 V8引擎的运行原理
V8引擎的运行原理
# JavaScript引擎
当我们编写JavaScript代码时,它实际上是一种高级语言,这种语言并不是机器语言 (opens new window)。
- 高级语言是设计给开发人员使用的,它包括了更多的抽象和可读性。
- 但是,计算机 (opens new window)的CPU只能理解特定的机器语言,它不理解JavaScript语言。
- 这意味着,在计算机上执行JavaScript代码之前,必须将其转换为机器语言。
这就是JavaScript引擎的作用:
- 事实上我们编写的JavaScript无论你交给浏览器或者Node执行,最后都是需要被CPU (opens new window)执行的;
- 但是CPU只认识自己的指令集,实际上是机器语言,才能被CPU所执行;
- 所以我们需要JavaScript引擎帮助我们将JavaScript代码翻译成CPU指令来执行;
比较常见的JavaScript引擎有哪些呢?
- SpiderMonkey:第一款JavaScript引擎,由Brendan Eich开发(也就是JavaScript作者);
- Chakra:微软开发,用于IT浏览器;
- JavaScriptCore:WebKit中的JavaScript引擎,Apple公司开发;
- V8:Google开发的强大JavaScript引擎,也帮助Chrome从众多浏览器中脱颖而出;
# 浏览器内核和JS引擎关系
- 浏览器内核和JavaScript引擎之间有紧密的关系,因为JavaScript引擎是浏览器内核中的一个组件。
- 浏览器内核负责渲染网页,并在渲染过程中执行JavaScript代码。
- JavaScript引擎则是负责解析、编译和执行JavaScript代码的核心组件。
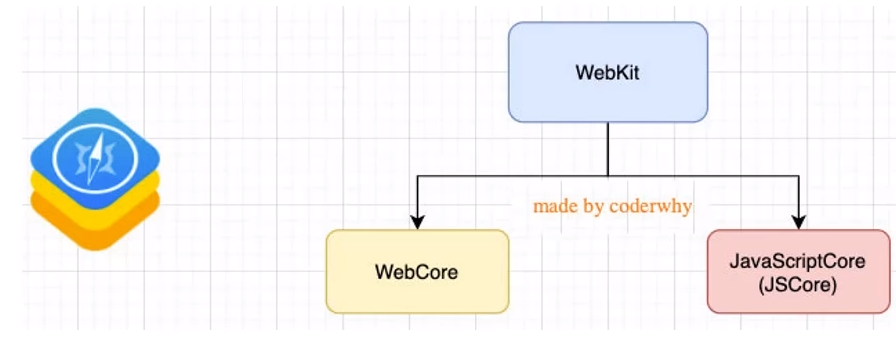
以WebKit为例,它是一种开源的浏览器内核,最初由Apple公司开发,并被用于Safari浏览器中。
- WebKit包含了一个JavaScript引擎,名为JavaScriptCore,它负责解析、编译和执行JavaScript代码。
WebKit事实上由两部分组成的:
- WebCore:负责HTML解析、布局、渲染等等相关的工作。
- JavaScriptCore:解析、执行JavaScript代码。
# V8引擎的运行原理
# V8引擎的官方定义
V8引擎是一款Google开源的高性能JavaScript和WebAssembly引擎,它是使用C++编写的。
- V8引擎的主要目标是提高JavaScript代码的性能和执行速度。
- V8引擎可以在多种操作系统上运行,包括Windows 7或更高版本、macOS 10.12+以及使用x64、IA-32、ARM或MIPS处理器的Linux系统。
V8引擎可以作为一个独立的应用程序运行,也可以嵌入到其他C++应用程序中,例如Node.js。
- 由于V8引擎的开源性和高性能,许多现代浏览器都使用了V8引擎或其修改版本,以提供更快、更高效的JavaScript执行体验。
# V8引擎如何工作呢?
# V8引擎的工作图
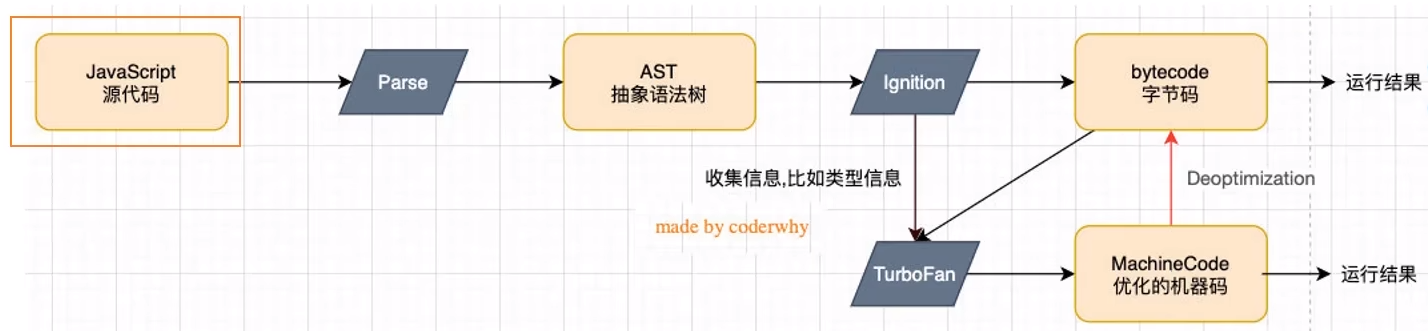
第一步,JS代码会经过parse功能模块。(解析,解析其实包括词法分析和语法分析)分析完了,会将其生成为AST抽象语法树。这里给大家提供了一个AST语法树转换网站 ,AST语法树在babel里也有被使用,学过vue的小伙伴应该很亲切。通过AST我们可以将ES6代码转换为ES5代码,也可以转换为字节码(通过ignition功能模块) 为什么一定要转换为字节码而不是机器指令?那是因为不同CPU架构,机器指令是不同的,而字节码是跨平台的,它就方便多了。
为了更加的优化,我们可以转换一些用的比较多的函数为字节码,也是上面图片的一个模块功能TurboFan,热函数功能。他可以将一些用的比较多的函数标记为热函数。方便提高效率。 但是我们可以看下面的代码
function sum(n1,n2){
n1 + n2
}
sum(20,30) //1
sum('aaa','bbb') //2
2
3
4
5
由于js是个动态语言,没有做类型限制,我们本想做一个数值的相加(并将其标记为热函数),可是阴差阳错,做成了字符串的拼接)(代码中标记为2处)。那咋解决呢?这个热函数是不是就不能用了呢?当然不是!引擎V8有个Deoptimization功能,它可以再将这种特殊情况转换为字节码。(其实就是处理一个特殊情况)。
由此我们可以推出,若使用Typescript开发,运行效率就会提高不少。
# 整体流程解析
- 词法分析:
- 首先,V8引擎将JavaScript代码分成一个个标记或词法单元,这些标记是程序语法的最小单元。
- 例如,变量名、关键字、运算符等都是词法单元。
- V8引擎使用词法分析器来完成这个任务。
- 语法分析:
- 在将代码分成标记或词法单元之后,V8引擎将使用语法分析器将这些标记转换为抽象语法树(AST)。
- 语法树是代码的抽象表示,它捕捉了代码中的结构和关系。
- V8引擎会检查代码是否符合JavaScript语言规范,并将其转换为抽象语法树。
- 字节码生成:
- 接下来,V8引擎将从语法树生成字节码。
- 字节码是一种中间代码,它包含了执行代码所需的指令序列。
- 字节码是一种抽象的机器代码,它比源代码更接近机器语言,但仍需要进一步编译成机器指令。
- 机器码生成:
- 最后,V8引擎将生成机器码,这是一种计算机可以直接执行的二进制代码。
- V8引擎使用即时编译器(JIT)来将字节码编译成机器码。
- JIT编译器将字节码分析为代码的热点部分,并生成高效的机器码,以提高代码的性能。
# V8引擎的架构设计
V8引擎本身的源码非常复杂,大概有超过100w行C++代码,通过了解它的架构,我们可以知道它是如何对JavaScript执行的:
Parse模块会将JavaScript代码转换成AST(抽象语法树),这是因为解释器并不直接认识JavaScript代码;
- 如果函数没有被调用,那么是不会被转换成AST的;
- Parse的V8官方文档:https://v8.dev/blog/scanner
Ignition是一个解释器,会将AST转换成ByteCode(字节码)
- 同时会收集TurboFan优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算);
- 如果函数只调用一次,Ignition会执行解释执行ByteCode;
- Ignition的V8官方文档:https://v8.dev/blog/ignition-interpreter
TurboFan是一个编译器,可以将字节码编译为CPU可以直接执行的机器码;
- 如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过TurboFan转换成优化的机器码,提高代码的执行性能;
- 但是,机器码实际上也会被还原为ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化(比如sum函数原来执行的是number类型,后来执行变成了string类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码;
- TurboFan的V8官方文档:https://v8.dev/blog/turbofan-jit
另外,V8引擎还包括了垃圾回收机制,用于自动管理内存的分配和释放。V8引擎使用了一种名为“分代式垃圾回收”(Generational Garbage Collection)的技术,它将堆区分成新生代和老年代两个部分,分别使用不同的垃圾回收策略,以提高垃圾回收的效率。
# V8的转化代码过程
比如我们有如下一段代码,V8引擎是如何一步步帮我们转化的呢?
