 JavaScript高级程序设计
JavaScript高级程序设计
# 什么是JavaScript
# JavaScript组成
核心(ECMAScript) 由 ECMA-262 定义并提供核心功能
文档对象模型(DOM)提供与网页内容交互的方法和接口
浏览器对象模型(BOM)提供与浏览器交互的方法和接口

# ECMAScript
ECMAScript,即 ECMA-262 定义的语言,并不局限于 Web 浏览器。
JavaScript 实现了ECMAScript
# DOM
文档对象模型(DOM,Document Object Model)是一个应用编程接口(API),用于在 HTML 中使用扩展的 XML。
DOM 通过创建表示文档的树,让开发者可以随心所欲地控制网页的内容和结构。使用 DOM API,可以轻松地删除、添加、替换、修改节点。

DOM Core (提供了一种映射 XML 文档,方便访问和操作文档任意部分)
DOM HTML (扩展了前者,并增加了特定于 HTML 的对象和方法。)
DOM 并非只能通过 JavaScript 访问,而且确实被其他很多语言实现了。不过对于浏览器来说,DOM 就是使用 ECMAScript 实现的,如今已经成为 JavaScript 语言的一大组成部分。
# BOM
浏览器对象模型(BOM) API,用于支持访问和操作浏览器的窗口。使用 BOM,开发者可以操控浏览器显示页面之外的部分。
# HTML 中的 JavaScript
# script标签属性
async:可选。表示应该立即开始下载脚本,但不能阻止其他页面动作,比如下载资源或等待其他脚本加载。只对外部脚本文件有效。
<script async src="example1.js"></script> <script async src="example2.js"></script>1
2async和defer它们两者也都只适用于外部脚本,都会告诉浏览器立即开始下载。不过,与 defer 不同的 是,标记为 async 的脚本并不保证能按照它们出现的次序执行- 异步脚本不应该在加载期间修改 DOM。
charset:可选。使用 src 属性指定的代码字符集。这个属性很少使用,因为大多数浏览器不在乎它的值。
crossorigin:可选。配置相关请求的CORS(跨源资源共享)设置。默认不使用CORS。crossorigin= "anonymous"配置文件请求不必设置凭据标志。crossorigin="use-credentials"设置凭据标志,意味着出站请求会包含凭据。
defer:可选。表示脚本可以延迟到文档完全被解析和显示之后再执行。只对外部脚本文件有效。在 IE7 及更早的版本中,对行内脚本也可以指定这个属性。
<script defer src="example1.js"></script> <script defer src="example2.js"></script>1
2- 这个属性表示脚本在执行的时候不会改变页面的结构。也就是说,脚本会被延迟到整个页面都解析完毕后再运行。(相当于浏览器立即下载,但延迟执行。)
integrity:可选。允许比对接收到的资源和指定的加密签名以验证子资源完整性(SRI,Subresource Integrity)。如果接收到的资源的签名与这个属性指定的签名不匹配,则页面会报错,脚本不会执行。这个属性可以用于确保内容分发网络(CDN,Content Delivery Network)不会提供恶意内容。
language:废弃。最初用于表示代码块中的脚本语言(如"JavaScript"、"JavaScript 1.2"或"VBScript")。大多数浏览器都会忽略这个属性,不应该再使用它。
src:可选。表示包含要执行的代码的外部文件。
<script src="example.js"></script>1- 与解释行内 JavaScript 一样,在解释外部 JavaScript 文件时**,页面也会阻塞**。(阻塞时间也包含下载文件的时间。)
使用了 src 属性的
<script>元素不应该再在<script>和</script>标签中再包含其他JavaScript 代码。如果两者都提供的话,则浏览器只会下载并执行脚本文件,从而忽略行内代码。<script src="http://www.somewhere.com/afile.js"></script>1- 浏览器在解析这个资源时,会向 src 属性指定的路径发送一个 GET 请求,以取得相应资源,假定是一个 JavaScript 文件。这个初始的请求不受浏览器同源策略限制,但返回并被执行的 JavaScript 则受限制。
type:可选。代替 language,表示代码块中脚本语言的内容类型(也称 MIME 类型)。按照惯例,这个值始终都是"text/javascript",尽管"text/javascript"和"text/ecmascript"都已经废弃了。JavaScript 文件的 MIME 类型通常是"application/x-javascript",不过给type 属性这个值有可能导致脚本被忽略。在非 IE 的浏览器中有效的其他值还有"application/javascript"和"application/ecmascript"。如果这个值是 module,则代码会被当成 ES6 模块,而且只有这时候代码中才能出现 import 和 export 关键字。
浏览器都会按照
<script>在页面中出现的顺序依次解释它们,前提是它们没有使用 defer 和 async 属性。第二个<script>元素的代码必须在第一个<script>元素的代码解释完毕才能开始解释,
