表 ops,其中 ops[i] 是你需要记录的第 i 项操作,ops 遵循下述规则:
- 整数
x- 表示本回合新获得分数x "+"- 表示本回合新获得的得分是前两次得分的总和。题目数据保证记录此操作时前面总是存在两个有效的分数。"D"- 表示本回合新获得的得分是前一次得分的两倍。题目数据保证记录此操作时前面总是存在一个有效的分数。"C"- 表示前一次得分无效,将其从记录中移除。题目数据保证记录此操作时前面总是存在一个有效的分数。
请你返回记录中所有得分的总和。
示例 1:
输入:ops = ["5","2","C","D","+"]
输出:30
解释:
"5" - 记录加 5 ,记录现在是 [5]
"2" - 记录加 2 ,记录现在是 [5, 2]
"C" - 使前一次得分的记录无效并将其移除,记录现在是 [5].
"D" - 记录加 2 * 5 = 10 ,记录现在是 [5, 10].
"+" - 记录加 5 + 10 = 15 ,记录现在是 [5, 10, 15].
所有得分的总和 5 + 10 + 15 = 30
2
3
4
5
6
7
8
9
示例 2:
输入:ops = ["5","-2","4","C","D","9","+","+"]
输出:27
解释:
"5" - 记录加 5 ,记录现在是 [5]
"-2" - 记录加 -2 ,记录现在是 [5, -2]
"4" - 记录加 4 ,记录现在是 [5, -2, 4]
"C" - 使前一次得分的记录无效并将其移除,记录现在是 [5, -2]
"D" - 记录加 2 * -2 = -4 ,记录现在是 [5, -2, -4]
"9" - 记录加 9 ,记录现在是 [5, -2, -4, 9]
"+" - 记录加 -4 + 9 = 5 ,记录现在是 [5, -2, -4, 9, 5]
"+" - 记录加 9 + 5 = 14 ,记录现在是 [5, -2, -4, 9, 5, 14]
所有得分的总和 5 + -2 + -4 + 9 + 5 + 14 = 27
2
3
4
5
6
7
8
9
10
11
12
示例 3:
输入:ops = ["1"]
输出:1
2
public static int calPoints(String[] operations) {
int ret = 0;
ArrayList<Integer> list = new ArrayList<>();
for (String op : operations) {
int n = list.size();
switch (op.charAt(0)) {
case '+':
ret += list.get(n-1) + list.get(n-2);
list.add(list.get(n-1) + list.get(n-2));
break;
case 'D':
ret += 2*list.get(n-1);
list.add(2*list.get(n-1));
break;
case 'C':
ret -= list.get(n-1);
list.remove(n-1);
break;
default:
ret += Integer.parseInt(op);
list.add(Integer.parseInt(op));
break;
}
}
return ret;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 693.交替位二进制数
给定一个正整数,检查它的二进制表示是否总是 0、1 交替出现:换句话说,就是二进制表示中相邻两位的数字永不相同。
示例 1:
输入:n = 5
输出:true
解释:5 的二进制表示是:101
2
3
示例 2:
输入:n = 7
输出:false
解释:7 的二进制表示是:111.
2
3
示例 3:
输入:n = 11
输出:false
解释:11 的二进制表示是:1011.
2
3
// 方法一: 模拟
public boolean hasAlternatingBits(int n) {
int prev= 2;
while (n != 0) {
int cur = n % 2;
if (cur == prev) {
return false;
}
prev = cur;
n/=2;
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
// 位运算
// 方法二: 位运算
public boolean hasAlternatingBits2(int n) {
int a = n ^ (n >> 1); // a的二进制位全为1
return (a & (a + 1)) == 0;
}
2
3
4
5
# 696.计数二进制子串
给定一个字符串 s,统计并返回具有相同数量 0 和 1 的非空(连续)子字符串的数量,并且这些子字符串中的所有 0 和所有 1 都是成组连续的。
重复出现(不同位置)的子串也要统计它们出现的次数。
示例 1:
输入:s = "00110011"
输出:6
解释:6 个子串满足具有相同数量的连续 1 和 0 :"0011"、"01"、"1100"、"10"、"0011" 和 "01" 。
注意,一些重复出现的子串(不同位置)要统计它们出现的次数。
另外,"00110011" 不是有效的子串,因为所有的 0(还有 1 )没有组合在一起。
2
3
4
5
示例 2:
输入:s = "10101"
输出:4
解释:有 4 个子串:"10"、"01"、"10"、"01" ,具有相同数量的连续 1 和 0 。
2
3

public int countBinarySubstrings(String s) {
int ptr =0, n = s.length(), last = 0, ans = 0;
while (ptr < n) {
char c = s.charAt(ptr);
int count = 0;
while (ptr < n && s.charAt(ptr) == c) {
ptr++;
count++;
}
ans += Math.min(count, last);
last = count;
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 697.数组的度
给定一个非空且只包含非负数的整数数组 nums,数组的 度 的定义是指数组里任一元素出现频数的最大值。
你的任务是在 nums 中找到与 nums 拥有相同大小的度的最短连续子数组,返回其长度。
示例 1:
输入:nums = [1,2,2,3,1]
输出:2
解释:
输入数组的度是 2 ,因为元素 1 和 2 的出现频数最大,均为 2 。
连续子数组里面拥有相同度的有如下所示:
[1, 2, 2, 3, 1], [1, 2, 2, 3], [2, 2, 3, 1], [1, 2, 2], [2, 2, 3], [2, 2]
最短连续子数组 [2, 2] 的长度为 2 ,所以返回 2 。
2
3
4
5
6
7
示例 2:
输入:nums = [1,2,2,3,1,4,2]
输出:6
解释:
数组的度是 3 ,因为元素 2 重复出现 3 次。
所以 [2,2,3,1,4,2] 是最短子数组,因此返回 6 。
2
3
4
5
提示:
nums.length在1到50,000范围内。nums[i]是一个在0到49,999范围内的整数。
public int findShortestSubArray(int[] nums) {
// 数组第一个值,出现的次数,第二个开始的索引,第三个值最后的索引
HashMap<Integer, int[]> map = new HashMap<>();
int n = nums.length;
for (int i = 0; i < n; i++) {
if (map.containsKey(nums[i])) {
map.get(nums[i])[0]++;
map.get(nums[i])[2] = i;
} else {
map.put(nums[i], new int[]{1,i,i});
}
}
int maxNum = 0, minLen = 0;
for (Map.Entry<Integer, int[]> entry : map.entrySet()) {
int[] arr = entry.getValue();
if (maxNum < arr[0]) {
maxNum = arr[0];
minLen = arr[2] - arr[1] + 1;
} else if (maxNum == arr[0]) {
if (minLen > arr[2] - arr[1] + 1) {
minLen = arr[2] - arr[1] + 1;
}
}
}
return minLen;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 700.二叉搜索树中的搜索
给定二叉搜索树(BST)的根节点 root 和一个整数值 val。
你需要在 BST 中找到节点值等于 val 的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 null 。
示例 1:

输入:root = [4,2,7,1,3], val = 2
输出:[2,1,3]
2
示例 2:

输入:root = [4,2,7,1,3], val = 5
输出:[]
2
提示:
- 数中节点数在
[1, 5000]范围内 1 <= Node.val <= 107root是二叉搜索树1 <= val <= 107
public TreeNode searchBST(TreeNode root, int val) {
if (root == null) {
return null;
}
if (root.val == val) {
return root;
}else if (root.val < val) {
return searchBST(root.right,val);
}else{
return searchBST(root.left, val);
}
}
2
3
4
5
6
7
8
9
10
11
12
// 迭代
// 方法二: 迭代
public TreeNode searchBST2(TreeNode root,int val) {
while (root != null) {
if (val == root.val) {
return root;
}
root = val < root.val ? root.left: root.right;
}
return null;
}
2
3
4
5
6
7
8
9
10
# 703.数据流中的第 K 大元素
设计一个找到数据流中第 k 大元素的类(class)。注意是排序后的第 k 大元素,不是第 k 个不同的元素。
请实现 KthLargest 类:
KthLargest(int k, int[] nums)使用整数k和整数流nums初始化对象。int add(int val)将val插入数据流nums后,返回当前数据流中第k大的元素。
示例:
输入:
["KthLargest", "add", "add", "add", "add", "add"]
[[3, [4, 5, 8, 2]], [3], [5], [10], [9], [4]]
输出:
[null, 4, 5, 5, 8, 8]
解释:
KthLargest kthLargest = new KthLargest(3, [4, 5, 8, 2]);
kthLargest.add(3); // return 4
kthLargest.add(5); // return 5
kthLargest.add(10); // return 5
kthLargest.add(9); // return 8
kthLargest.add(4); // return 8
2
3
4
5
6
7
8
9
10
11
12
13
提示:
1 <= k <= 1040 <= nums.length <= 104-104 <= nums[i] <= 104-104 <= val <= 104- 最多调用
add方法104次 - 题目数据保证,在查找第
k大元素时,数组中至少有k个元素
class KthLargest{
PriorityQueue<Integer> pq;
int k;
public KthLargest(int k, int[] nums) {
this.k = k;
pq = new PriorityQueue<Integer>();
for(int x: nums) {
add(x);
}
}
public int add(int val) {
pq.offer(val);
if (pq.size() > k) {
pq.poll();
}
return pq.peek();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# PriorityQueue(堆)
默认为小顶堆
应用场景:动态集合,会频繁加入删除元素,要求快速取出集合里面的最小值。
# 704.二分查找
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
2
3
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2
输出: -1
解释: 2 不存在 nums 中因此返回 -1
2
3
提示:
- 你可以假设
nums中的所有元素是不重复的。 n将在[1, 10000]之间。nums的每个元素都将在[-9999, 9999]之间。
public static int search(int[] nums, int target) {
int start = 0, end = nums.length-1;
while (start <= end ) {
int mid = start + (end - start) / 2;
if (nums[mid] == target ) {
return mid;
} else if (nums[mid] < target) {
start = mid + 1;
} else {
end = mid - 1;
}
}
return -1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 705.设计哈希集合
不使用任何内建的哈希表库设计一个哈希集合(HashSet)。
实现 MyHashSet 类:
void add(key)向哈希集合中插入值key。bool contains(key)返回哈希集合中是否存在这个值key。void remove(key)将给定值key从哈希集合中删除。如果哈希集合中没有这个值,什么也不做。
示例:
输入:
["MyHashSet", "add", "add", "contains", "contains", "add", "contains", "remove", "contains"]
[[], [1], [2], [1], [3], [2], [2], [2], [2]]
输出:
[null, null, null, true, false, null, true, null, false]
解释:
MyHashSet myHashSet = new MyHashSet();
myHashSet.add(1); // set = [1]
myHashSet.add(2); // set = [1, 2]
myHashSet.contains(1); // 返回 True
myHashSet.contains(3); // 返回 False ,(未找到)
myHashSet.add(2); // set = [1, 2]
myHashSet.contains(2); // 返回 True
myHashSet.remove(2); // set = [1]
myHashSet.contains(2); // 返回 False ,(已移除)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16


class MyHashSet {
private static final int BASE = 769;
private LinkedList[] data;
public MyHashSet() {
data = new LinkedList[BASE];
for (int i = 0; i < BASE; i++) {
data[i] = new LinkedList<Integer>();
}
}
public void add(int key) {
int h = hash(key);
Iterator<Integer> iterator = data[h].iterator();
while (iterator.hasNext()) {
Integer element = iterator.next();
if (element == key) {
return;
}
}
data[h].offerLast(key);
}
public void remove(int key) {
int h = hash(key);
Iterator<Integer> iterator = data[h].iterator();
while (iterator.hasNext()) {
Integer element = iterator.next();
if (element == key) {
data[h].remove(element);
return;
}
}
}
public boolean contains(int key) {
int h = hash(key);
Iterator<Integer> iterator = data[h].iterator();
while (iterator.hasNext()) {
Integer element = iterator.next();
if (element == key) {
return true;
}
}
return false;
}
// private static int hash(int key) {
private int hash(int key) {
return key % BASE;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 706.设计哈希映射
不使用任何内建的哈希表库设计一个哈希映射(HashMap)。
实现 MyHashMap 类:
MyHashMap()用空映射初始化对象void put(int key, int value)向 HashMap 插入一个键值对(key, value)。如果key已经存在于映射中,则更新其对应的值value。int get(int key)返回特定的key所映射的value;如果映射中不包含key的映射,返回-1。void remove(key)如果映射中存在key的映射,则移除key和它所对应的value。
示例:
输入:
["MyHashMap", "put", "put", "get", "get", "put", "get", "remove", "get"]
[[], [1, 1], [2, 2], [1], [3], [2, 1], [2], [2], [2]]
输出:
[null, null, null, 1, -1, null, 1, null, -1]
解释:
MyHashMap myHashMap = new MyHashMap();
myHashMap.put(1, 1); // myHashMap 现在为 [[1,1]]
myHashMap.put(2, 2); // myHashMap 现在为 [[1,1], [2,2]]
myHashMap.get(1); // 返回 1 ,myHashMap 现在为 [[1,1], [2,2]]
myHashMap.get(3); // 返回 -1(未找到),myHashMap 现在为 [[1,1], [2,2]]
myHashMap.put(2, 1); // myHashMap 现在为 [[1,1], [2,1]](更新已有的值)
myHashMap.get(2); // 返回 1 ,myHashMap 现在为 [[1,1], [2,1]]
myHashMap.remove(2); // 删除键为 2 的数据,myHashMap 现在为 [[1,1]]
myHashMap.get(2); // 返回 -1(未找到),myHashMap 现在为 [[1,1]]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
提示:
0 <= key, value <= 106- 最多调用
104次put、get和remove方法
class MyHashMap {
private class Pair {
private int key;
private int val;
public Pair(int key, int val) {
this.key = key;
this.val = val;
}
public int getKey() {
return key;
}
public int getVal() {
return val;
}
public void setVal(int val) {
this.val = val;
}
}
private static final int BASE = 769;
private LinkedList[] data;
public MyHashMap() {
data = new LinkedList[BASE];
for (int i = 0; i < BASE; i++) {
data[i] = new LinkedList<Pair>();
}
}
public void put(int key, int value) {
int h = hash(key);
Iterator<Pair> iterator = data[h].iterator();
while (iterator.hasNext()) {
Pair pair = iterator.next();
if (pair.getKey() == key) {
pair.setVal(value);
return;
}
}
data[h].offerLast(new Pair(key, value));
}
public int get(int key) {
int h = hash(key);
Iterator<Pair> iterator = data[h].iterator();
while (iterator.hasNext()) {
Pair pair = iterator.next();
if (pair.getKey() == key) {
return pair.getVal();
}
}
return -1;
}
public void remove(int key) {
int h = hash(key);
Iterator<Pair> iterator = data[h].iterator();
while (iterator.hasNext()) {
Pair pair = iterator.next();
if (pair.getKey() == key) {
data[h].remove(pair);
return;
}
}
}
private int hash(int key) {
return key % BASE;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
# 709.转换成小写字母
给你一个字符串 s ,将该字符串中的大写字母转换成相同的小写字母,返回新的字符串。
示例 1:
输入:s = "Hello"
输出:"hello"
2
示例 2:
输入:s = "here"
输出:"here"
2
示例 3:
输入:s = "LOVELY"
输出:"lovely"
2
提示:
1 <= s.length <= 100s由 ASCII 字符集中的可打印字符组成