const name = "coderwhy"
console.log(name)
function sayHi(name) {
console.log("Hi " + name)
}
sayHi(name)
2
3
4
5
6
7
8
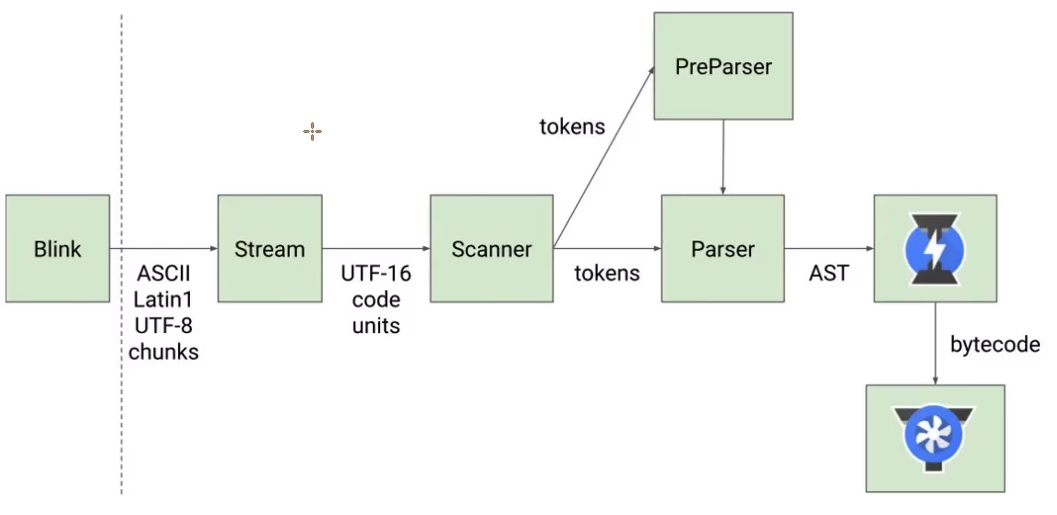
# 词法分析的过程
词法分析是将JavaScript代码转换成一系列标记的过程,它是编译过程的第一步。
- 在V8引擎中,词法分析器会将JavaScript代码分解成一系列标识符、关键字、操作符和字面量等基本元素,以供后续的语法分析和代码生成等步骤使用。
Token(type='const', value='const')
Token(type='identifier', value='name')
Token(type='operator', value='=')
Token(type='string', value='"coderwhy"')
Token(type='operator', value=';')
Token(type='console', value='console')
Token(type='operator', value='.')
Token(type='identifier', value='log')
Token(type='operator', value='(')
Token(type='identifier', value='name')
Token(type='operator', value=')')
Token(type='operator', value=';')
Token(type='function', value='function')
Token(type='identifier', value='sayHi')
Token(type='operator', value='(')
Token(type='identifier', value='name')
Token(type='operator', value=')')
Token(type='operator', value='{')
Token(type='console', value='console')
Token(type='operator', value='.')
Token(type='identifier', value='log')
Token(type='operator', value='(')
Token(type='string', value='"Hi "')
Token(type='operator', value='+')
Token(type='identifier', value='name')
Token(type='operator', value=')')
Token(type='operator', value=';')
Token(type='operator', value='}')
Token(type='identifier', value='sayHi')
Token(type='operator', value='(')
Token(type='identifier', value='name')
Token(type='operator', value=')')
Token(type='operator', value=';')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 语法分析的过程
接下来我们可以根据上面得到的tokens代码,进行语法分析,生成对应的AST树。
在V8引擎中,语法分析的过程可以分为两个阶段:解析(Parsing)和预处理(Pre-parsing)。
解析阶段是将tokens转换成抽象语法树(AST)的过程,而预处理阶段则是在解析阶段之前进行的,用于预处理一些代码,如函数和变量声明等。
对于你提供的JavaScript代码,V8引擎的解析和预处理过程如下所示:
V8引擎的解析和预处理过程如下所示:
1.预处理阶段
- 在预处理阶段,V8引擎会扫描整个代码,查找函数和变量声明,并将其添加到当前作用域的符号表中。
- 在这个过程中,V8引擎会同时进行词法分析和语法分析,生成一些中间表示,以便后续使用。
- 对于我们的代码,预处理阶段不会生成任何AST节点,因为它只包含了一个常量声明和一个函数声明,而没有变量声明(var声明的变量)。
为什么我们需要预解析?
function eat(){ function eatFood(){ .... //代码片段 } } eat()1
2
3
4
5
6我们看上面的函数,其实完全没有必要对eatFood那个方法进行解析。因为我们没有调用过它。如果每次都要对它转换成AST,bytecode真的很浪费性能!
所以V8会采用一个Preparser(预解析)功能,以此来提高性能。(引擎只需要知道有这个函数就行了,不需要阅读它里面具体的代码片段)
2.解析阶段
- 在解析阶段,V8引擎会将tokens转换成AST节点,生成一棵抽象语法树(AST)。
- AST是一种树形结构,用于表示程序的语法结构,它包含了多种类型的节点,如表达式节点、语句节点和声明节点等。
转化的AST树代码参考:
Program
└── VariableDeclaration (const name = "coderwhy")
└── ExpressionStatement (console.log(name))
└── FunctionDeclaration (function sayHi(name) { ... })
└── BlockStatement
└── ExpressionStatement (console.log("Hi " + name))
└── ExpressionStatement (sayHi(name))
2
3
4
5
6
7
从AST树中可以看出,整个程序由一个Program节点和三个子节点组成。
- 其中,第一个子节点是一个VariableDeclaration节点,表示常量声明语句;
- 第二个子节点是一个ExpressionStatement节点,表示console.log语句;
- 第三个子节点是一个FunctionDeclaration节点,表示函数声明语句。
- FunctionDeclaration节点包含一个BlockStatement子节点,表示函数体,其中包含一个ExpressionStatement节点,表示console.log语句。
- 最后一个子节点是一个ExpressionStatement节点,表示调用函数语句。
# 转化的字节码
根据上面得到的AST树,我们可以将其转换成对应的字节码。在V8引擎中,字节码是一种中间表示,用于表示程序的执行流程和指令序列。
V8引擎会将AST树转换成如下的字节码序列:
// 字节码指令集
[Constant name="coderwhy"]
[SetLocal name]
[GetLocal name]
[LoadProperty console]
[LoadProperty log]
[Call 1]
[Constant Hi ]
[GetLocal name]
[BinaryOperation +]
[Call 1]
[SetLocal sayHi]
[GetLocal name]
[GetLocal sayHi]
[Call 1]
[Return]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
根据上面生成的字节码,我们可以看到V8引擎生成的字节码指令集,每个指令都对应了一种操作,如Constant、SetLocal、GetLocal等等。下面是对字节码指令集的解释:
- Constant:将常量值压入操作数栈中。
- SetLocal:将操作数栈中的值存储到本地变量中。
- GetLocal:将本地变量的值压入操作数栈中。
- LoadProperty:从对象中加载属性值,并将其压入操作数栈中。
- Call:调用函数,并将返回值压入操作数栈中。
- BinaryOperation:对两个操作数执行二元运算,并将结果压入操作数栈中。
- Return:从当前函数中返回,并将返回值压入操作数栈中。
由于字节码是一种中间表示,它可以跨平台运行,在不同的操作系统和硬件平台上都可以执行。这种跨平台的特性,使得V8引擎成为了一款非常流行的JavaScript引擎。
在Node环境中,我们可以通过如下命令查看到字节码:
- 但是默认Node环境下是打印所有的字节码的,所以内容会非常多(了解即可)
node --print-bytecode test.js
# 生成的机器码
在V8引擎中,机器码是通过即时编译(Just-In-Time Compilation,JIT)技术生成的。
JIT编译是一种动态编译技术,它将字节码转换成本地机器码,并将其缓存起来以提高代码的执行速度和性能。
JIT编译器可以根据运行时信息对代码进行优化,并且可以根据不同的平台和硬件生成对应的机器码。
在V8引擎中,机器码的生成过程分为两个阶段:
- 预编译(pre-compilation)和优化(optimization)。
- 预编译阶段会生成一些简单的机器码,用于快速执行代码;
- 优化阶段则会根据代码的运行时信息生成更优化的机器码,以提高代码的执行效率和性能。
具体的生成过程如下:
1.预编译阶段
- 在预编译阶段,V8引擎会生成一些简单的机器码,用于快速执行代码。
- 这些机器码是基于字节码生成的,它们可以直接执行,并且具有一定的优化效果。
- 在这个阶段,V8引擎会根据代码的运行时信息生成一些简单的机器码,如对象和数组的存取、字符串的拼接、函数的调用等。
2.优化阶段
- 在优化阶段,V8引擎会根据代码的运行时信息生成更优化的机器码,以提高代码的执行效率和性能。
- 在这个阶段,V8引擎会通过分析代码的执行路径、类型信息、控制流程等,生成一些高效的机器码,并且可以进行多次优化,以获得更高的性能。
在优化阶段,V8引擎会使用TurboFan编译器来生成机器码。
- TurboFan是一个基于中间表示(Intermediate Representation,IR)的编译器,它可以将字节码转换成高效的机器码,并且可以进行多层次的优化,包括基于类型的优化、内联优化、控制流优化、垃圾回收优化等。
通过机器码的生成过程,我们可以看到V8引擎是如何根据代码的运行时信息生成高效的机器码,并且可以多次优化,以获得更高的性能。
- 在后续的执行过程中,V8引擎会将机器码缓存起来,以提高代码的执行速度和性能。
# 转化流程详细描述
var name = "name"
var num1 = 20
var num2 = 30
var result = num1 + num2
2
3
4
这段代码在V8引擎中运行的时候到底发生了什么样的过程?