# 标签位置
<script>元素放在页面的<head>标签内
把所有 JavaScript文件都放在<head>里,也就意味着必须把所有 JavaScript 代码都下载、解析和解释完成后,才能开始渲染页面(页面在浏览器解析到<body>的起始标签时开始渲染)。
在此期间浏览器窗口完全空白
将所有 JavaScript 引用放在
<body>元素中的页面内容后面
# 动态加载脚本
let script = document.createElement('script');
script.src = 'gibberish.js';
script.async = false;
document.head.appendChild(script);
2
3
4
默认情况下,以这种方式创建的<script>元素是以异步方式加载的,相当于添加了 async 属性。(但是并不是所有的浏览器都支持async)
以这种方式获取的资源对浏览器预加载器是不可见的。这会严重影响它们在资源获取队列中的优先级。根据应用程序的工作方式以及怎么使用,这种方式可能会严重影响性能。要想让预加载器知道这些动态请求文件的存在,可以在文档头部显式声明它们:
<link rel="preload" href="gibberish.js">
# 行内代码与外部文件
推荐使用外部文件的理由如下。
可维护性。JavaScript 代码如果分散到很多 HTML 页面,会导致维护困难。而用一个目录保存所有 JavaScript 文件,则更容易维护,这样开发者就可以独立于使用它们的 HTML 页面来编辑代码。
缓存。浏览器会根据特定的设置缓存所有外部链接的 JavaScript 文件,这意味着如果两个页面都用到同一个文件,则该文件只需下载一次。这最终意味着页面加载更快。
适应未来。通过把 JavaScript 放到外部文件中,就不必考虑用 XHTML 或前面提到的注释黑科技。
# 文档模式
可以使用 doctype 切换文档模式
混杂模式(quirks mode)和标准模式(standards mode)准标准模式(almost standards mode)。
html5的DOCTYPE声明,即<!DOCTYPE html>
# **<noscript>**元素
在下列两种情况下,浏览器将显示包含在
浏览器不支持脚本;
浏览器对脚本的支持被关闭。
任何一个条件被满足,包含在<noscript>中的内容就会被渲染。
使用
<noscript>元素,可以指定在浏览器不支持脚本时显示的内容。如果浏览器支持并启用脚本,则<noscript>元素中的任何内容都不会被渲染。
# 集合引用类型
# Array
# 转换方法
对象都有 toLocaleString()、toString()和 valueOf()方法
# toString()
toString()返回由数组中每个值的等效字符串拼接而成的一个逗号分隔的 字符串。(对数组的每个值都会调用其 toString()方法,以得到最终的字符串)
let colors = ["red", "blue", "green"];
console.log(colors.toString()); // red,blue,green
2
# valueOf()
valueOf()返回的还是数组本身
let colors = ["red", "blue", "green"];
console.log(colors.valueOf()); // Array(3) 0: "red"1: "blue"2: "green"length: 3
2
# toLocaleString()
调用数组的 toLocaleString()方法时,会得到一个逗号分隔的数组值的字符串。它与另外两个方法唯一的区别是,为了得到最终的字符串,会调用数组每个值的 toLocaleString()方法,而不是toString()方法。
let person1 = {
toLocaleString() {
return "toLocaleString1";
},
toString() {
return "toString1";
}
};
let person2 = {
toLocaleString() {
return "toLocaleString2";
},
toString() {
return "toString2";
}
};
let people = [person1, person2];
console.log(people); //
console.log(people.toString()); // toString1,toString2
console.log(people.toLocaleString()); // toLocaleString1,toLocaleString2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# join()
join()方法接收一个参数,即字符串分隔符,返回包含所有项的字符串。
let colors = ["red", "green", "blue"];
alert(colors.join(",")); // red,green,blue
alert(colors.join("||")); // red||green||blue
2
3
如果不给 join()传入任何参数,或者传入 undefined,则仍然使用逗号作为
分隔符
let colors = ["red", "green", "blue"];
alert(colors.join()); // red,green,blue