public static String toLowerCase(String s) {
char[] chars = s.toCharArray();
for (int i = 0; i < chars.length; i++) {
if (chars[i] >= 'A' && chars[i] <= 'Z') {
// chars[i] += 32;
chars[i] |= 32;
}
}
return new String(chars);
}
2
3
4
5
6
7
8
9
10
# 724.寻找数组的中心下标
给你一个整数数组 nums ,请计算数组的 中心下标 。
数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。
如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点对于中心下标位于数组最右端同样适用。
如果数组有多个中心下标,应该返回 最靠近左边 的那一个。如果数组不存在中心下标,返回 -1 。
示例 1:
输入:nums = [1, 7, 3, 6, 5, 6]
输出:3
解释:
中心下标是 3 。
左侧数之和 sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11 ,
右侧数之和 sum = nums[4] + nums[5] = 5 + 6 = 11 ,二者相等。
2
3
4
5
6
示例 2:
输入:nums = [1, 2, 3]
输出:-1
解释:
数组中不存在满足此条件的中心下标。
2
3
4
示例 3:
输入:nums = [2, 1, -1]
输出:0
解释:
中心下标是 0 。
左侧数之和 sum = 0 ,(下标 0 左侧不存在元素),
右侧数之和 sum = nums[1] + nums[2] = 1 + -1 = 0 。
2
3
4
5
6
public int pivotIndex(int[] nums) {
int total = Arrays.stream(nums).sum();
int sum = 0;
for (int i = 0; i < nums.length; i++) {
if (2*sum + nums[i] == total) {
return i;
}
sum += nums[i];
}
return -1;
}
2
3
4
5
6
7
8
9
10
11
# 728.自除数
自除数 是指可以被它包含的每一位数整除的数。
- 例如,
128是一个 自除数 ,因为128 % 1 == 0,128 % 2 == 0,128 % 8 == 0。
自除数 不允许包含 0 。
给定两个整数 left 和 right ,返回一个列表,列表的元素是范围 [left, right] 内所有的 自除数 。
示例 1:
输入:left = 1, right = 22
输出:[1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 12, 15, 22]
2
示例 2:
输入:left = 47, right = 85
输出:[48,55,66,77]
2
public List<Integer> selfDividingNumbers(int left, int right) {
ArrayList<Integer> list = new ArrayList<>();
boolean flag = false;
for (int i = left; i <= right; i++) {
flag = true;
int sum = i;
while (sum != 0) {
int k = sum % 10;
if (k == 0 || i % k != 0) {
flag = false;
break;
}
sum /= 10;
}
if (flag) {
list.add(i);
}
}
return list;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 733.图像渲染
有一幅以 m x n 的二维整数数组表示的图画 image ,其中 image[i][j] 表示该图画的像素值大小。
你也被给予三个整数 sr , sc 和 newColor 。你应该从像素 image[sr][sc] 开始对图像进行 上色填充 。
为了完成 上色工作 ,从初始像素开始,记录初始坐标的 上下左右四个方向上 像素值与初始坐标相同的相连像素点,接着再记录这四个方向上符合条件的像素点与他们对应 四个方向上 像素值与初始坐标相同的相连像素点,……,重复该过程。将所有有记录的像素点的颜色值改为 newColor 。
最后返回 经过上色渲染后的图像 。
示例 1:
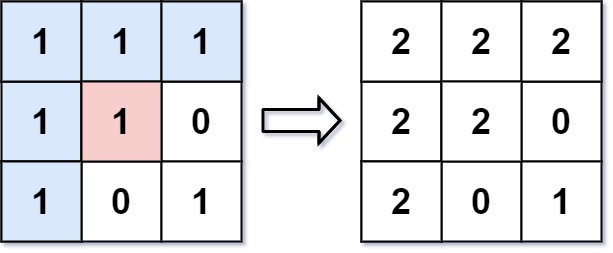
输入: image = [[1,1,1],[1,1,0],[1,0,1]],sr = 1, sc = 1, newColor = 2
输出: [[2,2,2],[2,2,0],[2,0,1]]
解析: 在图像的正中间,(坐标(sr,sc)=(1,1)),在路径上所有符合条件的像素点的颜色都被更改成2。
注意,右下角的像素没有更改为2,因为它不是在上下左右四个方向上与初始点相连的像素点。
2
3
4
示例 2:
输入: image = [[0,0,0],[0,0,0]], sr = 0, sc = 0, newColor = 2
输出: [[2,2,2],[2,2,2]]
2
提示:
m == image.lengthn == image[i].length1 <= m, n <= 500 <= image[i][j], newColor < 2160 <= sr < m0 <= sc < n
// 广度优先搜索方法
int[] dx = {1, 0, 0, -1};
int[] dy = {0, 1, -1, 0};
// 广度优先搜索
public int[][] floodFill(int[][] image, int sr, int sc, int color) {
int currentColor = image[sr][sc];
if (currentColor == color) {
return image;
}
int n = image.length, m = image[0].length;
LinkedList<int[]> queue = new LinkedList<>();
queue.offer(new int[]{sr, sc});
image[sr][sc] = color;
while (!queue.isEmpty()) {
int[] cell = queue.poll();
int x = cell[0], y = cell[1];
for (int i = 0; i < 4; i++) {
int mx = x + dx[i], my = y + dy[i];
if (mx >= 0 && mx < n && my >= 0 && my < m && image[mx][my] == currentColor) {
queue.offer(new int[]{mx,my});
image[mx][my] = color;
}
}
}
return image;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// 深度优先搜索
// 深度优先搜索
public int[][] floodFill2(int[][] image, int sr, int sc, int color) {
int currentColor = image[sr][sc];
if (currentColor != color) {
dfs(image, sr, sc, currentColor, color);
}
return image;
}
public void dfs(int[][] image, int x, int y,int currentColor, int color) {
if (image[x][y] == currentColor) {
image[x][y] = color;
for (int i = 0; i < 4; i++) {
int mx = x + dx[i], my = y + dy[i];
if (mx >= 0 && mx < image.length && my >= 0 && my < image[0].length) {
dfs(image,mx,my,currentColor,color);
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 744.寻找比目标字母大的最小字母
给你一个字符数组 letters,该数组按非递减顺序排序,以及一个字符 target。letters 里至少有两个不同的字符。
返回 letters 中大于 target 的最小的字符。如果不存在这样的字符,则返回 letters 的第一个字符。
示例 1:
输入: letters = ["c", "f", "j"],target = "a"
输出: "c"
解释:letters 中字典上比 'a' 大的最小字符是 'c'。
2
3
示例 2:
输入: letters = ["c","f","j"], target = "c"
输出: "f"
解释:letters 中字典顺序上大于 'c' 的最小字符是 'f'。
2
3
示例 3:
输入: letters = ["x","x","y","y"], target = "z"
输出: "x"
解释:letters 中没有一个字符在字典上大于 'z',所以我们返回 letters[0]。
2
3
提示:
2 <= letters.length <= 104letters[i]是一个小写字母letters按非递减顺序排序letters最少包含两个不同的字母target是一个小写字母
// 顺序查找
public static char nextGreatestLetter(char[] letters, char target) {
for (int i = 0; i < letters.length; i++) {
char ch = letters[i];
if (ch > target) {
return ch;
}
}
return letters[0];
}
2
3
4
5
6
7
8
9
// 二分查找
// 二分查找
public static char nextGreatestLetter2(char[] letters, char target) {
int n = letters.length;
int left = 0, right = n - 1;
if (target >= letters[right]) {
return letters[left];
}
while (left < right) {
int mid = left + (right - left) / 2;
if (letters[mid] > target) {
right = mid;
}else {
left = mid + 1;
}
}
return letters[left];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 746.使用最小花费爬楼梯
给你一个整数数组 cost ,其中 cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。
你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。
请你计算并返回达到楼梯顶部的最低花费。
示例 1:
输入:cost = [10,15,20]
输出:15
解释:你将从下标为 1 的台阶开始。
- 支付 15 ,向上爬两个台阶,到达楼梯顶部。
总花费为 15 。
2
3
4
5
示例 2:
输入:cost = [1,100,1,1,1,100,1,1,100,1]
输出:6
解释:你将从下标为 0 的台阶开始。
- 支付 1 ,向上爬两个台阶,到达下标为 2 的台阶。
- 支付 1 ,向上爬两个台阶,到达下标为 4 的台阶。
- 支付 1 ,向上爬两个台阶,到达下标为 6 的台阶。
- 支付 1 ,向上爬一个台阶,到达下标为 7 的台阶。
- 支付 1 ,向上爬两个台阶,到达下标为 9 的台阶。
- 支付 1 ,向上爬一个台阶,到达楼梯顶部。
总花费为 6 。
2
3
4
5
6
7
8
9
10
提示:
2 <= cost.length <= 10000 <= cost[i] <= 999
# 数据库
# 182.查找重复的电子邮箱
编写一个 SQL 查询,查找 Person 表中所有重复的电子邮箱。
示例:
+----+---------+
| Id | Email |
+----+---------+
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
+----+---------+
2
3
4
5
6
7
根据以上输入,你的查询应返回以下结果:
+---------+
| Email |
+---------+
| a@b.com |
+---------+
2
3
4
5
**说明:**所有电子邮箱都是小写字母。
SELECT DISTINCT
p1.Email
FROM
Person p1
WHERE
p1.Email IN (
SELECT
Email
FROM
Person
WHERE
Id != p1.Id)
2
3
4
5
6
7
8
9
10
11
12
方法一:使用 GROUP BY 和临时表
SELECT
Email
FROM
( SELECT Email, count( Email ) AS num FROM Person GROUP BY Email ) AS statistic
WHERE
num > 1;
2
3
4
5
6
方法二:使用 GROUP BY 和 HAVING 条件
SELECT
Email
FROM
Person
GROUP BY
Email
HAVING
count( Email ) > 1;
2
3
4
5
6
7
8
# 197.上升的温度
表: Weather
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| recordDate | date |
| temperature | int |
+---------------+---------+
id 是这个表的主键
该表包含特定日期的温度信息
2
3
4
5
6
7
8
9
编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 id 。
返回结果 不要求顺序 。
查询结果格式如下例。
示例 1:
输入:
Weather 表:
+----+------------+-------------+
| id | recordDate | Temperature |
+----+------------+-------------+
| 1 | 2015-01-01 | 10 |
| 2 | 2015-01-02 | 25 |
| 3 | 2015-01-03 | 20 |
| 4 | 2015-01-04 | 30 |
+----+------------+-------------+
输出:
+----+
| id |
+----+
| 2 |
| 4 |
+----+
解释:
2015-01-02 的温度比前一天高(10 -> 25)
2015-01-04 的温度比前一天高(20 -> 30)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
答案
SELECT
a.id
FROM
Weather a
JOIN weather b ON DATEDIFF( a.recordDate, b.recordDate ) = 1
WHERE
a.temperature > b.temperature
2
3
4
5
6
7
SELECT
a.id
FROM
Weather a
JOIN weather b ON TIMESTAMPDIFF(day, a.recordDate, b.recordDate ) = -1
WHERE
a.temperature > b.temperature
2
3
4
5
6
7
# timestampdiff()函数与datediff()函数的使用
1.timestampdiff()函数的作用是返回两个日期时间之间的整数差。而datediff()函数的作用也是返回两个日期值之差。
它们的函数语法分别为:
==TIMESTAMPDIFF(unit,datetime_expr1,datetime_expr2)==
==DATEDIFF(expr1,expr2)==
由于TIMESTAMPDIFF可返回两个日期时间的小时差、月份差和年份差,因此第一个参数可取hour\day\month\year等参数。
用datediff(expr1,expr2)函数计算2020-10-19与2021-10-18的日期值,注意当参数expr1>expr2时,返回的日期值为正,当参数expr1<expr2时,返回的日期值为负。
而TIMESTAMPDIFF()函数正好与datediff(expr1,expr2)函数相反,当datetime_expr1>datetime_expr2时,返回的值为负,当datetime_expr1<datetime_expr2时,返回的值为正。
# 511.游戏玩法分析 I
活动表 Activity:
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| player_id | int |
| device_id | int |
| event_date | date |
| games_played | int |
+--------------+---------+
表的主键是 (player_id, event_date)。
这张表展示了一些游戏玩家在游戏平台上的行为活动。
每行数据记录了一名玩家在退出平台之前,当天使用同一台设备登录平台后打开的游戏的数目(可能是 0 个)。
2
3
4
5
6
7
8
9
10
11
写一条 SQL 查询语句获取每位玩家 第一次登陆平台的日期。
查询结果的格式如下所示:
Activity 表:
+-----------+-----------+------------+--------------+
| player_id | device_id | event_date | games_played |
+-----------+-----------+------------+--------------+
| 1 | 2 | 2016-03-01 | 5 |
| 1 | 2 | 2016-05-02 | 6 |
| 2 | 3 | 2017-06-25 | 1 |
| 3 | 1 | 2016-03-02 | 0 |
| 3 | 4 | 2018-07-03 | 5 |
+-----------+-----------+------------+--------------+
Result 表:
+-----------+-------------+
| player_id | first_login |
+-----------+-------------+
| 1 | 2016-03-01 |
| 2 | 2017-06-25 |
| 3 | 2016-03-02 |
+-----------+-------------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
SELECT
player_id,
min( event_date ) first_login
FROM
Activity
GROUP BY
player_id
2
3
4
5
6
7
# 577.员工奖金
选出所有 bonus < 1000 的员工的 name 及其 bonus。
Employee 表单
+-------+--------+-----------+--------+
| empId | name | supervisor| salary |
+-------+--------+-----------+--------+
| 1 | John | 3 | 1000 |
| 2 | Dan | 3 | 2000 |
| 3 | Brad | null | 4000 |
| 4 | Thomas | 3 | 4000 |
+-------+--------+-----------+--------+
empId 是这张表单的主关键字
2
3
4
5
6
7
8
9
Bonus 表单
+-------+-------+
| empId | bonus |
+-------+-------+
| 2 | 500 |
| 4 | 2000 |
+-------+-------+
empId 是这张表单的主关键字
2
3
4
5
6
7
输出示例:
+-------+-------+
| name | bonus |
+-------+-------+
| John | null |
| Dan | 500 |
| Brad | null |
+-------+-------+
2
3
4
5
6
7
SELECT
name,
bonus
FROM
Employee e
LEFT JOIN Bonus b ON e.empId = b.empId
WHERE
ISNULL( bonus )
OR bonus < 1000;
2
3
4
5
6
7
8
9
# 584.寻找用户推荐人
SQL Schema
给定表 customer ,里面保存了所有客户信息和他们的推荐人。
+------+------+-----------+
| id | name | referee_id|
+------+------+-----------+
| 1 | Will | NULL |
| 2 | Jane | NULL |
| 3 | Alex | 2 |
| 4 | Bill | NULL |
| 5 | Zack | 1 |
| 6 | Mark | 2 |
+------+------+-----------+
2
3
4
5
6
7
8
9
10
写一个查询语句,返回一个客户列表,列表中客户的推荐人的编号都 不是 2。
对于上面的示例数据,结果为:
+------+
| name |
+------+
| Will |
| Jane |
| Bill |
| Zack |
+------+
2
3
4
5
6
7
8
SELECT NAME
FROM
customer
WHERE
referee_id != 2
OR referee_id is NULL
#或者
SELECT NAME
FROM
customer
WHERE
referee_id <> 2
OR referee_id is NULL
2
3
4
5
6
7
8
9
10
11
12
13
14
15
注意 :
select name from customer where referee_id != 2这种写法是错误的MySQL 使用三值逻辑 —— TRUE, FALSE 和 UNKNOWN。任何与
NULL值进行的比较都会与第三种值 UNKNOWN 做比较。这个“任何值”包括NULL本身!这就是为什么 MySQL 提供IS NULL和IS NOT NULL两种操作来对NULL特殊判断。提示
下面的解法同样是错误的,错误原因同上。避免错误的秘诀在于使用
IS NULL或者IS NOT NULL两种操作来对 NULL 值做特殊判断。SELECT name FROM customer WHERE referee_id = NULL OR referee_id <> 2;1
# 586.订单最多的客户
表: Orders
+-----------------+----------+
| Column Name | Type |
+-----------------+----------+
| order_number | int |
| customer_number | int |
+-----------------+----------+
Order_number是该表的主键。
此表包含关于订单ID和客户ID的信息。
2
3
4
5
6
7
8
编写一个SQL查询,为下了 最多订单 的客户查找 customer_number 。
测试用例生成后, 恰好有一个客户 比任何其他客户下了更多的订单。
查询结果格式如下所示。
示例 1:
输入:
Orders 表:
+--------------+-----------------+
| order_number | customer_number |
+--------------+-----------------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 3 |
+--------------+-----------------+
输出:
+-----------------+
| customer_number |
+-----------------+
| 3 |
+-----------------+
解释:
customer_number 为 '3' 的顾客有两个订单,比顾客 '1' 或者 '2' 都要多,因为他们只有一个订单。
所以结果是该顾客的 customer_number ,也就是 3 。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
进阶: 如果有多位顾客订单数并列最多,你能找到他们所有的 customer_number 吗?
SELECT
customer_number
FROM
Orders
GROUP BY
customer_number
ORDER BY
count( 0 ) DESC
LIMIT 1
2
3
4
5
6
7
8
9
# 595.大的国家
World 表:
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| name | varchar |
| continent | varchar |
| area | int |
| population | int |
| gdp | int |
+-------------+---------+
name 是这张表的主键。
这张表的每一行提供:国家名称、所属大陆、面积、人口和 GDP 值。
2
3
4
5
6
7
8
9
10
11
如果一个国家满足下述两个条件之一,则认为该国是 大国 :
- 面积至少为 300 万平方公里(即,
3000000 km2),或者 - 人口至少为 2500 万(即
25000000)
编写一个 SQL 查询以报告 大国 的国家名称、人口和面积。
按 任意顺序 返回结果表。
查询结果格式如下例所示。
示例:
输入:
World 表:
+-------------+-----------+---------+------------+--------------+
| name | continent | area | population | gdp |
+-------------+-----------+---------+------------+--------------+
| Afghanistan | Asia | 652230 | 25500100 | 20343000000 |
| Albania | Europe | 28748 | 2831741 | 12960000000 |
| Algeria | Africa | 2381741 | 37100000 | 188681000000 |
| Andorra | Europe | 468 | 78115 | 3712000000 |
| Angola | Africa | 1246700 | 20609294 | 100990000000 |
+-------------+-----------+---------+------------+--------------+
输出:
+-------------+------------+---------+
| name | population | area |
+-------------+------------+---------+
| Afghanistan | 25500100 | 652230 |
| Algeria | 37100000 | 2381741 |
+-------------+------------+---------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
SELECT
name,
population,
area
FROM
World
WHERE
area >= 3000000
OR population >= 25000000
2
3
4
5
6
7
8
9
解法二:使用union
SELECT
name,
population,
area
FROM
World
WHERE
area > 3000000 UNION
SELECT
NAME,
population,
area
FROM
World
WHERE
population > 25000000
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
注:方法二 比 方法一 运行速度更快,但是它们没有太大差别。
# 596.超过5名学生的课
表: Courses
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| student | varchar |
| class | varchar |
+-------------+---------+
(student, class)是该表的主键列。
该表的每一行表示学生的名字和他们注册的班级。
2
3
4
5
6
7
8
编写一个SQL查询来报告 至少有5个学生 的所有班级。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入:
Courses table:
+---------+----------+
| student | class |
+---------+----------+
| A | Math |
| B | English |
| C | Math |
| D | Biology |
| E | Math |
| F | Computer |
| G | Math |
| H | Math |
| I | Math |
+---------+----------+
输出:
+---------+
| class |
+---------+
| Math |
+---------+
解释:
-数学课有6个学生,所以我们包括它。
-英语课有1名学生,所以我们不包括它。
-生物课有1名学生,所以我们不包括它。
-计算机课有1个学生,所以我们不包括它。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
方法一:使用GROUP BY和 HAVING 条件
SELECT
class
FROM
Courses
GROUP BY
class
HAVING
count(DISTINCT student) >=5
2
3
4
5
6
7
8
方法二: 使用 GROUP BY 子句和子查询
SELECT
class
FROM
( SELECT class, COUNT( DISTINCT student ) AS num FROM Courses GROUP BY class ) AS temp_table
WHERE
num >= 5;
2
3
4
5
6
# 607.销售员
表: SalesPerson
+-----------------+---------+
| Column Name | Type |
+-----------------+---------+
| sales_id | int |
| name | varchar |
| salary | int |
| commission_rate | int |
| hire_date | date |
+-----------------+---------+
sales_id 是该表的主键列。
该表的每一行都显示了销售人员的姓名和 ID ,以及他们的工资、佣金率和雇佣日期。
2
3
4
5
6
7
8
9
10
11
表: Company
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| com_id | int |
| name | varchar |
| city | varchar |
+-------------+---------+
com_id 是该表的主键列。
该表的每一行都表示公司的名称和 ID ,以及公司所在的城市。
2
3
4
5
6
7
8
9
表: Orders
+-------------+------+
| Column Name | Type |
+-------------+------+
| order_id | int |
| order_date | date |
| com_id | int |
| sales_id | int |
| amount | int |
+-------------+------+
order_id 是该表的主键列。
com_id 是 Company 表中 com_id 的外键。
sales_id 是来自销售员表 sales_id 的外键。
该表的每一行包含一个订单的信息。这包括公司的 ID 、销售人员的 ID 、订单日期和支付的金额。
2
3
4
5
6
7
8
9
10
11
12
13
编写一个SQL查询,报告没有任何与名为 “RED” 的公司相关的订单的所有销售人员的姓名。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例:
输入:
SalesPerson 表:
+----------+------+--------+-----------------+------------+
| sales_id | name | salary | commission_rate | hire_date |
+----------+------+--------+-----------------+------------+
| 1 | John | 100000 | 6 | 4/1/2006 |
| 2 | Amy | 12000 | 5 | 5/1/2010 |
| 3 | Mark | 65000 | 12 | 12/25/2008 |
| 4 | Pam | 25000 | 25 | 1/1/2005 |
| 5 | Alex | 5000 | 10 | 2/3/2007 |
+----------+------+--------+-----------------+------------+
Company 表:
+--------+--------+----------+
| com_id | name | city |
+--------+--------+----------+
| 1 | RED | Boston |
| 2 | ORANGE | New York |
| 3 | YELLOW | Boston |
| 4 | GREEN | Austin |
+--------+--------+----------+
Orders 表:
+----------+------------+--------+----------+--------+
| order_id | order_date | com_id | sales_id | amount |
+----------+------------+--------+----------+--------+
| 1 | 1/1/2014 | 3 | 4 | 10000 |
| 2 | 2/1/2014 | 4 | 5 | 5000 |
| 3 | 3/1/2014 | 1 | 1 | 50000 |
| 4 | 4/1/2014 | 1 | 4 | 25000 |
+----------+------------+--------+----------+--------+
输出:
+------+
| name |
+------+
| Amy |
| Mark |
| Alex |
+------+
解释:
根据表 orders 中的订单 '3' 和 '4' ,容易看出只有 'John' 和 'Pam' 两个销售员曾经向公司 'RED' 销售过。
所以我们需要输出表 salesperson 中所有其他人的名字。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
SELECT NAME
FROM
SalesPerson
WHERE
sales_id NOT IN (
SELECT
sales_id
FROM
Orders
WHERE
com_id = ( SELECT com_id FROM Company WHERE NAME = 'RED' )
)
2
3
4
5
6
7
8
9
10
11
12
使用 OUTER JOIN 和 NOT IN
SELECT
s.NAME
FROM
Salesperson s
WHERE
s.sales_id NOT IN (
SELECT
o.sales_id
FROM
orders o
LEFT JOIN Company c ON o.com_id = c.com_id
WHERE
c.NAME = 'RED'
)
2
3
4
5
6
7
8
9
10
11
12
13
14
# 619.只出现一次的最大数字
MyNumbers 表:
+-------------+------+
| Column Name | Type |
+-------------+------+
| num | int |
+-------------+------+
这张表没有主键。可能包含重复数字。
这张表的每一行都含有一个整数。
2
3
4
5
6
7
单一数字 是在 MyNumbers 表中只出现一次的数字。
请你编写一个 SQL 查询来报告最大的 单一数字 。如果不存在 单一数字 ,查询需报告 null 。
查询结果如下例所示。
示例 1:
输入:
MyNumbers 表:
+-----+
| num |
+-----+
| 8 |
| 8 |
| 3 |
| 3 |
| 1 |
| 4 |
| 5 |
| 6 |
+-----+
输出:
+-----+
| num |
+-----+
| 6 |
+-----+
解释:单一数字有 1、4、5 和 6 。
6 是最大的单一数字,返回 6 。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
示例 2:
输入:
MyNumbers table:
+-----+
| num |
+-----+
| 8 |
| 8 |
| 7 |
| 7 |
| 3 |
| 3 |
| 3 |
+-----+
输出:
+------+
| num |
+------+
| null |
+------+
解释:输入的表中不存在单一数字,所以返回 null 。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
SELECT
MAX( num ) num
FROM
( SELECT num FROM MyNumbers GROUP BY num HAVING count(*) = 1 ) t;
2
3
4
# 620.有趣的电影
某城市开了一家新的电影院,吸引了很多人过来看电影。该电影院特别注意用户体验,专门有个 LED显示板做电影推荐,上面公布着影评和相关电影描述。
作为该电影院的信息部主管,您需要编写一个 SQL查询,找出所有影片描述为非 boring (不无聊) 的并且 id 为奇数 的影片,结果请按等级 rating 排列。
例如,下表 cinema:
+---------+-----------+--------------+-----------+
| id | movie | description | rating |
+---------+-----------+--------------+-----------+
| 1 | War | great 3D | 8.9 |
| 2 | Science | fiction | 8.5 |
| 3 | irish | boring | 6.2 |
| 4 | Ice song | Fantacy | 8.6 |
| 5 | House card| Interesting| 9.1 |
+---------+-----------+--------------+-----------+
2
3
4
5
6
7
8
9
对于上面的例子,则正确的输出是为:
+---------+-----------+--------------+-----------+
| id | movie | description | rating |
+---------+-----------+--------------+-----------+
| 5 | House card| Interesting| 9.1 |
| 1 | War | great 3D | 8.9 |
+---------+-----------+--------------+-----------+
2
3
4
5
6
SELECT
*
FROM
cinema
WHERE
description != 'boring'
AND ( id % 2 ) = 1
ORDER BY
rating DESC
2
3
4
5
6
7
8
9
使用 MOD() 函数
SELECT
*
FROM
cinema
WHERE
description != 'boring'
AND MOD ( id, 2 )= 1
ORDER BY
rating DESC
2
3
4
5
6
7
8
9
# 627.变更性别
Salary 表:
+-------------+----------+
| Column Name | Type |
+-------------+----------+
| id | int |
| name | varchar |
| sex | ENUM |
| salary | int |
+-------------+----------+
id 是这个表的主键。
sex 这一列的值是 ENUM 类型,只能从 ('m', 'f') 中取。
本表包含公司雇员的信息。
2
3
4
5
6
7
8
9
10
11
请你编写一个 SQL 查询来交换所有的 'f' 和 'm' (即,将所有 'f' 变为 'm' ,反之亦然),仅使用 单个 update 语句 ,且不产生中间临时表。
注意,你必须仅使用一条 update 语句,且 不能 使用 select 语句。
查询结果如下例所示。
示例 1:
输入:
Salary 表:
+----+------+-----+--------+
| id | name | sex | salary |
+----+------+-----+--------+
| 1 | A | m | 2500 |
| 2 | B | f | 1500 |
| 3 | C | m | 5500 |
| 4 | D | f | 500 |
+----+------+-----+--------+
输出:
+----+------+-----+--------+
| id | name | sex | salary |
+----+------+-----+--------+
| 1 | A | f | 2500 |
| 2 | B | m | 1500 |
| 3 | C | f | 5500 |
| 4 | D | m | 500 |
+----+------+-----+--------+
解释:
(1, A) 和 (3, C) 从 'm' 变为 'f' 。
(2, B) 和 (4, D) 从 'f' 变为 'm' 。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
方法:使用 UPDATE 和 CASE...WHEN
UPDATE Salary
SET sex =
CASE
sex
WHEN 'm' THEN
'f' ELSE 'm' END;
2
3
4
5
6
IF
UPDATE Salary
SET sex =
IF(sex = 'm','f','m')
2
3
IF(expr1,expr2,expr3);如果expr1为TRUE,则IF()返回值为expr2,否则返回值为expr3
UPDATE Salary
SET sex =
CASE
sex
WHEN 'm' THEN
'f'
WHEN 'f' THEN
'm' ELSE sex END;
2
3
4
5
6
7
8
# 1050.合作过至少三次的演员和导演
ActorDirector 表:
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| actor_id | int |
| director_id | int |
| timestamp | int |
+-------------+---------+
timestamp 是这张表的主键.
2
3
4
5
6
7
8
写一条SQL查询语句获取合作过至少三次的演员和导演的 id 对 (actor_id, director_id)
示例:
ActorDirector 表:
+-------------+-------------+-------------+
| actor_id | director_id | timestamp |
+-------------+-------------+-------------+
| 1 | 1 | 0 |
| 1 | 1 | 1 |
| 1 | 1 | 2 |
| 1 | 2 | 3 |
| 1 | 2 | 4 |
| 2 | 1 | 5 |
| 2 | 1 | 6 |
+-------------+-------------+-------------+
Result 表:
+-------------+-------------+
| actor_id | director_id |
+-------------+-------------+
| 1 | 1 |
+-------------+-------------+
唯一的 id 对是 (1, 1),他们恰好合作了 3 次。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
GROUP BY 与 COUNT(*)
SELECT
actor_id,
director_id
FROM
ActorDirector
GROUP BY
actor_id,
director_id
HAVING
count(*) >= 3
2
3
4
5
6
7
8
9
10
# 1068.产品销售分析 I
销售表 Sales:
+-------------+-------+
| Column Name | Type |
+-------------+-------+
| sale_id | int |
| product_id | int |
| year | int |
| quantity | int |
| price | int |
+-------------+-------+
(sale_id, year) 是销售表 Sales 的主键.
product_id 是关联到产品表 Product 的外键.
注意: price 表示每单位价格
2
3
4
5
6
7
8
9
10
11
12
产品表 Product:
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| product_id | int |
| product_name | varchar |
+--------------+---------+
product_id 是表的主键.
2
3
4
5
6
7
写一条SQL 查询语句获取 Sales 表中所有产品对应的 产品名称 product_name 以及该产品的所有 售卖年份 year 和 价格 price 。
查询结果中的顺序无特定要求。
查询结果格式示例如下:
Sales 表:
+---------+------------+------+----------+-------+
| sale_id | product_id | year | quantity | price |
+---------+------------+------+----------+-------+
| 1 | 100 | 2008 | 10 | 5000 |
| 2 | 100 | 2009 | 12 | 5000 |
| 7 | 200 | 2011 | 15 | 9000 |
+---------+------------+------+----------+-------+
Product 表:
+------------+--------------+
| product_id | product_name |
+------------+--------------+
| 100 | Nokia |
| 200 | Apple |
| 300 | Samsung |
+------------+--------------+
Result 表:
+--------------+-------+-------+
| product_name | year | price |
+--------------+-------+-------+
| Nokia | 2008 | 5000 |
| Nokia | 2009 | 5000 |
| Apple | 2011 | 9000 |
+--------------+-------+-------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
SELECT
product_name,
YEAR,
price
FROM
Sales s
LEFT JOIN Product p ON s.product_id = p.product_id;
2
3
4
5
6
7
# 1084.销售分析III
Table: Product
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| product_id | int |
| product_name | varchar |
| unit_price | int |
+--------------+---------+
Product_id是该表的主键。
该表的每一行显示每个产品的名称和价格。
2
3
4
5
6
7
8
9
Table: Sales
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| seller_id | int |
| product_id | int |
| buyer_id | int |
| sale_date | date |
| quantity | int |
| price | int |
+------ ------+---------+
这个表没有主键,它可以有重复的行。
product_id 是 Product 表的外键。
该表的每一行包含关于一个销售的一些信息。
2
3
4
5
6
7
8
9
10
11
12
13
编写一个SQL查询,报告2019年春季才售出的产品。即仅在**2019-01-01**至**2019-03-31**(含)之间出售的商品。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入:
Product table:
+------------+--------------+------------+
| product_id | product_name | unit_price |
+------------+--------------+------------+
| 1 | S8 | 1000 |
| 2 | G4 | 800 |
| 3 | iPhone | 1400 |
+------------+--------------+------------+
Sales table:
+-----------+------------+----------+------------+----------+-------+
| seller_id | product_id | buyer_id | sale_date | quantity | price |
+-----------+------------+----------+------------+----------+-------+
| 1 | 1 | 1 | 2019-01-21 | 2 | 2000 |
| 1 | 2 | 2 | 2019-02-17 | 1 | 800 |
| 2 | 2 | 3 | 2019-06-02 | 1 | 800 |
| 3 | 3 | 4 | 2019-05-13 | 2 | 2800 |
+-----------+------------+----------+------------+----------+-------+
输出:
+-------------+--------------+
| product_id | product_name |
+-------------+--------------+
| 1 | S8 |
+-------------+--------------+
解释:
id为1的产品仅在2019年春季销售。
id为2的产品在2019年春季销售,但也在2019年春季之后销售。
id 3的产品在2019年春季之后销售。
我们只退回产品1,因为它是2019年春季才销售的产品。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
SELECT
s.product_id,
p.product_name
FROM
Sales s
LEFT JOIN Product p ON s.product_id = p.product_id
group by
s.product_id
having
min(s.sale_date) >= '2019-01-01'
and max(s.sale_date) <= '2019-03-31';
2
3
4
5
6
7
8
9
10
11
SELECT
product_id,
product_name
FROM
Product
WHERE
product_id IN (
SELECT
product_id
FROM
Sales
GROUP BY
product_id
HAVING
max( sale_date ) <= '2019-03-31' AND min( sale_date ) >= '2019-01-01')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 1141.查询近30天活跃用户数
活动记录表:Activity
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| user_id | int |
| session_id | int |
| activity_date | date |
| activity_type | enum |
+---------------+---------+
该表是用户在社交网站的活动记录。
该表没有主键,可能包含重复数据。
activity_type 字段为以下四种值 ('open_session', 'end_session', 'scroll_down', 'send_message')。
每个 session_id 只属于一个用户。
2
3
4
5
6
7
8
9
10
11
12
请写SQL查询出截至 2019-07-27(包含2019-07-27),近 30 天的每日活跃用户数(当天只要有一条活动记录,即为活跃用户)。
以 任意顺序 返回结果表。
查询结果示例如下。
示例 1:
输入:
Activity table:
+---------+------------+---------------+---------------+
| user_id | session_id | activity_date | activity_type |
+---------+------------+---------------+---------------+
| 1 | 1 | 2019-07-20 | open_session |
| 1 | 1 | 2019-07-20 | scroll_down |
| 1 | 1 | 2019-07-20 | end_session |
| 2 | 4 | 2019-07-20 | open_session |
| 2 | 4 | 2019-07-21 | send_message |
| 2 | 4 | 2019-07-21 | end_session |
| 3 | 2 | 2019-07-21 | open_session |
| 3 | 2 | 2019-07-21 | send_message |
| 3 | 2 | 2019-07-21 | end_session |
| 4 | 3 | 2019-06-25 | open_session |
| 4 | 3 | 2019-06-25 | end_session |
+---------+------------+---------------+---------------+
输出:
+------------+--------------+
| day | active_users |
+------------+--------------+
| 2019-07-20 | 2 |
| 2019-07-21 | 2 |
+------------+--------------+
解释:注意非活跃用户的记录不需要展示。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
SELECT
activity_date AS DAY,
count( DISTINCT user_id ) AS active_users
FROM
Activity
WHERE
activity_date BETWEEN '2019-06-28'
AND '2019-07-27'
GROUP BY
activity_date;
2
3
4
5
6
7
8
9
10
# 1148.文章浏览 I
Views 表:
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| article_id | int |
| author_id | int |
| viewer_id | int |
| view_date | date |
+---------------+---------+
此表无主键,因此可能会存在重复行。
此表的每一行都表示某人在某天浏览了某位作者的某篇文章。
请注意,同一人的 author_id 和 viewer_id 是相同的。
2
3
4
5
6
7
8
9
10
11
请编写一条 SQL 查询以找出所有浏览过自己文章的作者,结果按照 id 升序排列。
查询结果的格式如下所示:
Views 表:
+------------+-----------+-----------+------------+
| article_id | author_id | viewer_id | view_date |
+------------+-----------+-----------+------------+
| 1 | 3 | 5 | 2019-08-01 |
| 1 | 3 | 6 | 2019-08-02 |
| 2 | 7 | 7 | 2019-08-01 |
| 2 | 7 | 6 | 2019-08-02 |
| 4 | 7 | 1 | 2019-07-22 |
| 3 | 4 | 4 | 2019-07-21 |
| 3 | 4 | 4 | 2019-07-21 |
+------------+-----------+-----------+------------+
结果表:
+------+
| id |
+------+
| 4 |
| 7 |
+------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
SELECT DISTINCT
author_id AS id
FROM
Views
WHERE
author_id = viewer_id
ORDER BY
id;
2
3
4
5
6
7
8
# 1179.重新格式化部门表
部门表 Department:
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| revenue | int |
| month | varchar |
+---------------+---------+
(id, month) 是表的联合主键。
这个表格有关于每个部门每月收入的信息。
月份(month)可以取下列值 ["Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sep","Oct","Nov","Dec"]。
2
3
4
5
6
7
8
9
10
编写一个 SQL 查询来重新格式化表,使得新的表中有一个部门 id 列和一些对应 每个月 的收入(revenue)列。
查询结果格式如下面的示例所示:
Department 表:
+------+---------+-------+
| id | revenue | month |
+------+---------+-------+
| 1 | 8000 | Jan |
| 2 | 9000 | Jan |
| 3 | 10000 | Feb |
| 1 | 7000 | Feb |
| 1 | 6000 | Mar |
+------+---------+-------+
查询得到的结果表:
+------+-------------+-------------+-------------+-----+-------------+
| id | Jan_Revenue | Feb_Revenue | Mar_Revenue | ... | Dec_Revenue |
+------+-------------+-------------+-------------+-----+-------------+
| 1 | 8000 | 7000 | 6000 | ... | null |
| 2 | 9000 | null | null | ... | null |
| 3 | null | 10000 | null | ... | null |
+------+-------------+-------------+-------------+-----+-------------+
注意,结果表有 13 列 (1个部门 id 列 + 12个月份的收入列)。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
SELECT
id,
SUM( CASE WHEN MONTH = 'Jan' THEN revenue END ) AS Jan_Revenue,
SUM( CASE WHEN MONTH = 'Feb' THEN revenue END ) AS Feb_Revenue,
SUM( CASE WHEN MONTH = 'Mar' THEN revenue END ) AS Mar_Revenue,
SUM( CASE WHEN MONTH = 'Apr' THEN revenue END ) AS Apr_Revenue,
SUM( CASE WHEN MONTH = 'May' THEN revenue END ) AS May_Revenue,
SUM( CASE WHEN MONTH = 'Jun' THEN revenue END ) AS Jun_Revenue,
SUM( CASE WHEN MONTH = 'Jul' THEN revenue END ) AS Jul_Revenue,
SUM( CASE WHEN MONTH = 'Aug' THEN revenue END ) AS Aug_Revenue,
SUM( CASE WHEN MONTH = 'Sep' THEN revenue END ) AS Sep_Revenue,
SUM( CASE WHEN MONTH = 'Oct' THEN revenue END ) AS Oct_Revenue,
SUM( CASE WHEN MONTH = 'Nov' THEN revenue END ) AS Nov_Revenue,
SUM( CASE WHEN MONTH = 'Dec' THEN revenue END ) AS Dec_Revenue
FROM
department
GROUP BY
id
ORDER BY
id;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 1407.排名靠前的旅行者
表:Users
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| name | varchar |
+---------------+---------+
id 是该表单主键。
name 是用户名字。
2
3
4
5
6
7
8
表:Rides
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| user_id | int |
| distance | int |
+---------------+---------+
id 是该表单主键。
user_id 是本次行程的用户的 id, 而该用户此次行程距离为 distance 。
2
3
4
5
6
7
8
9
写一段 SQL , 报告每个用户的旅行距离。
返回的结果表单,以 travelled_distance 降序排列 ,如果有两个或者更多的用户旅行了相同的距离, 那么再以 name 升序排列 。
查询结果格式如下例所示。
Users 表:
+------+-----------+
| id | name |
+------+-----------+
| 1 | Alice |
| 2 | Bob |
| 3 | Alex |
| 4 | Donald |
| 7 | Lee |
| 13 | Jonathan |
| 19 | Elvis |
+------+-----------+
Rides 表:
+------+----------+----------+
| id | user_id | distance |
+------+----------+----------+
| 1 | 1 | 120 |
| 2 | 2 | 317 |
| 3 | 3 | 222 |
| 4 | 7 | 100 |
| 5 | 13 | 312 |
| 6 | 19 | 50 |
| 7 | 7 | 120 |
| 8 | 19 | 400 |
| 9 | 7 | 230 |
+------+----------+----------+
Result 表:
+----------+--------------------+
| name | travelled_distance |
+----------+--------------------+
| Elvis | 450 |
| Lee | 450 |
| Bob | 317 |
| Jonathan | 312 |
| Alex | 222 |
| Alice | 120 |
| Donald | 0 |
+----------+--------------------+
Elvis 和 Lee 旅行了 450 英里,Elvis 是排名靠前的旅行者,因为他的名字在字母表上的排序比 Lee 更小。
Bob, Jonathan, Alex 和 Alice 只有一次行程,我们只按此次行程的全部距离对他们排序。
Donald 没有任何行程, 他的旅行距离为 0。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
SELECT
name,
IFNULL(sum( distance ),0) AS travelled_distance
FROM
Users u
LEFT JOIN Rides r ON u.id = r.user_id
GROUP BY
u.id
ORDER BY
travelled_distance DESC,
NAME ASC;
2
3
4
5
6
7
8
9
10
11
# 1.先查出每个有行程的用户的距离 用到group by 和sum
# 2.由于没有行程的用户也需要查找所以需用到left join(主表数据不受影响),
# 再通过IFNULL()函数对行程为null的用户赋值为0,最后对其order by排序就行了
SELECT
name,
ifnull( travelled_distance, 0 ) AS travelled_distance
FROM
Users
LEFT JOIN ( SELECT user_id, sum( distance ) AS travelled_distance FROM Rides GROUP BY user_id ) t1 ON t1.user_id = Users.id
ORDER BY
travelled_distance DESC,
NAME ASC
2
3
4
5
6
7
8
9
10
11
12
# 1484.按日期分组销售产品
表 Activities:
+-------------+---------+
| 列名 | 类型 |
+-------------+---------+
| sell_date | date |
| product | varchar |
+-------------+---------+
此表没有主键,它可能包含重复项。
此表的每一行都包含产品名称和在市场上销售的日期。
2
3
4
5
6
7
8
编写一个 SQL 查询来查找每个日期、销售的不同产品的数量及其名称。
每个日期的销售产品名称应按词典序排列。
返回按 sell_date 排序的结果表。
查询结果格式如下例所示。
示例 1:
输入:
Activities 表:
+------------+-------------+
| sell_date | product |
+------------+-------------+
| 2020-05-30 | Headphone |
| 2020-06-01 | Pencil |
| 2020-06-02 | Mask |
| 2020-05-30 | Basketball |
| 2020-06-01 | Bible |
| 2020-06-02 | Mask |
| 2020-05-30 | T-Shirt |
+------------+-------------+
输出:
+------------+----------+------------------------------+
| sell_date | num_sold | products |
+------------+----------+------------------------------+
| 2020-05-30 | 3 | Basketball,Headphone,T-shirt |
| 2020-06-01 | 2 | Bible,Pencil |
| 2020-06-02 | 1 | Mask |
+------------+----------+------------------------------+
解释:
对于2020-05-30,出售的物品是 (Headphone, Basketball, T-shirt),按词典序排列,并用逗号 ',' 分隔。
对于2020-06-01,出售的物品是 (Pencil, Bible),按词典序排列,并用逗号分隔。
对于2020-06-02,出售的物品是 (Mask),只需返回该物品名。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
SELECT
sell_date,
count(DISTINCT product) AS num_sold,
GROUP_CONCAT( DISTINCT product ORDER BY product ASC ) AS products
FROM
Activities
GROUP BY
sell_date;
2
3
4
5
6
7
8
# Write your MySQL query statement below
select sell_date,
count(distinct product) as num_sold, #计算每一个分组中不同产品的数量,并取一个新名字 num_sold
group_concat(distinct product order by product separator ',' )products #分完组以后,再合并分组,将不同的产品进行合并,并默认按字典顺序排列(A,B,C,D...)
from Activities
group by sell_date #首先按照日期进行分组
order by sell_date #按照日期顺序进行排列(默认从小到大)
2
3
4
5
6
7
# group_concat函数
group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符'])
以id分组,把name字段的值打印在一行,逗号分隔(默认)
select id,group_concat(name) from aa group by id;
以id分组,把name字段的值打印在一行,分号分隔
select id,group_concat(name separator ';') from aa group by id;
以id分组,把去冗余的name字段的值打印在一行,
逗号分隔
select id,group_concat(distinct name) from aa group by id;
以id分组,把name字段的值打印在一行,逗号分隔,以name排倒序
select id,group_concat(name order by name desc) from aa group by id;
# 1527.患某种疾病的患者
患者信息表: Patients
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| patient_id | int |
| patient_name | varchar |
| conditions | varchar |
+--------------+---------+
patient_id (患者 ID)是该表的主键。
'conditions' (疾病)包含 0 个或以上的疾病代码,以空格分隔。
这个表包含医院中患者的信息。
2
3
4
5
6
7
8
9
10
写一条 SQL 语句,查询患有 I 类糖尿病的患者 ID (patient_id)、患者姓名(patient_name)以及其患有的所有疾病代码(conditions)。I 类糖尿病的代码总是包含前缀 DIAB1 。
按 任意顺序 返回结果表。
查询结果格式如下示例所示。
示例 1:
输入:
Patients表:
+------------+--------------+--------------+
| patient_id | patient_name | conditions |
+------------+--------------+--------------+
| 1 | Daniel | YFEV COUGH |
| 2 | Alice | |
| 3 | Bob | DIAB100 MYOP |
| 4 | George | ACNE DIAB100 |
| 5 | Alain | DIAB201 |
+------------+--------------+--------------+
输出:
+------------+--------------+--------------+
| patient_id | patient_name | conditions |
+------------+--------------+--------------+
| 3 | Bob | DIAB100 MYOP |
| 4 | George | ACNE DIAB100 |
+------------+--------------+--------------+
解释:Bob 和 George 都患有代码以 DIAB1 开头的疾病。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
SELECT
*
FROM
Patients
WHERE
conditions REGEXP '^DIAB1|\\sDIAB1'
2
3
4
5
6
糖尿病位于第一个时: 以DIAB1开始,即CONDITIONS REGEXP '^DIAB1
糖尿病不是第一个时: 含有 空格DIAB1,即CONDITIONS REGEXP '\\sDIAB1,其中'\s'表示空格.
SELECT
*
FROM
Patients
WHERE
conditions LIKE 'DIAB1%'
OR conditions LIKE '% DIAB1%';
2
3
4
5
6
7
SELECT
*
FROM
Patients
WHERE
LEFT ( conditions, 5 )= "DIAB1"
OR LOCATE( " DIAB1", conditions ) != 0;
2
3
4
5
6
7
# left(str, length)
从左开始截取字符串
说明:left(被截取字段,截取长度)
# LOCATE(字符串1,字符串2)
返回字符串1在字符串2中第一次出现的位置,只要字符串2中包含字符串1,那么返回值必然大于0。
# LOCATE(字符串1,字符串2,pos)
返回字符串1在字符串2中第一次出现的位置,从位置pos开始算起;
如果返回0,表示从pos位置开始之后没有了
# 1581.进店却未进行过交易的顾客
表:Visits
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| visit_id | int |
| customer_id | int |
+-------------+---------+
visit_id 是该表的主键。
该表包含有关光临过购物中心的顾客的信息。
2
3
4
5
6
7
8
表:Transactions
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| transaction_id | int |
| visit_id | int |
| amount | int |
+----------------+---------+
transaction_id 是此表的主键。
此表包含 visit_id 期间进行的交易的信息。
2
3
4
5
6
7
8
9
有一些顾客可能光顾了购物中心但没有进行交易。请你编写一个 SQL 查询,来查找这些顾客的 ID ,以及他们只光顾不交易的次数。
返回以 任何顺序 排序的结果表。
查询结果格式如下例所示。
示例 1:
输入:
Visits
+----------+-------------+
| visit_id | customer_id |
+----------+-------------+
| 1 | 23 |
| 2 | 9 |
| 4 | 30 |
| 5 | 54 |
| 6 | 96 |
| 7 | 54 |
| 8 | 54 |
+----------+-------------+
Transactions
+----------------+----------+--------+
| transaction_id | visit_id | amount |
+----------------+----------+--------+
| 2 | 5 | 310 |
| 3 | 5 | 300 |
| 9 | 5 | 200 |
| 12 | 1 | 910 |
| 13 | 2 | 970 |
+----------------+----------+--------+
输出:
+-------------+----------------+
| customer_id | count_no_trans |
+-------------+----------------+
| 54 | 2 |
| 30 | 1 |
| 96 | 1 |
+-------------+----------------+
解释:
ID = 23 的顾客曾经逛过一次购物中心,并在 ID = 12 的访问期间进行了一笔交易。
ID = 9 的顾客曾经逛过一次购物中心,并在 ID = 13 的访问期间进行了一笔交易。
ID = 30 的顾客曾经去过购物中心,并且没有进行任何交易。`
ID = 54 的顾客三度造访了购物中心。在 2 次访问中,他们没有进行任何交易,在 1 次访问中,他们进行了 3 次交易。
ID = 96 的顾客曾经去过购物中心,并且没有进行任何交易。
如我们所见,ID 为 30 和 96 的顾客一次没有进行任何交易就去了购物中心。顾客 54 也两次访问了购物中心并且没有进行任何交易。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
SELECT
customer_id,
COUNT(*) count_no_trans
FROM
Visits v
LEFT JOIN Transactions t ON v.visit_id = t.visit_id
WHERE
amount IS NULL
GROUP BY
customer_id
ORDER BY
count_no_trans DESC;
2
3
4
5
6
7
8
9
10
11
12
# 1587.银行账户概要 II
表: Users
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| account | int |
| name | varchar |
+--------------+---------+
account 是该表的主键.
表中的每一行包含银行里中每一个用户的账号.
2
3
4
5
6
7
8
表: Transactions
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| trans_id | int |
| account | int |
| amount | int |
| transacted_on | date |
+---------------+---------+
trans_id 是该表主键.
该表的每一行包含了所有账户的交易改变情况.
如果用户收到了钱, 那么金额是正的; 如果用户转了钱, 那么金额是负的.
所有账户的起始余额为 0.
2
3
4
5
6
7
8
9
10
11
12
写一个 SQL, 报告余额高于 10000 的所有用户的名字和余额. 账户的余额等于包含该账户的所有交易的总和.
返回结果表单没有顺序要求.
查询结果格式如下例所示.
Users table:
+------------+--------------+
| account | name |
+------------+--------------+
| 900001 | Alice |
| 900002 | Bob |
| 900003 | Charlie |
+------------+--------------+
Transactions table:
+------------+------------+------------+---------------+
| trans_id | account | amount | transacted_on |
+------------+------------+------------+---------------+
| 1 | 900001 | 7000 | 2020-08-01 |
| 2 | 900001 | 7000 | 2020-09-01 |
| 3 | 900001 | -3000 | 2020-09-02 |
| 4 | 900002 | 1000 | 2020-09-12 |
| 5 | 900003 | 6000 | 2020-08-07 |
| 6 | 900003 | 6000 | 2020-09-07 |
| 7 | 900003 | -4000 | 2020-09-11 |
+------------+------------+------------+---------------+
Result table:
+------------+------------+
| name | balance |
+------------+------------+
| Alice | 11000 |
+------------+------------+
Alice 的余额为(7000 + 7000 - 3000) = 11000.
Bob 的余额为1000.
Charlie 的余额为(6000 + 6000 - 4000) = 8000.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
SELECT
name,
SUM( amount ) balance
FROM
Transactions t
LEFT JOIN Users u ON u.account = t.account
GROUP BY
t.account
HAVING
balance > 10000;
2
3
4
5
6
7
8
9
10
SELECT
*
FROM
(
SELECT
name, SUM(amount) balance
FROM
Users u
JOIN
Transactions t
ON
u.account = T.account
GROUP BY
u.account
) tmp
WHERE
tmp.balance > 10000;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 1667.修复表中的名字
表: Users
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| user_id | int |
| name | varchar |
+----------------+---------+
user_id 是该表的主键。
该表包含用户的 ID 和名字。名字仅由小写和大写字符组成。
2
3
4
5
6
7
8
编写一个 SQL 查询来修复名字,使得只有第一个字符是大写的,其余都是小写的。
返回按 user_id 排序的结果表。
查询结果格式示例如下。
示例 1:
输入:
Users table:
+---------+-------+
| user_id | name |
+---------+-------+
| 1 | aLice |
| 2 | bOB |
+---------+-------+
输出:
+---------+-------+
| user_id | name |
+---------+-------+
| 1 | Alice |
| 2 | Bob |
+---------+-------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
SELECT
user_id,
CONCAT(
UPPER(
SUBSTR( NAME, 1, 1 )),
LOWER(
SUBSTR( NAME, 2 ))) AS NAME
FROM
Users
ORDER BY
user_id;
2
3
4
5
6
7
8
9
10
11
# select user_id, CONCAT(UPPER(left(name, 1)), LOWER(SUBSTRING(name, 2))) as name
select user_id, CONCAT(UPPER(left(name, 1)), LOWER(RIGHT(name, length(name) - 1))) as name
from Users
order by user_id
2
3
4
# CONCAT() 函数
CONCAT 可以将多个字符串拼接在一起。
# LEFT(str, length) 函数
从左开始截取字符串,length 是截取的长度。
# LOWER(str) 将字符串中所有字符转为小写
# UPPER(str) 将字符串中所有字符转为大写
# substr() 函数
substr(string string,num start,num length);
string为字符串;start为起始位置;length为长度。
注意:mysql中的start是从1开始的。
# 1693.每天的领导和合伙人
表:DailySales
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| date_id | date |
| make_name | varchar |
| lead_id | int |
| partner_id | int |
+-------------+---------+
该表没有主键。
该表包含日期、产品的名称,以及售给的领导和合伙人的编号。
名称只包含小写英文字母。
2
3
4
5
6
7
8
9
10
11
写一条 SQL 语句,使得对于每一个 date_id 和 make_name,返回不同的 lead_id 以及不同的 partner_id 的数量。
按 任意顺序 返回结果表。
查询结果格式如下示例所示。
示例 1:
输入:
DailySales 表:
+-----------+-----------+---------+------------+
| date_id | make_name | lead_id | partner_id |
+-----------+-----------+---------+------------+
| 2020-12-8 | toyota | 0 | 1 |
| 2020-12-8 | toyota | 1 | 0 |
| 2020-12-8 | toyota | 1 | 2 |
| 2020-12-7 | toyota | 0 | 2 |
| 2020-12-7 | toyota | 0 | 1 |
| 2020-12-8 | honda | 1 | 2 |
| 2020-12-8 | honda | 2 | 1 |
| 2020-12-7 | honda | 0 | 1 |
| 2020-12-7 | honda | 1 | 2 |
| 2020-12-7 | honda | 2 | 1 |
+-----------+-----------+---------+------------+
输出:
+-----------+-----------+--------------+-----------------+
| date_id | make_name | unique_leads | unique_partners |
+-----------+-----------+--------------+-----------------+
| 2020-12-8 | toyota | 2 | 3 |
| 2020-12-7 | toyota | 1 | 2 |
| 2020-12-8 | honda | 2 | 2 |
| 2020-12-7 | honda | 3 | 2 |
+-----------+-----------+--------------+-----------------+
解释:
在 2020-12-8,丰田(toyota)有领导者 = [0, 1] 和合伙人 = [0, 1, 2] ,同时本田(honda)有领导者 = [1, 2] 和合伙人 = [1, 2]。
在 2020-12-7,丰田(toyota)有领导者 = [0] 和合伙人 = [1, 2] ,同时本田(honda)有领导者 = [0, 1, 2] 和合伙人 = [1, 2]。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
SELECT
date_id,
make_name,
count( DISTINCT lead_id ) unique_leads,
count( DISTINCT partner_id ) unique_partners
FROM
DailySales
GROUP BY
date_id,
make_name;
2
3
4
5
6
7
8
9
10
# 1729.求关注者的数量
表: Followers
+-------------+------+
| Column Name | Type |
+-------------+------+
| user_id | int |
| follower_id | int |
+-------------+------+
(user_id, follower_id) 是这个表的主键。
该表包含一个关注关系中关注者和用户的编号,其中关注者关注用户。
2
3
4
5
6
7
8
写出 SQL 语句,对于每一个用户,返回该用户的关注者数量。
按 user_id 的顺序返回结果表。
查询结果的格式如下示例所示。
示例 1:
输入:
Followers 表:
+---------+-------------+
| user_id | follower_id |
+---------+-------------+
| 0 | 1 |
| 1 | 0 |
| 2 | 0 |
| 2 | 1 |
+---------+-------------+
输出:
+---------+----------------+
| user_id | followers_count|
+---------+----------------+
| 0 | 1 |
| 1 | 1 |
| 2 | 2 |
+---------+----------------+
解释:
0 的关注者有 {1}
1 的关注者有 {0}
2 的关注者有 {0,1}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
SELECT
user_id,
count(*) followers_count
FROM
Followers
GROUP BY
user_id
ORDER BY
user_id;
2
3
4
5
6
7
8
9
# 1741.查找每个员工花费的总时间
表: Employees
+-------------+------+
| Column Name | Type |
+-------------+------+
| emp_id | int |
| event_day | date |
| in_time | int |
| out_time | int |
+-------------+------+
(emp_id, event_day, in_time) 是这个表的主键。
该表显示了员工在办公室的出入情况。
event_day 是此事件发生的日期,in_time 是员工进入办公室的时间,而 out_time 是他们离开办公室的时间。
in_time 和 out_time 的取值在1到1440之间。
题目保证同一天没有两个事件在时间上是相交的,并且保证 in_time 小于 out_time。
2
3
4
5
6
7
8
9
10
11
12
13
编写一个SQL查询以计算每位员工每天在办公室花费的总时间(以分钟为单位)。 请注意,在一天之内,同一员工是可以多次进入和离开办公室的。 在办公室里一次进出所花费的时间为out_time 减去 in_time。
返回结果表单的顺序无要求。 查询结果的格式如下:
Employees table:
+--------+------------+---------+----------+
| emp_id | event_day | in_time | out_time |
+--------+------------+---------+----------+
| 1 | 2020-11-28 | 4 | 32 |
| 1 | 2020-11-28 | 55 | 200 |
| 1 | 2020-12-03 | 1 | 42 |
| 2 | 2020-11-28 | 3 | 33 |
| 2 | 2020-12-09 | 47 | 74 |
+--------+------------+---------+----------+
Result table:
+------------+--------+------------+
| day | emp_id | total_time |
+------------+--------+------------+
| 2020-11-28 | 1 | 173 |
| 2020-11-28 | 2 | 30 |
| 2020-12-03 | 1 | 41 |
| 2020-12-09 | 2 | 27 |
+------------+--------+------------+
雇员 1 有三次进出: 有两次发生在 2020-11-28 花费的时间为 (32 - 4) + (200 - 55) = 173, 有一次发生在 2020-12-03 花费的时间为 (42 - 1) = 41。
雇员 2 有两次进出: 有一次发生在 2020-11-28 花费的时间为 (33 - 3) = 30, 有一次发生在 2020-12-09 花费的时间为 (74 - 47) = 27。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
SELECT
event_day day,
emp_id,
sum(out_time - in_time) total_time
FROM
Employees
GROUP BY
event_day,
emp_id;
2
3
4
5
6
7
8
9
# 1757.可回收且低脂的产品
表:Products
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| product_id | int |
| low_fats | enum |
| recyclable | enum |
+-------------+---------+
product_id 是这个表的主键。
low_fats 是枚举类型,取值为以下两种 ('Y', 'N'),其中 'Y' 表示该产品是低脂产品,'N' 表示不是低脂产品。
recyclable 是枚举类型,取值为以下两种 ('Y', 'N'),其中 'Y' 表示该产品可回收,而 'N' 表示不可回收。
2
3
4
5
6
7
8
9
10
写出 SQL 语句,查找既是低脂又是可回收的产品编号。
返回结果 无顺序要求 。
查询结果格式如下例所示:
Products 表:
+-------------+----------+------------+
| product_id | low_fats | recyclable |
+-------------+----------+------------+
| 0 | Y | N |
| 1 | Y | Y |
| 2 | N | Y |
| 3 | Y | Y |
| 4 | N | N |
+-------------+----------+------------+
Result 表:
+-------------+
| product_id |
+-------------+
| 1 |
| 3 |
+-------------+
只有产品 id 为 1 和 3 的产品,既是低脂又是可回收的产品。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
SELECT
product_id
FROM
Products
WHERE
low_fats = 'Y'
AND recyclable = 'Y';
2
3
4
5
6
7
# 1795.每个产品在不同商店的价格
表:Products
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| product_id | int |
| store1 | int |
| store2 | int |
| store3 | int |
+-------------+---------+
这张表的主键是product_id(产品Id)。
每行存储了这一产品在不同商店store1, store2, store3的价格。
如果这一产品在商店里没有出售,则值将为null。
2
3
4
5
6
7
8
9
10
11
请你重构 Products 表,查询每个产品在不同商店的价格,使得输出的格式变为(product_id, store, price) 。如果这一产品在商店里没有出售,则不输出这一行。
输出结果表中的 顺序不作要求 。
查询输出格式请参考下面示例。
示例 1:
输入:
Products table:
+------------+--------+--------+--------+
| product_id | store1 | store2 | store3 |
+------------+--------+--------+--------+
| 0 | 95 | 100 | 105 |
| 1 | 70 | null | 80 |
+------------+--------+--------+--------+
输出:
+------------+--------+-------+
| product_id | store | price |
+------------+--------+-------+
| 0 | store1 | 95 |
| 0 | store2 | 100 |
| 0 | store3 | 105 |
| 1 | store1 | 70 |
| 1 | store3 | 80 |
+------------+--------+-------+
解释:
产品0在store1,store2,store3的价格分别为95,100,105。
产品1在store1,store3的价格分别为70,80。在store2无法买到。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
1.列转行
SELECT
product_id,
'store1' store,
store1 price
FROM
Products
WHERE
store1 IS NOT NULL UNION
SELECT
product_id,
'store2' store,
store2 price
FROM
Products
WHERE
store2 IS NOT NULL UNION
SELECT
product_id,
'store3' store,
store3 price
FROM
Products
WHERE
store3 IS NOT NULL;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24

2.行转列
SELECT
product_id,
sum(
IF
( store = 'store1', price NULL )) store1,
sum(
IF
( store = 'store2', price NULL )) store2,
sum(
IF
( store = 'store3', price NULL )) store3
FROM
Product GROUP
GROUP BY
product_id;
2
3
4
5
6
7
8
9
10
11
12
13
14
15