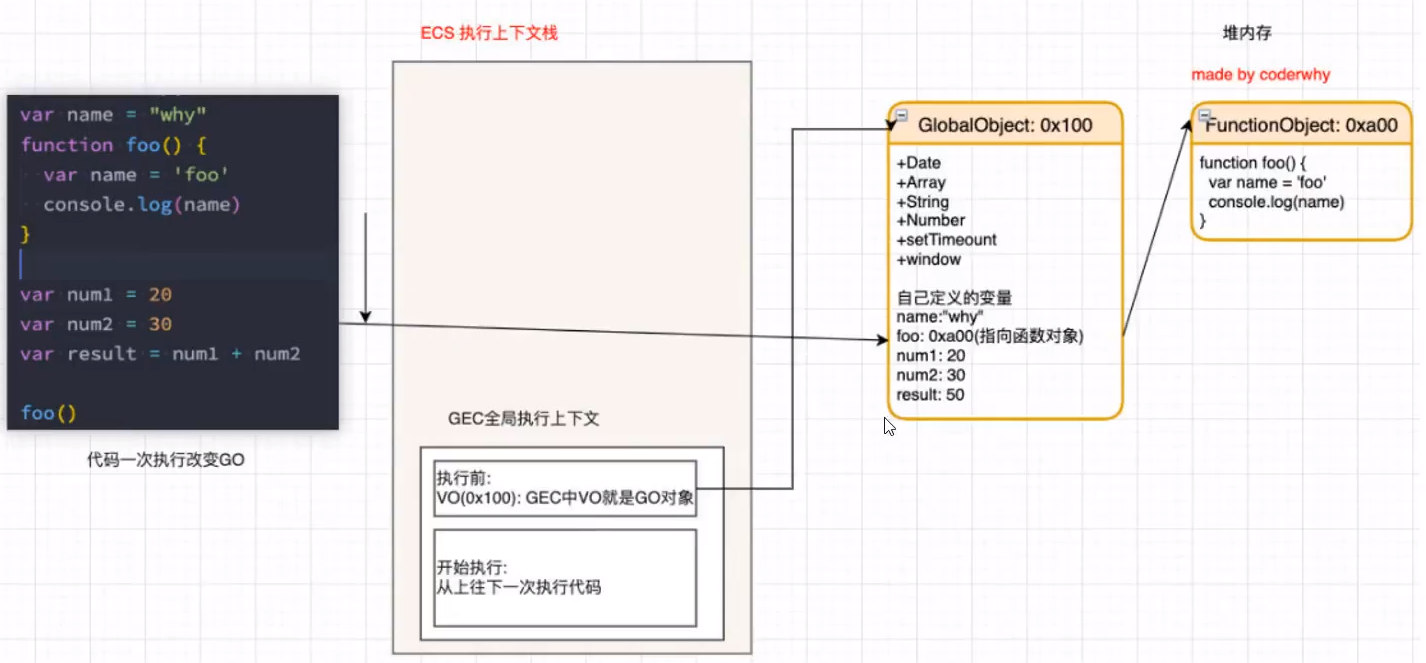
代码被解析时(从JS代码到AST抽象语法树的过程),V8引擎会帮我们创建一个对象名为GlobalObject。它会包含我们很多的全局对象,比如一些包装类(Math,String,Date…),setTimeout;window属性。要注意解析的时候,V8也会将上述代码的变量(name,num1,num2),写进这个GlobalObject,值为undefined 4.
运行代码!为了运行代码,V8内部有一个执行上下文栈(Excution context Stack)。并且为了执行全局代码,V8还要创建全局执行上下文(Global context Stack)将它放入执行上下文栈中。
全局执行上下文中维护了一个东西名为VO,它维护了全局对象GO(GlobalObject),所有要准备的东西都准备好了,就可以开始执行代码了。
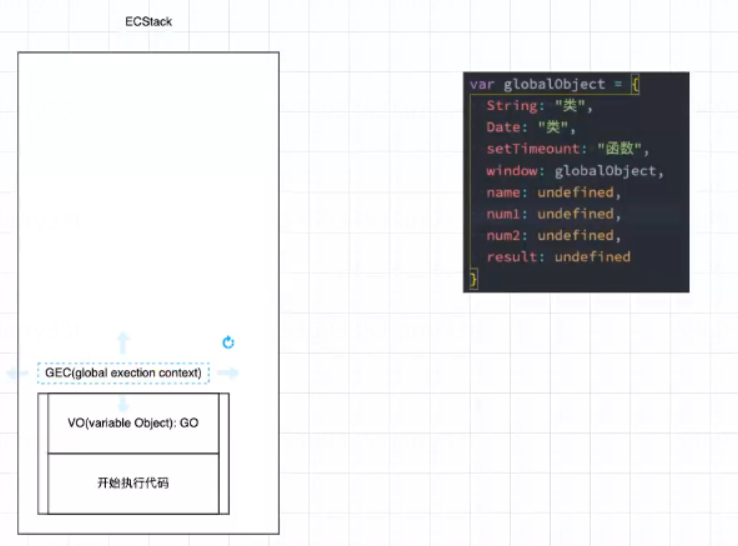
var name = "why"
var num1 = 20
console.log(num2); //A处,这个代码的值是undefined
var num2 = 30
var result = num1 + num2
2
3
4
5
这里我们在A处打印num2,会发现结果为undefined(不是null,不会说找不到)。这很好理解,因为在GO中num2这个变量已经给它赋值成了undefined。
这就是我们经常说的作用域提升(将变量放到GO里面),当我们没给GO里的变量赋值的时候打印,它的结果是undefined。
# JS执行原理
# 执行上下文
js引擎内部有一个执行上下文栈(Execution Context Stack,简称ECS),它是用于执行代码的调用栈。
那么现在它要执行谁呢?执行的是全局的代码块:
- 全局的代码块为了执行会构建一个Global Execution Context (GEC)(全局执行上下文) ;
- GEC会被放入到ECS中执行;
GEC被放入到ECS中里面包含两部分内容:
第一部分: 在代码执行前,在parser转成AST的过程中,会将全局定义的变量、函数等加入到GlobalObject中,但是并不会赋值;
- 这个过程也称之为变量的作用域提升(hoisting)
第二部分: 在代码执行中,对变量赋值,或者执行其他的函数;
Execution Contexts When control is transferred to ECMAScript executable code, control is entering an execution context.Activeexecution contexts logically form a stack.The top execution context on this logical stack is the runningexecution context.