alert(colors.join(undefined)); // red,green,blue
2
3
如果数组中某一项是 null 或 undefined,则在 join()、toLocaleString()、toString()和 valueOf()返回的结果中会以空字符串表示。
let colors = ["red", null, "blue"];
alert(colors.join()); // red,,blue
alert(colors.toString()); // red,,blue
2
3
# 栈方法
# push()
push()方法接收任意数量的参数,并将它们添加到数组末尾,返回数组的最新长度
let colors = new Array(); // 创建一个数组
let count = colors.push("red", "green"); // 推入两项
alert(count); // 2
count = colors.push("black"); // 再推入一项
alert(count); // 3
2
3
4
5
6
# pop()
pop()方法则用于删除数组的最后一项,同时减少数组的 length 值,返回被删除的项
let item = colors.pop(); // 取得最后一项
alert(item); // black
alert(colors.length); // 2
2
3
# 队列方法
# shift()
会删除数组的第一项并返回它,然后数组长度减 1
let colors = ["red", "blue"];
console.log(colors.shift()) // red
console.log(colors.length) // 1
2
3
# unshift()
unshift()就是执行跟 shift()相反的操作:在数组开头添加任意多个值,然后返回新的数组长度。
let colors = ["red", "blue"];
console.log(colors.unshift("1","2")) // 4
console.log(colors) // ['1', '2', 'red', 'blue']
console.log(colors.length) // 4
2
3
4
# 排序方法
# reverse()
reverse()方法就是将数组元素反向排列
let colors = ["red", "blue"];
console.log(colors.reverse()) // ['blue', 'red']
console.log(colors) // ['blue', 'red']
2
3
# sort()
默认情况下,sort()会按照升序重新排列数组元素
let colors = [5, 3, 4, 2, 7];
console.log(colors.sort()) // [2, 3, 4, 5, 7]
console.log(colors) // [2, 3, 4, 5, 7]
2
3
sort()会在每一项上调用 String()转型函数,然后比较字符串来决定顺序。即使数组的元素都是数值,也会先把数组转换为字符串再比较、排序。比如:
let values = [0, 1, 5, 10, 15];
values.sort();
console.log(values); // [0, 1, 10, 15, 5]
2
3
sort()方法可以接收一个比较函数
比较函数接收两个参数,如果第一个参数应该排在第二个参数前面,就返回负值;如果两个参数相等,就返回 0;如果第一个参数应该排在第二个参数后面,就返回正值。
function compare(value1, value2) {
if (value1 < value2) {
return -1;
} else if (value1 > value2) {
return 1;
} else {
return 0;
}
}
function cmp (a, b) {
return a - b // a > b则返回正值,需要交换a 和 b的位置
}
let values = [0, 1, 5, 10, 15];
values.sort(cmp);
console.log(values); //[0, 1, 5, 10, 15]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
箭头函数形式
let values = [0, 1, 5, 10, 15];
values.sort((a, b) => a > b ? -1 : 0)
console.log(values); // [15, 10, 5, 1, 0]
2
3
reverse()和 sort()都返回调用它们的数组的引用。
# 操作方法
# concat()
concat()方法可以在现有数组全部元素基础上创建一个新数组。它首先会创建一个当前数组的副本,然后再把它的参数添加到副本末尾,最后返回这个新构建的数组。如果传入一个或多个数组,则 concat()会把这些数组的每一项都添加到结果数组。如果参数不是数组,则直接把它们添加到结果数组末尾。
let colors = ["red", "green", "blue"];
let colors2 = colors.concat("yellow", ["black", "brown"]);
console.log(colors2) // ['red', 'green', 'blue', 'yellow', 'black', 'brown']
2
3