# 1873.计算特殊奖金
表: Employees
+-------------+---------+
| 列名 | 类型 |
+-------------+---------+
| employee_id | int |
| name | varchar |
| salary | int |
+-------------+---------+
employee_id 是这个表的主键。
此表的每一行给出了雇员id ,名字和薪水。
2
3
4
5
6
7
8
9
写出一个SQL 查询语句,计算每个雇员的奖金。如果一个雇员的id是奇数并且他的名字不是以'M'开头,那么他的奖金是他工资的100%,否则奖金为0。
Return the result table ordered by employee_id.
返回的结果集请按照employee_id排序。
查询结果格式如下面的例子所示。
示例 1:
输入:
Employees 表:
+-------------+---------+--------+
| employee_id | name | salary |
+-------------+---------+--------+
| 2 | Meir | 3000 |
| 3 | Michael | 3800 |
| 7 | Addilyn | 7400 |
| 8 | Juan | 6100 |
| 9 | Kannon | 7700 |
+-------------+---------+--------+
输出:
+-------------+-------+
| employee_id | bonus |
+-------------+-------+
| 2 | 0 |
| 3 | 0 |
| 7 | 7400 |
| 8 | 0 |
| 9 | 7700 |
+-------------+-------+
解释:
因为雇员id是偶数,所以雇员id 是2和8的两个雇员得到的奖金是0。
雇员id为3的因为他的名字以'M'开头,所以,奖金是0。
其他的雇员得到了百分之百的奖金。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
SELECT
employee_id,
IF
( employee_id % 2 = 1 AND NAME NOT LIKE 'M%', salary, 0 ) bonus
FROM
Employees
ORDER BY
employee_id;
2
3
4
5
6
7
8
SELECT
employee_id,
IF(MOD(employee_id,2)!=0 AND LEFT(name,1)!='M',salary,0) bonus
FROM Employees
ORDER BY employee_id
2
3
4
5
SELECT employee_id,
/*MOD为取余操作*/
(CASE WHEN MOD(employee_id,2)!=0 AND LEFT(name,1)!='M' THEN salary
WHEN MOD(employee_id,2)=0 OR LEFT(name,1)='M' THEN 0
END) bonus
FROM Employees
ORDER BY employee_id
2
3
4
5
6
7
# 1890.2020年最后一次登录
表: Logins
+----------------+----------+
| 列名 | 类型 |
+----------------+----------+
| user_id | int |
| time_stamp | datetime |
+----------------+----------+
(user_id, time_stamp) 是这个表的主键。
每一行包含的信息是user_id 这个用户的登录时间。
2
3
4
5
6
7
8
编写一个 SQL 查询,该查询可以获取在 2020 年登录过的所有用户的本年度 最后一次 登录时间。结果集 不 包含 2020 年没有登录过的用户。
返回的结果集可以按 任意顺序 排列。
查询结果格式如下例。
示例 1:
输入:
Logins 表:
+---------+---------------------+
| user_id | time_stamp |
+---------+---------------------+
| 6 | 2020-06-30 15:06:07 |
| 6 | 2021-04-21 14:06:06 |
| 6 | 2019-03-07 00:18:15 |
| 8 | 2020-02-01 05:10:53 |
| 8 | 2020-12-30 00:46:50 |
| 2 | 2020-01-16 02:49:50 |
| 2 | 2019-08-25 07:59:08 |
| 14 | 2019-07-14 09:00:00 |
| 14 | 2021-01-06 11:59:59 |
+---------+---------------------+
输出:
+---------+---------------------+
| user_id | last_stamp |
+---------+---------------------+
| 6 | 2020-06-30 15:06:07 |
| 8 | 2020-12-30 00:46:50 |
| 2 | 2020-01-16 02:49:50 |
+---------+---------------------+
解释:
6号用户登录了3次,但是在2020年仅有一次,所以结果集应包含此次登录。
8号用户在2020年登录了2次,一次在2月,一次在12月,所以,结果集应该包含12月的这次登录。
2号用户登录了2次,但是在2020年仅有一次,所以结果集应包含此次登录。
14号用户在2020年没有登录,所以结果集不应包含。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
SELECT
user_id,
max( time_stamp ) last_stamp
FROM
Logins
WHERE
YEAR ( time_stamp ) = '2020'
GROUP BY
user_id;
2
3
4
5
6
7
8
9
SELECT
user_id,
max( time_stamp ) last_stamp
FROM
Logins
WHERE
time_stamp >= '2020-01-01' and time_stamp < '2021-01-01'
GROUP BY
user_id;
2
3
4
5
6
7
8
9
# 1965.丢失信息的雇员
表: Employees
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| employee_id | int |
| name | varchar |
+-------------+---------+
employee_id 是这个表的主键。
每一行表示雇员的id 和他的姓名。
2
3
4
5
6
7
8
表: Salaries
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| employee_id | int |
| salary | int |
+-------------+---------+
employee_id is 这个表的主键。
每一行表示雇员的id 和他的薪水。
2
3
4
5
6
7
8
写出一个查询语句,找到所有 丢失信息 的雇员id。当满足下面一个条件时,就被认为是雇员的信息丢失:
- 雇员的 姓名 丢失了,或者
- 雇员的 薪水信息 丢失了,或者
返回这些雇员的id employee_id , 从小到大排序 。
查询结果格式如下面的例子所示。
示例 1:
输入:
Employees table:
+-------------+----------+
| employee_id | name |
+-------------+----------+
| 2 | Crew |
| 4 | Haven |
| 5 | Kristian |
+-------------+----------+
Salaries table:
+-------------+--------+
| employee_id | salary |
+-------------+--------+
| 5 | 76071 |
| 1 | 22517 |
| 4 | 63539 |
+-------------+--------+
输出:
+-------------+
| employee_id |
+-------------+
| 1 |
| 2 |
+-------------+
解释:
雇员1,2,4,5 都工作在这个公司。
1号雇员的姓名丢失了。
2号雇员的薪水信息丢失了。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
SELECT
employee_id
FROM
( SELECT employee_id FROM Employees UNION ALL SELECT employee_id FROM Salaries ) AS t
GROUP BY
employee_id
HAVING
count(*) = 1
ORDER BY
employee_id ASC;
2
3
4
5
6
7
8
9
10
SELECT
employee_id
FROM
(
SELECT
e.employee_id
FROM
Employees e
LEFT JOIN Salaries s ON e.employee_id = s.employee_id
WHERE
s.salary IS NULL UNION ALL
SELECT
s.employee_id
FROM
Salaries s
LEFT JOIN Employees e ON s.employee_id = e.employee_id
WHERE
e.NAME IS NULL
) t
ORDER BY
t.employee_id ASC;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 176.第二高的薪水
Employee 表:
+-------------+------+
| Column Name | Type |
+-------------+------+
| id | int |
| salary | int |
+-------------+------+
id 是这个表的主键。
表的每一行包含员工的工资信息。
2
3
4
5
6
7
8
编写一个 SQL 查询,获取并返回 Employee 表中第二高的薪水 。如果不存在第二高的薪水,查询应该返回 null 。
查询结果如下例所示。
示例 1:
输入:
Employee 表:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
输出:
+---------------------+
| SecondHighestSalary |
+---------------------+
| 200 |
+---------------------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
示例 2:
输入:
Employee 表:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
+----+--------+
输出:
+---------------------+
| SecondHighestSalary |
+---------------------+
| null |
+---------------------+
2
3
4
5
6
7
8
9
10
11
12
13
方法一:使用子查询和 LIMIT 子句
SELECT
( SELECT DISTINCT salary FROM Employee ORDER BY salary DESC LIMIT 1, 1 ) SecondHighestSalary
2
使用 IFNULL 和 LIMIT 子句
SELECT
IFNULL( ( SELECT DISTINCT salary FROM Employee ORDER BY salary DESC LIMIT 1, 1 ), NULL ) AS SecondHighestSalary;
2
# 177.第N高的薪水
表: Employee
+-------------+------+
| Column Name | Type |
+-------------+------+
| id | int |
| salary | int |
+-------------+------+
Id是该表的主键列。
该表的每一行都包含有关员工工资的信息。
2
3
4
5
6
7
8
编写一个SQL查询来报告 Employee 表中第 n 高的工资。如果没有第 n 个最高工资,查询应该报告为 null 。
查询结果格式如下所示。
示例 1:
输入:
Employee table:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
n = 2
输出:
+------------------------+
| getNthHighestSalary(2) |
+------------------------+
| 200 |
+------------------------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
示例 2:
输入:
Employee 表:
+----+--------+
| id | salary |
+----+--------+
| 1 | 100 |
+----+--------+
n = 2
输出:
+------------------------+
| getNthHighestSalary(2) |
+------------------------+
| null |
+------------------------+
2
3
4
5
6
7
8
9
10
11
12
13
14
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
SET N := N-1;
RETURN (
# Write your MySQL query statement below.
SELECT
(
IFNULL( (SELECT salary FROM Employee GROUP BY salary ORDER BY salary DESC LIMIT N , 1) , NULL )
)
);
END
2
3
4
5
6
7
8
9
10
11
# 窗口函数
实际上,在mysql8.0中有相关的内置函数,而且考虑了各种排名问题:
row_number(): 同薪不同名,相当于行号,例如3000、2000、2000、1000排名后为1、2、3、4
rank(): 同薪同名,有跳级,例如3000、2000、2000、1000排名后为1、2、2、4
dense_rank(): 同薪同名,无跳级,例如3000、2000、2000、1000排名后为1、2、2、3
ntile(): 分桶排名,即首先按桶的个数分出第一二三桶,然后各桶内从1排名,实际不是很常用
显然,本题是要用第三个函数。 另外这三个函数必须要要与其搭档over()配套使用,over()中的参数常见的有两个,分别是
partition by,按某字段切分
order by,与常规order by用法一致,也区分ASC(默认)和DESC,因为排名总得有个依据
注:下面代码仅在mysql8.0以上版本可用,最新OJ已支持。
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
SELECT
DISTINCT salary
FROM
(SELECT
salary, dense_rank() over(ORDER BY salary DESC) AS rnk
FROM
employee) tmp
WHERE rnk = N
);
END
2
3
4
5
6
7
8
9
10
11
12
13
14
# 代码随想录
# 数组
# 1.基础理论
数组理论基础
数组是非常基础的数据结构,在面试中,考察数组的题目一般在思维上都不难,主要是考察对代码的掌控能力
也就是说,想法很简单,但实现起来 可能就不是那么回事了。
首先要知道数组在内存中的存储方式,这样才能真正理解数组相关的面试题
数组是存放在连续内存空间上的相同类型数据的集合。
数组可以方便的通过下标索引的方式获取到下标下对应的数据。
举一个字符数组的例子,如图所示:

需要两点注意的是
- 数组下标都是从0开始的。
- 数组内存空间的地址是连续的
正是因为数组的在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。
例如删除下标为3的元素,需要对下标为3的元素后面的所有元素都要做移动操作,如图所示:

而且大家如果使用C++的话,要注意vector 和 array的区别,vector的底层实现是array,严格来讲vector是容器,不是数组。
数组的元素是不能删的,只能覆盖。
那么二维数组直接上图,大家应该就知道怎么回事了

那么二维数组在内存的空间地址是连续的么?
不同编程语言的内存管理是不一样的,以C++为例,在C++中二维数组是连续分布的。
我们来做一个实验,C++测试代码如下:
void test_arr() {
int array[2][3] = {
{0, 1, 2},
{3, 4, 5}
};
cout << &array[0][0] << " " << &array[0][1] << " " << &array[0][2] << endl;
cout << &array[1][0] << " " << &array[1][1] << " " << &array[1][2] << endl;
}
int main() {
test_arr();
}
2
3
4
5
6
7
8
9
10
11
12
测试地址为
0x7ffee4065820 0x7ffee4065824 0x7ffee4065828
0x7ffee406582c 0x7ffee4065830 0x7ffee4065834
2
注意地址为16进制,可以看出二维数组地址是连续一条线的。
一些录友可能看不懂内存地址,我就简单介绍一下, 0x7ffee4065820 与 0x7ffee4065824 差了一个4,就是4个字节,因为这是一个int型的数组,所以两个相邻数组元素地址差4个字节。
0x7ffee4065828 与 0x7ffee406582c 也是差了4个字节,在16进制里8 + 4 = c,c就是12。
如图:

所以可以看出在C++中二维数组在地址空间上是连续的。
像Java是没有指针的,同时也不对程序员暴露其元素的地址,寻址操作完全交给虚拟机。
所以看不到每个元素的地址情况,这里我以Java为例,也做一个实验。
public static void test_arr() {
int[][] arr = {{1, 2, 3}, {3, 4, 5}, {6, 7, 8}, {9,9,9}};
System.out.println(arr[0]);
System.out.println(arr[1]);
System.out.println(arr[2]);
System.out.println(arr[3]);
}
2
3
4
5
6
7
输出的地址为:
[I@7852e922
[I@4e25154f
[I@70dea4e
[I@5c647e05
2
3
4
这里的数值也是16进制,这不是真正的地址,而是经过处理过后的数值了,我们也可以看出,二维数组的每一行头结点的地址是没有规则的,更谈不上连续。
所以Java的二维数组可能是如下排列的方式:

# 2.二分查找
- 二分查找
- 35.搜索插入位置(opens new window) (opens new window)
- 34.在排序数组中查找元素的第一个和最后一个位置(opens new window) (opens new window)
- 69.x 的平方根
- 367.有效的完全平方数
- 26.删除排序数组中的重复项
- 283.移动零
- 844.比较含退格的字符串
- 977.有序数组的平方
# 滑动窗口
# 209.长度最小的子数组
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl+1, ..., numsr-1, numsr] ,并返回其长度**。**如果不存在符合条件的子数组,返回 0 。
示例 1:
输入:target = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
2
3
示例 2:
输入:target = 4, nums = [1,4,4]
输出:1
2
示例 3:
输入:target = 11, nums = [1,1,1,1,1,1,1,1]
输出:0
2
// 暴力解法
// 暴力解法,会超时
public static int minSubArrayLen(int target, int[] nums) {
int n = nums.length;
int min_Length = Integer.MAX_VALUE;
for (int i = 0; i < n; i++) {
int sum = 0;
for (int j = i; j < n; j++) {
sum += nums[j];
if (sum >= target) {
int length = j - i + 1;
min_Length = Math.min(length, min_Length);
break;
}
}
}
return min_Length == Integer.MAX_VALUE ? 0 : min_Length;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 滑动窗口
// 滑动窗口
public static int minSubArrayLen2(int target, int[] nums) {
int k = 0; // 窗口起始位置
int sum = 0; // 总和
int n = nums.length; // 数组长度
int min_Length = Integer.MAX_VALUE;
for (int i = 0; i < n; i++) { // 滑动窗口终止位置
sum += nums[i];
while (sum >= target) { // 此时已经找到了以i为起始位置的最小连续长度了
int result = i - k + 1; // 滑动窗口的长度
min_Length = Math.min(min_Length, result);
sum -= nums[k++]; // 更换滑动窗口的起始位置
}
}
return min_Length == Integer.MAX_VALUE ? 0 : min_Length;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 904.水果成篮 (opens new window)
你正在探访一家农场,农场从左到右种植了一排果树。这些树用一个整数数组 fruits 表示,其中 fruits[i] 是第 i 棵树上的水果 种类 。
你想要尽可能多地收集水果。然而,农场的主人设定了一些严格的规矩,你必须按照要求采摘水果:
- 你只有 两个 篮子,并且每个篮子只能装 单一类型 的水果。每个篮子能够装的水果总量没有限制。
- 你可以选择任意一棵树开始采摘,你必须从 每棵 树(包括开始采摘的树)上 恰好摘一个水果 。采摘的水果应当符合篮子中的水果类型。每采摘一次,你将会向右移动到下一棵树,并继续采摘。
- 一旦你走到某棵树前,但水果不符合篮子的水果类型,那么就必须停止采摘。
给你一个整数数组 fruits ,返回你可以收集的水果的 最大 数目。
示例 1:
输入:fruits = [1,2,1]
输出:3
解释:可以采摘全部 3 棵树。
2
3
示例 2:
输入:fruits = [0,1,2,2]
输出:3
解释:可以采摘 [1,2,2] 这三棵树。
如果从第一棵树开始采摘,则只能采摘 [0,1] 这两棵树。
2
3
4
示例 3:
输入:fruits = [1,2,3,2,2]
输出:4
解释:可以采摘 [2,3,2,2] 这四棵树。
如果从第一棵树开始采摘,则只能采摘 [1,2] 这两棵树。
2
3
4
示例 4:
输入:fruits = [3,3,3,1,2,1,1,2,3,3,4]
输出:5
解释:可以采摘 [1,2,1,1,2] 这五棵树。
2
3
// 滑动窗口
public static int totalFruit(int[] fruits) {
int n = fruits.length;
HashMap<Integer, Integer> hashMap = new HashMap<>();
int left = 0, right = 0, ans = 0;
for (right = 0; right < n; right++) {
hashMap.put(fruits[right], hashMap.getOrDefault(fruits[right],0) + 1);
while (hashMap.size() > 2) { // 长度大于2之后,也就是长度为3,要删除第一个
// 必须一个一个减1,为0后移除(这样可以找到左侧的left)
hashMap.put(fruits[left], hashMap.getOrDefault(fruits[left], 0) -1) ; // 删掉一个
if (hashMap.get(fruits[left]) == 0){ // 如果为0,就删掉
hashMap.remove(fruits[left]);
}
left++;
}
ans = Math.max(ans, right - left + 1);
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 76.最小覆盖子串 (opens new window)
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
注意:
- 对于
t中重复字符,我们寻找的子字符串中该字符数量必须不少于t中该字符数量。 - 如果
s中存在这样的子串,我们保证它是唯一的答案。
示例 1:
输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。
2
3
示例 2:
输入:s = "a", t = "a"
输出:"a"
解释:整个字符串 s 是最小覆盖子串。
2
3
示例 3:
输入: s = "a", t = "aa"
输出: ""
解释: t 中两个字符 'a' 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。
2
3
4
提示:
m == s.lengthn == t.length1 <= m, n <= 105s和t由英文字母组成
// 注意t可能有重复字符
static HashMap s_map = new HashMap<Character, Integer>(); // 存储s子串中包含t字符串字符的字符频数
static HashMap t_map = new HashMap<Character, Integer>(); // 存储t中每个字符出现的次数
public static String minWindow(String s, String t) {
int t_length = t.length();
int s_length = s.length();
if (t_length > s_length) {
return "";
}
for (int i = 0; i < t_length; i++) {
char c = t.charAt(i);
t_map.put(c,(Integer)t_map.getOrDefault(c,0) + 1);
}
int leftIndex = 0, rightIndex = 0, left = 0, right = 0, min = Integer.MAX_VALUE;
while (right < s_length) {
if (t_map.containsKey(s.charAt(right))) {
s_map.put(s.charAt(right), (Integer)s_map.getOrDefault(s.charAt(right), 0) + 1);
}
while (check() && left <= right) {
if (right - left + 1 < min) {
min = right - left + 1;
leftIndex = left;
rightIndex = right;
}
if (t_map.containsKey(s.charAt(left))) {
s_map.put(s.charAt(left), (Integer)s_map.getOrDefault(s.charAt(left),0) - 1);
}
left++;
}
right++;
}
return min == Integer.MAX_VALUE ? "" : s.substring(leftIndex, rightIndex + 1);
}
/**
* 检查是否包含字符串
* @return
*/
public static boolean check() {
Iterator iterator = t_map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry entry = (Map.Entry)iterator.next();
Character key = (Character) entry.getKey();
Integer value = (Integer) entry.getValue();
if ((Integer)s_map.getOrDefault(key,0) < value) {
return false;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 59.螺旋矩阵 II
给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
示例 1:

输入:n = 3
输出:[[1,2,3],[8,9,4],[7,6,5]]
2
示例 2:
输入:n = 1
输出:[[1]]
2
提示:
1 <= n <= 20
// 遵循左闭右开的规则
public static int[][] generateMatrix(int n) {
int[][] arr = new int[n][n];
int count = 1;
int start = 0;
int loop = 0; // 循环的次数
int i, j;
while (loop < n / 2) { // 循环的次数,每次循环顺时针
loop++;
// 上侧:从左往右循环
for (i = start; i < n - loop; i++) {
arr[start][i] = count++;
}
// 右侧:从上向下(此时i = n - 1)
for (j = start; j < n - loop; j++) {
arr[j][i] = count++;
}
// 下侧:从右到左(此时j = n - 1)
for (;i>=loop;i--) {
arr[j][i] = count++;
}
// 左侧:从下到上 (此时 i = start, = n - 1)
for (;j>=loop;j--) {
arr[j][i] = count++;
}
start++;
}
if (n % 2 != 0) {
arr[start][start] = count;
}
return arr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 链表
# 单链表
# 双链表
单链表中的指针域只能指向节点的下一个节点。
双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
双链表 既可以向前查询也可以向后查询。

# 循环链表

数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个节点。
所以链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
# 链表的操作
# 删除节点

# 添加节点


# 203.移除链表元素
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:
输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
2
示例 2:
输入:head = [], val = 1
输出:[]
2
示例 3:
输入:head = [7,7,7,7], val = 7
输出:[]
2
提示:
- 列表中的节点数目在范围
[0, 104]内 1 <= Node.val <= 500 <= val <= 50
// 可以设置一个虚拟头结点,这样原链表的所有节点就都可以按照统一的方式进行移除了。
public ListNode removeElements(ListNode head, int val) {
if (head == null) {
return head;
}
// 设置一个虚拟头结点
ListNode newHead = new ListNode(-1, head);
ListNode pre = newHead, cur = head;
while (cur != null) {
if (cur.val == val) {
pre.next = cur.next;
}else {
pre = cur;
}
cur = cur.next;
}
return newHead.next;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 不添加虚拟节点
// 不添加虚拟节点
public ListNode removeElements2(ListNode head, int val) {
while (head != null && head.val == val) {
head = head.next;
}
if (head == null) {
return head;
}
ListNode newHead = head, node = head; // 此时的头结点为去掉相同值的头结点
while (node != null) {
while (node.next != null && node.next.val == val) {
node.next = node.next.next;
}
node = node.next;
}
return newHead;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 707.设计链表
设计链表的实现。您可以选择使用单链表或双链表。单链表中的节点应该具有两个属性:val 和 next。val 是当前节点的值,next 是指向下一个节点的指针/引用。如果要使用双向链表,则还需要一个属性 prev 以指示链表中的上一个节点。假设链表中的所有节点都是 0-index 的。
在链表类中实现这些功能:
- get(index):获取链表中第
index个节点的值。如果索引无效,则返回-1。 - addAtHead(val):在链表的第一个元素之前添加一个值为
val的节点。插入后,新节点将成为链表的第一个节点。 - addAtTail(val):将值为
val的节点追加到链表的最后一个元素。 - addAtIndex(index,val):在链表中的第
index个节点之前添加值为val的节点。如果index等于链表的长度,则该节点将附加到链表的末尾。如果index大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。 - deleteAtIndex(index):如果索引
index有效,则删除链表中的第index个节点。
示例:
MyLinkedList linkedList = new MyLinkedList();
linkedList.addAtHead(1);
linkedList.addAtTail(3);
linkedList.addAtIndex(1,2); //链表变为1-> 2-> 3
linkedList.get(1); //返回2
linkedList.deleteAtIndex(1); //现在链表是1-> 3
linkedList.get(1); //返回3
2
3
4
5
6
7
提示:
0 <= index, val <= 1000- 请不要使用内置的 LinkedList 库。
get,addAtHead,addAtTail,addAtIndex和deleteAtIndex的操作次数不超过2000。
// 单链表
// 单链表
class MyLinkedList {
class ListNode {
int val;
ListNode next;
public ListNode(int val) {
this.val = val;
}
}
int size;
ListNode head;
// 初始化链表
public MyLinkedList() {
head = new ListNode(0);
head.next = null;
size = 0;
}
// 获取第index个索引
public int get(int index) {
if (index < 0 || index >= size) {
return -1;
}
int count = 0;
ListNode node = head.next;
while (node != null) {
if (count == index) return node.val;
node = node.next;
count ++;
}
return -1;
}
// 添加元素到头部
public void addAtHead(int val) {
addAtIndex(0,val);
}
// 添加元素到尾部
public void addAtTail(int val) {
addAtIndex(size,val);
}
// 添加元素
public void addAtIndex(int index, int val) {
if(index > size) {
return;
}
if (index < 0) {
index = 0;
}
ListNode prev = head;
for (int i = 0; i < index; i++) {
prev = prev.next;
}
ListNode listNode = new ListNode(val);
listNode.next = prev.next;
prev.next = listNode;
size++;
}
// 删除元素
public void deleteAtIndex(int index) {
if (index < 0 || index >= size) {
return;
}
size--;
if (index == 0) {
head = head.next;
return;
}
ListNode prev = head;
for (int i = 0; i < index; i++) {
prev = prev.next;
}
prev.next = prev.next.next;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
// 双链表
// 双链表
class MyLinkedList2 {
class ListNode {
int val;
ListNode next;
ListNode prev;
public ListNode(int val) {
this.val = val;
}
}
int size;
ListNode head;
ListNode tail;
// 初始化链表
public MyLinkedList2() {
head = new ListNode(0);
tail = new ListNode(0);
size = 0;
tail.prev = head;
head.next = tail;
}
// 获取第index个索引
public int get(int index) {
if(index < 0 || index >= size) return -1;
// 判断从哪一边开始遍历短
if (index >= size / 2) {
// 从后往前开始遍历
ListNode cur = tail;
for (int i = 0; i < size - index; i++) {
cur = cur.prev;
}
return cur.val;
} else {
// 从前往后遍历
ListNode cur = head.next;
for (int i = 0; i < index; i++) {
cur = cur.next;
}
return cur.val;
}
}
// 添加元素到头部
public void addAtHead(int val) {
addAtIndex(0,val);
}
// 添加元素到尾部
public void addAtTail(int val) {
addAtIndex(size,val);
}
// 添加元素
public void addAtIndex(int index, int val) {
if (index > size) return;
if (index < 0) index = 0;
ListNode cur = head;
for (int i = 0; i < index; i++) {
cur = cur.next;
}
ListNode listNode = new ListNode(val);
listNode.next = cur.next;
cur.next.prev = listNode;
cur.next = listNode;
listNode.prev = cur;
size++;
}
// 删除元素
public void deleteAtIndex(int index) {
if (index < 0 || index >= size) return;
size--;
ListNode curr = head;
for (int i = 0; i < index; i++) {
curr = curr.next;
}
curr.next.next.prev = curr;
curr.next = curr.next.next;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
# 206.反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
2
示例 2:
输入:head = [1,2]
输出:[2,1]
2
示例 3:
输入:head = []
输出:[]
2
提示:
- 链表中节点的数目范围是
[0, 5000] -5000 <= Node.val <= 5000
**进阶:**链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
// 双指针法
// 双指针法
public ListNode reverseList(ListNode head) {
ListNode prev = null;
ListNode curr = head;
ListNode temp = null;
while (curr != null) {
temp = curr.next; // 保存下一个结点
curr.next = prev;
prev = curr;
curr = temp;
}
return prev;
}
2
3
4
5
6
7
8
9
10
11
12
13
// 递归写法
// 递归写法
public ListNode reverseList2(ListNode head) {
return reverse(null, head);
}
private ListNode reverse(ListNode prev, ListNode curr) {
if (curr == null) {
return prev;
}
ListNode temp = null;
temp = curr.next; // 先保存一下节点
curr.next = prev;
// 更新prev,cur的位置
// prev = curr
// curr = temp
return reverse(curr, temp);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 从后向前递归
// 从后向前递归
public ListNode reverseList3(ListNode head) {
// 边缘条件判断
if (head == null) return null;
if (head.next == null) return head;
// 递归调用,翻转第二个结点开始往后的链表
ListNode last = reverseList3(head.next);
// 翻转头结点与第二个结点的指向
head.next.next = head;
// 此时的head节点为尾结点, next需要指向NULL
head.next = null;
return last;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 24.两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:

输入:head = [1,2,3,4]
输出:[2,1,4,3]
2
示例 2:
输入:head = []
输出:[]
2
示例 3:
输入:head = [1]
输出:[1]
2
提示:
- 链表中节点的数目在范围
[0, 100]内 0 <= Node.val <= 100
接下来就是交换相邻两个元素了,此时一定要画图,不画图,操作多个指针很容易乱,而且要操作的先后顺序
初始时,cur指向虚拟头结点,然后进行如下三步:

操作之后,链表如下:

看这个可能就更直观一些了:

对应的C++代码实现如下: (注释中详细和如上图中的三步做对应)
public ListNode swapPairs(ListNode head) {
ListNode dumyhead = new ListNode(-1); // 设置一个虚拟头结点
dumyhead.next = head;
ListNode curr = dumyhead;
ListNode temp; // 保存两个结点后面的节点
ListNode firstNode; // 临时节点。保存两个结点之中的第一个结点
ListNode secondNode; // 临时节点,保存两个结点之中的第二个结点
while (curr.next != null && curr.next.next != null) {
temp = curr.next.next.next;
firstNode = curr.next;
secondNode = curr.next.next;
curr.next = secondNode; // 步骤一
secondNode.next = firstNode; // 步骤二
firstNode.next = temp; // 步骤三
curr = firstNode; // cur移动,准备下一轮交换
}
return dumyhead.next;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 递归
// 递归
public ListNode swapPairs2(ListNode head) {
if(head == null || head.next == null) return head;
// 获取当前节点的下一个结点
ListNode next = head.next;
// 进行递归
ListNode newNode = swapPairs2(next.next);
// 这里进行交换
next.next = head;
head.next = newNode;
return next;
}
2
3
4
5
6
7
8
9
10
11
12
# 19.删除链表的倒数第 N 个结点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:

输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
2
示例 2:
输入:head = [1], n = 1
输出:[]
2
示例 3:
输入:head = [1,2], n = 1
输出:[1]
2
提示:
- 链表中结点的数目为
sz 1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz

public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode dumyhead = new ListNode(-1); // 设置虚拟头结点
dumyhead.next = head;
ListNode slow = dumyhead, fast = dumyhead;
for (int i = 0; i < n; i++) {
fast = fast.next;
}
while (fast.next != null) {
fast = fast.next;
slow = slow.next;
}
slow.next = slow.next.next;
return dumyhead.next;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
// 其他解题思路,解法一.先求出链表长度,然后再次遍历 解法二:全部进栈(带虚拟节点),然后出栈n个,取栈顶元素(也就是要删除元素的前一个元素)
# 面试题 02.07. 链表相交
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
图示两个链表在节点 c1 开始相交**:**
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
示例 1:
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
2
3
4
5
示例 2:
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at '2'
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
2
3
4
5
示例 3:
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
2
3
4
5
提示:
listA中节点数目为mlistB中节点数目为n0 <= m, n <= 3 * 1041 <= Node.val <= 1050 <= skipA <= m0 <= skipB <= n- 如果
listA和listB没有交点,intersectVal为0 - 如果
listA和listB有交点,intersectVal == listA[skipA + 1] == listB[skipB + 1]
简单来说,就是求两个链表交点节点的指针。 这里同学们要注意,交点不是数值相等,而是指针相等。
为了方便举例,假设节点元素数值相等,则节点指针相等。
看如下两个链表,目前curA指向链表A的头结点,curB指向链表B的头结点:

我们求出两个链表的长度,并求出两个链表长度的差值,然后让curA移动到,和curB 末尾对齐的位置,如图:

此时我们就可以比较curA和curB是否相同,如果不相同,同时向后移动curA和curB,如果遇到curA == curB,则找到交点。
// 使用两个指针,从长度相同的位置开始比较
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode newHeadA = headA,newHeadB = headB, currA = headA, currB = headB;
int count1 = 0, count2 = 0, n = 0; // n代表长的链表指针需要移动的步数
while (newHeadA != null) { // 计算链表A的长度
count1++;
newHeadA = newHeadA.next;
}
while (newHeadB != null) {
count2++;
newHeadB = newHeadB.next;
}
if (count1 >= count2) {
n = count1 - count2;
for (int i = 0; i < n; i++) {
currA = currA.next;
}
}else {
n = count2 - count1;
for (int i = 0; i < n; i++) {
currB = currB.next;
}
}
while (currA!= null && currB!= null) {
if (currA == currB) return currA;
currA = currA.next;
currB = currB.next;
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// 使用哈希集合
public ListNode getIntersectionNode2(ListNode headA, ListNode headB) {
HashSet<ListNode> visited = new HashSet<>();
ListNode node = headA;
while (node != null) {
visited.add(node);
node = node.next;
}
node = headB;
while (node != null) {
if (visited.contains(node)) return node;
node = node.next;
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 双指针,原理:A+B 组成的链表 和 B+A组成的链表一起遍历
// 不想交情况 m==n,遍历到各自链表末尾就会都会NULL,然后退出
// m≠n,遍历到m+n都会同时为NULL,然后退出
public ListNode getIntersectionNode3(ListNode headA, ListNode headB){
if (headA == null || headB == null) return null;
ListNode pA = headA, pB = headB;
while (pA != pB) { //遍历到最后如果没有相交,两者都会为NULL人,相等退出
pA = pA==null?headB:pA.next;
pB = pB==null?headA:pB.next;
}
return pA;
}
2
3
4
5
6
7
8
9
10
11
12
# 142.环形链表 II
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。
2
3
示例 2:
输入:head = [1,2], pos = 0
输出:返回索引为 0 的链表节点
解释:链表中有一个环,其尾部连接到第一个节点。
2
3
示例 3:
输入:head = [1], pos = -1
输出:返回 null
解释:链表中没有环。
2
3
提示:
- 链表中节点的数目范围在范围
[0, 104]内 -105 <= Node.val <= 105pos的值为-1或者链表中的一个有效索引
// 哈希表
public ListNode detectCycle2(ListNode head) {
HashSet<ListNode> visited = new HashSet<>();
ListNode pos = head;
while (pos != null) {
if (visited.contains(pos)) {
return pos;
}else {
visited.add(pos);
}
pos = pos.next;
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
// 快慢指针
// 快慢指针
public ListNode detectCycle(ListNode head) {
ListNode slow = head, fast = head;
while (fast != null && fast.next!= null) {
slow = slow.next;
fast = fast.next.next;
// 此时快慢指针已经相遇
if (slow == fast) {
ListNode index1 = head,index2 = slow;
while (index1 != index2) {
index1 = index1.next;
index2 = index2.next;
}
return index1;
}
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
主要考察两知识点:
- 判断链表是否环
- 如果有环,如何找到这个环的入口
# 判断链表是否有环
可以使用快慢指针法,分别定义 fast 和 slow 指针,从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在途中相遇 ,说明这个链表有环。
为什么fast 走两个节点,slow走一个节点,有环的话,一定会在环内相遇呢,而不是永远的错开呢
首先第一点:fast指针一定先进入环中,如果fast指针和slow指针相遇的话,一定是在环中相遇,这是毋庸置疑的。
那么来看一下,为什么fast指针和slow指针一定会相遇呢?
可以画一个环,然后让 fast指针在任意一个节点开始追赶slow指针。
会发现最终都是这种情况, 如下图:

fast和slow各自再走一步, fast和slow就相遇了
这是因为fast是走两步,slow是走一步,其实相对于slow来说,fast是一个节点一个节点的靠近slow的,所以fast一定可以和slow重合。

# 如果有环,如何找到这个环的入口
此时已经可以判断链表是否有环了,那么接下来要找这个环的入口了。
假设从头结点到环形入口节点 的节点数为x。 环形入口节点到 fast指针与slow指针相遇节点 节点数为y。 从相遇节点 再到环形入口节点节点数为 z。 如图所示:

那么相遇时: slow指针走过的节点数为: x + y, fast指针走过的节点数:x + y + n (y + z),n为fast指针在环内走了n圈才遇到slow指针, (y+z)为 一圈内节点的个数A。
因为fast指针是一步走两个节点,slow指针一步走一个节点, 所以 fast指针走过的节点数 = slow指针走过的节点数 * 2:
(x + y) * 2 = x + y + n (y + z)
两边消掉一个(x+y): x + y = n (y + z)
因为要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
所以要求x ,将x单独放在左面:x = n (y + z) - y ,
再从n(y+z)中提出一个 (y+z)来,整理公式之后为如下公式:x = (n - 1) (y + z) + z 注意这里n一定是大于等于1的,因为 fast指针至少要多走一圈才能相遇slow指针。
这个公式说明什么呢?
先拿n为1的情况来举例,意味着fast指针在环形里转了一圈之后,就遇到了 slow指针了。
当 n为1的时候,公式就化解为 x = z,
这就意味着,从头结点出发一个指针,从相遇节点 也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是 环形入口的节点。
也就是在相遇节点处,定义一个指针index1,在头结点处定一个指针index2。
让index1和index2同时移动,每次移动一个节点, 那么他们相遇的地方就是 环形入口的节点。
动画如下:

那么 n如果大于1是什么情况呢,就是fast指针在环形转n圈之后才遇到 slow指针。
其实这种情况和n为1的时候 效果是一样的,一样可以通过这个方法找到 环形的入口节点,只不过,index1 指针在环里 多转了(n-1)圈,然后再遇到index2,相遇点依然是环形的入口节点。
在推理过程中,大家可能有一个疑问就是:为什么第一次在环中相遇,slow的 步数 是 x+y 而不是 x + 若干环的长度 + y 呢?