当控制权转移到ECMAScript可执行代码时,控制权正在进入执行上下文。活动执行上下文在逻辑上形成一个堆栈。此逻辑堆栈上的顶级执行上下文是正在运行的执行上下文。
# VO对象
每一个执行上下文会关联一个VO (Variable Object,变量对象),变量和函数声明会被添加到这个VO对象中。 Every execution context has associated with it a variable object. Variables and functions declared in the source text are added as properties of the variable object. For function code,parameters are added as properties of the variable object.(每个执行上下文都关联了一个变量对象。源文本中声明的变量和函数将作为变量对象的属性添加。对于函数代码,参数是作为变量对象的属性添加的。)
当全局代码被执行的时候,VO就是GO对象了
Global Code
- The scope chain is created and initialised to contain the global object and no others. (作用域链被创建并初始化为包含全局对象而不包含其他对象。)
- Variable instantiation is performed using the global object as the variable object and using property. (使用全局对象作为变量对象并使用属性来执行变量实例化) attributes { DontDelete }.
- The this value is the global object.
代码执行前示意图:
注:图中函数应该放在上面
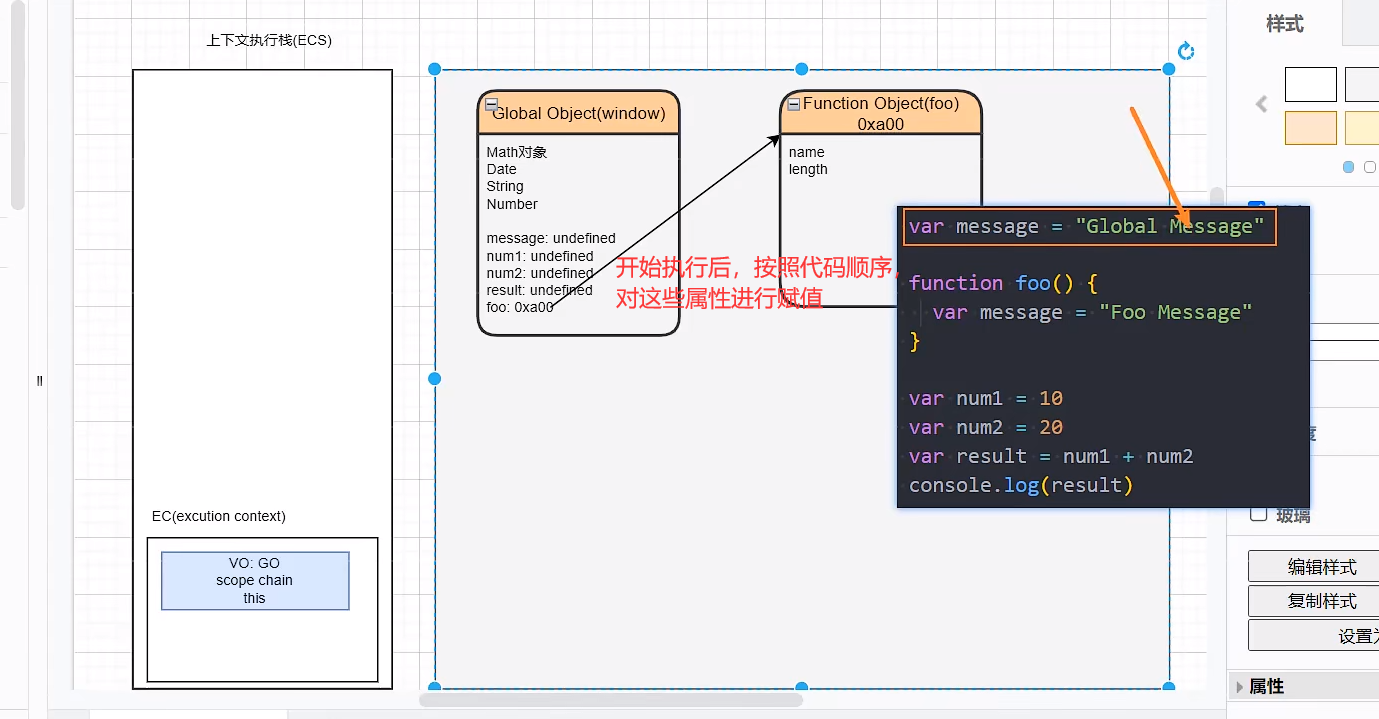
全局代码执行过程
# 函数如何被执行
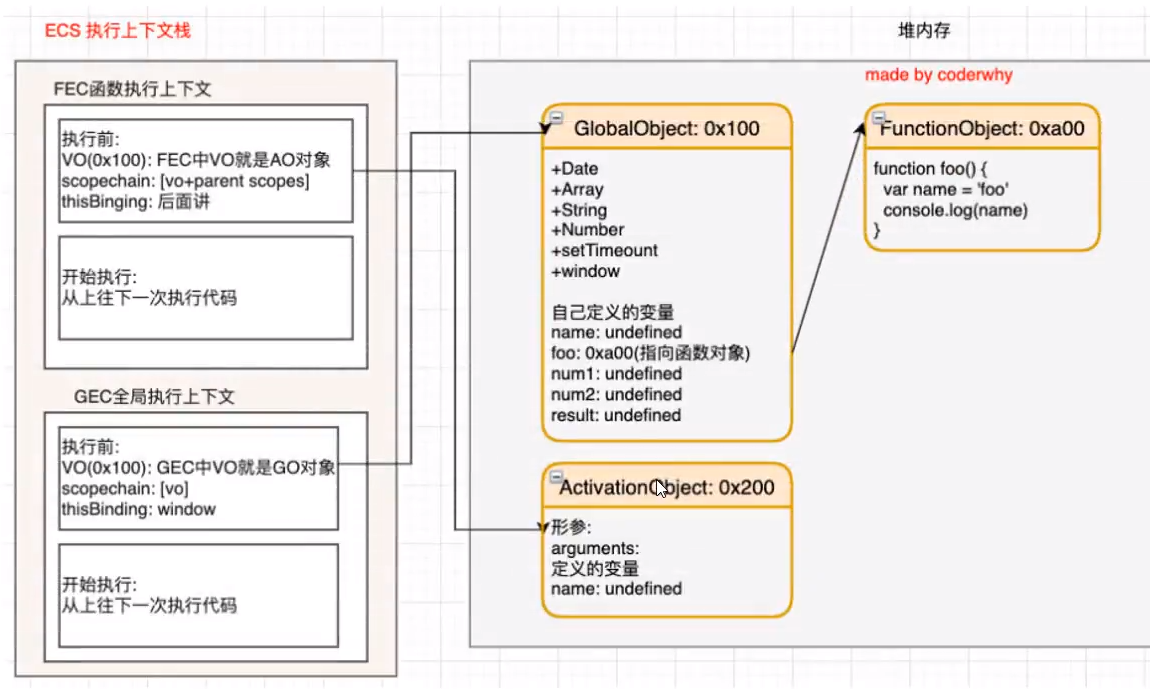
在执行的过程中执行到一个函数时,就会根据函数体创建一个函数执行上下文(Functiona Execution Context,简称FEC) , 并且呀入到EC Stack中。
因为每个执行上下文都会关联一个VO,那么函数执行上下文关联的VO是什么呢?
- 当进入一个函数执行上下文时,会创建一个AO对象(Activation Object) ;
- 这个AO对象会使用arguments作为初始化,并且初始值是传入的参数;
- 这个AO对象会作为执行上下文的VO来存放变量的初始化;
When control enters an execution context for function code,an object called the activation object is created and associated with the execution context. The activation object is initialised with a property with name arguments and attributes { DontDelete }. The initial value of this property is the arguments object described below. The activation object is then used as the variable object for the purposes of variable instantiation.