打平数组参数的行为可以重写,方法是在参数数组上指定一个特殊的符号:Symbol.isConcatSpreadable。这个符号能够阻止 concat()打平参数数组。相反,把这个值设置为 true 可以强制打平类数组对象
let colors = ["red", "green", "blue"];
let colors2 = ["black", "brown"]
// 强制不打平数组
colors2[Symbol.isConcatSpreadable] = false
let colors3 = colors.concat("yellow", colors2);
console.log(colors3) // ['red', 'green', 'blue', 'yellow', ["black", "brown"]]
let colors = ["red", "green", "blue"];
let colors2 = {
[Symbol.isConcatSpreadable]: true,
0: "pink",
1: "black",
length: 2
}
// Symbol.isConcatSpreadable为true,强制打平数组
let colors3 = colors.concat(colors2)
console.log(colors3) // ['red', 'green', 'blue', 'pink', 'black']
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# slice()
slice()用于创建一个包含原有数组中一个或多个元素的新数组。slice()方法可以接收一个或两个参数:返回元素的开始索引和结束索引。如果只有一个参数,则 slice()会返回该索引到数组末尾的所有元素。如果有两个参数,则 slice()返回从开始索引到结束索引对应的所有元素,其中不包含结束索引对应的元素。记住,这个操作不影响原始数组。
let colors = ["red", "green", "blue", "yellow", "purple"];
let colors2 = colors.slice(1);
console.log(colors2) // ['green', 'blue', 'yellow', 'purple']
// 包括开始索引,不包括结束索引
let colors3 = colors.slice(1, 4);
console.log(colors3) // ['green', 'blue', 'yellow']
console.log(colors.slice(-1)) // ['purple']
2
3
4
5
6
7
8
如果
slice()的参数有负值,那么就以数值长度加上这个负值的结果确定位置。比如,在包含 5 个元素的数组上调用 slice(-2,-1),就相当于调用 slice(3,4)。如果结束位置小于开始位置,则返回空数组。
# splice()
删除。需要给 splice()传 2 个参数:要删除的第一个元素的位置和要删除的元素数量。可以从数组中删除任意多个元素,比如 splice(0, 2)会删除前两个元素。
let colors = ["red", "green", "blue"]; let removed = colors.splice(0,1); // 删除第一项 console.log(colors); // ['green', 'blue'] console.log(removed); // ['red'],只有一个元素的数组1
2
3
4
插入。需要给 splice()传 3 个参数:开始位置、0(要删除的元素数量)和要插入的元素,可以在数组中指定的位置插入元素。第三个参数之后还可以传第四个、第五个参数,乃至任意多个要插入的元素。比如,splice(2, 0, "red", "green")会从数组位置 2 开始插入字符串"red"和"green"。
let colors = ["red", "green", "blue"]; let removed = colors.splice(1,0, 1,2,3,4); //索引1的位置开始,删除0个,插入1,2,3,4 console.log(colors); // ['red', 1, 2, 3, 4, 'green', 'blue'] // 如果没有删除元素,则返回空数组 console.log(removed); // [] 没有删除的元素返回空数组1
2
3
4
5let colors = ['red', 1, 2, 3, 4, 'green', 'blue'] let removed2 = colors.splice(1,4,5); //索引1的位置开始,删除4个,插入5 console.log(colors); // ['red', 5, 'green', 'blue'] console.log(removed2); // [1, 2, 3, 4]1
2
3
4
替换。splice()在删除元素的同时可以在指定位置插入新元素,同样要传入 3 个参数:开始位置、要删除元素的数量和要插入的任意多个元素。要插入的元素数量不一定跟删除的元素数量一致。比如,splice(2, 1, "red", "green")会在位置 2 删除一个元素,然后从该位置开始向数组中插入"red"和"green"。
只删除一个,就相当于替换的效果