首先slow进环的时候,fast一定是先进环来了。
如果slow进环入口,fast也在环入口,那么把这个环展开成直线,就是如下图的样子:

可以看出如果slow 和 fast同时在环入口开始走,一定会在环入口3相遇,slow走了一圈,fast走了两圈。
重点来了,slow进环的时候,fast一定是在环的任意一个位置,如图:
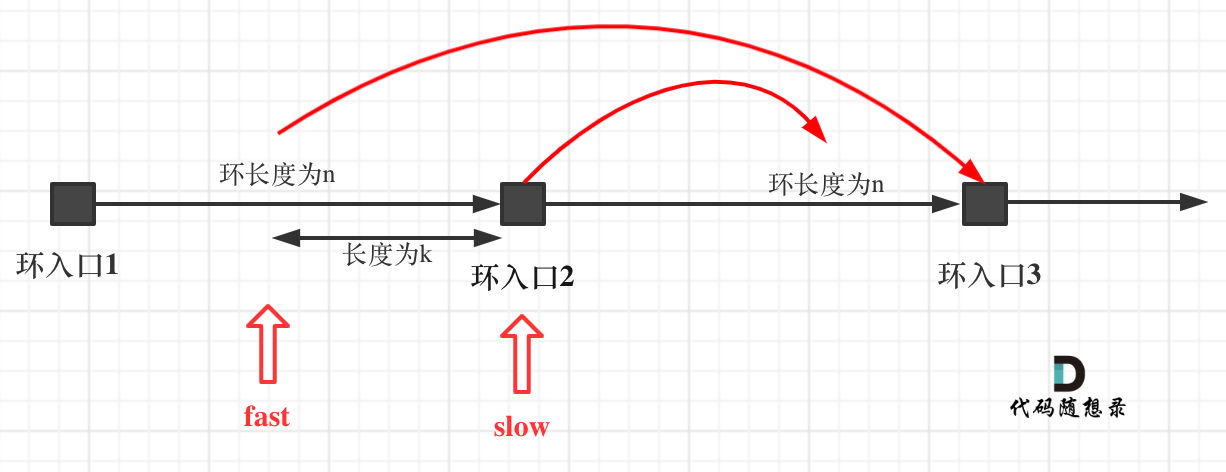
那么fast指针走到环入口3的时候,已经走了k + n 个节点,slow相应的应该走了(k + n) / 2 个节点。
因为k是小于n的(图中可以看出),所以(k + n) / 2 一定小于n。
也就是说slow一定没有走到环入口3,而fast已经到环入口3了。
这说明什么呢?
在slow开始走的那一环已经和fast相遇了。
那有同学又说了,为什么fast不能跳过去呢? 在刚刚已经说过一次了,fast相对于slow是一次移动一个节点,所以不可能跳过去。
# 哈希表
哈希表是根据关键码的值而直接进行访问的数据结构。
一般哈希表都是用来快速判断一个元素是否出现集合里。
# 哈希函数
哈希函数,把学生的姓名直接映射为哈希表上的索引,然后就可以通过查询索引下标快速知道这位同学是否在这所学校里了。
哈希函数如下图所示,通过hashCode把名字转化为数值,一般hashcode是通过特定编码方式,可以将其他数据格式转化为不同的数值,这样就把学生名字映射为哈希表上的索引数字了。

# 哈希碰撞

一般哈希碰撞有两种解决方法, 拉链法和线性探测法。
# 拉链法
刚刚小李和小王在索引1的位置发生了冲突,发生冲突的元素都被存储在链表中。 这样我们就可以通过索引找到小李和小王了
# 线性探测法
使用线性探测法,一定要保证tableSize大于dataSize。 我们需要依靠哈希表中的空位来解决碰撞问题。
例如冲突的位置,放了小李,那么就向下找一个空位放置小王的信息。所以要求tableSize一定要大于dataSize ,要不然哈希表上就没有空置的位置来存放 冲突的数据了。如图所示:
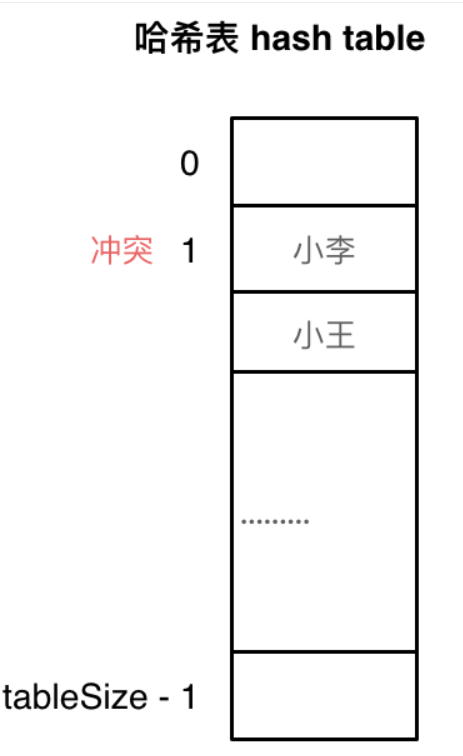
# 常见的三种哈希结构
当我们想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构。
- 数组
- set (集合)
- map(映射)
# 242.有效的字母异位词
给定两个字符串 *s* 和 *t* ,编写一个函数来判断 *t* 是否是 *s* 的字母异位词。
**注意:**若 *s* 和 *t* 中每个字符出现的次数都相同,则称 *s* 和 *t* 互为字母异位词。
示例 1:
输入: s = "anagram", t = "nagaram"
输出: true
2
示例 2:
输入: s = "rat", t = "car"
输出: false
2
提示:
1 <= s.length, t.length <= 5 * 104s和t仅包含小写字母
public static boolean isAnagram(String s, String t) {
if (s.length() != t.length()) return false;
HashMap<Character, Integer> map = new HashMap<>();
for (int i = 0; i < s.length(); i++) {
map.put(s.charAt(i),map.getOrDefault(s.charAt(i), 0) + 1);
}
for (int i = 0; i < t.length(); i++) {
if (map.containsKey(t.charAt(i))) {
if (map.get(t.charAt(i)) == 0) return false;
else {
map.put(t.charAt(i),map.get(t.charAt(i)) - 1);
}
} else {
return false;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 349.两个数组的交集
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
2
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
解释:[4,9] 也是可通过的
2
3
提示:
1 <= nums1.length, nums2.length <= 10000 <= nums1[i], nums2[i] <= 1000
public static int[] intersection(int[] nums1, int[] nums2) {
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums1.length; i++) {
map.put(nums1[i], map.getOrDefault(map.get(nums1[i]),0)+1);
}
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < nums2.length; i++) {
if (map.getOrDefault(nums2[i], 0) > 0) {
if (!list.contains(nums2[i])) {
list.add(nums2[i]);
}
map.put(nums2[i],map.get(nums2[i]) - 1);
}
}
int[] res = new int[list.size()];
for (int i = 0; i < list.size(); i++) {
res[i] = list.get(i);
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 1.两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
2
3
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
2
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
2
public static int[] twoSum(int[] nums, int target) {
HashMap<Integer, Integer> hashMap = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
if (hashMap.containsKey(nums[i])) {
return new int[] {hashMap.get(nums[i]), i };
} else {
hashMap.put(target - nums[i], i);
}
}
return null;
}
2
3
4
5
6
7
8
9
10
11
# 454.四数相加 II
给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足:
0 <= i, j, k, l < nnums1[i] + nums2[j] + nums3[k] + nums4[l] == 0
示例 1:
输入:nums1 = [1,2], nums2 = [-2,-1], nums3 = [-1,2], nums4 = [0,2]
输出:2
解释:
两个元组如下:
1. (0, 0, 0, 1) -> nums1[0] + nums2[0] + nums3[0] + nums4[1] = 1 + (-2) + (-1) + 2 = 0
2. (1, 1, 0, 0) -> nums1[1] + nums2[1] + nums3[0] + nums4[0] = 2 + (-1) + (-1) + 0 = 0
2
3
4
5
6
示例 2:
输入:nums1 = [0], nums2 = [0], nums3 = [0], nums4 = [0]
输出:1
2
提示:
n == nums1.lengthn == nums2.lengthn == nums3.lengthn == nums4.length1 <= n <= 200-228 <= nums1[i], nums2[i], nums3[i], nums4[i] <= 228
public static int fourSumCount(int[] nums1, int[] nums2, int[] nums3, int[] nums4) {
HashMap<Integer, Integer> hashMap = new HashMap<>();
int temp = 0,count = 0;
for (int i : nums1) {
for (int j : nums2) {
temp = i + j;
hashMap.put(temp, hashMap.getOrDefault(temp, 0 ) + 1);
}
}
for(int i : nums3) {
for (int j : nums4) {
temp = i + j;
if (hashMap.containsKey(0 - temp)) {
count += hashMap.get(0-temp);
}
}
}
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 383.赎金信
给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。
如果可以,返回 true ;否则返回 false 。
magazine 中的每个字符只能在 ransomNote 中使用一次。
示例 1:
输入:ransomNote = "a", magazine = "b"
输出:false
2
示例 2:
输入:ransomNote = "aa", magazine = "ab"
输出:false
2
示例 3:
输入:ransomNote = "aa", magazine = "aab"
输出:true
2
提示:
1 <= ransomNote.length, magazine.length <= 105ransomNote和magazine由小写英文字母组成
public static boolean canConstruct(String ransomNote, String magazine) {
if (ransomNote.length() > magazine.length()) {
return false;
}
HashMap<Character, Integer> map = new HashMap<>();
for (int i = 0; i < magazine.length(); i++) {
char c = magazine.charAt(i);
map.put(c, map.getOrDefault(c, 0) + 1);
}
for (int i = 0; i < ransomNote.length(); i++) {
char c = ransomNote.charAt(i);
map.put(c, map.getOrDefault(c,0) - 1);
if (map.get(c) < 0) return false;
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 15.三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请
你返回所有和为 0 且不重复的三元组。
**注意:**答案中不可以包含重复的三元组。
示例 1:
输入:nums = [-1,0,1,2,-1,-4]
输出:[[-1,-1,2],[-1,0,1]]
解释:
nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。
nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。
nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。
不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。
注意,输出的顺序和三元组的顺序并不重要。
2
3
4
5
6
7
8
示例 2:
输入:nums = [0,1,1]
输出:[]
解释:唯一可能的三元组和不为 0 。
2
3
示例 3:
输入:nums = [0,0,0]
输出:[[0,0,0]]
解释:唯一可能的三元组和为 0 。
2
3
public List<List<Integer>> threeSum(int[] nums) {
Arrays.sort(nums);
List<List<Integer>> result = new ArrayList<>();
for (int i = 0; i < nums.length; i++) {
// 排序之后如果第一个元素已经大于零,那么无论如何组合都不可能凑成三元组,直接返回结果就可以了
if (nums[i] > 0) return result;
// a的去重
if (i > 0 && nums[i] == nums[i-1]) continue;
int left = i + 1;
int right = nums.length - 1;
while (right > left) {
// 去重复逻辑如果放在这里,0,0,0 的情况,可能直接导致 right<=left 了,从而漏掉了 0,0,0 这种三元组
// 去重
// while (nums[left] == nums[left + 1]) left++;
// while (nums[right] == nums[right - 1]) right--;
if (nums[i] + nums[left] + nums[right] > 0) right --;
else if (nums[i] + nums[left] + nums[right] < 0) {
left++;
}else {
ArrayList<Integer> list = new ArrayList<>();
list.add(nums[i]);
list.add(nums[left]);
list.add(nums[right]);
result.add(list);
// 对b和c去重
while (right > left && nums[left] == nums[left + 1]) left++;
while (right > left && nums[right] == nums[right - 1]) right--;
// 找到答案,双指针同时收缩
left++;
right--;
}
}
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 18.四数之和
给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复):
0 <= a, b, c, d < na、b、c和d互不相同nums[a] + nums[b] + nums[c] + nums[d] == target
你可以按 任意顺序 返回答案 。
示例 1:
输入:nums = [1,0,-1,0,-2,2], target = 0
输出:[[-2,-1,1,2],[-2,0,0,2],[-1,0,0,1]]
2
示例 2:
输入:nums = [2,2,2,2,2], target = 8
输出:[[2,2,2,2]]
2
提示:
1 <= nums.length <= 200-109 <= nums[i] <= 109-109 <= target <= 109
public static List<List<Integer>> fourSum(int[] nums, int target) {
Arrays.sort(nums);
int n = nums.length;
ArrayList<List<Integer>> result = new ArrayList<>();
for (int i = 0; i < n; i++) {
// 排序后的第一个结果如果大于target,就没有结果(应该去掉)
// if (nums[i] > target) return result;
if (nums[i] > 0 && nums[i] > target) return result;
// 去重a
if (i > 0 && nums[i] == nums[i-1]) continue;
for (int j = i+1; j < n; j++) {
// 去重b
if (j > i+1 && nums[j] == nums[j-1]) continue;
int left = j +1, right = nums.length - 1;
while (right > left) {
long sum = (long)nums[i] + nums[j] + nums[left] + nums[right];
if ( sum > target) {
right --;
} else if (sum < target) {
left++;
}else {
// ArrayList<Integer> list = new ArrayList<>();
// list.add(nums[i]);
// list.add(nums[j]);
// list.add(nums[left]);
// list.add(nums[right]);
result.add(Arrays.asList(nums[i],nums[j],nums[left],nums[right]));
// 对c和d去重
while (right > left && nums[left] == nums[left+1]) left++;
while (right > left && nums[right] == nums[right-1]) right--;
left++;
right--;
}
}
}
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 字符串
# 344.反转字符串
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须**原地 (opens new window)修改输入数组**、使用 O(1) 的额外空间解决这一问题。
示例 1:
输入:s = ["h","e","l","l","o"]
输出:["o","l","l","e","h"]
2
示例 2:
输入:s = ["H","a","n","n","a","h"]
输出:["h","a","n","n","a","H"]
2
提示:
1 <= s.length <= 105s[i]都是 ASCII (opens new window) 码表中的可打印字符
public static void reverseString(char[] s) {
int n = s.length;
for (int i = 0; i < n / 2; i++) {
char c = s[i];
s[i] = s[n-1-i];
s[n-1-i] = c;
}
}
public static void reverseString2(char[] s) {
int n = s.length;
for (int left = 0,right = n - 1; left < right; left++, right--) {
char c = s[left];
s[left] = s[right];
s[right] = c;
}
}
public static void reverseString3(char[] s) {
int n = s.length;
for (int left = 0,right = n - 1; left < right; left++, right--) {
s[left] ^= s[right]; // a = a ^ b
s[right] ^= s[left]; // b = b ^ (a^b) = a, a = a ^ b;
s[left] ^= s[right]; // a = (a ^ b) ^ a = b
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 541.反转字符串 II
给定一个字符串 s 和一个整数 k,从字符串开头算起,每计数至 2k 个字符,就反转这 2k 字符中的前 k 个字符。
- 如果剩余字符少于
k个,则将剩余字符全部反转。 - 如果剩余字符小于
2k但大于或等于k个,则反转前k个字符,其余字符保持原样。
示例 1:
输入:s = "abcdefg", k = 2
输出:"bacdfeg"
2
示例 2:
输入:s = "abcd", k = 2
输出:"bacd"
2
提示:
1 <= s.length <= 104s仅由小写英文组成1 <= k <= 104
public static String reverseStr(String s, int k) {
char[] arr = s.toCharArray();
int n = arr.length;
for (int i = 0; i < n; i+= 2*k) {
// 少于k则i+k > n,末尾全部反转。
// 末尾大于k则 n > i + k,只反转末尾前k个
reverse(arr,i,Math.min(n,i+k) - 1);
}
return new String(arr);
}
// 反转字符串
public static void reverse(char[] s, int start, int end) {
while (start < end) {
char c = s[start];
s[start] = s[end];
s[end] = c;
start++;
end--;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 剑指 Offer 05. 替换空格
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
示例 1:
输入:s = "We are happy."
输出:"We%20are%20happy."
2
限制:
0 <= s 的长度 <= 10000
public static String replaceSpace(String s) {
String str = "";
char[] arr = s.toCharArray();
for (int i = 0; i < arr.length; i++) {
if (arr[i] == ' ') str += "%20";
else str += arr[i];
}
return str;
}
2
3
4
5
6
7
8
9
# 151.反转字符串中的单词
给你一个字符串 s ,请你反转字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
**注意:**输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
示例 1:
输入:s = "the sky is blue"
输出:"blue is sky the"
2
示例 2:
输入:s = " hello world "
输出:"world hello"
解释:反转后的字符串中不能存在前导空格和尾随空格。
2
3
示例 3:
输入:s = "a good example"
输出:"example good a"
解释:如果两个单词间有多余的空格,反转后的字符串需要将单词间的空格减少到仅有一个。
2
3
提示:
1 <= s.length <= 104s包含英文大小写字母、数字和空格' 's中 至少存在一个 单词
利用库函数
public static String reverseWords(String s) {
// 去掉两端空白
s = s.trim();
String[] split = s.split("\\s+");
List<String> list = Arrays.asList(split);
Collections.reverse(list);
return String.join(" ",list);
}
2
3
4
5
6
7
8
// 自己实现
// 方法2 : 1.先去掉多余的空格 2. 反转整个字符串 3. 反转每个单词
public static String reverseWords2(String s) {
StringBuffer stringBuffer = trimSpace(s);
reverseString(stringBuffer, 0,stringBuffer.length()-1);
reverseEachWords(stringBuffer);
return stringBuffer.toString();
}
// 去掉字符串左右以及中间多余的单词
public static StringBuffer trimSpace(String s) {
int left = 0, right = s.length() - 1;
while (left <= right && s.charAt(left) == ' ')left++;
while (left <= right && s.charAt(right) == ' ') right--;
StringBuffer sb = new StringBuffer();
while (left <= right) {
char c = s.charAt(left);
if (c != ' ') sb.append(c);
else if (sb.charAt(sb.length() - 1)!= ' ') {
sb.append(c);
}
left++;
}
return sb;
}
// 反转整个字符串
public static void reverseString(StringBuffer sb, int left, int right) {
while (left < right) {
char c = sb.charAt(left);
sb.setCharAt(left, sb.charAt(right));
sb.setCharAt(right,c);
left++;
right--;
}
}
// 反转每个单词
public static void reverseEachWords(StringBuffer sb) {
int n = sb.length();
int start = 0,end = 0;
while (start < n){
while (end < n && sb.charAt(end) != ' ') end++;
// 反转单词
reverseString(sb,start, end-1);
start = end + 1;
end++;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# 剑指 Offer 58 - II. 左旋转字符串
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"。
示例 1:
输入: s = "abcdefg", k = 2
输出: "cdefgab"
2
示例 2:
输入: s = "lrloseumgh", k = 6
输出: "umghlrlose"
2
限制:
1 <= k < s.length <= 10000
// 思路:旋转全部字符串
// 然后分别旋转
public static String reverseLeftWords(String s, int n) {
StringBuffer sb = new StringBuffer(s);
sb.reverse();
reverseString(sb,0,sb.length() - n - 1);
reverseString(sb,sb.length() - n, sb.length() - 1);
return sb.toString();
}
public static void reverseString(StringBuffer sb, int left, int right) {
while (left < right) {
char c = sb.charAt(left);
sb.setCharAt(left, sb.charAt(right));
sb.setCharAt(right, c);
left++;
right--;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 28. 实现 strStr()
- 找出字符串中第一个匹配项的下标
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
示例 1:
输入:haystack = "sadbutsad", needle = "sad"
输出:0
解释:"sad" 在下标 0 和 6 处匹配。
第一个匹配项的下标是 0 ,所以返回 0 。
2
3
4
示例 2:
输入:haystack = "leetcode", needle = "leeto"
输出:-1
解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。
2
3
提示:
1 <= haystack.length, needle.length <= 104haystack和needle仅由小写英文字符组成
// KMP算法
public static void getNext(int[] next, String s) {
int j = 0;
next[0] = 0;
// i后缀末尾位置,j前缀末尾位置,也代表最长相等前缀长度
for (int i = 1; i < s.length(); i++) {
// 前后缀不相等的情况
while (j > 0 && s.charAt(i) != s.charAt(j)) { // j要保证大于0,因为下面有取j-1作为数组下标的操作
j = next[j-1]; // 注意这里,是要找前一位的对应的回退位置了
}
// 前后最相等的情况
if (s.charAt(i) == s.charAt(j)) {
j++;
}
next[i] = j;
}
}
public static int strStr(String haystack, String needle) {
if (needle.length() == 0) {
return 0;
}
int[] next = new int[needle.length()];
getNext(next, needle);
int j = 0;
for (int i = 0; i < haystack.length(); i++) {
while (j > 0 &&haystack.charAt(i) != needle.charAt(j)) {
j = next[j-1];
}
if (haystack.charAt(i) == needle.charAt(j)) {
j++;
}
if (j == needle.length() ) {
return (i - needle.length() + 1);
}
}
return -1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# KMP
KMP的经典思想就是:当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。
# 什么是KMP
因为是由这三位学者发明的:Knuth,Morris和Pratt,所以取了三位学者名字的首字母。所以叫做KMP
# 前缀表
写过KMP的同学,一定都写过next数组,那么这个next数组究竟是个啥呢?
next数组就是一个前缀表(prefix table)。
前缀表有什么作用呢?
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。
为了清楚地了解前缀表的来历,我们来举一个例子:
要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
请记住文本串和模式串的作用,对于理解下文很重要,要不然容易看懵。所以说三遍:
要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
如动画所示:

# 最长公共前后缀
文章中字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串。
后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
我查了一遍 算法导论 和 算法4里KMP的章节,都没有提到 “最长公共前后缀”这个词,也不知道从哪里来了,我理解是用“最长相等前后缀” 更准确一些。
因为前缀表要求的就是相同前后缀的长度。
而最长公共前后缀里面的“公共”,更像是说前缀和后缀公共的长度。这其实并不是前缀表所需要的。
所以字符串a的最长相等前后缀为0。 字符串aa的最长相等前后缀为1。 字符串aaa的最长相等前后缀为2。 等等.....。
# 为什么一定要用前缀表
这就是前缀表,那为啥就能告诉我们 上次匹配的位置,并跳过去呢?
回顾一下,刚刚匹配的过程在下标5的地方遇到不匹配,模式串是指向f,如图:
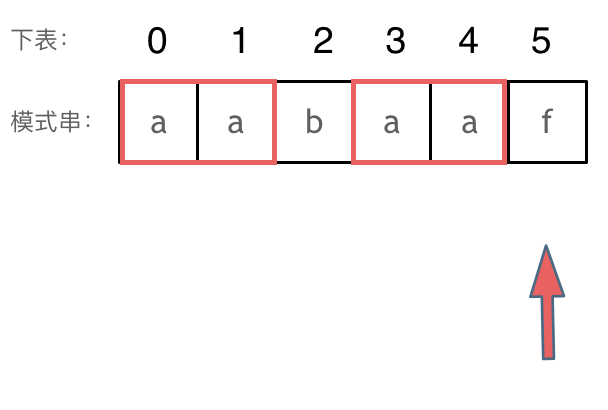
然后就找到了下标2,指向b,继续匹配:如图

- 前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;
- 后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串
# 459.重复的子字符串
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
示例 1:
输入: s = "abab"
输出: true
解释: 可由子串 "ab" 重复两次构成。
2
3
示例 2:
输入: s = "aba"
输出: false
2
示例 3:
输入: s = "abcabcabcabc"
输出: true
解释: 可由子串 "abc" 重复四次构成。 (或子串 "abcabc" 重复两次构成。)
2
3
提示:
1 <= s.length <= 104s由小写英文字母组成
思路:

假设字符串s使用多个重复子串构成(这个子串是最小重复单位),重复出现的子字符串长度是x,所以s是由n * x组成。
因为字符串s的最长相同前后缀的长度一定是不包含s本身,所以 最长相同前后缀长度必然是m * x,而且 n - m = 1,(如上图)
所以如果 nx % (n - m)x = 0,就可以判定有重复出现的子字符串。
public static boolean repeatedSubstringPattern2(String s) {
int len = s.length();
int[] next = new int[len];
int j = 0;
next[0] = 0;
// i表示后缀末尾位置,j表示前缀末尾位置,同时也表示最长前缀长度
for (int i = 1; i < s.length(); i++) {
// 前后缀不相等
while (j > 0 && s.charAt(i) != s.charAt(j)) {
j = next[j-1];
}
// 前后缀相等
if (s.charAt(i) == s.charAt(j)) {
j++;
}
next[i] = j;
}
if (next[len-1] != 0 && len % (len - next[len -1]) == 0) return true;
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 双指针法
# 27.移除元素
给你一个数组 nums 和一个值 val,你需要 原地 (opens new window) 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 (opens new window)修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以**「引用」**方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝
int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
2
3
4
5
6
7
8
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
2
3
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,4,0,3]
解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
2
3
public int removeElement(int[] nums, int val) {
int slow = 0, fast = 0;
for (fast = 0; fast < nums.length; fast++) {
if (nums[fast] != val) {
nums[slow++] = nums[fast];
}
}
return slow;
}
2
3
4
5
6
7
8
9
# 344.反转字符串
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须**原地 (opens new window)修改输入数组**、使用 O(1) 的额外空间解决这一问题。
示例 1:
输入:s = ["h","e","l","l","o"]
输出:["o","l","l","e","h"]
2
示例 2:
输入:s = ["H","a","n","n","a","h"]
输出:["h","a","n","n","a","H"]
2
提示:
1 <= s.length <= 105s[i]都是 ASCII (opens new window) 码表中的可打印字符
public static void reverseString(char[] s) {
int n = s.length;
for (int i = 0,j = n - 1; i < j ; i++, j--) {
s[i] ^= s[j];
s[j] ^= s[i];
s[i] ^= s[j];
}
}
2
3
4
5
6
7
8
# 剑指 Offer 05. 替换空格
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
示例 1:
输入:s = "We are happy."
输出:"We%20are%20happy."
2
public String replaceSpace(String s) {
if (s.length() == 0 || s == null) return s;
StringBuffer sb = new StringBuffer();
for (int i = 0; i < s.length(); i++) {
// 有空格,就将空格扩容三倍
if (s.charAt(i) == ' ') sb.append(" ");
}
// 没有空格就直接返回
if (sb.length() == 0) return s;
int left = s.length() - 1; // 左指针指向原始字符串的最后一个位置
s+=sb.toString();
int right = s.length() -1; // 右指针指向扩容两倍空格字符串的最后一个位置
char[] chars = s.toCharArray();
while (left >= 0) {
if (chars[left] == ' ') {
chars[right--] = '0';
chars[right--] = '2';
chars[right] = '%';
} else {
chars[right] = chars[left];
}
left--;
right--;
}
return new String(chars);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 151.反转字符串中的单词
给你一个字符串 s ,请你反转字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
**注意:**输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
示例 1:
输入:s = "the sky is blue"
输出:"blue is sky the"
2
示例 2:
输入:s = " hello world "
输出:"world hello"
解释:反转后的字符串中不能存在前导空格和尾随空格。
2
3
示例 3:
输入:s = "a good example"
输出:"example good a"
解释:如果两个单词间有多余的空格,反转后的字符串需要将单词间的空格减少到仅有一个。
2
3
// 思路: 1.去掉两端空格以及中间多余的空格,2.反转整个字符串 3. 反转每一个单词
public String reverseWords(String s) {
StringBuffer sb = trimSpace(s);
int n = sb.length();
reverseString(sb,0, n-1);
reverseEachWords(sb);
return sb.toString();
}
// 去掉两端的空格,以及中间的空格
public StringBuffer trimSpace(String str) {
int i = 0, j = str.length() - 1;
StringBuffer sb = new StringBuffer();
while (str.charAt(i) == ' ') i++;
while (str.charAt(j) == ' ') j--;
while (i <= j) {
if (str.charAt(i) != ' ') sb.append(str.charAt(i));
else if (sb.charAt(sb.length() -1) != ' ') {
sb.append(str.charAt(i));
}
i++;
}
return sb;
}
// 反转字符串
public void reverseString(StringBuffer sb, int left, int right) {
while (left < right) {
char c = sb.charAt(left);
sb.setCharAt(left, sb.charAt(right));
sb.setCharAt(right, c);
left++;
right--;
}
}
public void reverseEachWords(StringBuffer sb){
int start = 0;
int end = 0;
int n = sb.length();
while (end < n) {
while (end < n && sb.charAt(end) != ' ') end ++;
reverseString(sb,start, end - 1);
start = end+1;
end++;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# 206.反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:

输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
2
示例 2:

输入:head = [1,2]
输出:[2,1]
2
示例 3:
输入:head = []
输出:[]
2
public ListNode reverseList(ListNode head) {
ListNode prev = null, curr = head;
while (curr != null) {
ListNode temp = curr.next;
curr.next = prev;
prev = curr;
curr = temp;
}
return prev;
}
2
3
4
5
6
7
8
9
10
# 19.删除链表的倒数第 N 个结点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:

输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
2
示例 2:
输入:head = [1], n = 1
输出:[]
2
示例 3:
输入:head = [1,2], n = 1
输出:[1]
2
提示:
- 链表中结点的数目为
sz 1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode VirtualNode = new ListNode(-1); // 创建一个虚拟节点
VirtualNode.next = head;
ListNode slow = VirtualNode, fast = VirtualNode;
for (int i = 0; i < n; i++) {
fast = fast.next;
}
while (fast.next != null) {
slow = slow.next;
fast = fast.next;
}
slow.next = slow.next.next;
return VirtualNode.next;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 面试题 02.07. 链表相交
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
图示两个链表在节点 c1 开始相交**:**
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
示例 1:
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
2
3
4
5
示例 2:
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at '2'
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
2
3
4
5
示例 3:
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
2
3
4
5
提示:
listA中节点数目为mlistB中节点数目为n0 <= m, n <= 3 * 1041 <= Node.val <= 1050 <= skipA <= m0 <= skipB <= n- 如果
listA和listB没有交点,intersectVal为0 - 如果
listA和listB有交点,intersectVal == listA[skipA + 1] == listB[skipB + 1]
// 解法一:先求出两个链表的差,然后再一起遍历
public ListNode getIntersectionNode(ListNode headA, ListNode headB){
ListNode pA = headA, pB = headB;
int n = getLength(pA),m = getLength(pB);
if (m > n) {
for (int i = 0; i < m - n; i++) {
pB = pB.next;
}
} else {
for (int i = 0; i < n - m; i++) {
pA = pA.next;
}
}
while (pA != null && pB != null) {
if (pA == pB) return pA;
pA = pA.next;
pB = pB.next;
}
return null;
}
int getLength(ListNode head) {
int n =0;
ListNode p = head;
while (p!= null) {
n++;
p = p.next;
}
return n;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// 解法二:利用A+B B+A
// 双指针,原理:A+B 组成的链表 和 B+A组成的链表一起遍历
// 不想交情况 m==n,遍历到各自链表末尾就会都会NULL,然后退出
// m≠n,遍历到m+n都会同时为NULL,然后退出
public ListNode getIntersectionNode3(ListNode headA, ListNode headB){
if (headA == null || headB == null) return null;
ListNode pA = headA, pB = headB;
while (pA != pB) {
pA = pA == null ? headB : pA.next;
pB = pB == null ? headA : pB.next;
}
return pA;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 142.环形链表 II
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
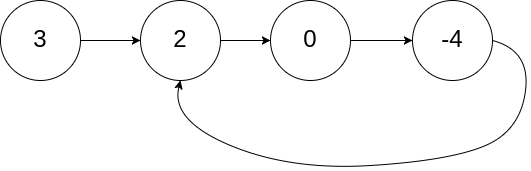
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。
2
3
示例 2:
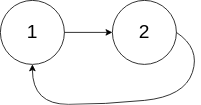
输入:head = [1,2], pos = 0
输出:返回索引为 0 的链表节点
解释:链表中有一个环,其尾部连接到第一个节点。
2
3
示例 3:

输入:head = [1], pos = -1
输出:返回 null
解释:链表中没有环。
2
3
提示:
- 链表中节点的数目范围在范围
[0, 104]内 -105 <= Node.val <= 105pos的值为-1或者链表中的一个有效索引
public ListNode detectCycle(ListNode head) {
ListNode fast = head, slow = head;
while (fast != null && fast.next!= null) {
slow = slow.next;
fast = fast.next.next;
if (slow == fast) {
ListNode index1 = head;
ListNode index2 = fast;
while (index1 != index2) {
index1 = index1.next;
index2 = index2.next;
}
return index2;
}
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 15.三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请
你返回所有和为 0 且不重复的三元组。
**注意:**答案中不可以包含重复的三元组。
示例 1:
输入:nums = [-1,0,1,2,-1,-4]
输出:[[-1,-1,2],[-1,0,1]]
解释:
nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。
nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。
nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。
不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。
注意,输出的顺序和三元组的顺序并不重要。
2
3
4
5
6
7
8
示例 2:
输入:nums = [0,1,1]
输出:[]
解释:唯一可能的三元组和不为 0 。
2
3
示例 3:
输入:nums = [0,0,0]
输出:[[0,0,0]]
解释:唯一可能的三元组和为 0 。
2
3
提示:
3 <= nums.length <= 3000-105 <= nums[i] <= 105
public static List<List<Integer>> threeSum(int[] nums) {
Arrays.sort(nums);
ArrayList<List<Integer>> lists = new ArrayList<>();
int n = nums.length;
for (int a = 0; a < n; a++) {
// 排序后第一个数字大于0,后面的就不会有符合题意的答案了
if (nums[a] > 0) return lists;
// 对a进行去重。用nums[a-1] == nums[a]的好处就是,a已经在前面用过了
if (a >= 1 && nums[a-1] == nums[a]) continue;
int b = a + 1, c= n - 1;
while (b < c) {
int result = nums[a] + nums[b] +nums[c];
if (result > 0) c--;
else if (result < 0) b++;
else {
lists.add(Arrays.asList(nums[a],nums[b],nums[c]));
// 对b和c进行去重
while (b < c && nums[b+1] == nums[b]) b++;
while (b < c && nums[c] == nums[c-1]) c--;
b++;
c--;
}
}
}
return lists;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 18.四数之和
给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复):
0 <= a, b, c, d < na、b、c和d互不相同nums[a] + nums[b] + nums[c] + nums[d] == target
你可以按 任意顺序 返回答案 。
示例 1:
输入:nums = [1,0,-1,0,-2,2], target = 0
输出:[[-2,-1,1,2],[-2,0,0,2],[-1,0,0,1]]
2
示例 2:
输入:nums = [2,2,2,2,2], target = 8
输出:[[2,2,2,2]]
2
提示:
1 <= nums.length <= 200-109 <= nums[i] <= 109-109 <= target <= 109
public static List<List<Integer>> fourSum(int[] nums, int target) {
ArrayList<List<Integer>> lists = new ArrayList<>();
Arrays.sort(nums);
int n = nums.length;
for (int a= 0; a < n; a++) {
// target可能为负数,所以不能只通过一个条件nums[a] > target来判断是否结束
if (nums[a] > 0 && nums[a] > target) return lists;
// 对a进行去重
if (a > 0 && nums[a] == nums[a-1]) continue;
for (int b = a + 1; b < n; b++) {
// 对b进行去重
if (b > a+1 && nums[b] == nums[b-1]) continue;
int c = b + 1 , d = n - 1;
while (c < d) {
long result = nums[a] + nums[b] + nums[c] + nums[d];
if (result > target) d--;
else if (result < target) c++;
else {
lists.add(Arrays.asList(nums[a], nums[b], nums[c], nums[d]));
// 对c进行去重
while (c < d && nums[c] == nums[c+1]) c++;
// 对d进行去重
while (c < d && nums[d] == nums[d-1]) d--;
c++;
d--;
}
}
}
}
return lists;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 栈与队列
# 232.用栈实现队列
请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
实现 MyQueue 类:
void push(int x)将元素 x 推到队列的末尾int pop()从队列的开头移除并返回元素int peek()返回队列开头的元素boolean empty()如果队列为空,返回true;否则,返回false
说明:
- 你 只能 使用标准的栈操作 —— 也就是只有
push to top,peek/pop from top,size, 和is empty操作是合法的。 - 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
示例 1:
输入:
["MyQueue", "push", "push", "peek", "pop", "empty"]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 1, 1, false]
解释:
MyQueue myQueue = new MyQueue();
myQueue.push(1); // queue is: [1]
myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue)
myQueue.peek(); // return 1
myQueue.pop(); // return 1, queue is [2]
myQueue.empty(); // return false
2
3
4
5
6
7
8
9
10
11
12
13
提示:
1 <= x <= 9- 最多调用
100次push、pop、peek和empty - 假设所有操作都是有效的 (例如,一个空的队列不会调用
pop或者peek操作)
class MyQueue {
Stack<Integer> stack1; // 输入栈
Stack<Integer> stack2; // 输出栈
public MyQueue() {
stack1 = new Stack<>();
stack2 = new Stack<>();
}
public void push(int x) {
stack1.push(x);
}
public int pop() {
fillStack();
return stack2.pop();
}
public int peek() {
fillStack();
return stack2.peek();
}
public boolean empty() {
return stack1.isEmpty() && stack2.isEmpty();
}
public void fillStack() {
if (!stack2.isEmpty()) {
return;
} else {
while (!stack1.isEmpty()) {
stack2.push(stack1.pop());
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
在push数据的时候,只要数据放进输入栈就好,但在pop的时候,操作就复杂一些,输出栈如果为空,就把进栈数据全部导入进来(注意是全部导入),再从出栈弹出数据,如果输出栈不为空,则直接从出栈弹出数据就可以了。
最后如何判断队列为空呢?如果进栈和出栈都为空的话,说明模拟的队列为空了。
# 225.用队列实现栈
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。
实现 MyStack 类:
void push(int x)将元素 x 压入栈顶。int pop()移除并返回栈顶元素。int top()返回栈顶元素。boolean empty()如果栈是空的,返回true;否则,返回false。
注意:
- 你只能使用队列的基本操作 —— 也就是
push to back、peek/pop from front、size和is empty这些操作。 - 你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
示例:
输入:
["MyStack", "push", "push", "top", "pop", "empty"]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 2, 2, false]
解释:
MyStack myStack = new MyStack();
myStack.push(1);
myStack.push(2);
myStack.top(); // 返回 2
myStack.pop(); // 返回 2
myStack.empty(); // 返回 False
2
3
4
5
6
7
8
9
10
11
12
13
提示:
1 <= x <= 9- 最多调用
100次push、pop、top和empty - 每次调用
pop和top都保证栈不为空
// 两个队列实现
class MyStack {
Queue<Integer> queue1;
Queue<Integer> queue2;
public MyStack() {
queue1 = new LinkedList<>();
queue2 = new LinkedList<>();
}
public void push(int x) {
queue2.offer(x);
while (!queue1.isEmpty()) { //队列1不为空
queue2.offer(queue1.poll());
}
Queue<Integer> temp = queue1;
queue1 = queue2;
queue2 = temp;
}
public int pop() {
return queue1.poll();
}
public int top() {
return queue1.peek();
}
public boolean empty() {
return queue1.isEmpty();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// 一个队列实现
class MyStack2 {
Queue<Integer> queue1;
public MyStack2() {
queue1 = new LinkedList<>();
}
public void push(int x) {
int n = queue1.size();
queue1.offer(x);
for (int i = 0; i < n; i++) { //将前面的数插到后面
queue1.offer(queue1.poll());
}
}
public int pop() {
return queue1.poll();
}
public int top() {
return queue1.peek();
}
public boolean empty() {
return queue1.isEmpty();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 20.有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
示例 1:
输入:s = "()"
输出:true
2
示例 2:
输入:s = "()[]{}"
输出:true
2
示例 3:
输入:s = "(]"
输出:false
2
提示:
1 <= s.length <= 104s仅由括号'()[]{}'组成
public static boolean isValid2(String s) {
int n = s.length();
// 奇数肯定构不成括号匹配
if (n % 2 == 1) return false;
Stack<Character> stack = new Stack<>();
for (int i = 0; i < n; i++) {
char ch = s.charAt(i);
// 碰到左括号就把对应的右括号入栈
if (ch == '(') {
stack.push(')');
} else if (ch == '[') {
stack.push(']');
} else if (ch == '{') {
stack.push('}');
// 1. 栈为空,并且当前元素是右括号,则肯定不能匹配
// 2.栈不为空,但当前右括号不能和栈中的元素匹配
}else if (stack.isEmpty() || stack.peek() != ch) {
return false;
} else { // 匹配
stack.pop();
}
}
return stack.isEmpty();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 1047.删除字符串中的所有相邻重复项
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
在 S 上反复执行重复项删除操作,直到无法继续删除。
在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
示例:
输入:"abbaca"
输出:"ca"
解释:
例如,在 "abbaca" 中,我们可以删除 "bb" 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 "aaca",其中又只有 "aa" 可以执行重复项删除操作,所以最后的字符串为 "ca"。
2
3
4
提示:
1 <= S.length <= 20000S仅由小写英文字母组成。
public static String removeDuplicates(String s) {
Stack<Character> stack = new Stack<>();
int n = s.length();
for (int i = 0; i < n; i++) {
char ch = s.charAt(i);
if (!stack.isEmpty() && stack.peek() == ch) {
stack.pop();
} else {
stack.push(ch);
}
}
StringBuffer sb = new StringBuffer();
while (!stack.isEmpty()) {
sb.append(stack.pop());
}
return sb.reverse().toString();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 双指针
public static String removeDuplicates2(String s) {
char[] ch = s.toCharArray();
int fast = 0;
int slow = 0;
while (fast < s.length()) {
ch[slow] = ch[fast];
if (slow > 0 && ch[slow] == ch[slow - 1]) {
slow--;
} else {
slow++;
}
fast++;
}
return new String(ch,0,slow);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 150.逆波兰表达式求值
给你一个字符串数组 tokens ,表示一个根据 逆波兰表示法 (opens new window) 表示的算术表达式。
请你计算该表达式。返回一个表示表达式值的整数。
注意:
- 有效的算符为
'+'、'-'、'*'和'/'。 - 每个操作数(运算对象)都可以是一个整数或者另一个表达式。
- 两个整数之间的除法总是 向零截断 。
- 表达式中不含除零运算。
- 输入是一个根据逆波兰表示法表示的算术表达式。
- 答案及所有中间计算结果可以用 32 位 整数表示。
示例 1:
输入:tokens = ["2","1","+","3","*"]
输出:9
解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
2
3
示例 2:
输入:tokens = ["4","13","5","/","+"]
输出:6
解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
2
3
示例 3:
输入:tokens = ["10","6","9","3","+","-11","*","/","*","17","+","5","+"]
输出:22
解释:该算式转化为常见的中缀算术表达式为:
((10 * (6 / ((9 + 3) * -11))) + 17) + 5
= ((10 * (6 / (12 * -11))) + 17) + 5
= ((10 * (6 / -132)) + 17) + 5
= ((10 * 0) + 17) + 5
= (0 + 17) + 5
= 17 + 5
= 22
2
3
4
5
6
7
8
9
10
public static int evalRPN(String[] tokens) {
Stack<String> stack = new Stack<>();
int n = tokens.length;
for (int i = 0; i < n; i++) {
String ch = tokens[i];
if ("+".equals(ch) || "-".equals(ch) || "*".equals(ch) || "/".equals(ch)) {
int b = Integer.parseInt(stack.pop());
int a = Integer.parseInt(stack.pop());
int result = 0;
switch (ch) {
case "+": result = a + b; break;
case "-": result = a - b; break;
case "*": result = a * b; break;
case "/": result = a / b; break;
}
stack.push(Integer.toString(result));
}else {
stack.push(ch);
}
}
return Integer.parseInt(stack.pop());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 239.滑动窗口最大值
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回 滑动窗口中的最大值 。
示例 1:
输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7
2
3
4
5
6
7
8
9
10
11
示例 2:
输入:nums = [1], k = 1
输出:[1]
2
提示:
1 <= nums.length <= 105-104 <= nums[i] <= 1041 <= k <= nums.length
package com.ep.LeetCode_Type.StackAndQueue;
import java.util.*;
/***
* @author dep
* @version 1.0
* @date 2023-03-21 8:49
*/
public class exercise6_239_滑动窗口最大值 {
static class MyQueue {
Deque<Integer> deque = new LinkedList<>();
// 弹出队列第一个元素,弹出的时候要判断要弹出的元素是否和队列头元素是都相等
// 并且要判断是否是非空队列
void poll (int val) {
if (!deque.isEmpty() && val == deque.peek()) {
deque.poll();
}
}
// 添加元素,如果添加的元素大于入口处的元素,就将入口元素弹出
// 保证队列单调递减
// 比如此时队列元素3,1,2将要入队,比1大,所以1弹出,此时队列:3,2
void add (int val) {
while (!deque.isEmpty() && val > deque.getLast()) {
deque.removeLast();
}
deque.add(val);
}
// 队列的队顶元素始终为最大值
int peek() {
return deque.peek();
}
}
public static int[] maxSlidingWindow(int[] nums, int k) {
if (nums.length == 1) return nums;
int len = nums.length - k + 1; //结果的长度
int num = 0;
int[] res= new int[len];
MyQueue myQueue = new MyQueue();
for (int i = 0; i < k; i++) {
myQueue.add(nums[i]);
}
res[num++] = myQueue.peek();
for (int i = k; i < nums.length; i++) {
// 滑动窗口移除最前面的元素
myQueue.poll(nums[i-k]);
// 滑动窗口加入最后面的元素
myQueue.add(nums[i]);
// 记录对应的最大值
res[num++] = myQueue.peek();
}
return res;
}
public static void main(String[] args) {
int[] nums = {1,3,-1,-3,5,3,6,7};int k = 3;
int[] ints = maxSlidingWindow(nums, k);
System.out.println(Arrays.toString(ints));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
# 347.前 K 个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
2
示例 2:
输入: nums = [1], k = 1
输出: [1]
2
提示:
1 <= nums.length <= 105k的取值范围是[1, 数组中不相同的元素的个数]- 题目数据保证答案唯一,换句话说,数组中前
k个高频元素的集合是唯一的
**进阶:**你所设计算法的时间复杂度 必须 优于 O(n log n) ,其中 n 是数组大小。
import java.util.*;
/***
* @author dep
* @version 1.0
* @date 2023-03-21 10:41
*/
public class exercise7_347_前K个高频元素 {
public static int[] topKFrequent(int[] nums, int k) {
HashMap<Integer, Integer> hashMap = new HashMap<>();
PriorityQueue<int[]> queue = new PriorityQueue<>(new Comparator<int[]>() {
@Override
public int compare(int[] o1, int[] o2) {
return o2[1] - o1[1];
}
});
for (int i = 0; i < nums.length; i++) {
hashMap.put(nums[i], hashMap.getOrDefault(nums[i],0) + 1);
}
Set<Map.Entry<Integer, Integer>> entries = hashMap.entrySet();
for (Map.Entry<Integer,Integer> entry : entries) {
queue.add(new int[]{entry.getKey(), entry.getValue()});
}
int[] res = new int[k];
for (int i = 0; i < k; i++) {
res[i] = queue.poll()[0];
}
return res;
}
public static void main(String[] args) {
int[] nums = {1}; int k = 1;
int[] ints = topKFrequent(nums, k);
System.out.println(Arrays.toString(ints));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 二叉树
# 二叉树理论基础
# 二叉树种类
# 满二叉树
满二叉树:如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。