函数执行过程(执行前)
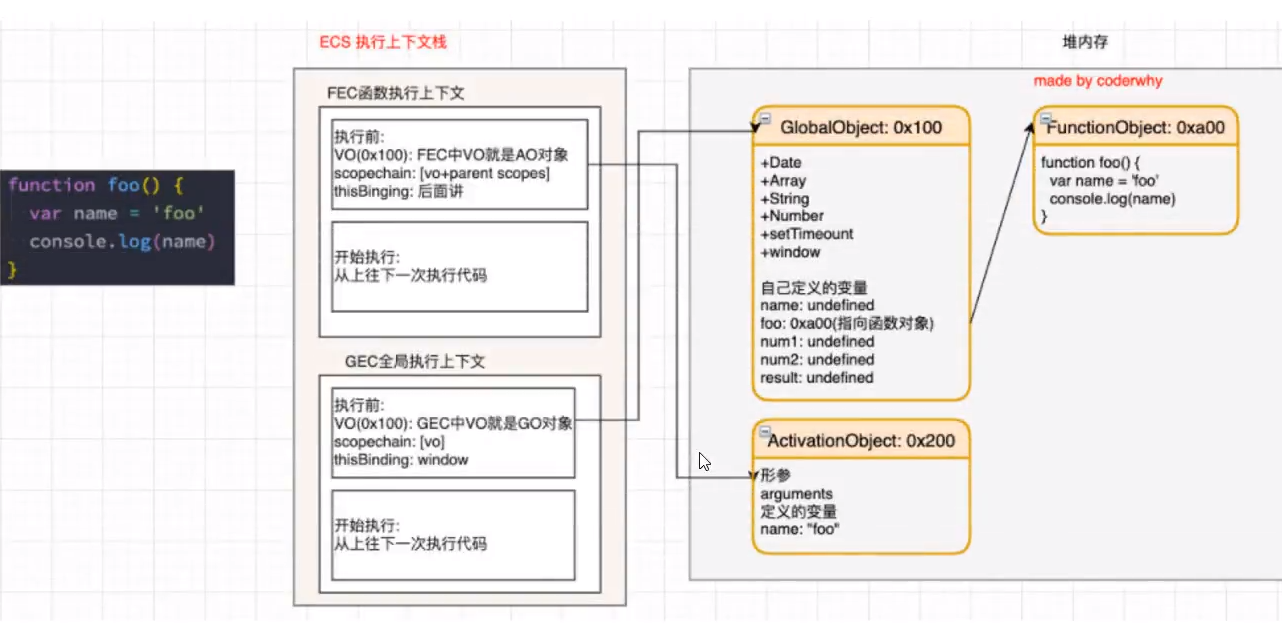
函数执行过程(执行后)
# 函数多次执行
函数第一次被调用
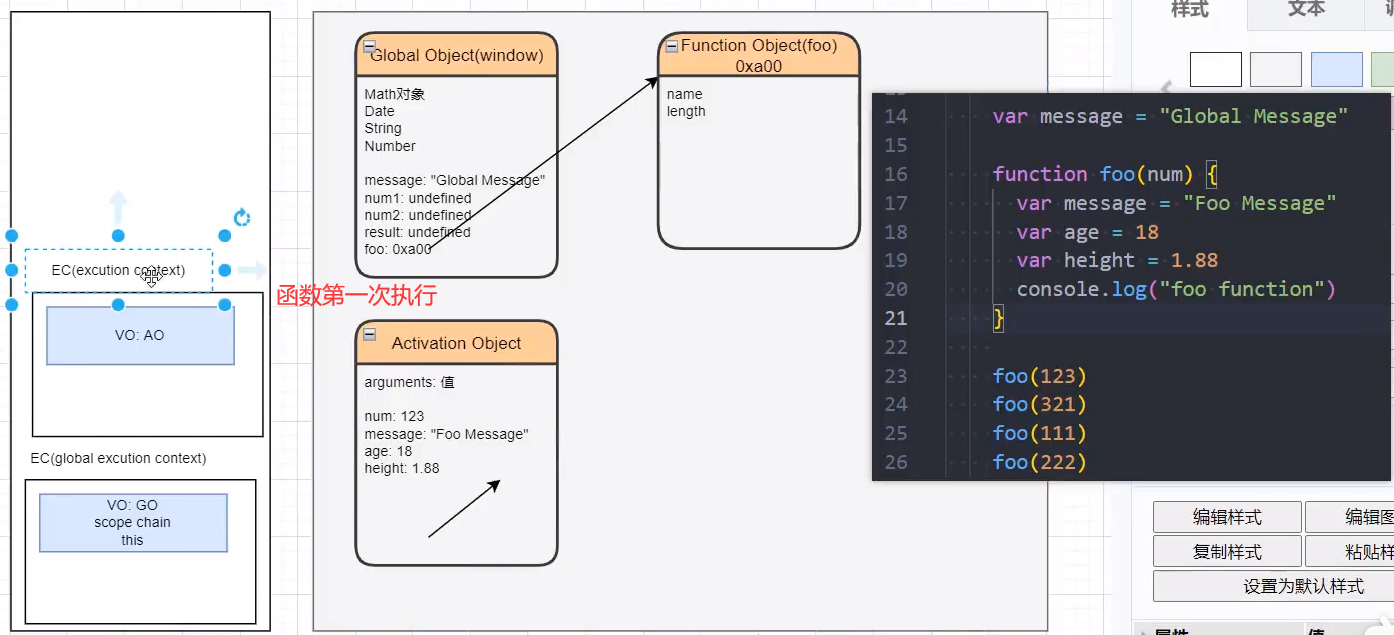
函数第二次被调用
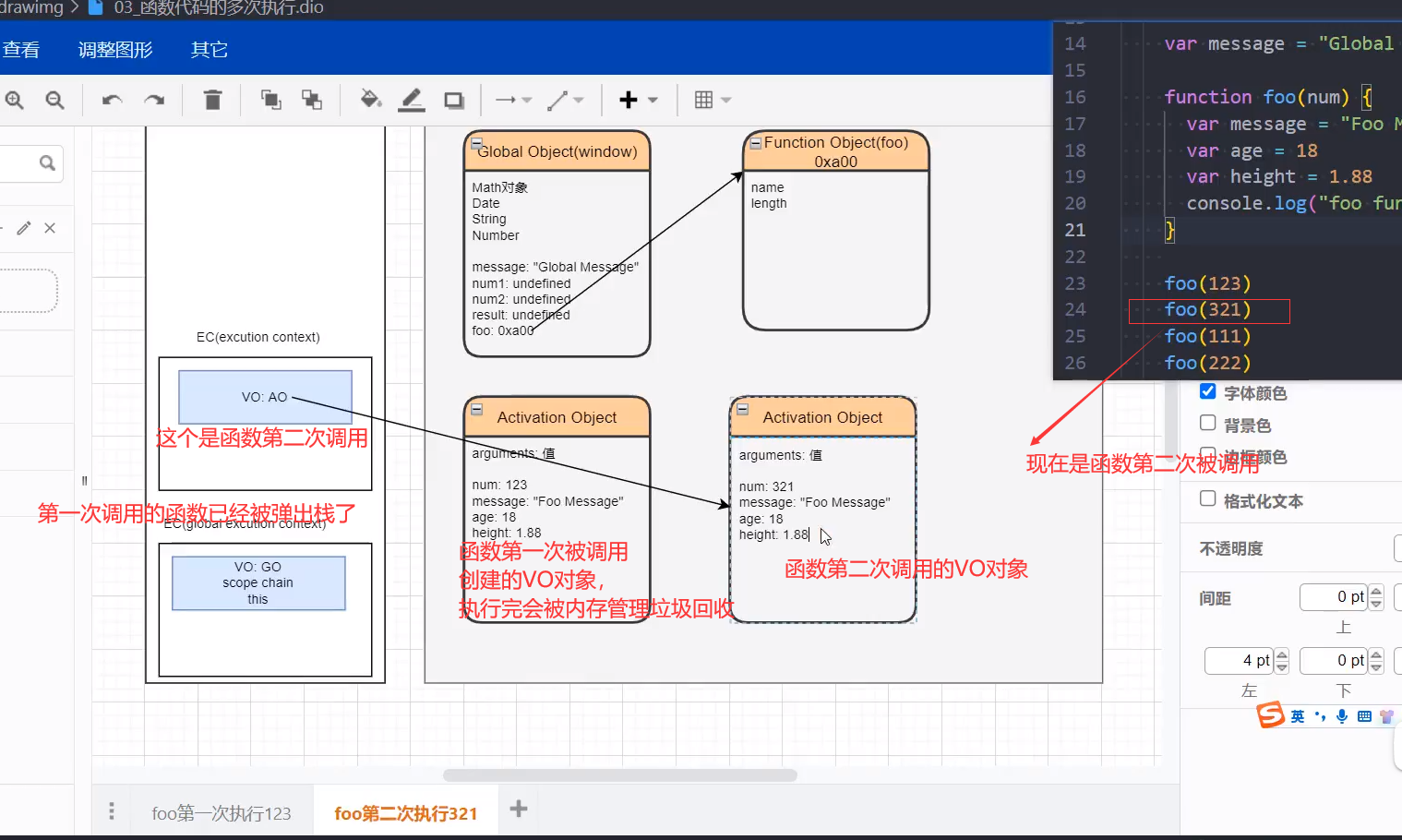
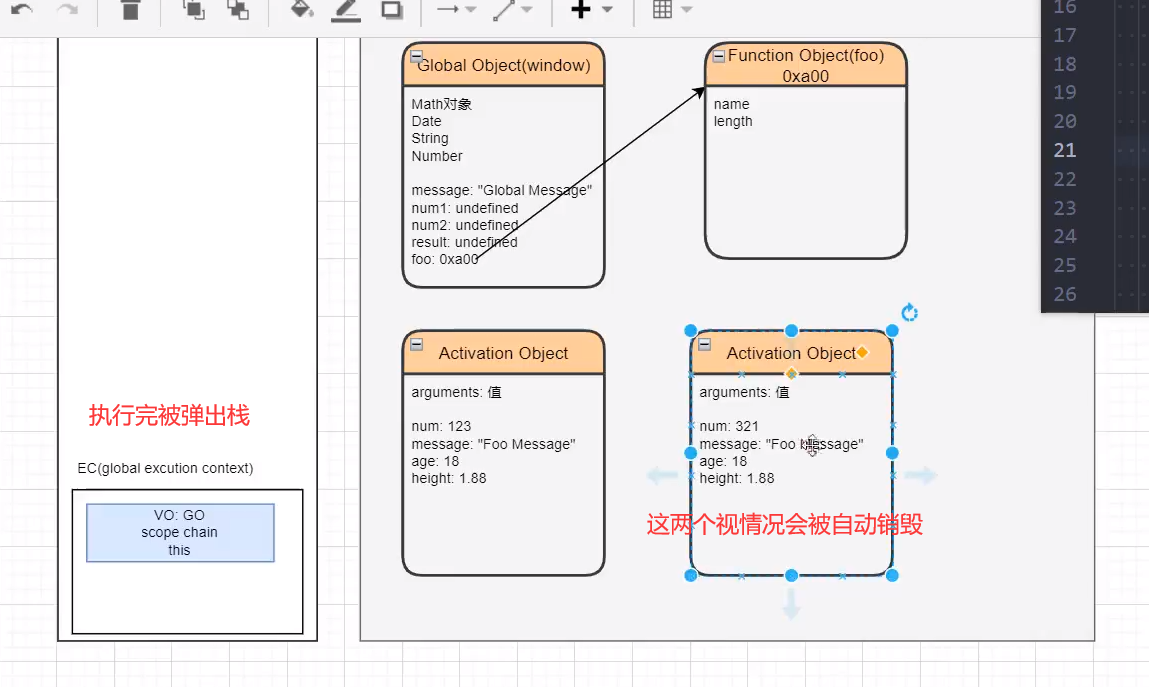
执行完:
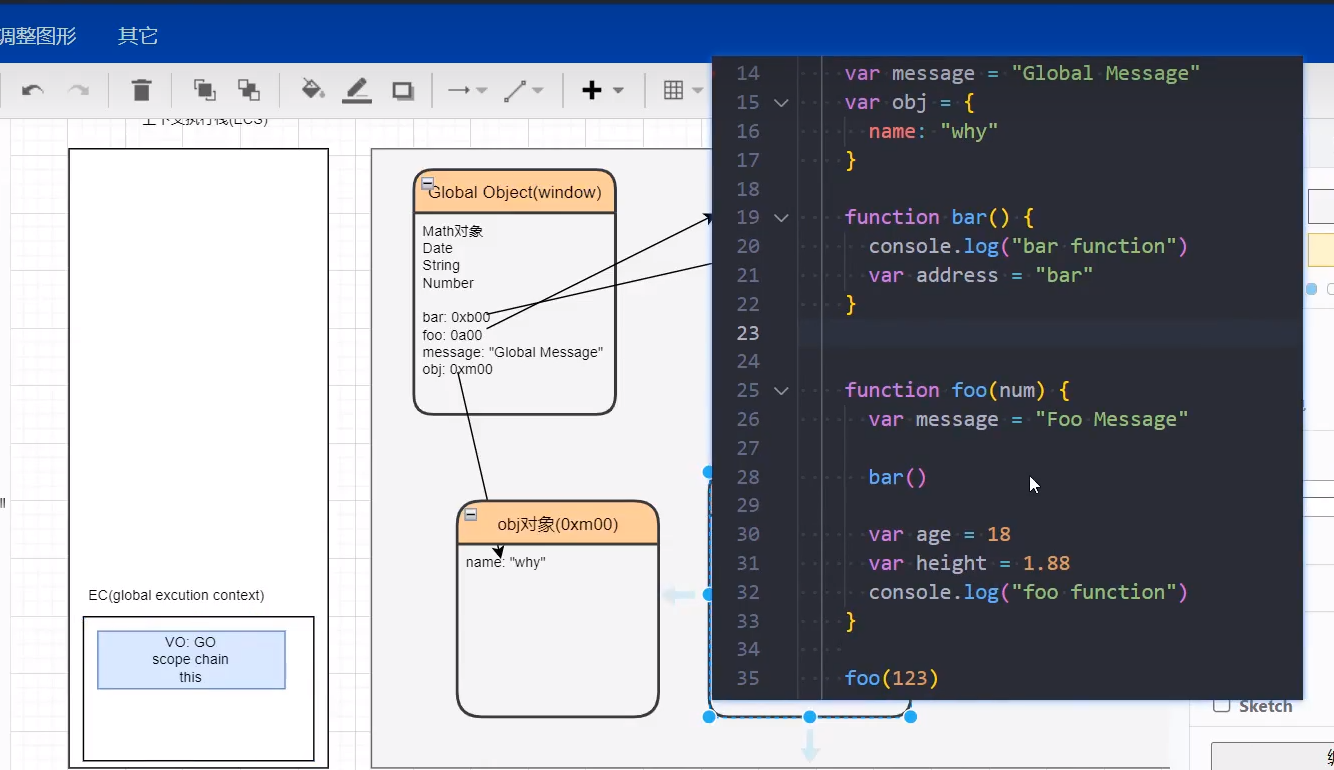
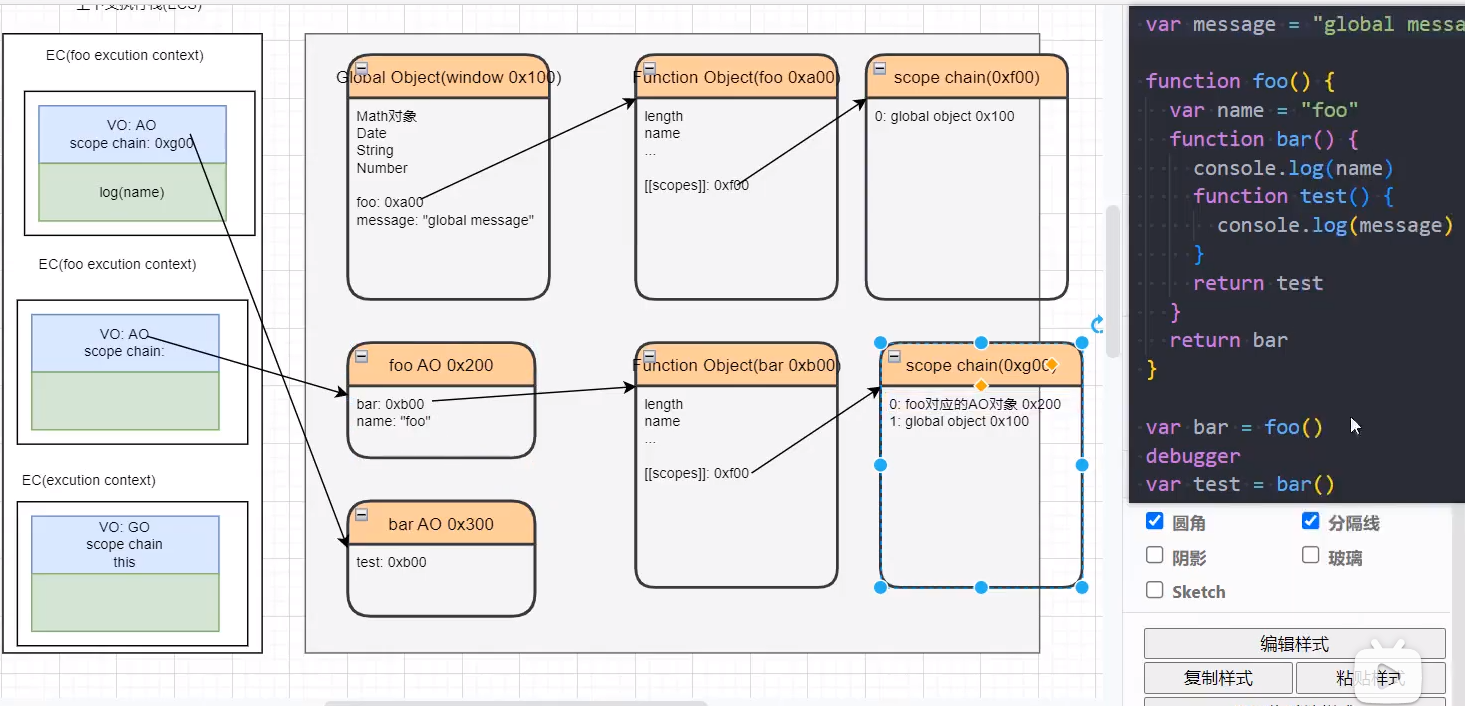
# 函数间相互被调用
未执行前:只有函数会被预先创建。