let colors = ['red', 1, 'green', 'blue'] let removed2 = colors.splice(1,"pink"); //索引1的位置开始,删除1个,插入"pink" 相当于替换 console.log(colors); // ['red','pink' , 'green', 'blue'] console.log(removed2); // [1]1
2
3
4
只传一个参数(相当于删除到末尾)
let colors = ['red', 1, 'green', 'blue']
let removed2 = colors.splice(1); //索引1的位置开始,删除到末尾
console.log(colors); // ['red']
console.log(removed2); // [1, 'green', 'blue']
2
3
4
# 搜索和位置方法
ECMAScript 提供两类搜索数组的方法:按严格相等搜索和按断言函数搜索。
# 严格相等
indexOf()和 lastIndexOf()都返回要查找的元素在数组中的位置,如果没找到则返回-1。includes()返回布尔值,表示是否至少找到一个与指定元素匹配的项。
indexOf() lastIndexOf() includes()
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
// 一个参数,要查找的元素
console.log(numbers.indexOf(4)); // 3
console.log(numbers.lastIndexOf(4)); // 5
console.log(numbers.includes(4)); // true
// 两个参数,第一个参数:要查找的元素,第二个参数:查询开始的索引
console.log(numbers.indexOf(4, 4)); // 5
console.log(numbers.lastIndexOf(4, 4)); // 3
console.log(numbers.includes(4, 7)); // false
// 在比较第一个参数跟数组每一项时,会使用全等(===)比较,也就是说两项必须严格相等
let person = { name: "Nicholas" };
let people = [{ name: "Nicholas" }];
let morePeople = [person];
console.log(people.indexOf(person)); // -1
console.log(morePeople.indexOf(person)); // 0
console.log(people.includes(person)); // false
console.log(morePeople.includes(person)); // true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 断言函数
断言函数接收 3 个参数:元素、索引和数组本身。其中元素是数组中当前搜索的元素,索引是当前元素的索引,而数组就是正在搜索的数组。断言函数返回真值,表示是否匹配。
find()返回第一个匹配的元素
findIndex()返回第一个匹配元素的索引
const people = [
{
name: "Matt",
age: 27
},
{
name: "Nicholas",
age: 29
}
];
console.log(people.find((element, index, array) => element.age < 28)); // {name: "Matt", age: 27}
console.log(people.findIndex((element, index, array) => element.age < 28)); // 0
// 找不到返回undefined
console.log(people.find((element, index, array) => element.age > 30)); // undefined
console.log(people.findIndex((element, index, array) => element.age > 30)); // -1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
const evens = [2, 4, 6];
// 找到匹配后,永远不会检查数组的最后一个元素
evens.find((element, index, array) => {
console.log(element);
console.log(index);
console.log(array);
return element === 4;
});
// 2
// 0
// [2, 4, 6]
// 4
// 1
// [2, 4, 6]
2
3
4
5
6
7
8
9
10
11
12
13
14
这两个方法也都接收第二个可选的参数,用于指定断言函数内部 this 的值。
# 迭代方法
ECMAScript 为数组定义了 5 个迭代方法。每个方法接收两个参数:以每一项为参数运行的函数,以及可选的作为函数运行上下文的作用域对象(影响函数中 this 的值)。传给每个方法的函数接收 3个参数:数组元素、元素索引和数组本身。