这棵二叉树为满二叉树,也可以说深度为k,有2^k-1个节点的二叉树。
# 完全二叉树
完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2^(h-1) 个节点。
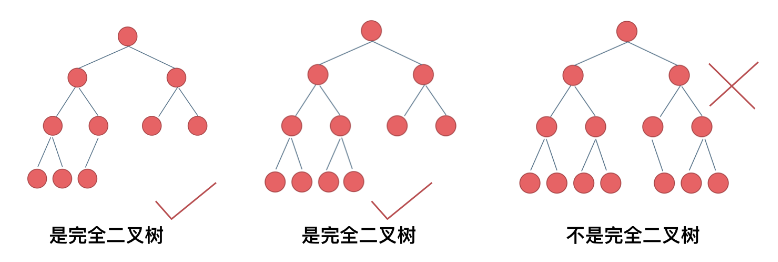
# 二叉搜索树
二叉搜索树是一个有序树。
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树

# 平衡二叉搜索树
平衡二叉搜索树:又被称为AVL(Adelson-Velsky and Landis)树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。

# 二叉树的存储方式
二叉树可以链式存储,也可以顺序存储。
那么链式存储方式就用指针, 顺序存储的方式就是用数组。
链式存储:
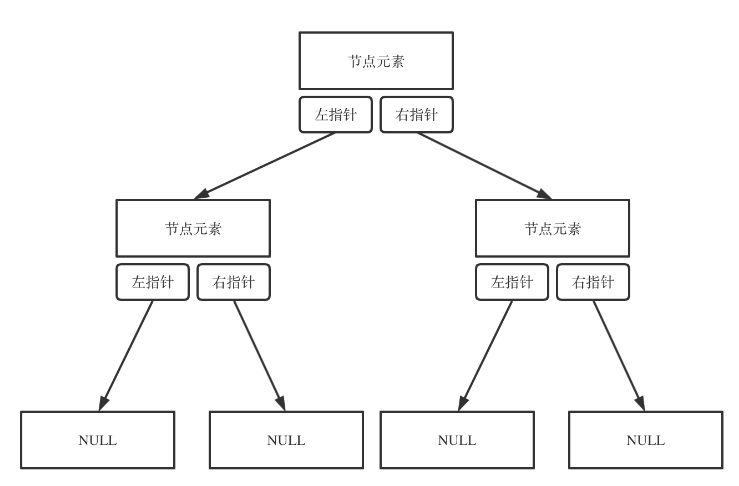
顺序存储:

# 二叉树的遍历方式
二叉树主要有两种遍历方式:
- 深度优先遍历:先往深走,遇到叶子节点再往回走。
- 广度优先遍历:一层一层的去遍历。
- 深度优先遍历
- 前序遍历(递归法,迭代法)
- 中序遍历(递归法,迭代法)
- 后序遍历(递归法,迭代法)
- 广度优先遍历
- 层次遍历(迭代法)
// 二叉树定义
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
2
3
4
5
6
7
8
9
10
11
12
# 二叉树的递归遍历
递归三要素:
- 确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
- 确定终止条件: 写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
- 确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
以前序遍历为例:
- 确定递归函数的参数和返回值:因为要打印出前序遍历节点的数值,所以参数里需要传入vector来放节点的数值,除了这一点就不需要再处理什么数据了也不需要有返回值,所以递归函数返回类型就是void,代码如下:
void traversal(TreeNode* cur, vector<int>& vec)
- 确定终止条件:在递归的过程中,如何算是递归结束了呢,当然是当前遍历的节点是空了,那么本层递归就要结束了,所以如果当前遍历的这个节点是空,就直接return,代码如下:
if (cur == NULL) return;
- 确定单层递归的逻辑:前序遍历是中左右的循序,所以在单层递归的逻辑,是要先取中节点的数值,代码如下:
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
2
3
# 144.二叉树的前序遍历
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
示例 1:

输入:root = [1,null,2,3]
输出:[1,2,3]
2
示例 2:
输入:root = []
输出:[]
2
示例 3:
输入:root = [1]
输出:[1]
2
示例 4:
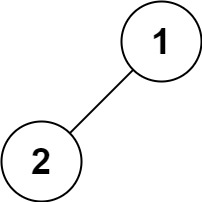
输入:root = [1,2]
输出:[1,2]
2
示例 5:
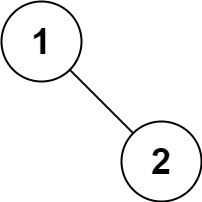
输入:root = [1,null,2]
输出:[1,2]
2
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
**进阶:**递归算法很简单,你可以通过迭代算法完成吗?
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
preorder(root,res);
return res;
}
// 先序遍历
public void preorder(TreeNode root,List<Integer> res) {
if (root == null) return;
res.add(root.val);
preorder(root.left,res);
preorder(root.right,res);
}
2
3
4
5
6
7
8
9
10
11
12
# 145.二叉树的后序遍历
给你一棵二叉树的根节点 root ,返回其节点值的 后序遍历 。
示例 1:
输入:root = [1,null,2,3]
输出:[3,2,1]
2
示例 2:
输入:root = []
输出:[]
2
示例 3:
输入:root = [1]
输出:[1]
2
提示:
- 树中节点的数目在范围
[0, 100]内 -100 <= Node.val <= 100
**进阶:**递归算法很简单,你可以通过迭代算法完成吗?
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
postorder(root,res);
return res;
}
// 后序遍历
public void postorder(TreeNode root,List<Integer> res) {
if (root == null) return;
postorder(root.left,res);
postorder(root.right,res);
res.add(root.val);
}
2
3
4
5
6
7
8
9
10
11
12
# 94.二叉树的中序遍历
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:
输入:root = [1,null,2,3]
输出:[1,3,2]
2
示例 2:
输入:root = []
输出:[]
2
示例 3:
输入:root = [1]
输出:[1]
2
提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
inorder(root,res);
return res;
}
// 中序遍历
public void inorder(TreeNode root,List<Integer> res) {
if (root == null) return;
inorder(root.left,res);
res.add(root.val);
inorder(root.right,res);
}
2
3
4
5
6
7
8
9
10
11
12
# 589.N 叉树的前序遍历
给定一个 n 叉树的根节点 root ,返回 其节点值的 前序遍历 。
n 叉树 在输入中按层序遍历进行序列化表示,每组子节点由空值 null 分隔(请参见示例)
示例 1:
输入:root = [1,null,3,2,4,null,5,6]
输出:[1,3,5,6,2,4]
2
示例 2:
输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
输出:[1,2,3,6,7,11,14,4,8,12,5,9,13,10]
2
提示:
- 节点总数在范围
[0, 104]内 0 <= Node.val <= 104- n 叉树的高度小于或等于
1000
public List<Integer> preorder(Node root) {
List<Integer> res = new ArrayList<>();
dfs(root,res);
return res;
}
public void dfs(Node root, List<Integer> res) {
if (root == null) return;
res.add(root.val);
for (Node node : root.children) {
dfs(node, res);
}
}
2
3
4
5
6
7
8
9
10
11
12
# 二叉树迭代遍历
# 前序遍历(迭代法)
前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子。
为什么要先加入 右孩子,再加入左孩子呢? 因为这样出栈的时候才是中左右的顺序。
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
preorder(root,res);
return res;
}
// 先序遍历(迭代法)
public void preorderTree(TreeNode root,List<Integer> res) {
if (root == null ) return;
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
res.add(node.val);
if (node.right != null) stack.push(node.right);
if (node.left != null) stack.push(node.left);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 中序遍历(迭代法)
// 中序遍历(迭代)
public void inorderTree(TreeNode root,List<Integer> res) {
TreeNode curr = root;
Stack<TreeNode> stack = new Stack();
while (curr != null || !stack.isEmpty()) {
if (curr != null) { // 指针来访问节点,访问到最底层
stack.push(curr); // 将访问的节点放进栈
curr = curr.left;
} else { // 此时已经走到了最左边的节点
curr = stack.pop();
res.add(curr.val);
curr = curr.right;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 后序遍历(迭代法)
再来看后序遍历,先序遍历是中左右,后续遍历是左右中,那么我们只需要调整一下先序遍历的代码顺序,就变成中右左的遍历顺序,然后在反转result数组,输出的结果顺序就是左右中了,如下图:

// 后序遍历(迭代)
public void postorderTree(TreeNode root, List<Integer> res) {
if(root == null) return;
TreeNode curr;
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
curr = stack.pop();
res.add(curr.val);
if (curr.left != null) stack.push(curr.left);
if (curr.right != null) stack.push(curr.right);
}
Collections.reverse(res);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 二叉树的统一迭代法
就是要处理的节点放入栈之后,紧接着放入一个空指针作为标记
// 先序遍历(统一 迭代法)
public void preorder1(TreeNode root, List<Integer> res) {
Stack<TreeNode> stack = new Stack<>();
if (root != null) stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.peek();
if (node != null) {
stack.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
if (node.right != null) stack.push(node.right);
if (node.left != null) stack.push(node.left);
stack.push(node);
stack.push(null); // // 中节点访问过,但是还没有处理,加入空节点做为标记。
} else {
stack.pop(); // 将空节点弹出
res.add(stack.pop().val); // 加入结果集
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 中序遍历(统一 迭代法)
public void inorder1(TreeNode root, List<Integer> res) {
Stack<TreeNode> stack = new Stack<>();
if (root != null) stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.peek();
if (node != null) {
stack.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
if (node.right != null) stack.push(node.right);
stack.push(node);
stack.push(null); // // 中节点访问过,但是还没有处理,加入空节点做为标记。
if (node.left != null) stack.push(node.left);
} else {
stack.pop(); // 将空节点弹出
res.add(stack.pop().val); // 加入结果集
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 后序遍历(统一 迭代法)
public void postorder1(TreeNode root, List<Integer> res) {
Stack<TreeNode> stack = new Stack<>();
if (root != null) stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.peek();
if (node != null) {
stack.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
stack.push(node);
stack.push(null); // // 中节点访问过,但是还没有处理,加入空节点做为标记。
if (node.right != null) stack.push(node.right);
if (node.left != null) stack.push(node.left);
} else {
stack.pop(); // 将空节点弹出
res.add(stack.pop().val); // 加入结果集
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 二叉树层序遍历
# 102.二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:[[3],[9,20],[15,7]]
2
示例 2:
输入:root = [1]
输出:[[1]]
2
示例 3:
输入:root = []
输出:[]
2
提示:
- 树中节点数目在范围
[0, 2000]内 -1000 <= Node.val <= 1000
// 层次遍历
public List<List<Integer>> levelOrder(TreeNode root) {
Queue<TreeNode> queue = new ArrayDeque<>();
List<List<Integer>> res = new ArrayList();
if (root != null) queue.add(root);
while (!queue.isEmpty()) {
int size = queue.size();
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
list.add(node.val);
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
res.add(list);
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 107.二叉树的层序遍历 II
给你二叉树的根节点 root ,返回其节点值 自底向上的层序遍历 。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
示例 1:
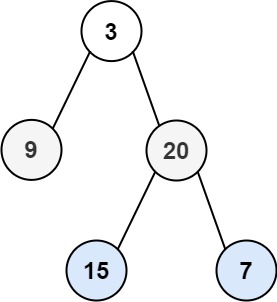
输入:root = [3,9,20,null,null,15,7]
输出:[[15,7],[9,20],[3]]
2
示例 2:
输入:root = [1]
输出:[[1]]
2
示例 3:
输入:root = []
输出:[]
2
提示:
- 树中节点数目在范围
[0, 2000]内 -1000 <= Node.val <= 1000
// 二叉树层次遍历(自下向上)
public List<List<Integer>> levelOrderBottom(TreeNode root) {
Queue<TreeNode> queue = new ArrayDeque<>();
List<List<Integer>> res = new ArrayList<>();
if (root != null) queue.add(root);
int size = 0;
while (!queue.isEmpty()) {
size = queue.size();
List<Integer> list = new ArrayList<>();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
list.add(node.val);
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
res.add(list);
}
Collections.reverse(res);
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 199.二叉树的右视图
给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
示例 1:

输入: [1,2,3,null,5,null,4]
输出: [1,3,4]
2
示例 2:
输入: [1,null,3]
输出: [1,3]
2
示例 3:
输入: []
输出: []
2
提示:
- 二叉树的节点个数的范围是
[0,100] -100 <= Node.val <= 100
// 层次遍历,结果集中只加入每层最后一个元素
public List<Integer> rightSideView(TreeNode root) {
Queue<TreeNode> queue = new ArrayDeque<>();
List<Integer> res = new ArrayList<>();
if (root != null) queue.add(root);
TreeNode node = null;
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) { // 遍历完成之后node就是最右侧的元素
node = queue.poll();
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
res.add(node.val);
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 637.二叉树的层平均值
给定一个非空二叉树的根节点 root , 以数组的形式返回每一层节点的平均值。与实际答案相差 10-5 以内的答案可以被接受。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:[3.00000,14.50000,11.00000]
解释:第 0 层的平均值为 3,第 1 层的平均值为 14.5,第 2 层的平均值为 11 。
因此返回 [3, 14.5, 11] 。
2
3
4
示例 2:

输入:root = [3,9,20,15,7]
输出:[3.00000,14.50000,11.00000]
2
提示:
- 树中节点数量在
[1, 104]范围内 -231 <= Node.val <= 231 - 1
public List<Double> averageOfLevels(TreeNode root) {
Queue<TreeNode> queue = new ArrayDeque<>();
if (root != null) queue.add(root);
List<Double> res = new ArrayList<>();
while(!queue.isEmpty()) {
int size = queue.size();
Double sum = 0.0;
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
sum += node.val;
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
res.add(sum / size);
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 429.N 叉树的层序遍历
给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)。
树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例)。
示例 1:

输入:root = [1,null,3,2,4,null,5,6]
输出:[[1],[3,2,4],[5,6]]
2
示例 2:

输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
输出:[[1],[2,3,4,5],[6,7,8,9,10],[11,12,13],[14]]
2
提示:
- 树的高度不会超过
1000 - 树的节点总数在
[0, 10^4]之间
public List<List<Integer>> levelOrder(Node root) {
List<List<Integer>> res = new ArrayList<>();
if (root == null) return res;
Queue<Node> queue = new ArrayDeque<>();
queue.add(root);
while (!queue.isEmpty()) {
int size = queue.size();
List<Integer> list = new ArrayList<>();
for (int i = 0; i < size; i++) {
Node node = queue.poll();
if (node != null){
list.add(node.val);
for (Node temp : node.children) {
if (temp != null) queue.add(temp);
}
}
}
res.add(list);
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 515.在每个树行中找最大值
给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。
示例1:

输入: root = [1,3,2,5,3,null,9]
输出: [1,3,9]
2
示例2:
输入: root = [1,2,3]
输出: [1,3]
2
提示:
- 二叉树的节点个数的范围是
[0,104] -231 <= Node.val <= 231 - 1
public List<Integer> largestValues(TreeNode root) {
List<Integer> res = new ArrayList<>();
if (root == null) return res;
Queue<TreeNode> queue = new ArrayDeque<>();
queue.add(root);
while (!queue.isEmpty()) {
int size = queue.size();
int max = Integer.MIN_VALUE;
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
max = Math.max(max,node.val);
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
res.add(max);
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 116.填充每个节点的下一个右侧节点指针
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
2
3
4
5
6
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
示例 1:
输入:root = [1,2,3,4,5,6,7]
输出:[1,#,2,3,#,4,5,6,7,#]
解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,'#' 标志着每一层的束。
2
3
示例 2:
输入:root = []
输出:[]
2
提示:
- 树中节点的数量在
[0, 212 - 1]范围内 -1000 <= node.val <= 1000
public Node connect(Node root) {
if (root == null) return root;
Queue<Node> queue = new ArrayDeque<>();
Node node = root;
queue.add(node);
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
Node curr = queue.poll();
if (i != size - 1) {
Node next = queue.peek();
curr.next = next;
} else {
curr.next = null; // 这里可以不加,默认就是NULL
}
if (curr.left != null) queue.add(curr.left);
if (curr.right != null) queue.add(curr.right);
}
}
return node;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 117.填充每个节点的下一个右侧节点指针 II
给定一个二叉树:
struct Node {
int val;
Node *left;
Node *right;
Node *next;
}
2
3
4
5
6
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL 。
初始状态下,所有 next 指针都被设置为 NULL 。
示例 1:
输入:root = [1,2,3,4,5,null,7]
输出:[1,#,2,3,#,4,5,7,#]
解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化输出按层序遍历顺序(由 next 指针连接),'#' 表示每层的末尾。
2
3
示例 2:
输入:root = []
输出:[]
2
提示:
- 树中的节点数在范围
[0, 6000]内 -100 <= Node.val <= 100
解法和上题一模一样
# 104.二叉树的最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
2
3
4
5
返回它的最大深度 3
广度优先搜索
// 广度优先搜索
public int maxDepth2(TreeNode root) {
if (root == null) return 0;
Queue<TreeNode> queue = new ArrayDeque<>();
queue.add(root);
int count = 0;
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
if (node.left!= null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
count++;
}
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
深度优先搜索
// 深度优先遍历
public int maxDepth(TreeNode root) {
if (root == null) return 0;
else {
int leftDepth = maxDepth(root.left);
int rightDepth = maxDepth(root.right);
return Math.max(leftDepth, rightDepth) + 1;
}
}
2
3
4
5
6
7
8
9
# 111.二叉树的最小深度
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
**说明:**叶子节点是指没有子节点的节点。
示例 1:
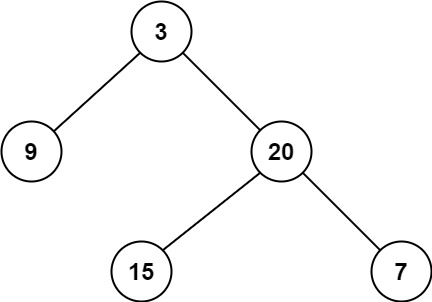
输入:root = [3,9,20,null,null,15,7]
输出:2
2
示例 2:
输入:root = [2,null,3,null,4,null,5,null,6]
输出:5
2
提示:
- 树中节点数的范围在
[0, 105]内 -1000 <= Node.val <= 1000
// 广度优先搜索
public int minDepth2(TreeNode root) {
if (root == null) return 0;
Queue<TreeNode> queue = new ArrayDeque<>();
queue.add(root);
int count = 0;
while (!queue.isEmpty()) {
int size = queue.size();
count++;
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
if (node.left == null && node.right == null) {
return count;
} else {
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
}
}
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 深度优先搜索
public int minDepth(TreeNode root) {
if (root == null) return 0;
if (root.left == null && root.right == null) return 1;
int minDepth = Integer.MAX_VALUE;
if (root.left != null) {
minDepth = Math.min(minDepth(root.left), minDepth);
}
if (root.right != null) {
minDepth = Math.min(minDepth(root.right), minDepth);
}
return minDepth + 1;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 226.翻转二叉树
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
示例 1:
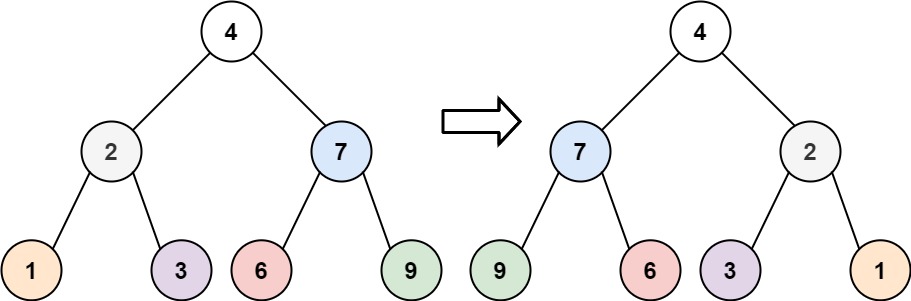
输入:root = [4,2,7,1,3,6,9]
输出:[4,7,2,9,6,3,1]
2
示例 2:
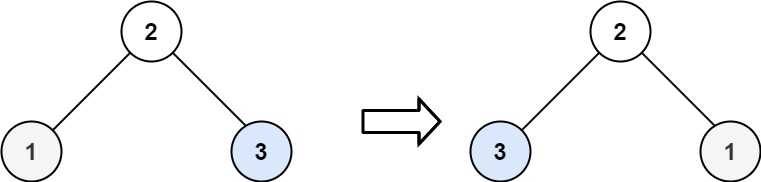
输入:root = [2,1,3]
输出:[2,3,1]
2
示例 3:
输入:root = []
输出:[]
2
提示:
- 树中节点数目范围在
[0, 100]内 -100 <= Node.val <= 100
// 先序递归翻转 (根左右)
public TreeNode invertTree(TreeNode root) {
if(root == null) return root;
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
invertTree(root.left);
invertTree(root.right);
return root;
}
2
3
4
5
6
7
8
9
10
// 后序遍历翻转 (左右根)
public TreeNode invertTree2(TreeNode root) {
if (root == null) return root;
invertTree2(root.left);
invertTree2(root.right);
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
return root;
}
2
3
4
5
6
7
8
9
10
// 中序遍历翻转(左根右)
public TreeNode invertTree3(TreeNode root) {
if (root == null) return root;
invertTree3(root.left);
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
invertTree3(root.left); //右边的已经交换到左边了,所以这个左边是原来的右边
return root;
}
2
3
4
5
6
7
8
9
10
// 层序遍历翻转
public TreeNode invertTree4(TreeNode root) {
if (root == null) return root;
Queue<TreeNode> queue = new ArrayDeque<>();
queue.add(root);
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
TreeNode temp = node.left;
node.left = node.right;
node.right = temp;
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
}
return root;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 101.对称二叉树
给你一个二叉树的根节点 root , 检查它是否轴对称。
示例 1:

输入:root = [1,2,2,3,4,4,3]
输出:true
2
示例 2:

输入:root = [1,2,2,null,3,null,3]
输出:false
2
提示:
- 树中节点数目在范围
[1, 1000]内 -100 <= Node.val <= 100
终止条件:
- 左节点为空,右节点不为空,不对称,return false
- 左不为空,右为空,不对称 return false
- 左右都为空,对称,返回true
此时已经排除掉了节点为空的情况,那么剩下的就是左右节点不为空:
- 左右都不为空,比较节点数值,不相同就return false
public boolean isSymmetric(TreeNode root) {
if (root == null) return true;
return compare(root.left, root.right);
}
public boolean compare(TreeNode left, TreeNode right) {
if (left == null && right == null) {
return true;
} else if (left == null && right != null) {
return false;
} else if (left != null && right == null) {
return false;
} else if (left.val != right.val) {
return false;
} else {
return compare(left.left,right.right) && compare(left.right, right.left);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public boolean isSymmetric(TreeNode root) {
if (root == null) return true;
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root.left);
queue.add(root.right);
while (!queue.isEmpty()) {
TreeNode leftNode = queue.poll();
TreeNode rightNode = queue.poll();
if (leftNode == null && rightNode == null) { // 左右结点为空,说明是对称的
continue;
}
if (leftNode == null && rightNode != null) return false;
else if (leftNode != null && rightNode == null) return false;
else if (leftNode.val != rightNode.val) return false;
queue.add(leftNode.left);
queue.add(rightNode.right);
queue.add(leftNode.right);
queue.add(rightNode.left);
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 100. 相同的树
给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
示例 1:
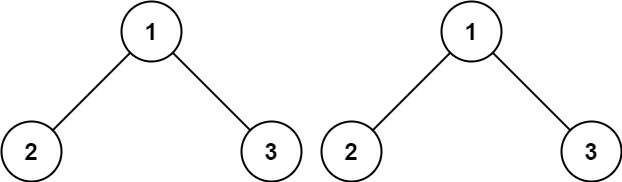
输入:p = [1,2,3], q = [1,2,3]
输出:true
2
示例 2:

输入:p = [1,2], q = [1,null,2]
输出:false
2
示例 3:
输入:p = [1,2,1], q = [1,1,2]
输出:false
2
提示:
- 两棵树上的节点数目都在范围
[0, 100]内 -104 <= Node.val <= 104
public boolean isSameTree(TreeNode p, TreeNode q) {
if (p == null && q == null) {
return true;
} else if (p == null || q == null) {
return false;
} else if (p.val != q.val) {
return false;
} else {
return isSameTree(p.left,q.left) && isSameTree(p.right, q.right);
}
}
2
3
4
5
6
7
8
9
10
11
// 广度优先遍历
public boolean isSameTree2(TreeNode p, TreeNode q) {
if (p == null && q== null) return true;
else if (p == null || q == null) return false;
Queue<TreeNode> queue1 = new LinkedList<>();
Queue<TreeNode> queue2 = new LinkedList<>();
queue1.offer(p);
queue2.offer(q);
while (!queue1.isEmpty() && !queue2.isEmpty()) {
TreeNode p1 = queue1.poll();
TreeNode p2 = queue2.poll();
if (p1.val != p2.val) return false;
TreeNode left1 = p1.left,right1 = p1.right,left2 = p2.left, right2 = p2.right;
if (left1 == null ^ left2 ==null) return false;
if (right1 == null ^ right2 == null) return false;
if (left1 != null) queue1.offer(left1);
if (right1 != null) queue1.offer(right1);
if (left2 != null) queue2.offer(left2);
if (right2 != null) queue2.offer(right2);
}
return queue1.isEmpty() && queue2.isEmpty();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 572.另一棵树的子树(字节考了题解的第三种方法)
给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。
二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所有后代节点。tree 也可以看做它自身的一棵子树。
示例 1:
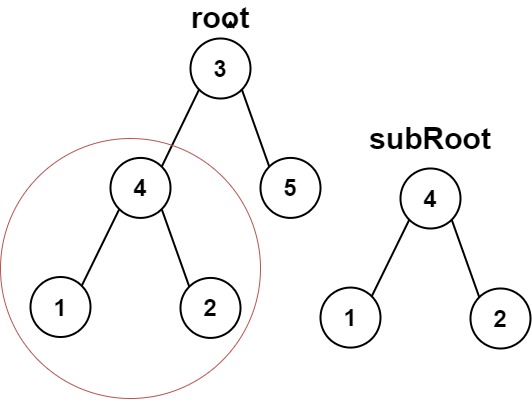
输入:root = [3,4,5,1,2], subRoot = [4,1,2]
输出:true
2
示例 2:

输入:root = [3,4,5,1,2,null,null,null,null,0], subRoot = [4,1,2]
输出:false
2
提示:
root树上的节点数量范围是[1, 2000]subRoot树上的节点数量范围是[1, 1000]-104 <= root.val <= 104-104 <= subRoot.val <= 104
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
return dfs(root, subRoot);
}
public boolean dfs(TreeNode root, TreeNode subRoot) {
if (root == null) return false;
return check(root,subRoot) || dfs(root.left,subRoot) || dfs(root.right, subRoot);
}
public boolean check(TreeNode root, TreeNode subRoot) {
if (root == null && subRoot == null) {
return true;
}else if (root == null || subRoot == null) {
return false;
}else if (root.val != subRoot.val) {
return false;
}
return check(root.left,subRoot.left) && check(root.right, subRoot.right);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// TODO 第三种解法
# 222.完全二叉树的节点个数
给你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。
完全二叉树 (opens new window) 的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2h 个节点。
示例 1:

输入:root = [1,2,3,4,5,6]
输出:6
2
示例 2:
输入:root = []
输出:0
2
示例 3:
输入:root = [1]
输出:1
2
提示:
- 树中节点的数目范围是
[0, 5 * 104] 0 <= Node.val <= 5 * 104- 题目数据保证输入的树是 完全二叉树
**进阶:**遍历树来统计节点是一种时间复杂度为 O(n) 的简单解决方案。你可以设计一个更快的算法吗?
// 广度优先搜索
public int countNodes(TreeNode root) {
if(root == null) return 0;
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
int count = 0;
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
count++;
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
// 深度优先搜索
public int countNodes2(TreeNode root) {
if (root == null) return 0;
return dfs(root);
}
public int dfs(TreeNode root) {
if (root == null) return 0;
int leftNum = dfs(root.left);
int rightNum = dfs(root.right);
return leftNum + rightNum + 1;
}
2
3
4
5
6
7
8
9
10
11
# 110.平衡二叉树
给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为:
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
示例 1:
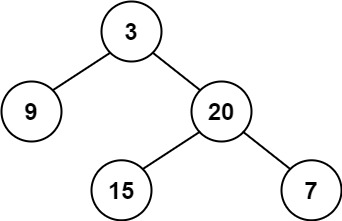
输入:root = [3,9,20,null,null,15,7]
输出:true
2
示例 2:
输入:root = [1,2,2,3,3,null,null,4,4]
输出:false
2
示例 3:
输入:root = []
输出:true
2
提示:
- 树中的节点数在范围
[0, 5000]内 -104 <= Node.val <= 104
public boolean isBalanced(TreeNode root) {
return getHeightDifference(root) == -1 ? false : true;
}
// 求左右高度之差
public int getHeightDifference(TreeNode node) {
if (node == null) return 0;
int leftDepth = getHeightDifference(node.left);
if (leftDepth == -1) return -1;
int rightDepth = getHeightDifference(node.right);
if (rightDepth == -1) return -1;
if (Math.abs(leftDepth - rightDepth) > 1) {
return -1;
} else {
return Math.max(leftDepth, rightDepth) + 1;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 257.二叉树的所有路径
给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。
叶子节点 是指没有子节点的节点。
示例 1:
输入:root = [1,2,3,null,5]
输出:["1->2->5","1->3"]
2
示例 2:
输入:root = [1]
输出:["1"]
2
提示:
- 树中节点的数目在范围
[1, 100]内 -100 <= Node.val <= 100
回溯和递归是一一对应的,有一个递归,就要有一个回溯
package com.ep.LeetCode_Type.Tree;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
/***
* @author dep
* @version 1.0
* @date 2023-04-01 9:41
*/
public class exercise20_257_二叉树的所有路径 {
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {
}
TreeNode(int val) {
this.val = val;
}
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
static List<Integer> path;
static List<String> res;
public List<String> binaryTreePaths(TreeNode root) {
path = new ArrayList<>();
res = new LinkedList<>();
dfs(root);
return res;
}
public void dfs(TreeNode node){
path.add(node.val); // 中,中为什么写在这里,因为最后一个节点也要加入到path中
if (node.left == null && node.right == null) { // 叶子结点
if (path.size() > 0) {
String str = "";
for (int i = 0; i < path.size() - 1; i++) {
str += path.get(i) + "->";
}
str += path.get(path.size() - 1);
res.add(str);
}
return;
}
if (node.left != null) { // 左
dfs(node.left);
path.remove(path.size() - 1); // 回溯
}
if (node.right != null) { // 右
dfs(node.right);
path.remove(path.size() - 1); // 回溯
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
回溯隐藏在traversal(cur->left, path + "->", result);中的 path + "->"。 每次函数调用完,path依然是没有加上"->" 的,这就是回溯了。
public List<String> binaryTreePaths2(TreeNode root) {
List<String> res = new LinkedList<>();
traversal(root,"",res);
return res;
}
public void traversal(TreeNode node, String path, List<String> res) {
path += node.val;
if (node.left == null && node.right == null) {
res.add(path);
return;
}
if (node.left != null) {
traversal(node.left, path + "->", res); // 回溯隐藏在这里
}
if (node.right != null) {
traversal(node.right, path + "->", res); // 回溯隐藏在这里
}
// if (node != null) { // 伪代码,
// path += "->";
// traversal(node.left, path, res);
// path.pop('>'); // 回溯过程
// path.pop('-')
// }
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 404.左叶子之和
给定二叉树的根节点 root ,返回所有左叶子之和。
示例 1:

输入: root = [3,9,20,null,null,15,7]
输出: 24
解释: 在这个二叉树中,有两个左叶子,分别是 9 和 15,所以返回 24
2
3
示例 2:
输入: root = [1]
输出: 0
2
提示:
- 节点数在
[1, 1000]范围内 -1000 <= Node.val <= 1000
public int sumOfLeftLeaves(TreeNode root) {
if (root == null) return 0;
int leftValue = sumOfLeftLeaves(root.left); // 左
int rightValue = sumOfLeftLeaves(root.right); // 右
int midValue = 0;
if (root.left != null && root.left.left == null && root.left.right == null) { // 判断是否是左叶子
midValue = root.left.val;
}
int sum =midValue + leftValue + rightValue;
return sum;
}
2
3
4
5
6
7
8
9
10
11
12
public int sumOfLeftLeaves2(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
int sum = 0;
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
if (node.left != null && node.left.left == null && node.left.right == null) {
sum += node.left.val;
}
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
return sum;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 513.找树左下角的值
给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。
假设二叉树中至少有一个节点。
示例 1:

输入: root = [2,1,3]
输出: 1
2
示例 2:

输入: [1,2,3,4,null,5,6,null,null,7]
输出: 7
2
提示:
- 二叉树的节点个数的范围是
[1,104] -231 <= Node.val <= 231 - 1
public int findBottomLeftValue1(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
int result = 0;
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
if (i == 0) result = node.val;
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
private int Deep = -1; // 树的深度
private int value = 0;
// 递归法
public int findBottomLeftValue(TreeNode root) {
value = root.val;
findLeftValue(root, 0);
return value;
}
private void findLeftValue(TreeNode root, int deep) {
if (root == null) return;
if (root.left == null && root.right == null) {
if (deep > Deep) {
value = root.val;
Deep = deep;
}
}
if (root.left != null) findLeftValue(root.left, deep + 1);
if (root.right != null) findLeftValue(root.right, deep + 1);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 112.路径总和
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
叶子节点 是指没有子节点的节点。
示例 1:
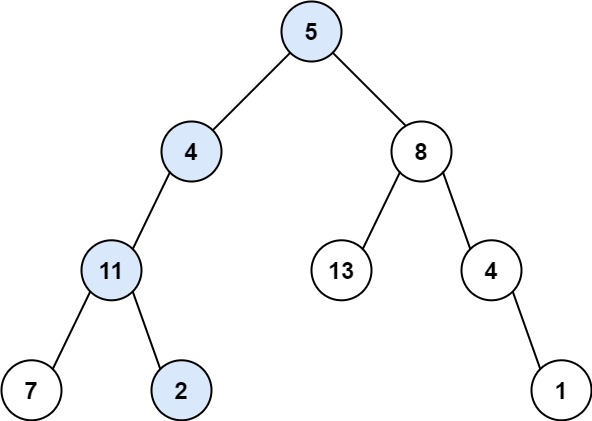
输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true
解释:等于目标和的根节点到叶节点路径如上图所示。
2
3
示例 2:

输入:root = [1,2,3], targetSum = 5
输出:false
解释:树中存在两条根节点到叶子节点的路径:
(1 --> 2): 和为 3
(1 --> 3): 和为 4
不存在 sum = 5 的根节点到叶子节点的路径。
2
3
4
5
6
示例 3:
输入:root = [], targetSum = 0
输出:false
解释:由于树是空的,所以不存在根节点到叶子节点的路径。
2
3
提示:
- 树中节点的数目在范围
[0, 5000]内 -1000 <= Node.val <= 1000-1000 <= targetSum <= 1000
public boolean hasPathSum(TreeNode root, int targetSum) {
if (root == null ) return false;
if (root.left == null && root.right == null) {
return root.val == targetSum;
}
return hasPathSum(root.left, targetSum - root.val) || hasPathSum(root.right, targetSum - root.val);
}
2
3
4
5
6
7
// 层序遍历
public boolean hasPathSum2(TreeNode root, int targetSum) {
if (root == null) return false;
Queue<TreeNode> queueNode = new LinkedList<>();
Queue<Integer> queueValue = new LinkedList<>();
queueNode.add(root);
queueValue.add(root.val);
while (!queueNode.isEmpty()) {
int size = queueNode.size();
for (int i = 0; i < size; i++) {
TreeNode node = queueNode.poll();
Integer temp = queueValue.poll();
if (node.left == null && node.right == null && temp == targetSum) {
return true;
}
if (node.left != null) {
queueNode.add(node.left);
queueValue.add(temp + node.left.val);
}
if (node.right != null) {
queueNode.add(node.right);
queueValue.add(temp + node.right.val);
}
}
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 106.从中序与后序遍历序列构造二叉树
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:

输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
输出:[3,9,20,null,null,15,7]
2
示例 2:
输入:inorder = [-1], postorder = [-1]
输出:[-1]
2
提示:
1 <= inorder.length <= 3000postorder.length == inorder.length-3000 <= inorder[i], postorder[i] <= 3000inorder和postorder都由 不同 的值组成postorder中每一个值都在inorder中inorder保证是树的中序遍历postorder保证是树的后序遍历
package com.ep.LeetCode_Type.Tree;
import sun.font.FontRunIterator;
import sun.reflect.generics.tree.Tree;
import java.util.HashMap;
/***
* @author dep
* @version 1.0
* @date 2023-04-04 8:59
*/
public class exercise24_106_从中序与后序遍历序列构造二叉树 {
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {
}
TreeNode(int val) {
this.val = val;
}
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
static HashMap<Integer, Integer> map;
public TreeNode buildTree(int[] inorder, int[] postorder) {
// // 1.后序数组为0,空节点
// if(postorder.length == 0) return null;
// // 2.后序数组最后一个元素为根节点
// int rootValue = postorder[postorder.length - 1];
// TreeNode root = new TreeNode(rootValue);
// // 如果为叶子节点直接返回
// if (postorder.length == 1) return root;
// //3. 寻找中序数组位置切割点
// int index = 0;
// for (int i = 0; i < inorder.length; i++) {
// if (inorder[i] == rootValue) {
// index = i;
// break;
// }
// }
// // 4.:切割中序数组,得到 中序左数组和中序右数组
// // 5.:切割后序数组,得到 后序左数组和后序右数组
// // root.left = buildTree(中序左数组, 后序左数组);
// // root.right = buildTree(中序右数组, 后序右数组);
map = new HashMap<>();
for (int i = 0; i < inorder.length; i++) { // 用map保存中序序列的数值对应位置
map.put(inorder[i],i);
}
return findNode(inorder,0,inorder.length,postorder,0,postorder.length);
}
public TreeNode findNode(int[] inorder, int inBegin,int inEnd, int[] postorder, int postBegin, int postEnd) {
if (inBegin >= inEnd || postBegin >= postEnd) { // 左闭右开
return null;
}
// 找到后序数组的最后一个元素在中序数组的位置
int rootIndex = map.get(postorder[postEnd - 1]);
// 构造根节点
TreeNode root = new TreeNode(inorder[rootIndex]);
int lenOfLeft = rootIndex - inBegin;
// 后序:左右中,中序:左中右
// 在中序中找到中的位置,中序左边的长度,也就是后序数组左的长度
root.left = findNode(inorder, inBegin, rootIndex, postorder, postBegin, postBegin + lenOfLeft);
root.right = findNode(inorder, rootIndex + 1, inEnd, postorder, postBegin + lenOfLeft, postEnd - 1);
return root;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
# 105.从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:

输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出: [3,9,20,null,null,15,7]
2
示例 2:
输入: preorder = [-1], inorder = [-1]
输出: [-1]
2
提示:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder和inorder均 无重复 元素inorder均出现在preorderpreorder保证 为二叉树的前序遍历序列inorder保证 为二叉树的中序遍历序列
package com.ep.LeetCode_Type.Tree;
import java.util.HashMap;
/***
* @author dep
* @version 1.0
* @date 2023-04-05 9:21
*/
public class exercise25_105_从前序与中序遍历序列构造二叉树 {
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {
}
TreeNode(int val) {
this.val = val;
}
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
static HashMap<Integer, Integer> map;
public TreeNode buildTree(int[] preorder, int[] inorder) {
if(preorder.length == 0) return null;
map = new HashMap<>();
for (int i = 0; i < inorder.length; i++) {
map.put(inorder[i], i);
}
return build(preorder,0,preorder.length,inorder,0,inorder.length);
}
public TreeNode build(int[] preorder, int preBegin, int preEnd, int[] inorder, int inBegin, int inEnd) {
if (preBegin >= preEnd || inBegin >= inEnd) { // 左闭右开
return null;
}
// 在前序数组中找到根结点
int rootValue = preorder[preBegin];
// 找到根节点在中序数组中的索引位置
int rootIndex = map.get(rootValue);
TreeNode root = new TreeNode(rootValue);
int lenOfLeft = rootIndex - inBegin;
root.left = build(preorder,preBegin + 1, preBegin + 1 + lenOfLeft, inorder,inBegin, rootIndex);
root.right = build(preorder, preBegin + 1 + lenOfLeft , preEnd, inorder, rootIndex + 1, inEnd);
return root;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 654.最大二叉树
给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建:
- 创建一个根节点,其值为
nums中的最大值。 - 递归地在最大值 左边 的 子数组前缀上 构建左子树。
- 递归地在最大值 右边 的 子数组后缀上 构建右子树。
返回 nums 构建的 最大二叉树 。
示例 1:
输入:nums = [3,2,1,6,0,5]
输出:[6,3,5,null,2,0,null,null,1]
解释:递归调用如下所示:
- [3,2,1,6,0,5] 中的最大值是 6 ,左边部分是 [3,2,1] ,右边部分是 [0,5] 。
- [3,2,1] 中的最大值是 3 ,左边部分是 [] ,右边部分是 [2,1] 。
- 空数组,无子节点。
- [2,1] 中的最大值是 2 ,左边部分是 [] ,右边部分是 [1] 。
- 空数组,无子节点。
- 只有一个元素,所以子节点是一个值为 1 的节点。
- [0,5] 中的最大值是 5 ,左边部分是 [0] ,右边部分是 [] 。
- 只有一个元素,所以子节点是一个值为 0 的节点。
- 空数组,无子节点。
2
3
4
5
6
7
8
9
10
11
12
示例 2:

输入:nums = [3,2,1]
输出:[3,null,2,null,1]
2
提示:
1 <= nums.length <= 10000 <= nums[i] <= 1000nums中的所有整数 互不相同
package com.ep.LeetCode_Type.Tree;
/***
* @author dep
* @version 1.0
* @date 2023-04-06 9:08
*/
public class exercise26_654_最大二叉树 {
public static class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {
}
TreeNode(int val) {
this.val = val;
}
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
public static TreeNode constructMaximumBinaryTree(int[] nums) {
TreeNode root = build(nums, 0, nums.length);
return root;
}
public static TreeNode build(int[] nums, int begin, int end) {
if (begin >= end) {
return null;
}
// 找到根节点的索引( 最大值)
Integer max = Integer.MIN_VALUE;
Integer rootIndex = -1;
for (int i = begin; i < end; i++) {
if (nums[i] > max) {
max = nums[i];
rootIndex = i;
}
}
TreeNode root = new TreeNode(max);
root.left = build(nums, begin, rootIndex);
root.right = build(nums, rootIndex + 1, end);
return root;
}
public static void main(String[] args) {
int[] nums = {3,2,1,6,0,5};
TreeNode treeNode = constructMaximumBinaryTree(nums);
preTree(treeNode);
}
public static void preTree(TreeNode root) {
if (root == null) {
return;
}
System.out.println(root.val);
preTree(root.left);
preTree(root.right);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
# 617.合并二叉树
给你两棵二叉树: root1 和 root2 。
想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
返回合并后的二叉树。
注意: 合并过程必须从两个树的根节点开始。
示例 1:

输入:root1 = [1,3,2,5], root2 = [2,1,3,null,4,null,7]
输出:[3,4,5,5,4,null,7]
2
示例 2:
输入:root1 = [1], root2 = [1,2]
输出:[2,2]
2
提示:
- 两棵树中的节点数目在范围
[0, 2000]内 -104 <= Node.val <= 104
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
TreeNode root = new TreeNode();
if (root1 != null && root2 != null) {
root.val = root1.val + root2.val;
root.left = mergeTrees(root1.left, root2.left);
root.right = mergeTrees(root1.right, root2.right);
return root;
}else if (root1 != null && root2 == null) {
root.val = root1.val;
root.left = mergeTrees(root1.left, null);
root.right = mergeTrees(root1.right, null);
return root;
}else if (root2 != null && root1 == null) {
root.val = root2.val;
root.left = mergeTrees(null, root2.left);
root.right = mergeTrees(null, root2.right);
return root;
} else {
return null;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// 前中序合并都可以,这里用前序
public TreeNode mergeTrees2(TreeNode root1, TreeNode root2) {
if (root1 == null) return root2;
if (root2 == null) return root1;
root1.val += root2.val;
root1.left = mergeTrees2(root1.left, root2.left);
root1.right = mergeTrees2(root1.right, root2.right);
return root1;
}
2
3
4
5
6
7
8
9
// 迭代法
public TreeNode mergeTrees3(TreeNode root1, TreeNode root2) {
if (root1 == null) return root2;
if (root2 == null) return root1;
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root1);
queue.add(root2);
while (!queue.isEmpty()) {
TreeNode node1 = queue.poll();
TreeNode node2 = queue.poll();
// 此时两节点一定不为空,val相加
node1.val += node2.val;
// 如果两棵树左节点都不为空,加入队列
if (node1.left != null && node2.left != null) {
queue.add(node1.left);
queue.add(node2.left);
}
// 如果两棵树右节点都不为空,加入队列
if (node1.right != null && node2.right != null) {
queue.add(node1.right);
queue.add(node2.right);
}
// 当t1的左节点 为空, t2节点不为空,就赋值过去
if (node1.left == null && node2.left != null) {
node1.left = node2.left;
}
if (node1.right == null && node2.right != null) {
node1.right = node2.right;
}
}
return root1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 700.二叉搜索树中的搜索
给定二叉搜索树(BST)的根节点 root 和一个整数值 val。
你需要在 BST 中找到节点值等于 val 的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 null 。
示例 1:

输入:root = [4,2,7,1,3], val = 2
输出:[2,1,3]
2
示例 2:
输入:root = [4,2,7,1,3], val = 5
输出:[]
2
提示:
- 数中节点数在
[1, 5000]范围内 1 <= Node.val <= 107root是二叉搜索树1 <= val <= 107
// searchBST(root->left, val),别忘了 递归函数还有返回值。
//递归函数的返回值是什么? 是 左子树如果搜索到了val,要将该节点返回。
// 如果不用一个变量将其接住,那么返回值不就没了。
public TreeNode searchBST(TreeNode root, int val) {
if (root == null || val == root.val) return root;
TreeNode result = null;
if(val > root.val) {
result = searchBST(root.right, val);
} else if (val < root.val) {
result = searchBST(root.left, val);
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
// 迭代法
public TreeNode searchBST2(TreeNode root, int val) {
while (root != null) {
if (val == root.val) {
return root;
}
root = val > root.val ? root.right : root.left;
}
return null;
}
2
3
4
5
6
7
8
9
10
# 98.验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
- 节点的左子树只包含 小于 当前节点的数。
- 节点的右子树只包含 大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:

输入:root = [2,1,3]
输出:true
2
示例 2:

输入:root = [5,1,4,null,null,3,6]
输出:false
解释:根节点的值是 5 ,但是右子节点的值是 4 。
2
3
提示:
- 树中节点数目范围在
[1, 104]内 -231 <= Node.val <= 231 - 1
static List<Integer> res = new LinkedList<>();
// 中序遍历,二叉搜索树中序遍历可以得到一个有序序列
public void inorder(TreeNode root) {
if (root == null) return;
inorder(root.left);
res.add(root.val);
inorder(root.right);
}
public boolean isValidBST(TreeNode root) {
res.clear();
inorder(root);
for (int i = 1; i < res.size(); i++) {
if (res.get(i-1) >= res.get(i)) return false;
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public boolean isValidBST(TreeNode root) {
return isValidBST(root,Long.MIN_VALUE, Long.MAX_VALUE);
}
public boolean isValidBST(TreeNode node, long lower, long upper) {
if (node == null) return true;
if (node.val <= lower || node.val >= upper) return false;
return isValidBST(node.left, lower, node.val) && isValidBST(node.right, node.val, upper);
}
2
3
4
5
6
7
8
// 迭代
public boolean isValidBST2(TreeNode root) {
Deque<TreeNode> stack = new LinkedList<>();
double inorder = -Double.MAX_VALUE;
while (!stack.isEmpty() || root != null) {
while (root != null) {
stack.push(root);
root = root.left;
}
root = stack.pop();
// 如果中序遍历得到的节点的值小于前一个inorder,说明不是二叉搜索树
if (root.val <= inorder) {
return false;
}
inorder = root.val;
root = root.right;
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 530.二叉搜索树的最小绝对差
给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。
差值是一个正数,其数值等于两值之差的绝对值。
示例 1:
输入:root = [4,2,6,1,3]
输出:1
2
示例 2:

输入:root = [1,0,48,null,null,12,49]
输出:1
2
提示:
- 树中节点的数目范围是
[2, 104] 0 <= Node.val <= 105
int min = Integer.MAX_VALUE;
TreeNode pre;
public int getMinimumDifference(TreeNode root) {
dfs(root);
return min;
}
public void dfs(TreeNode node) {
if (node == null) return;
dfs(node.left);
if (pre != null) {
min = Math.min(min, node.val - pre.val);
}
pre = node;
dfs(node.right);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int min;
int pre;
public int getMinimumDifference(TreeNode root) {
min = Integer.MAX_VALUE;
pre = -1;
dfs(root);
return min;
}
public void dfs(TreeNode node) {
if (node == null) return;
dfs(node.left);
if (pre == -1) {
pre = node.val;
}else {
min = Math.min(min,node.val - pre);
pre = node.val;
}
dfs(node.right);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// 迭代法
public int getMinimumDifference2(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
TreeNode pre = null;
int min = Integer.MAX_VALUE;
while (!stack.isEmpty() || curr != null) {
if (curr != null) {
stack.push(curr);
curr = curr.left;
} else {
curr = stack.pop();
if (pre != null) {
min = Math.min(min, curr.val - pre.val);
}
pre = curr;
curr = curr.right;
}
}
return min;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 501.二叉搜索树中的众数
给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数 (opens new window)(即,出现频率最高的元素)。
如果树中有不止一个众数,可以按 任意顺序 返回。
假定 BST 满足如下定义:
- 结点左子树中所含节点的值 小于等于 当前节点的值
- 结点右子树中所含节点的值 大于等于 当前节点的值
- 左子树和右子树都是二叉搜索树
示例 1:
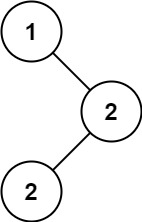
输入:root = [1,null,2,2]
输出:[2]
2
示例 2:
输入:root = [0]
输出:[0]
2
提示:
- 树中节点的数目在范围
[1, 104]内 -105 <= Node.val <= 105
// 借助额外的空间
static HashMap<Integer, Integer> map;
public int[] findMode1(TreeNode root) {
List<Integer> list = new ArrayList<>();
if (root == null) list.stream().mapToInt(Integer::intValue).toArray();
map = new HashMap<>();
inorder(root);
// 对map进行排序
List<Map.Entry<Integer, Integer>> mapEntryList = map.entrySet().stream()
.sorted((c1, c2) -> c2.getValue().compareTo(c1.getValue()))
.collect(Collectors.toList());
list.add(mapEntryList.get(0).getKey());
for (int i = 1; i < mapEntryList.size(); i++) {
if (mapEntryList.get(i).getValue() == mapEntryList.get(i - 1).getValue()) {
list.add(mapEntryList.get(i).getKey());
} else {
break;
}
}
return list.stream().mapToInt(Integer::intValue).toArray();
}
public void inorder(TreeNode root) {
if (root == null) return;
inorder(root.left);
map.put(root.val, map.getOrDefault(root.val, 0 ) + 1);
inorder(root.right);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
static int count;
static int maxCount;
TreeNode pre;
List<Integer> list;
// 递归
public int[] findMode2(TreeNode root) {
count = 0;
maxCount = 0;
pre = null;
list = new ArrayList<>();
dfs(root);
return list.stream().mapToInt(Integer::intValue).toArray();
}
public void dfs(TreeNode curr) {
if (curr == null) return;
dfs(curr.left); // 左
// 中
if (pre == null) { // 第一个节点
count = 1;
} else if (pre.val == curr.val){ // 和前一个结点值相同
count ++;
} else {
count = 1;
}
pre = curr;
if (count == maxCount) { // 如果和最大值相同,则收集结果
list.add(curr.val);
}
if (count > maxCount) {
maxCount = count; // 更新最大频率
list.clear();
list.add(curr.val);
}
dfs(curr.right);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
// 迭代
public int[] findMode(TreeNode root) {
count = 0;
maxCount = 0;
pre = null;
list = new ArrayList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (!stack.isEmpty() || curr != null) {
if (curr != null) {
stack.push(curr);
curr = curr.left;
} else {
curr = stack.pop();
if (pre == null) {
count = 1;
} else if(pre.val == curr.val) {
count ++;
} else {
count = 1;
}
pre = curr;
if (count == maxCount) { // 如果和最大值相同,则收集结果
list.add(curr.val);
}
if (count > maxCount) {
maxCount = count; // 更新最大频率
list.clear();
list.add(curr.val);
}
curr = curr.right;
}
}
return list.stream().mapToInt(Integer::intValue).toArray();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 236.二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科 (opens new window)中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
示例 1:
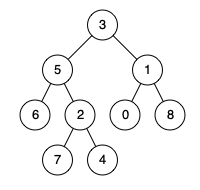
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
2
3
示例 2:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。
2
3
示例 3:
输入:root = [1,2], p = 1, q = 2
输出:1
2
提示:
- 树中节点数目在范围
[2, 105]内。 -109 <= Node.val <= 109- 所有
Node.val互不相同。 p != qp和q均存在于给定的二叉树中。
# 思路分析
如果找到一个节点,发现左子树出现结点p,右子树出现节点q,或者 左子树出现结点q,右子树出现节点p,那么该节点就是节点p和q的最近公共祖先。 即情况一:

public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == null || root == p || root == q) return root;
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p , q);
if (left != null && right != null) { // 左子树出现结点p,右子树出现节点q
return root;
}
if (left == null && right != null) {
return right;
} else if (left != null && right == null) {
return left;
} else {
return null;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 235.二叉搜索树的最近公共祖先
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科 (opens new window)中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]

示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输出: 6
解释: 节点 2 和节点 8 的最近公共祖先是 6。
2
3
示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
输出: 2
解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
2
3
说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉搜索树中。
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == null) return root;
if (p.val < root.val && root.val > q.val) { // 向左去搜索 p和q都在左子树
TreeNode left = lowestCommonAncestor(root.left, p, q);
if (left != null) {
return left;
}
}
if (q.val > root.val && p.val > root.val) { // 向左遍历 p和q都在右子树
TreeNode right = lowestCommonAncestor(root.right, p, q);
if (right != null) {
return right;
}
}
// 剩下就是在p和q中间,并且也一定是最近公共祖先
return root;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 迭代法
public TreeNode lowestCommonAncestor2(TreeNode root, TreeNode p, TreeNode q) {
while (root != null) {
if (root.val > p.val && root.val > q.val) {
root = root.left;
} else if (root.val < p.val && root.val < q.val) {
root = root.right;
} else {
return root;
}
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 701.二叉搜索树中的插入操作
给定二叉搜索树(BST)的根节点 root 和要插入树中的值 value ,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。
注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回 任意有效的结果 。
示例 1:

输入:root = [4,2,7,1,3], val = 5
输出:[4,2,7,1,3,5]
解释:另一个满足题目要求可以通过的树是:
2
3
示例 2:
输入:root = [40,20,60,10,30,50,70], val = 25
输出:[40,20,60,10,30,50,70,null,null,25]
2
示例 3:
输入:root = [4,2,7,1,3,null,null,null,null,null,null], val = 5
输出:[4,2,7,1,3,5]
2
提示:
- 树中的节点数将在
[0, 104]的范围内。 -108 <= Node.val <= 108- 所有值
Node.val是 独一无二 的。 -108 <= val <= 108- 保证
val在原始BST中不存在。
// 二叉搜索树新插入的节点是叶子结点
public TreeNode insertIntoBST(TreeNode root, int val) {
if (root == null) {
TreeNode node = new TreeNode(val);
root = node;
}
if (root.val > val) {
root.left = insertIntoBST(root.left, val);
}
if (root.val < val) {
root.right = insertIntoBST(root.right, val);
}
return root;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
TreeNode parent;
public TreeNode insertIntoBST2(TreeNode root, int val) {
if (root == null) {
root = new TreeNode(val);
}
dfs(root, val);
return root;
}
public void dfs(TreeNode curr, int val) {
if (curr == null){
if (val > parent.val) parent.right = new TreeNode(val);
else parent.left = new TreeNode(val);
return;
}
parent = curr;
if (val < curr.val) dfs(curr.left, val);
if (val > curr.val) dfs(curr.right, val);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 迭代法
public TreeNode insertIntoBST3(TreeNode root, int val) {
if (root == null) {
root = new TreeNode(val);
return root;
}
TreeNode curr = root;
TreeNode parent = root;
while (curr != null) {
parent = curr;
if (curr.val > val) curr = curr.left;
else curr = curr.right;
}
if (val > parent.val) parent.right = new TreeNode(val);
else parent.left = new TreeNode(val);
return root;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 450.删除二叉搜索树中的节点
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
一般来说,删除节点可分为两个步骤:
- 首先找到需要删除的节点;
- 如果找到了,删除它。
示例 1:
输入:root = [5,3,6,2,4,null,7], key = 3
输出:[5,4,6,2,null,null,7]
解释:给定需要删除的节点值是 3,所以我们首先找到 3 这个节点,然后删除它。
一个正确的答案是 [5,4,6,2,null,null,7], 如下图所示。
另一个正确答案是 [5,2,6,null,4,null,7]。
2
3
4
5
示例 2:
输入: root = [5,3,6,2,4,null,7], key = 0
输出: [5,3,6,2,4,null,7]
解释: 二叉树不包含值为 0 的节点
2
3
示例 3:
输入: root = [], key = 0
输出: []
2
提示:
- 节点数的范围
[0, 104]. -105 <= Node.val <= 105- 节点值唯一
root是合法的二叉搜索树-105 <= key <= 105
// 1.删除的节点是左叶子结点
// 2.删除的节点是右叶子结点
// 3.删除的节点是根节点
// 4.删除的节点是左节点
// 5.删除的节点是右结点
public TreeNode delete(TreeNode curr, int key) {
if (curr == null) return curr;
if (curr.val > key) {
curr.left = delete(curr.left, key);
}else if (curr.val < key) {
curr.right = delete(curr.right, key);
} else {
if (curr.left == null) return curr.right;
if (curr.right == null) return curr.left;
TreeNode temp = curr.right;
while (temp.left != null) {
temp = temp.left;
}
curr.val = temp.val;
curr.right = delete(curr.right, temp.val);
}
return curr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public TreeNode deleteNode(TreeNode root, int key) {
if (root == null) return root; // 第一种情况,没找到删除的节点,遍历到空节点值
if (root.val == key) {
// 第二种情况: 左右孩子都为空(叶子结点),直接删除结点
if (root.left == null && root.right == null) {
return null;
}
// 第三种情况:左孩子为空,右孩子不为空,删除节点,右孩子补位,返回右孩子为根节点
else if (root.left == null) {
return root.right;
}
// 第四种情况:其右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
else if (root.right == null) {
return root.left;
}
// 第五种情况:左右孩子节点都不为空,则将删除节点的左子树放到删除节点的右子树的最左面节点的左孩子的位置
// 并返回删除节点右孩子为新的根节点。
else {
TreeNode cur = root.right; // 找右子树最左面的节点
while (cur.left != null) {
cur = cur.left;
}
cur.left = root.left; // 把要删除的节点(root)左子树放在cur的左子树的位置
root = root.right; // 返回旧root作为新root
return root;
}
}
if (root.val > key) root.left = deleteNode(root.left, key);
if (root.val < key) root.right = deleteNode(root.right, key);
return root;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// 迭代
// 1.删除的节点是左叶子结点
// 2.删除的节点是右叶子结点
// 3.删除的节点是根节点
// 4.删除的节点是左节点
// 5.删除的节点是右结点
// 将目标节点(删除节点)的左子树放到 目标节点的右子树的最左面节点的左孩子位置上
// 并返回目标节点右孩子为新的根节点
public TreeNode deleteOneNode(TreeNode target) {
if (target == null) return target;
// 右子树为空,就返回左结点。(也包含了左子树为空,返回空)直接pre指向 target.left (实现了删除target)
if (target.right == null) return target.left;
// 找到右子树最左结点
TreeNode curr = target.right;
while (curr.left != null) {
curr = curr.left;
}
curr.left = target.left;
return target.right;
}
public TreeNode deleteNode2(TreeNode root, int key) {
TreeNode curr = root;
TreeNode pre = null;
while (curr != null) {
if (curr.val == key) break;
pre = curr;
if (curr.val < key) curr = curr.right;
else curr = curr.left;
}
if (pre == null) { // 要删除的节点是根节点
return deleteOneNode(curr);
}
if (pre.val < key) { // 删除的是右节点
pre.right = deleteOneNode(curr);
} else {
pre.left = deleteOneNode(curr);
}
return root;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 669.修剪二叉搜索树
给你二叉搜索树的根节点 root ,同时给定最小边界low 和最大边界 high。通过修剪二叉搜索树,使得所有节点的值在[low, high]中。修剪树 不应该 改变保留在树中的元素的相对结构 (即,如果没有被移除,原有的父代子代关系都应当保留)。 可以证明,存在 唯一的答案 。
所以结果应当返回修剪好的二叉搜索树的新的根节点。注意,根节点可能会根据给定的边界发生改变。
示例 1:

输入:root = [1,0,2], low = 1, high = 2
输出:[1,null,2]
2
示例 2:
输入:root = [3,0,4,null,2,null,null,1], low = 1, high = 3
输出:[3,2,null,1]
2
提示:
- 树中节点数在范围
[1, 104]内 0 <= Node.val <= 104- 树中每个节点的值都是 唯一 的
- 题目数据保证输入是一棵有效的二叉搜索树
0 <= low <= high <= 104
public TreeNode trimBST(TreeNode root, int low, int high) {
if (root == null) return null;
if (root.val < low) { // 此时root,以及root的左子树都是要删除的结点
// 不能直接return root.right (因为右子树也可能存在比low小的)
TreeNode right = trimBST(root.right, low, high);
return right;
}
if (root.val > high) {
TreeNode left = trimBST(root.left, low, high);
return left;
}
root.left = trimBST(root.left, low, high);
root.right = trimBST(root.right, low, high);
return root;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 108.将有序数组转换为二叉搜索树
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
示例 1:

输入:nums = [-10,-3,0,5,9]
输出:[0,-3,9,-10,null,5]
解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案:
2
3
示例 2:
输入:nums = [1,3]
输出:[3,1]
解释:[1,null,3] 和 [3,1] 都是高度平衡二叉搜索树。
2
3
提示:
1 <= nums.length <= 104-104 <= nums[i] <= 104nums按 严格递增 顺序排列
public TreeNode sortedArrayToBST(int[] nums) {
if (nums.length == 0) return null;
return buildBST(nums, 0, nums.length - 1);
}
// 左闭右闭区间
public TreeNode buildBST(int[] nums, int start, int end) {
if (start > end) return null;
int mid = start + end >> 1;
TreeNode root = new TreeNode(nums[mid]);
root.left = buildBST(nums, start, mid - 1);
root.right = buildBST(nums, mid + 1 , end);
return root;
}
2
3
4
5
6
7
8
9
10
11
12
13
// 迭代法
public TreeNode sortedArrayToBST2(int[] nums) {
if (nums.length == 0) return null;
Queue<Integer> leftQueue = new LinkedList<>(); // 存放左区间
Queue<Integer> rightQueue = new LinkedList<>(); // 存放右区间
Queue<TreeNode> nodeQueue = new LinkedList<>(); // 存放结点
TreeNode root = new TreeNode(0);
nodeQueue.add(root);
leftQueue.add(0);
rightQueue.add(nums.length - 1);
while (!nodeQueue.isEmpty()) {
int left = leftQueue.poll();
int right = rightQueue.poll();
TreeNode node = nodeQueue.poll();
int mid = left + (right - left) / 2;
node.val = nums[mid];
if (left <= mid - 1) {
node.left = new TreeNode(0);
nodeQueue.add(node.left);
leftQueue.add(left);
rightQueue.add(mid - 1);
}
if (right >= mid + 1) {
node.right = new TreeNode(0);
nodeQueue.add(node.right);
leftQueue.add(mid + 1);
rightQueue.add(right);
}
}
return root;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 538.把二叉搜索树转换为累加树
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
提醒一下,二叉搜索树满足下列约束条件:
- 节点的左子树仅包含键 小于 节点键的节点。
- 节点的右子树仅包含键 大于 节点键的节点。
- 左右子树也必须是二叉搜索树。
**注意:**本题和 1038: https://leetcode-cn.com/problems/binary-search-tree-to-greater-sum-tree/ 相同
示例 1:

输入:[4,1,6,0,2,5,7,null,null,null,3,null,null,null,8]
输出:[30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
2
示例 2:
输入:root = [0,null,1]
输出:[1,null,1]
2
示例 3:
输入:root = [1,0,2]
输出:[3,3,2]
2
示例 4:
输入:root = [3,2,4,1]
输出:[7,9,4,10]
2
提示:
- 树中的节点数介于
0和104之间。 - 每个节点的值介于
-104和104之间。 - 树中的所有值 互不相同 。
- 给定的树为二叉搜索树。
int pre = 0;
public TreeNode convertBST(TreeNode root) {
dfs(root);
return root;
}
public void dfs(TreeNode root) { // 右中左遍历
if (root == null) return;
dfs(root.right);
root.val += pre;
pre = root.val;
dfs(root.left);
}
2
3
4
5
6
7
8
9
10
11
12
// 迭代法(中序的迭代法)
public TreeNode convertBST2(TreeNode root) {
if (root == null) return root;
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
int pre = 0;
while (!stack.isEmpty() || curr != null) {
if (curr != null) {
stack.push(curr); // 右
curr = curr.right;
} else {
curr = stack.pop(); // 中
curr.val += pre;
pre = curr.val;
curr = curr.left; //左
}
}
return root;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 回溯算法
回溯法也可以叫做回溯搜索法,它是一种搜索的方式。
回溯法解决的问题
回溯法,一般可以解决如下几种问题:
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
# 回溯法模板
- 回溯函数模板返回值以及参数
回溯算法中函数返回值一般为void。
void backtracking(参数)
- 回溯函数终止条件
if (终止条件) {
存放结果;
return;
}
2
3
4
- 回溯搜索的遍历过程

for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
2
3
4
5
for循环就是遍历集合区间,可以理解一个节点有多少个孩子,这个for循环就执行多少次。
backtracking这里自己调用自己,实现递归。
for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。
完整模板
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 7.组合
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
2
3
4
5
6
7
8
9
10
示例 2:
输入:n = 1, k = 1
输出:[[1]]
2
提示:
1 <= n <= 201 <= k <= n

package com.ep.LeetCode_Type.BackTracking;
import java.util.*;
/***
* @author dep
* @version 1.0
* @date 2023-03-30 10:22
*/
public class exercise1_77_组合 {
static List<Integer> path;
static List<List<Integer>> res;
public static List<List<Integer>> combine(int n, int k) {
path = new ArrayList<>();
res = new LinkedList<>();
backtracking(n,k,1);
return res;
}
// 1. 确定参数和返回值
static void backtracking(int n, int k, int startIndex){
// 2.确定终止条件
if (path.size() == k) {
res.add(new ArrayList<>(path));
return;
}
// 3.回溯遍历搜索过程
for (int i = startIndex; i <= n; i++) {
path.add(i);
backtracking(n,k,i+1);
path.remove(path.size() - 1);
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int k = scanner.nextInt();
List<List<Integer>> combine = combine(n, k);
System.out.println(combine);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 剪枝优化

- 已经选择的元素个数:path.size();
- 还需要的元素个数为: k - path.size();
- 在集合n中至多要从该起始位置 : n - (k - path.size()) + 1,开始遍历
为什么有个+1呢,因为包括起始位置,我们要是一个左闭的集合。
举个例子,n = 4,k = 3, 目前已经选取的元素为0(path.size为0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++) // i为本次搜索的起始位置
# 216.组合总和 III
找出所有相加之和为 n 的 k 个数的组合,且满足下列条件:
- 只使用数字1到9
- 每个数字 最多使用一次
返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。
示例 1:
输入: k = 3, n = 7
输出: [[1,2,4]]
解释:
1 + 2 + 4 = 7
没有其他符合的组合了。
2
3
4
5
示例 2:
输入: k = 3, n = 9
输出: [[1,2,6], [1,3,5], [2,3,4]]
解释:
1 + 2 + 6 = 9
1 + 3 + 5 = 9
2 + 3 + 4 = 9
没有其他符合的组合了。
2
3
4
5
6
7
示例 3:
输入: k = 4, n = 1
输出: []
解释: 不存在有效的组合。
在[1,9]范围内使用4个不同的数字,我们可以得到的最小和是1+2+3+4 = 10,因为10 > 1,没有有效的组合。
2
3
4
package com.ep.LeetCode_Type.BackTracking;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
/***
* @author dep
* @version 1.0
* @date 2023-03-31 11:05
*/
public class exercise2_216_组合总和III {
static List<List<Integer>> res;
static List<Integer> path;
public static List<List<Integer>> combinationSum3(int k, int n) {
res = new LinkedList<>();
path = new ArrayList<>();
backtracking(n,k,1);
System.out.println(res);
return res;
}
// 1.确定参数和返回值
static void backtracking(int n, int k ,int startIndex) {
// 2.确定终止条件
if (path.size() == k) {
int sum = 0;
for (int i = 0; i < path.size(); i++) {
sum += path.get(i);
}
if (sum == n) {
res.add(new ArrayList<>(path));
}
return;
}
// 回溯搜索遍历
for (int i = startIndex; i <= 9 - (k - path.size()) + 1; i++) {
path.add(i);
if (i <= n){
backtracking(n,k,i + 1);
}
path.remove(path.size() - 1);
}
}
public static void main(String[] args) {
int n = 1, k = 4;
combinationSum3(k,n);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 17.电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。