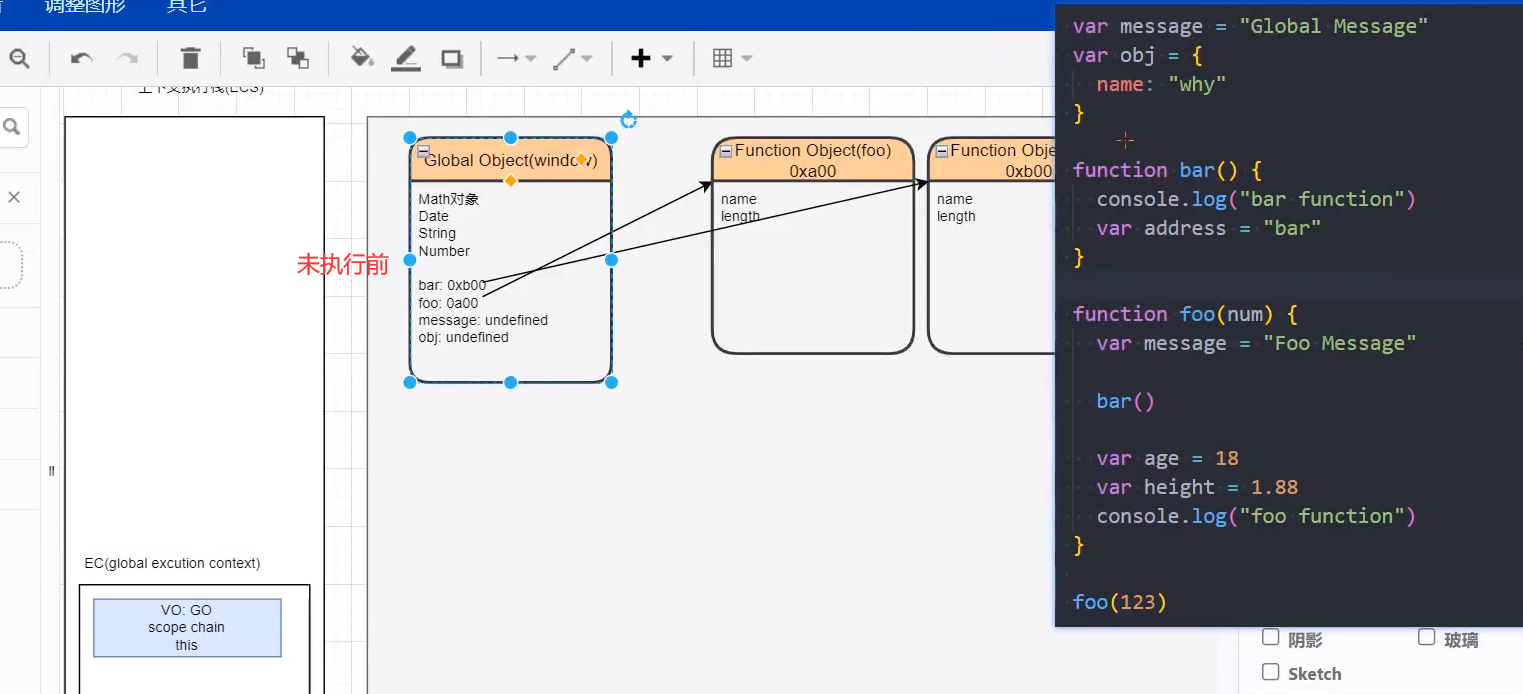

bar函数执行完毕
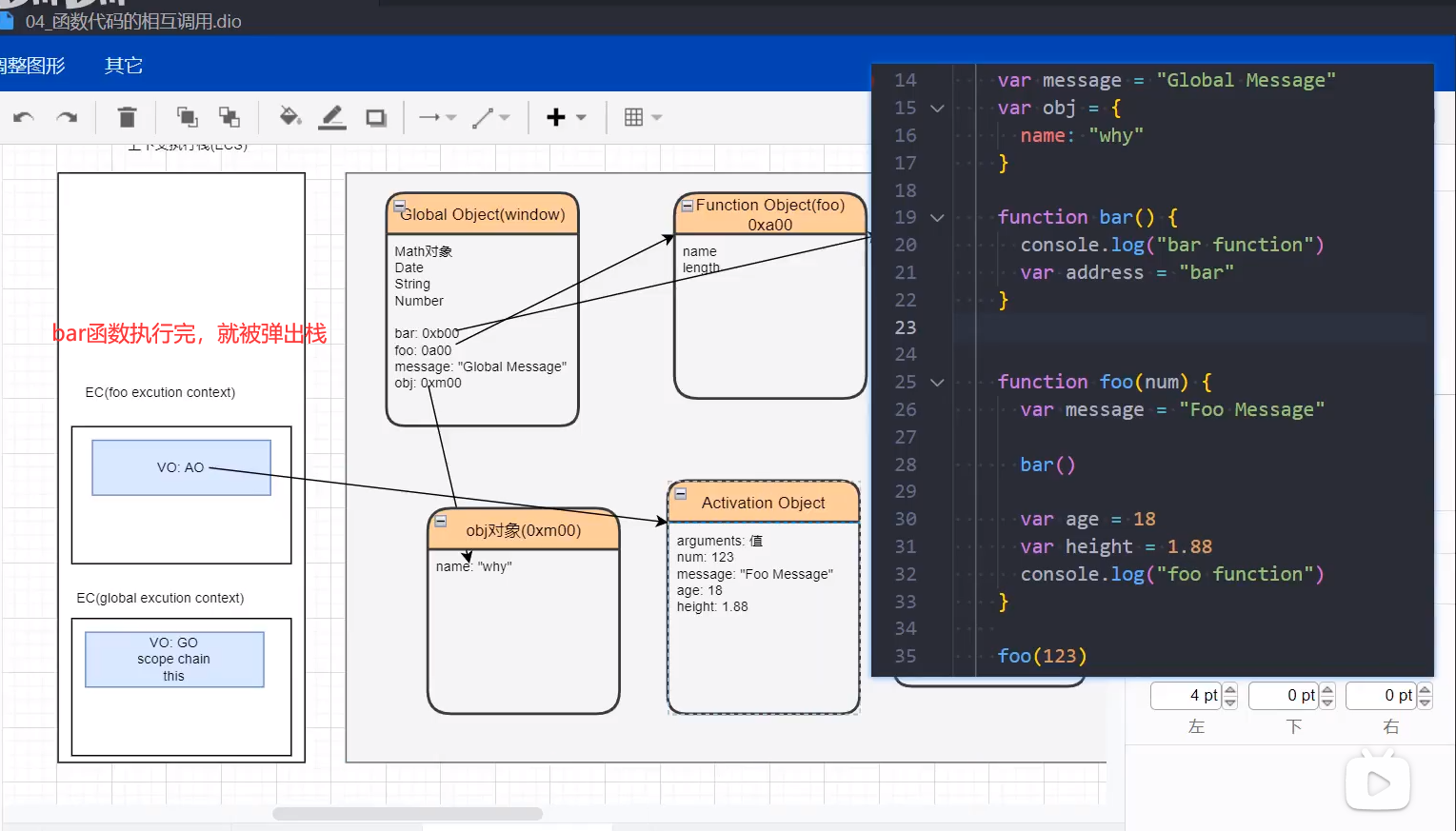
foo函数执行完毕
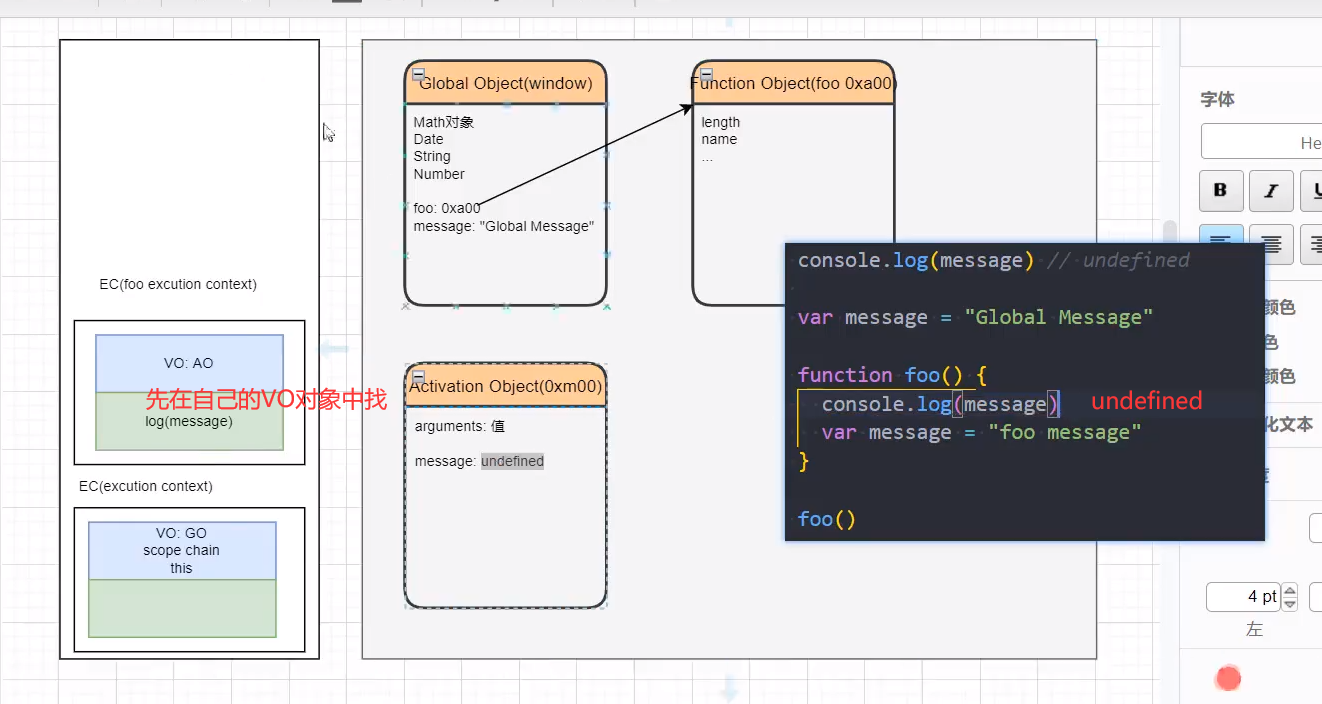
# 作用域和作用域链
- 当进入到一个执行上下文时,执行上下文也会关联一个作用域链(Scope Chain)
- 作用域链是一个对象列表,用于变量标识符的求值;
- 当进入一个执行上下文时,这个作用域链被创建,并且根据代码类型,添加一系列的对象; Every execution context has associated with it a scope chain. A