every():对数组每一项都运行传入的函数,如果对每一项函数都返回 true,则这个方法返回 true。let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1]; let everyResult = numbers.every((item, index, array) => item > 2); console.log(everyResult); // false everyResult = numbers.every((item, index, array) => item >= 1); console.log(everyResult); // true1
2
3
4
5some():对数组每一项都运行传入的函数,如果有一项函数返回 true,则这个方法返回 true。let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1]; let someResult = numbers.some((item, index, array) => item > 2); console.log(someResult); // true1
2
3filter():对数组每一项都运行传入的函数,函数返回 true 的项会组成数组之后返回。let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1]; let filterResult = numbers.filter((item, index, array) => item > 2); console.log(filterResult); // [3, 4, 5, 4, 3]1
2
3forEach():对数组每一项都运行传入的函数,没有返回值。let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1]; numbers.forEach((item, index, array) => { console.log(item) // 元素 console.log(index) // 索引 console.log(array) // 数组本身 });1
2
3
4
5
6map():对数组每一项都运行传入的函数,返回由每次函数调用的结果构成的数组。let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1]; let mapResult = numbers.map((item, index, array) => item * 2); console.log(mapResult); // [2, 4, 6, 8, 10, 8, 6, 4, 2]1
2
3
# 归并方法
ECMAScript 为数组提供了两个归并方法:reduce()和reduceRight()。这两个方法都会迭代数组的所有项,并在此基础上构建一个最终返回值。reduce()方法从数组第一项开始遍历到最后一项。而 reduceRight()从最后一项开始遍历至第一项。
给 reduce()和 reduceRight()的函数接收 4 个参数: 上一个归并值、当前项、当前项的索引和数组本身。这个函数返回的任何值都会作为下一次调用同一个函数的第一个参数。如果没有给这两个方法传入可选的第二个参数(作为归并起点值),则第一次迭代将从数组的第二项开始,因此传给归并函数的第一个参数是数组的第一项,第二个参数是数组的第二项。
# reduce
let arr = [1, 2, 3, 4, 5]
let sum = arr.reduce((prev, cur, index, item) => {
console.log("prev, cur, index", prev, cur, index)
return prev + cur
})
console.log(sum)
2
3
4
5
6

# reduceRight
let arr = [1, 2, 3, 4, 5]
let sum = arr.reduceRight((prev, cur, index, item) => {
console.log("prev, cur, index", prev, cur, index)
return prev + cur
})
console.log(sum)
2
3
4
5
6

# 定性数组
# Map
ECMAScript 6 的新增特性,Map 是一种新的集合类型
# 基本 API
以给 Map 构造函数传入一个可迭代对象
// 使用嵌套数组初始化映射
const m = new Map([
['key1', 'value1'],
['key2', 'value2'],
['key3', 'value3']
]);
console.log(m.size)
2
3
4
5
6
7
// 使用自定义迭代器初始化映射
const m2 = new Map({
[Symbol.iterator]: function*() {
yield ['key1', 'value1'];
yield ['key2', 'value2'];
yield ['key3', 'value3'];
}
});
console.log(m2)
2
3
4
5
6
7
8
9
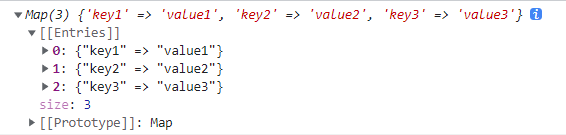
// 映射期待的键/值对,无论是否提供
const m3 = new Map([[]])
console.log(m3.get(undefined)) // undefined
console.log(m3.has(undefined)) // true
2
3
4
Map使用 get()和 has()进行查询,可以通过 size 属性获取映射中的键/值对的数量,还可以使用delete()和 clear()删除值。
# set() 、has() 、delete()、clear()
const map = new Map()