示例 1:
输入:digits = "23"
输出:["ad","ae","af","bd","be","bf","cd","ce","cf"]
2
示例 2:
输入:digits = ""
输出:[]
2
示例 3:
输入:digits = "2"
输出:["a","b","c"]
2
提示:
0 <= digits.length <= 4digits[i]是范围['2', '9']的一个数字。
package com.ep.LeetCode_Type.BackTracking;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
/***
* @author dep
* @version 1.0
* @date 2023-04-01 11:12
*/
public class exercise3_17_电话号码的字母组合 {
static List<String> res;
static StringBuffer path;
static String[] letterMap = {
"", // 0
"", // 1
"abc", // 2
"def", // 3
"ghi", // 4
"jkl", // 5
"mno", // 6
"pqrs", // 7
"tuv", // 8
"wxyz", // 9
};
public List<String> letterCombinations(String digits) {
res = new LinkedList<>();
path = new StringBuffer();
if (digits == null || digits.length() == 0) {
return res;
}
backTracking(digits,0);
return res;
}
// 确定参数和返回值
void backTracking(String digits,int index) {
// 确定终止条件
if (index == digits.length()) {
res.add(path.toString());
return;
}
Integer digit = digits.charAt(index) - '0';
String letters = letterMap[digit];
for (int i = 0; i < letters.length(); i++) {
path.append(letters.charAt(i));
backTracking(digits, index + 1);
path.deleteCharAt(path.length() - 1); // 回溯
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# 39.组合总和
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
示例 1:
输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]]
解释:
2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。
7 也是一个候选, 7 = 7 。
仅有这两种组合。
2
3
4
5
6
示例 2:
输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]]
2
示例 3:
输入: candidates = [2], target = 1
输出: []
2
提示:
1 <= candidates.length <= 302 <= candidates[i] <= 40candidates的所有元素 互不相同1 <= target <= 40
package com.ep.LeetCode_Type.BackTracking;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
/***
* @author dep
* @version 1.0
* @date 2023-04-02 11:01
*/
public class exercise4_39_组合总和 {
static List<Integer> path;
static List<List<Integer>> res;
public static List<List<Integer>> combinationSum(int[] candidates, int target) {
path = new ArrayList<>();
res = new LinkedList<>();
Arrays.sort(candidates);
backTracking(candidates, target,0,0);
return res;
}
// 1. 确定返回值和参数
static void backTracking(int[] candidates, int target, int sum, int startIndex) {
if (sum > target) return;
// 2. 确定终止条件
if (sum == target) {
res.add(new ArrayList<>(path));
return;
}
// 3.回溯遍历搜索过程
for (int i = startIndex; i < candidates.length; i++) {
if (sum + candidates[i] > target) break;
path.add(candidates[i]);
sum += candidates[i];
backTracking(candidates, target, sum, i);
sum -= candidates[i];
path.remove(path.size() - 1);
}
}
public static void main(String[] args) {
int[] candidates = {8,7,4,3}; int target = 11;
List<List<Integer>> lists = combinationSum(candidates, target);
System.out.println(lists);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# 40.组合总和 II
给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用 一次 。
**注意:**解集不能包含重复的组合。
示例 1:
输入: candidates = [10,1,2,7,6,1,5], target = 8,
输出:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
2
3
4
5
6
7
8
示例 2:
输入: candidates = [2,5,2,1,2], target = 5,
输出:
[
[1,2,2],
[5]
]
2
3
4
5
6
提示:
1 <= candidates.length <= 1001 <= candidates[i] <= 501 <= target <= 30
关键:去重
package com.ep.LeetCode_Type.BackTracking;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
/***
* @author dep
* @version 1.0
* @date 2023-04-04 10:17
*/
public class exercise5_40_组合总和II {
static List<Integer> path;
static List<List<Integer>> res;
public static List<List<Integer>> combinationSum2(int[] candidates, int target) {
path = new ArrayList<>();
res = new LinkedList<>();
int[] used = new int[candidates.length];
Arrays.sort(candidates);
backTracking(candidates,target,0,0,used);
return res;
}
// 1.确定函数返回值和参数
static void backTracking(int[] candidates, int target, int sum, int startIndex, int[] used){
// 2. 确定终止条件
if (sum == target) {
res.add(new ArrayList<>(path));
return;
}
for (int i = startIndex; i < candidates.length; i++) {
if (sum + candidates[i] > target) {
break;
}
// used[i - 1] == 1,说明同一树枝candidates[i - 1]使用过
// used[i - 1] == 0,说明同一树层candidates[i - 1]使用过
// 要对同一树层使用过的元素进行跳过
if (i > 0 && candidates[i] == candidates[i-1] && used[i-1] == 0) { // 去重
continue;
}
path.add(candidates[i]);
used[i] = 1;
backTracking(candidates, target, sum + candidates[i], i + 1, used);
used[i] = 0;
path.remove(path.size() - 1);
}
}
public static void main(String[] args) {
int[] candidates = {10,1,2,7,6,1,5};
int target = 8;
List<List<Integer>> lists = combinationSum2(candidates, target);
System.out.println(lists);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
# 131.分割回文串
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
回文串 是正着读和反着读都一样的字符串。
示例 1:
输入:s = "aab"
输出:[["a","a","b"],["aa","b"]]
2
示例 2:
输入:s = "a"
输出:[["a"]]
2
提示:
1 <= s.length <= 16s仅由小写英文字母组成

package com.ep.LeetCode_Type.BackTracking;
import java.util.ArrayList;
import java.util.List;
/***
* @author dep
* @version 1.0
* @date 2023-04-05 9:52
*/
public class exercise6_131_分割回文串 {
static List<String> path;
static List<List<String>> res;
public static List<List<String>> partition(String s) {
path = new ArrayList<>();
res = new ArrayList<>();
backTracking(s,0);
return res;
}
// 1.确定参数和返回值
public static void backTracking(String s, int startIndex) {
if (startIndex >= s.length()) {
res.add(new ArrayList<>(path));
return;
}
// startIndex相当于是切割线
for (int i = startIndex; i < s.length(); i++) {
// 如果是回文字符串,则记录
if (isHuiWen(s, startIndex, i)){
path.add(s.substring(startIndex, i+1)); // 截取左闭右开
} else {
continue;
}
// 起始位置后移,保证不重复
backTracking(s, i+1);
path.remove(path.size() - 1);
}
}
// 判断你是否是回文
public static Boolean isHuiWen(String s, int left, int end) {
if (left == end) return true;
int i, j;
for ( i = left, j = end ; i < j; i++, j--) {
if (s.charAt(i) != s.charAt(j)) {
return false;
}
}
return true;
}
public static void main(String[] args) {
String s ="cdd";
List<List<String>> partition = partition(s);
System.out.println(partition);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# 93.复原 IP 地址
有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 '.' 分隔。
- 例如:
"0.1.2.201"和"192.168.1.1"是 有效 IP 地址,但是"0.011.255.245"、"192.168.1.312"和"192.168@1.1"是 无效 IP 地址。
给定一个只包含数字的字符串 s ,用以表示一个 IP 地址,返回所有可能的有效 IP 地址,这些地址可以通过在 s 中插入 '.' 来形成。你 不能 重新排序或删除 s 中的任何数字。你可以按 任何 顺序返回答案。
示例 1:
输入:s = "25525511135"
输出:["255.255.11.135","255.255.111.35"]
2
示例 2:
输入:s = "0000"
输出:["0.0.0.0"]
2
示例 3:
输入:s = "101023"
输出:["1.0.10.23","1.0.102.3","10.1.0.23","10.10.2.3","101.0.2.3"]
2
提示:
1 <= s.length <= 20s仅由数字组成
package com.ep.LeetCode_Type.BackTracking;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
/***
* @author dep
* @version 1.0
* @date 2023-04-07 9:34
*/
public class exercise7_93_复原IP地址 {
static List<String> res;
public static List<String> restoreIpAddresses(String s) {
res = new LinkedList<>();
if (s.length() > 12) return res;
backTracking(new StringBuffer(s),0,0);
return res;
}
// 1.确定参数和返回值
public static void backTracking(StringBuffer s, int startIndex, int pointSum) {
// 2.终止条件
if (pointSum == 3) {
// 判断最后一个是否合法
if (isValid(s, startIndex, s.length() - 1)) {
res.add(s.toString());
}
return;
}
// 搜索遍历
for (int i = startIndex; i < s.length(); i++) {
if (isValid(s, startIndex, i)) {
s.insert(i + 1, '.');
pointSum++;
backTracking(s, i + 2, pointSum);
s.deleteCharAt(i+1);
pointSum--;
} else {
break;
}
}
}
// 是否是合法的ip数字(左闭右闭)
public static Boolean isValid(StringBuffer s, int start, int end) {
if (end - start + 1 > 3) return false;
if (start > end) return false;
// 0 开头的数字不合法
if (s.charAt(start) == '0' && start != end) {
return false;
}
int num = 0;
for (int i = start; i <= end; i++) {
if (s.charAt(i) > '9' || s.charAt(i) < '0') {
return false;
}
num = num * 10 + (s.charAt(i) - '0');
if (num > 255) {
return false;
}
}
return true;
}
public static void main(String[] args) {
String s = "0000";
System.out.println(restoreIpAddresses(s));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
# 78.子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
2
示例 2:
输入:nums = [0]
输出:[[],[0]]
2
提示:
1 <= nums.length <= 10-10 <= nums[i] <= 10nums中的所有元素 互不相同

package com.ep.LeetCode_Type.BackTracking;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
/***
* @author dep
* @version 1.0
* @date 2023-04-09 10:04
*/
public class exercise8_78_子集 {
static List<Integer> path;
static List<List<Integer>> res;
public static List<List<Integer>> subsets(int[] nums) {
res = new LinkedList<>();
path = new LinkedList<>();
if (nums.length == 0) {
res.add(new ArrayList<>(path));
return res;
}
backTracking(nums, 0);
return res;
}
// 子集问题与组合问题的区别,组合问题只需要在叶子结点收集结果,而子集节点每层都要收集结果
public static void backTracking(int[] nums, int startIndex) {
res.add(new ArrayList<>(path));
// // 终止条件 (这里可以不用写), 因为startIndex >= nums.length之后下面的for循环就不会执行了
// if (startIndex >= nums.length) {
// return;
// }
// 遍历搜索
for (int i = startIndex; i < nums.length; i++) {
path.add(nums[i]);
backTracking(nums,i+1);
path.remove(path.size() - 1);
}
}
public static void main(String[] args) {
int [] nums = {1,2,3};
List<List<Integer>> subsets = subsets(nums);
System.out.println(subsets);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# 90.子集 II
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
示例 1:
输入:nums = [1,2,2]
输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]
2
示例 2:
输入:nums = [0]
输出:[[],[0]]
2
提示:
1 <= nums.length <= 10-10 <= nums[i] <= 10
package com.ep.LeetCode_Type.BackTracking;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
/***
* @author dep
* @version 1.0
* @date 2023-04-10 9:10
*/
public class exercise9_90_子集II {
static List<Integer> path = new ArrayList<>();
static List<List<Integer>> res = new LinkedList<>();
public static List<List<Integer>> subsetsWithDup(int[] nums) {
Arrays.sort(nums);
int[] used = new int[nums.length];
backTracking(nums, 0,used);
return res;
}
// 1. 确定参数和返回值
public static void backTracking(int[] nums, int startIndex, int[] used) {
res.add(new ArrayList<>(path));
// 2.确定终止条件 (自己问题不需要去重)
// if (startIndex >= nums.length) {
// return;
// }
for (int i = startIndex; i < nums.length; i++) {
if (i > 0 && nums[i] == nums[i - 1] && used[i-1] == 0) { // 难点:树层去重
continue;
}
path.add(nums[i]);
used[i] = 1;
backTracking(nums, i+1,used);
used[i] = 0;
path.remove(path.size() - 1);
}
}
public static void main(String[] args) {
int[] nums = {1,2,2};
System.out.println(subsetsWithDup(nums));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# 491.递增子序列
给你一个整数数组 nums ,找出并返回所有该数组中不同的递增子序列,递增子序列中 至少有两个元素 。你可以按 任意顺序 返回答案。
数组中可能含有重复元素,如出现两个整数相等,也可以视作递增序列的一种特殊情况。
示例 1:
输入:nums = [4,6,7,7]
输出:[[4,6],[4,6,7],[4,6,7,7],[4,7],[4,7,7],[6,7],[6,7,7],[7,7]]
2
示例 2:
输入:nums = [4,4,3,2,1]
输出:[[4,4]]
2
提示:
1 <= nums.length <= 15-100 <= nums[i] <= 100
同一父节点下的同层上使用过的元素就不能再使用了

package com.ep.LeetCode_Type.BackTracking;
import java.util.*;
/***
* @author dep
* @version 1.0
* @date 2023-04-11 10:14
*/
public class exercise10_491_递增子序列 {
static List<Integer> path;
static List<List<Integer>> res;
public static List<List<Integer>> findSubsequences(int[] nums) {
path = new ArrayList<>();
res = new LinkedList<>();
backTracking(nums,0);
return res;
}
public static void backTracking(int[] nums, int startIndex) {
if (path.size() >= 2) {
res.add(new ArrayList<>(path));
}
HashMap<Integer, Integer> used = new HashMap<>();
for (int i = startIndex; i < nums.length; i++) {
if(path.size() > 0 && nums[i] < path.get(path.size() - 1) || used.getOrDefault(nums[i], 0) >= 1) {
continue;
}
used.put(nums[i], used.getOrDefault(nums[i],0) + 1); // 不用回溯,只记录本层递归中是否有重复的
path.add(nums[i]);
backTracking(nums, i + 1);
path.remove(path.size() - 1);
}
}
public static void main(String[] args) {
int[] nums ={4,6,7,7};
System.out.println(findSubsequences(nums));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 46.全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
2
示例 2:
输入:nums = [0,1]
输出:[[0,1],[1,0]]
2
示例 3:
输入:nums = [1]
输出:[[1]]
2
提示:
1 <= nums.length <= 6-10 <= nums[i] <= 10nums中的所有整数 互不相同
package com.ep.LeetCode_Type.BackTracking;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
/***
* @author dep
* @version 1.0
* @date 2023-04-12 9:41
*/
public class exercise11_46_全排列 {
static List<Integer> path;
static List<List<Integer>> res;
public static List<List<Integer>> permute(int[] nums) {
path = new ArrayList<>();
res = new LinkedList<>();
int[] used = new int[nums.length];
backTracking(nums, used);
return res;
}
public static void backTracking(int[] nums, int[] used) {
if (path.size() == nums.length) {
res.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < nums.length; i++) {
// 这种写法也可以过
// if (path.contains(nums[i]) ) {
// continue;
// }
if (used[i] == 1) continue; // 说明已经获取过了
path.add(nums[i]);
used[i] = 1;
backTracking(nums, used);
used[i] = 0;
path.remove(path.size() - 1);
}
}
public static void main(String[] args) {
int[] nums = {1,2,3};
List<List<Integer>> permute = permute(nums);
System.out.println(permute);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 47.全排列 II
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]
2
3
4
5
示例 2:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
2
提示:
1 <= nums.length <= 8-10 <= nums[i] <= 10

如果要对树层中前一位去重,就用used[i - 1] == false,如果要对树枝前一位去重用used[i - 1] == true。
package com.ep.LeetCode_Type.BackTracking;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
/***
* @author dep
* @version 1.0
* @date 2023-04-13 10:02
*/
public class exercise12_47_全排列II {
static List<Integer> path;
static List<List<Integer>> res;
public static List<List<Integer>> permuteUnique(int[] nums) {
path = new LinkedList<>();
res = new LinkedList<>();
int[] used = new int[nums.length];
Arrays.sort(nums);
backTracking(nums, used);
return res;
}
public static void backTracking(int[] nums, int[] used) {
if (path.size() == nums.length) {
res.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < nums.length; i++) {
if (i > 0 && nums[i] == nums[i-1] && used[i-1] == 0) {
continue;
}
if(used[i] == 0) {
path.add(nums[i]);
used[i] = 1;
backTracking(nums, used);
used[i] = 0;
path.remove(path.size() - 1);
}
}
}
public static void main(String[] args) {
int[] nums = {1,2,3};
System.out.println(permuteUnique(nums));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# 332.重新安排行程
给你一份航线列表 tickets ,其中 tickets[i] = [fromi, toi] 表示飞机出发和降落的机场地点。请你对该行程进行重新规划排序。
所有这些机票都属于一个从 JFK(肯尼迪国际机场)出发的先生,所以该行程必须从 JFK 开始。如果存在多种有效的行程,请你按字典排序返回最小的行程组合。
- 例如,行程
["JFK", "LGA"]与["JFK", "LGB"]相比就更小,排序更靠前。
假定所有机票至少存在一种合理的行程。且所有的机票 必须都用一次 且 只能用一次。
示例 1:
输入:tickets = [["MUC","LHR"],["JFK","MUC"],["SFO","SJC"],["LHR","SFO"]]
输出:["JFK","MUC","LHR","SFO","SJC"]
2
示例 2:

输入:tickets = [["JFK","SFO"],["JFK","ATL"],["SFO","ATL"],["ATL","JFK"],["ATL","SFO"]]
输出:["JFK","ATL","JFK","SFO","ATL","SFO"]
解释:另一种有效的行程是 ["JFK","SFO","ATL","JFK","ATL","SFO"] ,但是它字典排序更大更靠后。
2
3
提示:
1 <= tickets.length <= 300tickets[i].length == 2fromi.length == 3toi.length == 3fromi和toi由大写英文字母组成fromi != toi
package com.ep.LeetCode_Type.BackTracking;
import com.sun.org.apache.bcel.internal.generic.IF_ACMPEQ;
import java.util.*;
/***
* @author dep
* @version 1.0
* @date 2023-04-16 9:41
*/
public class exercise13_332_重新安排行程 {
static LinkedList<String> res;
static LinkedList<String> path;
public static List<String> findItinerary(List<List<String>> tickets) {
path = new LinkedList<>();
Collections.sort(tickets, (a, b) -> a.get(1).compareTo(b.get(1)));
boolean[] used = new boolean[tickets.size()];
path.add("JFK");
backTracking((ArrayList) tickets, used);
return res;
}
public static boolean backTracking(ArrayList<List<String>> tickets, boolean[] used) {
if (path.size() == tickets.size() + 1) {
res = new LinkedList<>(path);
return true;
}
for (int i = 0; i < tickets.size(); i++) {
if (!used[i] && tickets.get(i).get(0).equals(path.getLast())) {
path.add(tickets.get(i).get(1));
used[i] = true;
if (backTracking(tickets, used)) {
return true;
}
used[i] = false;
path.removeLast();
}
}
return false;
}
public static void main(String[] args) {
List<List<String>> tickets = new LinkedList<List<String>>();
tickets.add(new LinkedList<String>(){
{add("JFK"); add("KUL");}
});
tickets.add(new LinkedList<String>(){
{add("JFK"); add("NRT");}
});
tickets.add(new LinkedList<String>(){
{add("NRT"); add("JFK");}
});
findItinerary(tickets);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# 51.N 皇后
按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
示例 1:
输入:n = 4
输出:[[".Q..","...Q","Q...","..Q."],["..Q.","Q...","...Q",".Q.."]]
解释:如上图所示,4 皇后问题存在两个不同的解法。
2
3
示例 2:
输入:n = 1
输出:[["Q"]]
2
提示:
1 <= n <= 9
package com.ep.LeetCode_Type.BackTracking;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
/***
* @author dep
* @version 1.0
* @date 2023-04-20 10:16
*/
public class exercise14_51_N皇后 {
static List<List<String>> res = new LinkedList<>();
public static List<List<String>> solveNQueens(int n) {
char[][] chessboard = new char[n][n];
for (char[] c :chessboard) {
Arrays.fill(c, '.');
}
backTracking(0, n, chessboard);
return res;
}
public static void backTracking(int row, int n, char[][] chessboard) {
if (row == n) {
res.add(ArrayToList(chessboard));
return;
}
for (int col = 0; col < n; col++) { // 代表列
if (isValid(row, col, n, chessboard)) {
chessboard[row][col] = 'Q';
backTracking(row + 1, n, chessboard);
chessboard[row][col] = '.';
}
}
}
public static List ArrayToList(char[][] chessboard) {
ArrayList<String> list = new ArrayList<>();
for (char[] c: chessboard) {
list.add(String.valueOf(c));
}
return list;
}
// 检查是否合法
public static boolean isValid(int row, int col, int n, char[][] chessboard) {
// 检查列
for (int i = 0; i < row; i++) {
if (chessboard[i][col] == 'Q') {
return false;
}
}
// 检查45度对角线
for (int i = row - 1, j = col - 1; i >= 0 && j >= 0 ; i--, j--) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
// 检查135度对角线
for (int i = row - 1, j = col + 1; i >= 0 && j <= n - 1; i--, j++) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
return true;
}
public static void main(String[] args) {
System.out.println(solveNQueens(1));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
# 37.解数独
编写一个程序,通过填充空格来解决数独问题。
数独的解法需 遵循如下规则:
- 数字
1-9在每一行只能出现一次。 - 数字
1-9在每一列只能出现一次。 - 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。(请参考示例图)
数独部分空格内已填入了数字,空白格用 '.' 表示。
示例 1:

输入:board = [["5","3",".",".","7",".",".",".","."],["6",".",".","1","9","5",".",".","."],[".","9","8",".",".",".",".","6","."],["8",".",".",".","6",".",".",".","3"],["4",".",".","8",".","3",".",".","1"],["7",".",".",".","2",".",".",".","6"],[".","6",".",".",".",".","2","8","."],[".",".",".","4","1","9",".",".","5"],[".",".",".",".","8",".",".","7","9"]]
输出:[["5","3","4","6","7","8","9","1","2"],["6","7","2","1","9","5","3","4","8"],["1","9","8","3","4","2","5","6","7"],["8","5","9","7","6","1","4","2","3"],["4","2","6","8","5","3","7","9","1"],["7","1","3","9","2","4","8","5","6"],["9","6","1","5","3","7","2","8","4"],["2","8","7","4","1","9","6","3","5"],["3","4","5","2","8","6","1","7","9"]]
解释:输入的数独如上图所示,唯一有效的解决方案如下所示:
2
3
提示:
board.length == 9board[i].length == 9board[i][j]是一位数字或者'.'- 题目数据 保证 输入数独仅有一个解

package com.ep.LeetCode_Type.BackTracking;
/***
* @author dep
* @version 1.0
* @date 2023-04-22 9:27
*/
public class exercise15_37_解数独 {
public static void solveSudoku(char[][] board) {
backTracking(board);
}
public static Boolean backTracking(char[][] board) {
for (int row = 0; row < board.length; row++) {
for (int col = 0; col < board[0].length; col++) {
if (board[row][col] != '.') continue;
for (char i = '1'; i <= '9'; i++) {
if (isValid(row,col,i,board)) {
board[row][col] = i;
Boolean aBoolean = backTracking(board);
if (aBoolean) {
return true;
}
board[row][col] = '.';
}
}
return false; // 9个数都试完了,都不行,那么就返回false
}
}
return true;
}
/***
* 判断棋盘是否重复:1.同行是否重复,2.同列是否重复,3.九宫格是否重复
* @param row
* @param col
* @param val
* @param board
* @return
*/
public static boolean isValid (int row, int col, char val, char[][] board) {
// 同行是否重复
for (int i = 0; i < 9; i++) {
if (board[row][i] == val) {
return false;
}
}
// 同列是否重复
for (int i = 0; i < 9; i++) {
if (board[i][col] == val) {
return false;
}
}
// 9宫格是否重复
// 第一九宫格 (0,1,2)
// 第二九宫格 (3,4,5)
// 第三九宫格 (6,7,8)
int startRow = (row / 3) * 3;
int startCol = (col / 3) * 3;
for (int i = startRow; i < startRow + 3; i++) {
for (int j = startCol; j < startCol + 3; j++) {
if (board[i][j] == val) {
return false;
}
}
}
return true;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
# 贪心算法
# 贪心一般解题步骤
贪心算法一般分为如下四步:
- 将问题分解为若干个子问题
- 找出适合的贪心策略
- 求解每一个子问题的最优解
- 将局部最优解堆叠成全局最优解
# 455.分发饼干
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
示例 1:
输入: g = [1,2,3], s = [1,1]
输出: 1
解释:
你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。
虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。
所以你应该输出1。
2
3
4
5
6
示例 2:
输入: g = [1,2], s = [1,2,3]
输出: 2
解释:
你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。
你拥有的饼干数量和尺寸都足以让所有孩子满足。
所以你应该输出2.
2
3
4
5
6
提示:
1 <= g.length <= 3 * 1040 <= s.length <= 3 * 1041 <= g[i], s[j] <= 231 - 1
public static int findContentChildren(int[] g, int[] s) {
int i = 0, j = 0;
int count = 0;
Arrays.sort(g);
Arrays.sort(s);
while (i < g.length && j < s.length) {
if (s[j] >= g[i]) {
count ++;
i++;
j++;
} else {
j++;
}
}
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 376.摆动序列(要用动态规划再做)
如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为 **摆动序列 。**第一个差(如果存在的话)可能是正数或负数。仅有一个元素或者含两个不等元素的序列也视作摆动序列。
- 例如,
[1, 7, 4, 9, 2, 5]是一个 摆动序列 ,因为差值(6, -3, 5, -7, 3)是正负交替出现的。 - 相反,
[1, 4, 7, 2, 5]和[1, 7, 4, 5, 5]不是摆动序列,第一个序列是因为它的前两个差值都是正数,第二个序列是因为它的最后一个差值为零。
子序列 可以通过从原始序列中删除一些(也可以不删除)元素来获得,剩下的元素保持其原始顺序。
给你一个整数数组 nums ,返回 nums 中作为 摆动序列 的 最长子序列的长度 。
示例 1:
输入:nums = [1,7,4,9,2,5]
输出:6
解释:整个序列均为摆动序列,各元素之间的差值为 (6, -3, 5, -7, 3) 。
2
3
示例 2:
输入:nums = [1,17,5,10,13,15,10,5,16,8]
输出:7
解释:这个序列包含几个长度为 7 摆动序列。
其中一个是 [1, 17, 10, 13, 10, 16, 8] ,各元素之间的差值为 (16, -7, 3, -3, 6, -8) 。
2
3
4
示例 3:
输入:nums = [1,2,3,4,5,6,7,8,9]
输出:2
2
public int wiggleMaxLength(int[] nums) {
if (nums.length <= 1) return nums.length;
int curDiff = 0; // 当前一对差值
int preDiff = 0; // 前一对差值
int result = 1; // 记录峰值个数,序列默认序列最右边一个峰值
for (int i = 0; i < nums.length - 1; i++) {
curDiff = nums[i + 1] - nums[i];
// 出现峰值
if ((preDiff <= 0 && curDiff > 0) || (preDiff >= 0 && curDiff < 0)) {
result ++;
preDiff = curDiff;
}
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 53.最大子数组和(要用动态规划再做)
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组 是数组中的一个连续部分。
示例 1:
输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
输出:6
解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
2
3
示例 2:
输入:nums = [1]
输出:1
2
示例 3:
输入:nums = [5,4,-1,7,8]
输出:23
2
提示:
1 <= nums.length <= 105-104 <= nums[i] <= 104
**进阶:**如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的 分治法 求解。
局部最优:当前“连续和”为负数的时候立刻放弃,从下一个元素重新计算“连续和”,因为负数加上下一个元素 “连续和”只会越来越小。
全局最优:选取最大“连续和”
public static int maxSubArray(int[] nums) {
int result = Integer.MIN_VALUE;
int count = 0;
for (int i = 0; i < nums.length; i++) {
count += nums[i];
if (count > result) {
result = count;
}
if (count <= 0) count = 0;
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
# 122.买卖股票的最佳时机 II
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
示例 1:
输入:prices = [7,1,5,3,6,4]
输出:7
解释:在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6 - 3 = 3 。
总利润为 4 + 3 = 7 。
2
3
4
5
示例 2:
输入:prices = [1,2,3,4,5]
输出:4
解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
总利润为 4 。
2
3
4
示例 3:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 交易无法获得正利润,所以不参与交易可以获得最大利润,最大利润为 0 。
2
3
提示:
1 <= prices.length <= 3 * 1040 <= prices[i] <= 104
假如第0天买入,第3天卖出,那么利润为:prices[3] - prices[0]。
相当于(prices[3] - prices[2]) + (prices[2] - prices[1]) + (prices[1] - prices[0])。
此时就是把利润分解为每天为单位的维度,而不是从0天到第3天整体去考虑!
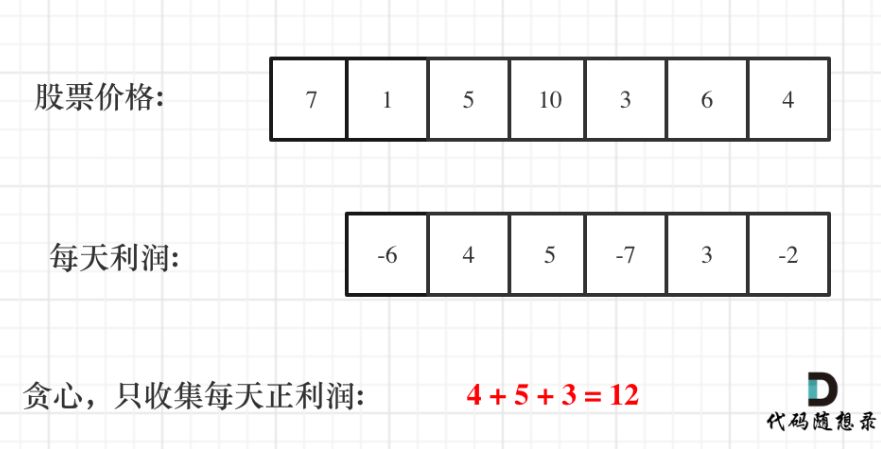
public static int maxProfit(int[] prices) {
int result = 0;
for (int i = 1; i < prices.length; i++) {
result += Math.max(prices[i] - prices[i-1], 0);
}
return result;
}
2
3
4
5
6
7
# 55.跳跃游戏
给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标。
示例 1:
输入:nums = [2,3,1,1,4]
输出:true
解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。
2
3
示例 2:
输入:nums = [3,2,1,0,4]
输出:false
解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。
2
3
提示:
1 <= nums.length <= 3 * 1040 <= nums[i] <= 105
贪心算法局部最优解:每次取最大跳跃步数(取最大覆盖范围),整体最优解:最后得到整体最大覆盖范围,看是否能到终点。
public static boolean canJump(int[] nums) {
int cover = 0;
if(nums.length == 1) return true; //起初就位于第一个元素
for (int i = 0; i <= cover; i++) {
cover = Math.max(i + nums[i], cover);
if (cover >= nums.length - 1) {
return true;
}
}
return false;
}
2
3
4
5
6
7
8
9
10
11
# 45.跳跃游戏 II
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。
每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i + j] 处:
0 <= j <= nums[i]i + j < n
返回到达 nums[n - 1] 的最小跳跃次数。生成的测试用例可以到达 nums[n - 1]。
示例 1:
输入: nums = [2,3,1,1,4]
输出: 2
解释: 跳到最后一个位置的最小跳跃数是 2。
从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。
2
3
4
示例 2:
输入: nums = [2,3,0,1,4]
输出: 2
2
public int jump(int[] nums) {
if (nums == null || nums.length == 0 || nums.length == 1) {
return 0;
}
// 记录当前覆盖的最大区域
int curDistance = 0;
// 最大的覆盖区域
int maxDistance = 0;
// 记录最大的跳跃次数
int ans = 0;
for (int i = 0; i < nums.length; i++) {
// 在可覆盖区域内更新最大的覆盖区域
maxDistance = Math.max(i + nums[i], maxDistance);
if (maxDistance >= nums.length - 1) {
ans++;
break;
}
if (i == curDistance) {
curDistance = maxDistance;
ans++;
}
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public int jump2(int[] nums) {
int result = 0;
// 当前覆盖的最远距离下标
int end = 0;
// 下一步覆盖的最远距离下标
int temp = 0;
for (int i = 0; i <= end && end < nums.length - 1; i++) {
temp = Math.max(temp, i + nums[i]);
if (i == end) {
end = temp;
result++;
}
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 1005.K 次取反后最大化的数组和
给你一个整数数组 nums 和一个整数 k ,按以下方法修改该数组:
- 选择某个下标
i并将nums[i]替换为-nums[i]。
重复这个过程恰好 k 次。可以多次选择同一个下标 i 。
以这种方式修改数组后,返回数组 可能的最大和 。
示例 1:
输入:nums = [4,2,3], k = 1
输出:5
解释:选择下标 1 ,nums 变为 [4,-2,3] 。
2
3
示例 2:
输入:nums = [3,-1,0,2], k = 3
输出:6
解释:选择下标 (1, 2, 2) ,nums 变为 [3,1,0,2] 。
2
3
示例 3:
输入:nums = [2,-3,-1,5,-4], k = 2
输出:13
解释:选择下标 (1, 4) ,nums 变为 [2,3,-1,5,4] 。
2
3
提示:
1 <= nums.length <= 104-100 <= nums[i] <= 1001 <= k <= 104第一步:将数组按照绝对值大小从大到小排序,注意要按照绝对值的大小
第二步:从前向后遍历,遇到负数将其变为正数,同时K--
第三步:如果K还大于0,那么反复转变数值最小的元素,将K用完
第四步:求和
public int largestSumAfterKNegations(int[] nums, int k) {
// 按绝对值从大到小排列
nums = IntStream
.of(nums)
.boxed()
.sorted((o1, o2) -> Math.abs(o2) - Math.abs(o1))
.mapToInt(Integer::intValue)
.toArray();
for (int i = 0; i < nums.length; i++) {
if (nums[i] < 0 && k > 0) {
k--;
nums[i] = -nums[i];
}
}
if (k % 2 == 1) nums[nums.length - 1] *= -1;
int result = 0;
for (int i : nums) {
result += i;
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 134.加油站
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
给定两个整数数组 gas 和 cost ,如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则 保证 它是 唯一 的。
示例 1:
输入: gas = [1,2,3,4,5], cost = [3,4,5,1,2]
输出: 3
解释:
从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
因此,3 可为起始索引。
2
3
4
5
6
7
8
9
10
示例 2:
输入: gas = [2,3,4], cost = [3,4,3]
输出: -1
解释:
你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。
我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油
开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油
开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油
你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。
因此,无论怎样,你都不可能绕环路行驶一周。
2
3
4
5
6
7
8
9
提示:
gas.length == ncost.length == n1 <= n <= 1050 <= gas[i], cost[i] <= 104
可以换一个思路,首先如果总油量减去总消耗大于等于零那么一定可以跑完一圈,说明 各个站点的加油站 剩油量rest[i]相加一定是大于等于零的。
每个加油站的剩余量rest[i]为gas[i] - cost[i]。
i从0开始累加rest[i],和记为curSum,一旦curSum小于零,说明[0, i]区间都不能作为起始位置,因为这个区间选择任何一个位置作为起点,到i这里都会断油,那么起始位置从i+1算起,再从0计算curSum。
public int canCompleteCircuit(int[] gas, int[] cost) {
int curSum = 0;
int totalSum = 0;
int index = 0;
for (int i = 0; i < gas.length; i++) {
curSum += gas[i] - cost[i];
totalSum += gas[i] - cost[i];
if (curSum < 0) {
index = (i + 1) % gas.length;
curSum = 0;
}
}
if (totalSum < 0) return -1;
return index;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 135.分发糖果
n 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。
你需要按照以下要求,给这些孩子分发糖果:
- 每个孩子至少分配到
1个糖果。 - 相邻两个孩子评分更高的孩子会获得更多的糖果。
请你给每个孩子分发糖果,计算并返回需要准备的 最少糖果数目 。
示例 1:
输入:ratings = [1,0,2]
输出:5
解释:你可以分别给第一个、第二个、第三个孩子分发 2、1、2 颗糖果。
2
3
示例 2:
输入:ratings = [1,2,2]
输出:4
解释:你可以分别给第一个、第二个、第三个孩子分发 1、2、1 颗糖果。
第三个孩子只得到 1 颗糖果,这满足题面中的两个条件。
2
3
4
提示:
n == ratings.length1 <= n <= 2 * 1040 <= ratings[i] <= 2 * 104
public static int candy(int[] ratings) {
int[] candy = new int[ratings.length];
for (int i = 0; i < candy.length; i++) {
candy[i] = 1;
}
// 处理右边比左边大的情况(从前往后遍历)
for (int i = 1; i < candy.length; i++) {
if (ratings[i] > ratings[i-1]) {
candy[i] = candy[i-1] + 1;
}
}
// 处理左边比右边大的情况(从后向前遍历)
for (int i = candy.length - 1; i >= 1 ; i--) {
// 左边比右边大,并且分发的糖果左边大于等于右边,才加
// if (ratings[i] < ratings[i - 1] && candy[i] > candy[i-1]) {
// candy[i - 1] = candy[i] + 1;
// }
// 也可以采用下面这种写法
if (ratings[i] < ratings[i-1]) {
candy[i - 1] = Math.max(candy[i-1], candy[i] + 1);
}
}
int sum = 0;
for (int i = 0; i < candy.length; i++) {
sum += candy[i];
}
return sum;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 860.柠檬水找零
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
给你一个整数数组 bills ,其中 bills[i] 是第 i 位顾客付的账。如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
示例 1:
输入:bills = [5,5,5,10,20]
输出:true
解释:
前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。
第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。
第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。
由于所有客户都得到了正确的找零,所以我们输出 true。
2
3
4
5
6
7
示例 2:
输入:bills = [5,5,10,10,20]
输出:false
解释:
前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。
对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。
对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。
由于不是每位顾客都得到了正确的找零,所以答案是 false。
2
3
4
5
6
7
提示:
1 <= bills.length <= 105bills[i]不是5就是10或是20情况一:账单是5,直接收下。
情况二:账单是10,消耗一个5,增加一个10
情况三:账单是20,优先消耗一个10和一个5,如果不够,再消耗三个5
public static boolean lemonadeChange(int[] bills) {
int five = 0, ten = 0, twenty = 0;
for (int i = 0; i < bills.length; i++) {
if (bills[i] == 5) {
five ++;
}else if (bills[i] == 10) {
ten++;
if (five > 0) {
five--;
} else {
return false;
}
} else if (bills[i] == 20) {
twenty++;
if (ten > 0 && five > 0) {
ten--;
five--;
} else if (five >= 3) {
five -= 3;
} else {
return false;
}
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 406.根据身高重建队列
假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] = [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。
请你重新构造并返回输入数组 people 所表示的队列。返回的队列应该格式化为数组 queue ,其中 queue[j] = [hj, kj] 是队列中第 j 个人的属性(queue[0] 是排在队列前面的人)。
示例 1:
输入:people = [[7,0],[4,4],[7,1],[5,0],[6,1],[5,2]]
输出:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
解释:
编号为 0 的人身高为 5 ,没有身高更高或者相同的人排在他前面。
编号为 1 的人身高为 7 ,没有身高更高或者相同的人排在他前面。
编号为 2 的人身高为 5 ,有 2 个身高更高或者相同的人排在他前面,即编号为 0 和 1 的人。
编号为 3 的人身高为 6 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
编号为 4 的人身高为 4 ,有 4 个身高更高或者相同的人排在他前面,即编号为 0、1、2、3 的人。
编号为 5 的人身高为 7 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
因此 [[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]] 是重新构造后的队列。
2
3
4
5
6
7
8
9
10
示例 2:
输入:people = [[6,0],[5,0],[4,0],[3,2],[2,2],[1,4]]
输出:[[4,0],[5,0],[2,2],[3,2],[1,4],[6,0]]
2
提示:
1 <= people.length <= 20000 <= hi <= 1060 <= ki < people.length- 题目数据确保队列可以被重建
题解:https://leetcode.cn/problems/queue-reconstruction-by-height/solutions/486493/xian-pai-xu-zai-cha-dui-dong-hua-yan-shi-suan-fa-g/
public static int[][] reconstructQueue(int[][] people) {
// people[i] = [hi, ki] 表示第i个人的身高为 hi ,前面正好有ki个身高大于或等于hi的人。
// 按身高降序排序,身高相同按照
Arrays.sort(people, (a,b) -> {
if (a[0] == b[0]) {
return a[1] - b[1];
} else {
return b[0] - a[0];
}
});
// LinkedList<int[]> queue = new LinkedList<>();
// for (int[] p: people) {
// queue.add(p[1], p);
// }
// return queue.toArray(new int[queue.size()][]);
LinkedList<int[]> queue = new LinkedList<>();
for (int i = 0; i < people.length; i++) {
if (queue.size() > people[i][1]) {
// 结果集中元素个数大于第i个人前面应有的人数时,将第i个人插入到结果集的第people[i]位置
queue.add(people[i][1], people[i]);
} else {
// 结果集中元素个数小于等于第i个人前面应有的人数时,将第i个人插入到结果集的第people[i]位置
queue.add(queue.size(), people[i]);
}
}
return queue.toArray(new int[queue.size()][]);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 452.用最少数量的箭引爆气球
有一些球形气球贴在一堵用 XY 平面表示的墙面上。墙面上的气球记录在整数数组 points ,其中points[i] = [xstart, xend] 表示水平直径在 xstart 和 xend之间的气球。你不知道气球的确切 y 坐标。
一支弓箭可以沿着 x 轴从不同点 完全垂直 地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 x``start,x``end, 且满足 xstart ≤ x ≤ x``end,则该气球会被 引爆 。可以射出的弓箭的数量 没有限制 。 弓箭一旦被射出之后,可以无限地前进。
给你一个数组 points ,返回引爆所有气球所必须射出的 最小 弓箭数 。
示例 1:
输入:points = [[10,16],[2,8],[1,6],[7,12]]
输出:2
解释:气球可以用2支箭来爆破:
-在x = 6处射出箭,击破气球[2,8]和[1,6]。
-在x = 11处发射箭,击破气球[10,16]和[7,12]。
2
3
4
5
示例 2:
输入:points = [[1,2],[3,4],[5,6],[7,8]]
输出:4
解释:每个气球需要射出一支箭,总共需要4支箭。
2
3
示例 3:
输入:points = [[1,2],[2,3],[3,4],[4,5]]
输出:2
解释:气球可以用2支箭来爆破:
- 在x = 2处发射箭,击破气球[1,2]和[2,3]。
- 在x = 4处射出箭,击破气球[3,4]和[4,5]。
2
3
4
5
提示:
1 <= points.length <= 105points[i].length == 2-231 <= xstart < xend <= 231 - 1
public static int findMinArrowShots(int[][] points) {
// [[-2147483646,-2147483645],[2147483646,2147483647]]
// 用差值比较会导致这个测试用例过不去
Arrays.sort(points, (a, b) -> {
// 用Integer.compare,不会溢出
return Integer.compare(a[0],b[0]);
});
int count = 1;
for (int i = 1; i < points.length; i++) {
if (points[i][0] > points[i-1][1]) { // 这两个气球不挨着
count++;
} else { // 更新重叠气球的最小右边界
// 缩小区间 例如 [1,6],[2,8] 变为 [1,6]
points[i][1] = Math.min(points[i-1][1],points[i][1]);
}
}
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 435.无重叠区间
给定一个区间的集合 intervals ,其中 intervals[i] = [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。
示例 1:
输入: intervals = [[1,2],[2,3],[3,4],[1,3]]
输出: 1
解释: 移除 [1,3] 后,剩下的区间没有重叠。
2
3
示例 2:
输入: intervals = [ [1,2], [1,2], [1,2] ]
输出: 2
解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
2
3
示例 3:
输入: intervals = [ [1,2], [2,3] ]
输出: 0
解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
2
3
提示:
1 <= intervals.length <= 105intervals[i].length == 2-5 * 104 <= starti < endi <= 5 * 104
public int eraseOverlapIntervals(int[][] intervals) {
// 按照左区间排序
Arrays.sort(intervals, (a,b) -> {
return Integer.compare(a[0],b[0]);
});
int count = 0;
for (int i = 1; i < intervals.length; i++) {
if (intervals[i-1][1] > intervals[i][0]){ // 重叠
intervals[i][1] = Math.min(intervals[i-1][1], intervals[i][1]);
count++;
}
}
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 763.划分字母区间
给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。
注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s 。
返回一个表示每个字符串片段的长度的列表。
示例 1:
输入:s = "ababcbacadefegdehijhklij"
输出:[9,7,8]
解释:
划分结果为 "ababcbaca"、"defegde"、"hijhklij" 。
每个字母最多出现在一个片段中。
像 "ababcbacadefegde", "hijhklij" 这样的划分是错误的,因为划分的片段数较少。
2
3
4
5
6
示例 2:
输入:s = "eccbbbbdec"
输出:[10]
2
提示:
1 <= s.length <= 500s仅由小写英文字母组成
public static List<Integer> partitionLabels(String s) {
LinkedList<Integer> result = new LinkedList<>();
int hash[] = new int[27];
// 记录每个字母出现的最远位置
for (int i = 0; i < s.length(); i++) {
hash[s.charAt(i) - 'a'] = i;
}
int left = 0, right = 0;
for (int i = 0; i < s.length(); i++) {
right = Math.max(right, hash[s.charAt(i) - 'a']);
if (i == right) {
result.add(right - left + 1);
left = i + 1;
}
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 56.合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
2
3
示例 2:
输入:intervals = [[1,4],[4,5]]
输出:[[1,5]]
解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
2
3
提示:
1 <= intervals.length <= 104intervals[i].length == 20 <= starti <= endi <= 104
public static int[][] merge(int[][] intervals) {
// 按左区间排序
Arrays.sort(intervals, (a, b) -> {
return Integer.compare(a[0], b[0]);
});
List<int[]> result = new LinkedList<>();
int start = intervals[0][0];
int right = intervals[0][1];
for (int i = 1; i < intervals.length; i++) {
if (intervals[i][0] <= right) { // 左边界小于等于右边界,说明可以合并
right = Math.max( right, intervals[i][1]);
} else {
result.add(new int[]{start, right});
start = intervals[i][0];
right = intervals[i][1];
}
}
result.add(new int[]{start, right});
return result.toArray(new int[result.size()][]);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 738.单调递增的数字
当且仅当每个相邻位数上的数字 x 和 y 满足 x <= y 时,我们称这个整数是单调递增的。
给定一个整数 n ,返回 小于或等于 n 的最大数字,且数字呈 单调递增 。
示例 1:
输入: n = 10
输出: 9
2
示例 2:
输入: n = 1234
输出: 1234
2
示例 3:
输入: n = 332
输出: 299
2
提示:
0 <= n <= 109
// 暴力破解,会超时
// 判断数字的每一位是否递增
public static boolean checkNumberIncrease (int num) {
int max = 10; // 记录前一位数字(从后往前)
while (num != 0) {
int t = num % 10;
if (max >= t) max = t;
else return false;
num /= 10;
}
return true;
}
public static int monotoneIncreasingDigits(int n) {
for (int i = n; i >= 0; i--) {
if (checkNumberIncrease(i)) {
return i;
}
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
上面写的暴力会超时
// 贪心算法
public static int monotoneIncreasingDigits2(int n) {
// 将数字转换为字符串
String s = String.valueOf(n);
char[] num = s.toCharArray();
int flag = num.length; // flag用来标记赋值9从哪里开始
for (int i = num.length - 1; i >= 1; i--) {
if (num[i-1] > num[i]){ // 前一位数字比后一位数字大
flag = i;
num[i-1] = (char) (num[i-1] - 1);
}
}
for (int i = flag; i < num.length; i++) {
num[i] = '9';
}
return Integer.parseInt(String.valueOf(num));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 968.监控二叉树
给定一个二叉树,我们在树的节点上安装摄像头。
节点上的每个摄影头都可以监视其父对象、自身及其直接子对象。
计算监控树的所有节点所需的最小摄像头数量。
示例 1:
输入:[0,0,null,0,0]
输出:1
解释:如图所示,一台摄像头足以监控所有节点。
2
3
示例 2:
输入:[0,0,null,0,null,0,null,null,0]
输出:2
解释:需要至少两个摄像头来监视树的所有节点。 上图显示了摄像头放置的有效位置一。
**提示:**
2
3
4
- 给定树的节点数的范围是
[1, 1000]。 - 每个节点的值都是 0。
// 0 表示无覆盖
// 1 表示有摄像头
// 2 表示有覆盖
static int result;
public int dfs(TreeNode cur) {
// 空节点或者叶子结点(有覆盖)
if (cur == null) return 2;
int left = dfs(cur.left);
int right = dfs(cur.right);
// 情况1: 左右结点都有覆盖
if (left == 2 && right == 2) return 0;
// 情况2
// left == 0 && right == 0 左右节点无覆盖
// left == 1 && right == 0 左节点有摄像头,右节点无覆盖
// left == 0 && right == 1 左节点有无覆盖,右节点摄像头
// left == 0 && right == 2 左节点无覆盖,右节点覆盖
// left == 2 && right == 0 左节点覆盖,右节点无覆盖
if (left == 0 || right == 0) {
result++;
return 1;
}
// 情况3
// left == 1 && right == 2 左节点有摄像头,右节点有覆盖
// left == 2 && right == 1 左节点有覆盖,右节点有摄像头
// left == 1 && right == 1 左右节点都有摄像头
// 其他情况前段代码均已覆盖
if (left == 1 || right == 1) return 2;
// 以上代码我没有使用else,主要是为了把各个分支条件展现出来,这样代码有助于读者理解
// 这个 return -1 逻辑不会走到这里。
return -1;
}
public int minCameraCover(TreeNode root) {
result = 0;
if (dfs(root) == 0) { // root无覆盖
result++;
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# 动态规划
动态规划中每一个状态一定是由上一个状态推导出来的
解题步骤:
- 确定dp数组(dp table)以及下标的含义
- 确定递推公式
- dp数组如何初始化
- 确定遍历顺序
- 举例推导dp数组
# 509.斐波那契数
斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0,F(1) = 1
F(n) = F(n - 1) + F(n - 2),其中 n > 1
2
给定 n ,请计算 F(n) 。
示例 1:
输入:n = 2
输出:1
解释:F(2) = F(1) + F(0) = 1 + 0 = 1
2
3
示例 2:
输入:n = 3
输出:2
解释:F(3) = F(2) + F(1) = 1 + 1 = 2
2
3
示例 3:
输入:n = 4
输出:3
解释:F(4) = F(3) + F(2) = 2 + 1 = 3
2
3
public int fib(int n) {
if (n <= 1) {
return n;
}
// 1. 确定dp数组,以及下标的含义
// 2.确定递推公式 dp[i] = dp[i-1] + dp[i-2]
int[] dp = new int[n+1];
// 3.初始化数组
dp[0] = 0; dp[1] = 1;
// 4.确定顺序
for (int i = 2; i <= n; i++) {
dp[i] = dp[i-1] + dp[i-2];
}
return dp[n];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 70.爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
示例 1:
输入:n = 2
输出:2
解释:有两种方法可以爬到楼顶。
1. 1 阶 + 1 阶
2. 2 阶
2
3
4
5
示例 2:
输入:n = 3
输出:3
解释:有三种方法可以爬到楼顶。
1. 1 阶 + 1 阶 + 1 阶
2. 1 阶 + 2 阶
3. 2 阶 + 1 阶
2
3
4
5
6
提示:
1 <= n <= 45
public int climbStairs(int n) {
if(n == 1) return n;
int[] dp = new int[n + 1];
dp[0] = 1;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
// 最后一步一个台阶或者两个台阶
dp[i] = dp[i-1] + dp[i-2];
}
return dp[n];
}
2
3
4
5
6
7
8
9
10
11
// 简化空间复杂度
public int climbStairs2(int n) {
if (n == 1) return n;
int[] dp = new int[3];
dp[0] = 1;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
dp[2] = dp[0] + dp[1];
dp[0] = dp[1];
dp[1] = dp[2];
}
return dp[2];
}
2
3
4
5
6
7
8
9
10
11
12
13
完全背包
public static int climbStairs(int n) {
int[] dp = new int[n + 1];
dp[0] = 1;
for (int i = 1; i <= n ; i++) { // 背包
for (int j = 1; j <= 2; j++) { // 物品
if (i >= j) {
dp[i] += dp[i-j];
}
}
}
return dp[n];
}
2
3
4
5
6
7
8
9
10
11
12
# 746.使用最小花费爬楼梯
给你一个整数数组 cost ,其中 cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。
你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。
请你计算并返回达到楼梯顶部的最低花费。
示例 1:
输入:cost = [10,15,20]
输出:15
解释:你将从下标为 1 的台阶开始。
- 支付 15 ,向上爬两个台阶,到达楼梯顶部。
总花费为 15 。
2
3
4
5
示例 2:
输入:cost = [1,100,1,1,1,100,1,1,100,1]
输出:6
解释:你将从下标为 0 的台阶开始。
- 支付 1 ,向上爬两个台阶,到达下标为 2 的台阶。
- 支付 1 ,向上爬两个台阶,到达下标为 4 的台阶。
- 支付 1 ,向上爬两个台阶,到达下标为 6 的台阶。
- 支付 1 ,向上爬一个台阶,到达下标为 7 的台阶。
- 支付 1 ,向上爬两个台阶,到达下标为 9 的台阶。
- 支付 1 ,向上爬一个台阶,到达楼梯顶部。
总花费为 6 。
2
3
4
5
6
7
8
9
10
public int minCostClimbingStairs(int[] cost) {
// 1. dp数组的含义 dp[i],到达第i个位置的最小花费
// 2. 递推公式 dp[i] = min (dp[i-1] + cost[i-1], dp[i-1] + cost[i-2])
// 3. 数组初始化 dp[0] = 0 dp[1] = 0
// 4. 遍历顺序
int n = cost.length;
int[] dp = new int[n + 1];
dp[0] = 0; dp[1] = 0;
for (int i = 2; i <= n; i++) {
dp[i] = Math.min(dp[i-1] + cost[i-1], dp[i-2] + cost[i-2]);
}
return dp[n];
}
2
3
4
5
6
7
8
9
10
11
12
13
// 简化空间复杂度
public int minCostClimbingStairs2(int[] cost) {
int n = cost.length;
int prev = 0;
int curr = 0;
for (int i = 2; i <= n; i++) {
int next = Math.min(curr + cost[i-1] , prev + cost[i-2]);
prev = curr;
curr = next;
}
return curr;
}
2
3
4
5
6
7
8
9
10
11
12
# 62.不同路径
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1:
输入:m = 3, n = 7
输出:28
2
示例 2:
输入:m = 3, n = 2
输出:3
解释:
从左上角开始,总共有 3 条路径可以到达右下角。
1. 向右 -> 向下 -> 向下
2. 向下 -> 向下 -> 向右
3. 向下 -> 向右 -> 向下
2
3
4
5
6
7
示例 3:
输入:m = 7, n = 3
输出:28
2
示例 4:
输入:m = 3, n = 3
输出:6
2
提示:
1 <= m, n <= 100- 题目数据保证答案小于等于
2 * 109
// 转化为求二叉树叶子结点的个数 (会超时)
public static int uniquePaths(int m, int n) {
return dfs(1,1,m,n);
}
public static int dfs(int i, int j, int m, int n) {
if (i > m || j > n) return 0;
if (i == m && j == n) return 1; // 找到了一种方法,相当于找到了叶子结点
return dfs(i + 1, j, m, n) + dfs(i, j + 1, m, n);
}
2
3
4
5
6
7
8
9
10
public static int uniquePaths2(int m, int n) {
// 1. 确定dp数组的含义 dp[i][j]表示从0,0起点出发到终点的路径
// 2. 递推公式 dp[i][j] = dp[i-1][j] + dp[i][j-1];
// 从dp[i-1][j]向右走一步,dp[i][j-1]向下走一步都可以到达dp[i][j]
// 3. 数组初始化dp[i][0] = 1, dp[0][j] = 1
// 4. 遍历顺序
int[][] dp = new int[m][n];
for (int i = 0; i < m; i++) {
dp[i][0] = 1;
}
for (int i = 0; i < n; i++) {
dp[0][i] = 1;
}
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
return dp[m-1][n-1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 63.不同路径 II
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
网格中的障碍物和空位置分别用 1 和 0 来表示。
示例 1:

输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]
输出:2
解释:3x3 网格的正中间有一个障碍物。
从左上角到右下角一共有 2 条不同的路径:
1. 向右 -> 向右 -> 向下 -> 向下
2. 向下 -> 向下 -> 向右 -> 向右
2
3
4
5
6
示例 2:

输入:obstacleGrid = [[0,1],[0,0]]
输出:1
2
提示:
m == obstacleGrid.lengthn == obstacleGrid[i].length1 <= m, n <= 100obstacleGrid[i][j]为0或1
public static int uniquePathsWithObstacles(int[][] obstacleGrid) {
// 1. dp[i][j] 表示从起点到终点路径数量
// 2. 递推公式 dp[i][j] = dp[i-1][j] + di[i][j-1];
// dp[i-1][j]向下走一步到达dp[i][j], dp[i][j-1] 向右走一步到达dp[i][j]
// 3. dp数组初始化 dp[i][0] = 1; dp[0][j] = 1;
// 4. 顺序遍历
int m = obstacleGrid.length, n = obstacleGrid[0].length;
int[][] dp = new int[m][n];
for (int i = 0; i < m && obstacleGrid[i][0] == 0; i++) {
dp[i][0] = 1;
}
for (int i = 0; i < n && obstacleGrid[0][i] == 0; i++) {
dp[0][i] = 1;
}
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (obstacleGrid[i][j] == 0) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
}
return dp[m-1][n-1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 343.整数拆分
给定一个正整数 n ,将其拆分为 k 个 正整数 的和( k >= 2 ),并使这些整数的乘积最大化。
返回 你可以获得的最大乘积 。
示例 1:
输入: n = 2
输出: 1
解释: 2 = 1 + 1, 1 × 1 = 1。
2
3
示例 2:
输入: n = 10
输出: 36
解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。
2
3
提示:
2 <= n <= 58
j * (i - j) 是单纯的把整数拆分为两个数相乘,而j * dp[i - j]是拆分成两个以及两个以上的个数相乘。如果定义dp[i - j] * dp[j] 也是默认将一个数强制拆成4份以及4份以上了。
public int integerBreak(int n) {
if (n == 2) return 1;
if (n == 3) return 2;
if (n == 4) return 4;
int result = 1;
while (n > 4) {
result *= 3;
n -= 3;
}
result *= n;
return result;
}
2
3
4
5
6
7
8
9
10
11
12
动态规划
public int integerBreak2(int n) {
int[] dp = new int[n+1];
dp[2] = 1;
for (int i = 3; i <= n; i++) {
for (int j = 1; j <= i / 2; j++) {
dp[i] = Math.max(dp[i], Math.max((i - j) * j, dp[i-j] * j));
}
}
return dp[n];
}
2
3
4
5
6
7
8
9
10
# 96.不同的二叉搜索树
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
示例 1:

输入:n = 3
输出:5
2
示例 2:
输入:n = 1
输出:1
2
提示:
1 <= n <= 19
dp[i] += dp[j - 1] * dp[i - j]; ,j-1 为j为头结点左子树节点数量,i-j 为以j为头结点右子树节点数量
public static int numTrees(int n) {
int[] dp = new int[n+1];
dp[0] = 1;
for (int i = 1; i <= n; i++) {
// dp[i] 为 1...i为头结点的二叉搜索树的个数的和
for (int j = 1; j <= i; j++) {
//代表以j为头结点 dp[j-1] * dp[i-j];
dp[i] += dp[j-1] * dp[i-j];
}
}
return dp[n];
}
2
3
4
5
6
7
8
9
10
11
12
# 01背包问题
dp[i][j] 表示从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大是多少。
- 不放物品i:由
dp[i-1][j]推出,即背包容量为j,里面不放物品i的最大价值,此时dp[i][j]就是dp[i-1][j]。(其实就是当物品i的重量大于背包j的重量时,物品i无法放进背包中,所以被背包内的价值依然和前面相同。) - 放物品i:由
dp[i-1][j-weight[i]]推出,dp[i-1][j- weight[i]]为背包容量为j - weight[i]的时候不放物品i的最大价值,那么dp[i-1][j-weight[i]]+value[i](物品i的价值),就是背包放物品i得到的最大价值
package com.ep.LeetCode_Type.DynamicProgramming;
/***
* @author dep
* @version 1.0
* @date 2023-05-16 9:46
*/
public class exercise8_01背包问题 {
/**
* @param weight 物品的重量
* @param value 物品的价值
* @param bagSize 物品大小
*/
public static void testWeightBagProblem(int[] weight, int[] value, int bagSize) {
int m = weight.length;
int n = bagSize + 1;
int[][] dp = new int[m][n]; // dp[i][j], 0-i个物品,j背包的重量
// 数组初始化
// for (int i = 0; i < m; i++) { // 背包的容量为0
// dp[i][0] = 0;
// }
// for (int j = 1; j < n; j++) { // 放索引为0的物品
// if (weight[0] <= j) {
// dp[0][j] = value[0];
// } else {
// dp[0][j] = 0;
// }
// }
for (int j = weight[0]; j <= bagSize; j++) {
dp[0][j] = value[0];
}
// 两种情况: 1. 不选择第i个物品 dp[i-1][j] 2. 选择第i个物品 dp[i-1][j - weight[i]] + value[i]
for (int i = 1; i < m; i++) { // 物品
for (int j = 1; j < n; j++) { // 背包重量
if (j < weight[i]) {
// 此时物品重量已经超越了背包的最大承受重量
dp[i][j] = dp[i-1][j];
} else {
dp[i][j] = Math.max(dp[i-1][j], dp[i-1][j-weight[i]] + value[i]);
}
}
}
// 打印dp数组
for (int i = 0; i < m; i++) {
for (int j = 0; j <= bagSize; j++) {
System.out.print(dp[i][j] + "\t");
}
System.out.println("\n");
}
}
public static void main(String[] args) {
// int[] weight = {1,3,4};
// int[] value = {15,20,30};
// int bagSize = 4;
int[] weight = {1,2,3,4};
int[] value = {2,4,4,5};
int bagSize = 5;
testWeightBagProblem(weight,value,bagSize);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
一维数组
public static void testWeightBagProblem2(int[] weight, int[] value, int bagSize) {
int m = weight.length; // 物品的个数
int n = bagSize; // 背包的容量
int[] dp = new int[n + 1]; // dp[j] 表示背包容量为j时的最大价值
dp[0] = 0;
for (int i = 0; i < m; i++) { // 物品
for (int j = bagSize; j >= weight[i]; j--) { // 背包
dp[j] = Math.max(dp[j], dp[j - weight[i]] + value[i]);
}
}
System.out.println(Arrays.toString(dp));
}
2
3
4
5
6
7
8
9
10
11
12
13
# 416.分割等和子集
给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
示例 1:
输入:nums = [1,5,11,5]
输出:true
解释:数组可以分割成 [1, 5, 5] 和 [11] 。
2
3
示例 2:
输入:nums = [1,2,3,5]
输出:false
解释:数组不能分割成两个元素和相等的子集。
2
3
提示:
1 <= nums.length <= 2001 <= nums[i] <= 100
public static boolean canPartition(int[] nums) {
int sum = 0;
for (int i = 0; i < nums.length; i++) {
sum += nums[i];
}
if (sum % 2 == 1) return false;
int target = sum / 2;
// 转化为一个01背包问题
// 相当于背包的容量为target
int[] dp = new int[target + 1];
for (int i = 0; i < nums.length; i++) {
for (int j = target; j >= nums[i] ; j--) {
dp[j] = Math.max(dp[j], dp[j - nums[i]] + nums[i]);
}
}
if (dp[target] == target) return true;
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 1049.最后一块石头的重量 II
有一堆石头,用整数数组 stones 表示。其中 stones[i] 表示第 i 块石头的重量。
每一回合,从中选出任意两块石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下:
- 如果
x == y,那么两块石头都会被完全粉碎; - 如果
x != y,那么重量为x的石头将会完全粉碎,而重量为y的石头新重量为y-x。
最后,最多只会剩下一块 石头。返回此石头 最小的可能重量 。如果没有石头剩下,就返回 0。
示例 1:
输入:stones = [2,7,4,1,8,1]
输出:1
解释:
组合 2 和 4,得到 2,所以数组转化为 [2,7,1,8,1],
组合 7 和 8,得到 1,所以数组转化为 [2,1,1,1],
组合 2 和 1,得到 1,所以数组转化为 [1,1,1],
组合 1 和 1,得到 0,所以数组转化为 [1],这就是最优值。
2
3
4
5
6
7
示例 2:
输入:stones = [31,26,33,21,40]
输出:5
2
提示:
1 <= stones.length <= 301 <= stones[i] <= 100
分成两堆石头,一堆石头的总重量是dp[target],另一堆就是sum - dp[target]。
public static int lastStoneWeightII(int[] stones) {
int[] dp = new int[1501];
int sum = 0;
for (int i = 0; i < stones.length; i++) {
sum += stones[i];
}
int target = sum / 2;
for (int i = 0; i < stones.length; i++) {
for (int j = target; j >= stones[i] ; j--) {
dp[j] = Math.max(dp[j], dp[j - stones[i]] + stones[i]);
}
}
return sum - dp[target] - dp[trget];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 494.目标和
给你一个整数数组 nums 和一个整数 target 。
向数组中的每个整数前添加 '+' 或 '-' ,然后串联起所有整数,可以构造一个 表达式 :
- 例如,
nums = [2, 1],可以在2之前添加'+',在1之前添加'-',然后串联起来得到表达式"+2-1"。
返回可以通过上述方法构造的、运算结果等于 target 的不同 表达式 的数目。
示例 1:
输入:nums = [1,1,1,1,1], target = 3
输出:5
解释:一共有 5 种方法让最终目标和为 3 。
-1 + 1 + 1 + 1 + 1 = 3
+1 - 1 + 1 + 1 + 1 = 3
+1 + 1 - 1 + 1 + 1 = 3
+1 + 1 + 1 - 1 + 1 = 3
+1 + 1 + 1 + 1 - 1 = 3
2
3
4
5
6
7
8
示例 2:
输入:nums = [1], target = 1
输出:1
2
提示:
1 <= nums.length <= 200 <= nums[i] <= 10000 <= sum(nums[i]) <= 1000-1000 <= target <= 1000
public int findTargetSumWays(int[] nums, int target) {
// 加法集合用left来表示,减法结合用right来表示, 则1. left + right = sum
// 2. left - right = target 1和2结合left = (sum + target) / 2
int sum = 0;
for (int i = 0; i < nums.length; i++) {
sum += nums[i];
}
if (Math.abs(target) > sum) return 0;
if ((sum + target) % 2 == 1) return 0;
int bagSize = (sum + target) / 2;
int[] dp = new int[bagSize + 1];
dp[0] = 1;
// 已经有一个1(nums[i]) 的话,有 dp[4]种方法 凑成 容量为5的背包。
// 已经有一个2(nums[i]) 的话,有 dp[3]种方法 凑成 容量为5的背包。
// 已经有一个3(nums[i]) 的话,有 dp[2]中方法 凑成 容量为5的背包
// 已经有一个4(nums[i]) 的话,有 dp[1]中方法 凑成 容量为5的背包
// 已经有一个5 (nums[i])的话,有 dp[0]中方法 凑成 容量为5的背包
for (int i = 0; i < nums.length; i++) { // 物品
for (int j = bagSize; j >= nums[i]; j--) {
dp[j] += dp[j - nums[i]];
}
}
return dp[bagSize];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 518.零钱兑换 II
给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。
请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。
假设每一种面额的硬币有无限个。
题目数据保证结果符合 32 位带符号整数。
示例 1:
输入:amount = 5, coins = [1, 2, 5]
输出:4
解释:有四种方式可以凑成总金额:
5=5
5=2+2+1
5=2+1+1+1
5=1+1+1+1+1
2
3
4
5
6
7
示例 2:
输入:amount = 3, coins = [2]
输出:0
解释:只用面额 2 的硬币不能凑成总金额 3 。
2
3
示例 3:
输入:amount = 10, coins = [10]
输出:1
2
提示:
1 <= coins.length <= 3001 <= coins[i] <= 5000coins中的所有值 互不相同0 <= amount <= 5000
public static int change(int amount, int[] coins) {
int bagSize = amount;
int[] dp = new int[bagSize + 1];
dp[0] = 1;
// 完全背包问题中,先物品再背包是组合, 先背包再物品是排列
for (int i = 0; i < coins.length; i++) { // 物品
for (int j = coins[i]; j <= bagSize; j++) { // 背包
dp[j] += dp[j-coins[i]];
}
}
return dp[bagSize];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 377.组合总和 Ⅳ
给你一个由 不同 整数组成的数组 nums ,和一个目标整数 target 。请你从 nums 中找出并返回总和为 target 的元素组合的个数。
题目数据保证答案符合 32 位整数范围。
示例 1:
输入:nums = [1,2,3], target = 4
输出:7
解释:
所有可能的组合为:
(1, 1, 1, 1)
(1, 1, 2)
(1, 2, 1)
(1, 3)
(2, 1, 1)
(2, 2)
(3, 1)
请注意,顺序不同的序列被视作不同的组合。
2
3
4
5
6
7
8
9
10
11
12
示例 2:
输入:nums = [9], target = 3
输出:0
2
提示:
1 <= nums.length <= 2001 <= nums[i] <= 1000nums中的所有元素 互不相同1 <= target <= 1000
public static int combinationSum4(int[] nums, int target) {
int[] dp = new int[target + 1];
dp[0] = 1;
for (int i = 0; i <= target; i++) { // 背包
for (int j = 0; j < nums.length; j++) { // 物品
if (i >= nums[j]) {
dp[i] += dp[i - nums[j]];
}
}
}
return dp[target];
}
2
3
4
5
6
7
8
9
10
11
12
回溯(会超时)
static int Count = 0;
public static int combinationSum42(int[] nums, int target) {
backTracking(nums, target, 0);
return Count;
}
public static void backTracking(int[] nums, int target, int sum) {
if (sum == target) {
Count++;
return;
}
for (int i = 0; i < nums.length; i++) {
if (sum + nums[i] <= target) {
backTracking(nums, target, sum + nums[i]);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 322.零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins = [1, 2, 5], amount = 11
输出:3
解释:11 = 5 + 5 + 1
2
3
示例 2:
输入:coins = [2], amount = 3
输出:-1
2
示例 3:
输入:coins = [1], amount = 0
输出:0
2
提示:
1 <= coins.length <= 121 <= coins[i] <= 231 - 10 <= amount <= 104
public static int coinChange(int[] coins, int amount) {
int[] dp = new int[amount + 1];
dp[0] = 0;
for (int i = 1; i <= amount; i++) {
dp[i] = Integer.MAX_VALUE;
}
for (int i = 0; i < coins.length; i++) { // 遍历物品
for (int j = coins[i]; j <= amount; j++) { // 遍历背包
if (dp[j - coins[i]] != Integer.MAX_VALUE) {
dp[j] = Math.min(dp[j - coins[i]] + 1, dp[j]);
}
}
}
if (dp[amount] == Integer.MAX_VALUE) return -1;
return dp[amount];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 279.完全平方数
给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
示例 1:
输入:n = 12
输出:3
解释:12 = 4 + 4 + 4
2
3
示例 2:
输入:n = 13
输出:2
解释:13 = 4 + 9
2
3
提示:
1 <= n <= 104
public static int numSquares(int n) {
int q = (int) Math.sqrt(n);
int[] dp = new int[n + 1];
dp[0] = 0;
for (int i = 1; i <= n; i++) {
dp[i] = Integer.MAX_VALUE;
}
for (int i = 1; i <= q; i++) { // 遍历物品
for (int j = i * i; j <= n ; j++) {
if (j >= i * i) {
dp[j] = Math.min(dp[j - i * i] + 1, dp[j]);
}
}
}
return dp[n];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 198.打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
示例 1:
输入:[1,2,3,1]
输出:4
解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
2
3
4
示例 2:
输入:[2,7,9,3,1]
输出:12
解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
偷窃到的最高金额 = 2 + 9 + 1 = 12 。
2
3
4
提示:
1 <= nums.length <= 1000 <= nums[i] <= 400
public static int rob(int[] nums) {
int n = nums.length;
if (n == 0) return 0;
if (n == 1) return nums[0];
int[] dp = new int[n];
dp[0] = nums[0];
dp[1] = Math.max(nums[0], nums[1]);
// 01 背包问题
for (int i = 2; i < n ; i++) {
dp[i] = Math.max(dp[i - 2] + nums[i], dp[i - 1]);
System.out.println(dp[i]);
}
return dp[n - 1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 213.打家劫舍 II
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。
给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,今晚能够偷窃到的最高金额。
示例 1:
输入:nums = [2,3,2]
输出:3
解释:你不能先偷窃 1 号房屋(金额 = 2),然后偷窃 3 号房屋(金额 = 2), 因为他们是相邻的。
2
3
示例 2:
输入:nums = [1,2,3,1]
输出:4
解释:你可以先偷窃 1 号房屋(金额 = 1),然后偷窃 3 号房屋(金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
2
3
4
示例 3:
输入:nums = [1,2,3]
输出:3
2
提示:
1 <= nums.length <= 1000 <= nums[i] <= 1000
public static int rob(int[] nums) {
if (nums.length == 0) return 0;
if (nums.length == 1) return nums[0];
return Math.max(findMax(nums, 0, nums.length - 2), findMax(nums, 1 , nums.length - 1));
}
public static int findMax(int[] nums, int start, int end) {
if (start == end) return nums[start];
int[] dp = new int[end + 1];
dp[start] = nums[start];
for (int i = start + 2; i <= end; i++) {
dp[i] = Math.max(dp[i -2] + nums[i], dp[i - 1]);
}
return dp[end];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 337.打家劫舍 III
小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。
除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果 两个直接相连的房子在同一天晚上被打劫 ,房屋将自动报警。
给定二叉树的 root 。返回 在不触动警报的情况下 ,小偷能够盗取的最高金额 。
示例 1:

输入: root = [3,2,3,null,3,null,1]
输出: 7
解释: 小偷一晚能够盗取的最高金额 3 + 3 + 1 = 7
2
3
示例 2:
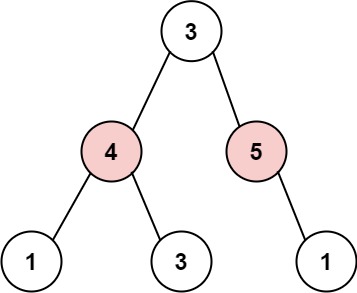
输入: root = [3,4,5,1,3,null,1]
输出: 9
解释: 小偷一晚能够盗取的最高金额 4 + 5 = 9
2
3
提示:
- 树的节点数在
[1, 104]范围内 0 <= Node.val <= 104
public int rob(TreeNode root) {
int[] res = robAction(root);
return Math.max(res[0], res[1]);
}
public int[] robAction(TreeNode root) {
// 下标为0记录不偷该节点所得到的的最大金钱,下标为1记录偷该节点所得到的的最大金钱。
int[] res = new int[2];
if (root == null) {
return res;
}
int[] left = robAction(root.left);
int[] right = robAction(root.right);
// 偷左右孩子 (左孩子偷和不偷的最大值 + 右孩子偷和不偷的最大值)
res[0] = Math.max(left[0], left[1]) + Math.max(right[0], right[1]);
// 偷根节点,左右孩子都不偷
res[1] = root.val + left[0] + right[0];
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 121.买卖股票的最佳时机
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
2
3
4
示例 2:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
2
3
提示:
1 <= prices.length <= 1050 <= prices[i] <= 104
public int maxProfit(int[] prices) {
int n = prices.length;
int[][] dp = new int[n][2];
dp[0][0] = -prices[0];
dp[0][1] = 0;
// dp[i][0]代表第i天持有股票的最大收益
// dp[i][1]代表第i天不持有股票的最大收益
for (int i = 1; i < prices.length; i++) {
// 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:dp[i - 1][0]
// 第i天买入股票,所得现金就是买入今天的股票后所得现金即:-prices[i]
dp[i][0] = Math.max(dp[i-1][0], -prices[i]);
// 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:dp[i - 1][1]
// 第i天卖出股票,所得现金就是按照今天股票价格卖出后所得现金即:prices[i] + dp[i - 1][0]
dp[i][1] = Math.max(dp[i-1][0] + prices[i], dp[i-1][1]);
}
return dp[n - 1][1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 122.买卖股票的最佳时机 II
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
示例 1:
输入:prices = [7,1,5,3,6,4]
输出:7
解释:在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6 - 3 = 3 。
总利润为 4 + 3 = 7 。
2
3
4
5
示例 2:
输入:prices = [1,2,3,4,5]
输出:4
解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
总利润为 4 。
2
3
4
示例 3:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 交易无法获得正利润,所以不参与交易可以获得最大利润,最大利润为 0 。
2
3
提示:
1 <= prices.length <= 3 * 1040 <= prices[i] <= 104
public static int maxProfit(int[] prices) {
int n = prices.length;
int[][] dp = new int[n][2];
dp[0][0] = -prices[0];
dp[0][1] = 0;
for (int i = 1; i < prices.length; i++) {
// 第i天持有股票即dp[i][0]
// 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:dp[i - 1][0]
// 第i天买入股票,所得现金就是昨天不持有股票的所得现金减去 今天的股票价格 即:dp[i - 1][1] - prices[i]
dp[i][0] = Math.max(dp[i-1][0], dp[i-1][1] - prices[i]);
// dp[i][1] 表示第i天不持有股票所得最多现金
// 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:dp[i - 1][1]
// 第i天卖出股票,所得现金就是按照今天股票价格卖出后所得现金即:prices[i] + dp[i - 1][0]
dp[i][1] = Math.max(dp[i-1][1], dp[i-1][0] + prices[i]);
}
return dp[n-1][1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 123.买卖股票的最佳时机 III
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
**注意:**你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入:prices = [3,3,5,0,0,3,1,4]
输出:6
解释:在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。
随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3 。
2
3
4
示例 2:
输入:prices = [1,2,3,4,5]
输出:4
解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。
因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
2
3
4
5
示例 3:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这个情况下, 没有交易完成, 所以最大利润为 0。
2
3
示例 4:
输入:prices = [1]
输出:0
2
提示:
1 <= prices.length <= 1050 <= prices[i] <= 105
public static int maxProfit(int[] prices) {
int n = prices.length;
if (n == 0) return 0;
int[][] dp = new int[n][5];
// 一共5个状态
// 0 什么也不操作
// 1 第一次持有股票
// 2 第一次不持有股票
// 3 第二次持有股票
// 4 第二次不持有股票
dp[0][1] = -prices[0];
dp[0][3] = -prices[0];
for (int i = 1; i < n; i++) {
dp[i][1] = Math.max(dp[i-1][0] - prices[i], dp[i-1][1]);
dp[i][2] = Math.max(dp[i-1][1] + prices[i], dp[i-1][2]);
dp[i][3] = Math.max(dp[i-1][2] - prices[i], dp[i-1][3]);
dp[i][4] = Math.max(dp[i-1][3] + prices[i], dp[i-1][4]);
}
return dp[n-1][4];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 188.买卖股票的最佳时机 IV
给定一个整数数组 prices ,它的第 i 个元素 prices[i] 是一支给定的股票在第 i 天的价格,和一个整型 k 。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。也就是说,你最多可以买 k 次,卖 k 次。
**注意:**你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入:k = 2, prices = [2,4,1]
输出:2
解释:在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4-2 = 2 。
2
3
示例 2:
输入:k = 2, prices = [3,2,6,5,0,3]
输出:7
解释:在第 2 天 (股票价格 = 2) 的时候买入,在第 3 天 (股票价格 = 6) 的时候卖出, 这笔交易所能获得利润 = 6-2 = 4 。
随后,在第 5 天 (股票价格 = 0) 的时候买入,在第 6 天 (股票价格 = 3) 的时候卖出, 这笔交易所能获得利润 = 3-0 = 3 。
2
3
4
提示:
0 <= k <= 1000 <= prices.length <= 10000 <= prices[i] <= 1000
public static int maxProfit(int k, int[] prices) {
int n = prices.length;
if (n == 0) return 0;
int[][] dp = new int[n][2 * k + 1];
for (int i = 1; i < 2 * k; i += 2) {
dp[0][i] = -prices[0];
}
// 奇数买入
// 偶数卖出
for (int i = 1; i < n; i++) {
for (int j = 0; j < 2 * k - 1; j += 2) {
// 奇数买入
dp[i][j+1] = Math.max(dp[i-1][j] - prices[i],dp[i-1][j + 1]);
// 偶数卖出
dp[i][j+2] = Math.max(dp[i-1][j+1] + prices[i],dp[i-1][j + 2]);
}
}
return dp[n-1][2 * k];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 309.最佳买卖股票时机含冷冻期
给定一个整数数组prices,其中第 prices[i] 表示第 *i* 天的股票价格 。
设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票):
- 卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。
**注意:**你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入: prices = [1,2,3,0,2]
输出: 3
解释: 对应的交易状态为: [买入, 卖出, 冷冻期, 买入, 卖出]
2
3
示例 2:
输入: prices = [1]
输出: 0
2
提示:
1 <= prices.length <= 50000 <= prices[i] <= 1000
public int maxProfit(int[] prices) {
int n = prices.length;
if (n == 0) return 0;
// dp[i][0] 状态1:持有股票
// dp[i][1] 状态2:不持有股票 保持卖出的状态
// dp[i][2] 状态3:不持有股票 今天卖出
// dp[i][3] 状态4: 今天冷冻期
int[][] dp = new int[n][4];
dp[0][0] = -prices[0];
for (int i = 1; i < n; i++) {
// 继续保持前一天状态, 今天买入 前一天冷冻期可以买入股票,前一天是保持卖出状态
dp[i][0] = Math.max(dp[i-1][0], Math.max(dp[i-1][3] - prices[i],dp[i-1][1] - prices[i]));
dp[i][1] = Math.max(dp[i-1][1], dp[i-1][3]);
dp[i][2] = dp[i-1][0] + prices[i];
dp[i][3] = dp[i-1][2];
}
return Math.max(dp[n-1][3], Math.max(dp[n-1][1], dp[n-1][2]));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18