scope chain is a list of objects that are searched when evaluating an Identifier. When control enters an execution context,a scope chain is created and populated with an initial set of objects,depending on the type of code. During execution within an execution context,the scope chain of the execution context is affected only by with statements (see 12.10) and catch clauses (see 12.14). (每个执行上下文都有一个与之相关联的作用域链。作用域链是在评估标识符时搜索的对象列表。当控件进入执行上下文时,根据代码的类型,将创建一个作用域链,并使用一组初始对象进行填充。在执行上下文中执行期间,执行上下文的作用域链仅受with语句(见12.10)和catch子句(见12.14)的影响。)
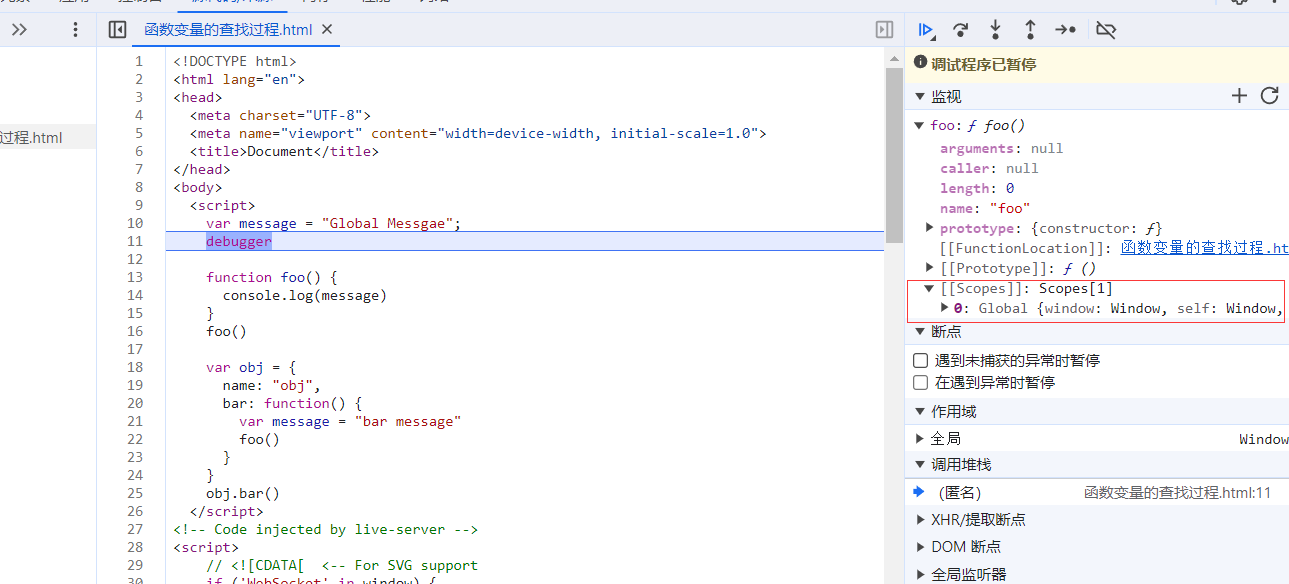
函数变量的查找过程
函数的作用域链是在函数定义的时候就已经确定了
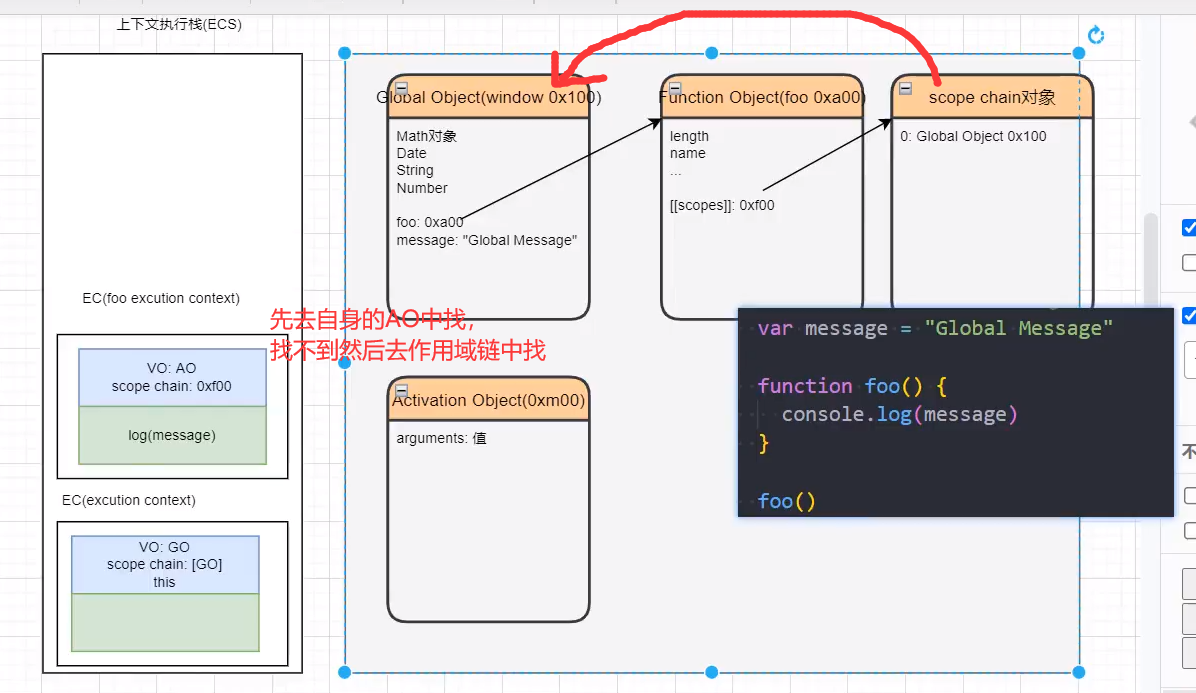
函数嵌套示意图
# 真题