map.set('key1', 'value1')
map.set('key2', 'value2')
console.log(map.get('key1')) // value1
console.log(map.get('key2')) // value2
console.log(map.size) // 2
map.has('key1')
map.has('abc')
map.set('key1', '会覆盖原来的value1')
console.log(map.get('key1')) // 会覆盖原来的value1
map.delete('key1')
console.log(map.size) // 1
map.clear()
console.log(map.size) // 0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
set()方法返回映射实例,因此可以把多个操作连缀起来,包括初始化声明
const map4 = new Map()
.set('key1', 'value1')
.set('key2', 'value2')
console.log(map4.size) // 2
2
3
4
Map 可以使用任何 JavaScript 数据类型作为键。 与 Object 类似,映射的值是没有限制的。
// map 可以使用任意的类型作为键值
const map5 = new Map()
const fun1 = function(){}
const obj1 = {}
const map111 = new Map()
map5.set(fun1, 'fun1')
map5.set(obj1, 'obj1')
map5.set(map111, 'map111')
console.log(map5.size) // 3
console.log(map5.get(fun1)) // fun1
// SameValueZero 比较意味着独立实例不冲突
console.log(map5.get(function() {})) // undefined
2
3
4
5
6
7
8
9
10
11
12
与严格相等一样,在映射中用作键和值的对象及其他“集合”类型,在自己的内容或属性被修改时仍然保持不变:
const map6 = new Map()
const objKey = {},
objVal = {},
arrKey = [],
arrVal = []
map6.set(objKey, objVal)
map6.set(arrKey, arrVal)
console.log(map6.get(objKey)) // {}
console.log(map6.get(arrKey)) // []
objKey.key = 'key'
objVal.val = 'val'
objVal.val2 = 'val2'
arrKey.push(1,2,3)
arrVal.push(1,2,3,4)
console.log(map6.get(objKey)) // {val: 'val', val2: 'val2'}
console.log(map6.get(arrKey)) // [1, 2, 3, 4]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
map存在的问题
const a = 0 / "" // NaN,
b = 0/ "", // NaN
c = +0,
d= -0
console.log(a === b) // false
console.log(c === d) // true
const map7 = new Map().set(a, 'NaN').set(c,'正负0')
console.log(map7.get(b)) // 竟然也能拿到 NaN
console.log(map7.get(d)) // 也拿到了c存储的值正负0
2
3
4
5
6
7
8
9
10
# 顺序和迭代
与 Object 类型的一个主要差异是,Map 实例会维护键值对的插入顺序,因此可以根据插入顺序执行迭代操作。
映射实例可以提供一个迭代器(Iterator),能以插入顺序生成[key, value]形式的数组.可以通过 entries()方法(或者 Symbol.iterator 属性,它引用 entries())取得这个迭代器
const map8 = new Map([
['key1', 'value1'],
['key2', 'value2'],
['key3', 'value3']
]);
console.log(map8.entries === map8[Symbol.iterator]) // true
for(let entrty of map8.entries()) {
console.log(entrty) // entrty[0] 是key entrty[1]是value
}
// ['key1', 'value1']
// ['key2', 'value2']
// ['key3', 'value3']
for(let iter of map8[Symbol.iterator]()) {
console.log(iter)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
entries()是默认迭代器,可以直接对映射实例使用扩展操作,把映射转换为数组
const map8 = new Map([
['key1', 'value1'],
['key2', 'value2'],
['key3', 'value3']
]);
console.log([...map8])
// ['key1', 'value1']
// ['key2', 'value2']
// ['key3', 'value3']
const map9 = new Map().set('key1', 'val1').set('key2','val2')
console.log([...map9])
// ['key1', 'val1']
// ['key2', 'val2']
2
3
4
5
6
7
8
9
10
11
12
13
14
如果不使用迭代器,而是使用回调方式,则可以调用映射的 forEach(callback, opt_thisArg)方法并传入回调,依次迭代每个键/值对。传入的回调接收可选的第二个参数,这个参数用于重写回调内部 this 的值
const map8 = new Map([
['key1', 'value1'],
['key2', 'value2'],
['key3', 'value3']
]);
const obj = {a: 1}
map8.forEach((value, key) => {
console.log(this) // Windows
console.log(`${key} -> ${value}`)
},obj)
map8.forEach(function(value, key){
console.log(this) // {a: 1}
console.log(`${key} -> ${value}`)
},obj)
2
3
4
5
6
7
8
9
10
11
12
13
14
# keys()和 values()
const map8 = new Map([
['key1', 'value1'],
['key2', 'value2'],
['key3', 'value3']
]);
console.log(map8.keys()) // MapIterator {'key1', 'key2', 'key3'}
console.log(map8.values()) // MapIterator {'value1', 'value2', 'value3'}
for(let key of map8.keys()) {
console.log(key)
}
for(let val of map8.values()) {
console.log(key)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
键和值在迭代器遍历时是可以修改的,但映射内部的引用则无法修改。
// 作为键的字符串原始值是不能修改的
for(let key of map8.keys()) {
key = 'newKey'
console.log(key)
console.log(map8.get('newKey')) // undefined
}
// 修改了作为键的对象的属性,但对象在映射内部仍然引用相同的值
const obj2 = {a: 1}
const map10 = new Map().set(obj2, obj2)
for(let key of map10.keys()) {
key.a = 2
console.log(key, map10.get(key)) // {a: 2} {a: 2}
}
console.log([...map10]) // [{a: 2}, {a: 2}]
2
3
4
5
6
7
8
9
10
11
12
13
14
# 选择Map还是Object
内存占用
Object 和 Map 的工程级实现在不同浏览器间存在明显差异,但存储单个键/值对所占用的内存数量
都会随键的数量线性增加。批量添加或删除键/值对则取决于各浏览器对该类型内存分配的工程实现。
不同浏览器的情况不同,但给定固定大小的内存,Map 大约可以比 Object 多存储 50%的键/值对。
插入性能
向 Object 和 Map 中插入新键/值对的消耗大致相当,不过插入 Map 在所有浏览器中一般会稍微快
一点儿。对这两个类型来说,插入速度并不会随着键/值对数量而线性增加。如果代码涉及大量插入操
作,那么显然 Map 的性能更佳。
查找速度
与插入不同,从大型 Object 和 Map 中查找键/值对的性能差异极小,但如果只包含少量键/值对,
则 Object 有时候速度更快。在把 Object 当成数组使用的情况下(比如使用连续整数作为属性),浏
览器引擎可以进行优化,在内存中使用更高效的布局。这对 Map 来说是不可能的。对这两个类型而言,
查找速度不会随着键/值对数量增加而线性增加。如果代码涉及大量查找操作,那么某些情况下可能选
择 Object 更好一些。
删除性能
使用 delete 删除 Object 属性的性能一直以来饱受诟病,目前在很多浏览器中仍然如此。为此,
出现了一些伪删除对象属性的操作,包括把属性值设置为 undefined 或 null。但很多时候,这都是一
种讨厌的或不适宜的折中。而对大多数浏览器引擎来说,Map 的 delete()操作都比插入和查找更快。
如果代码涉及大量删除操作,那么毫无疑问应该选择 Map。
# WeakMap
ECMAScript 6 新增的“弱映射”(WeakMap)是一种新的集合类型,为这门语言带来了增强的键/
值对存储机制。WeakMap 是 Map 的“兄弟”类型,其 API 也是 Map 的子集。WeakMap 中的“weak”(弱),
描述的是 JavaScript 垃圾回收程序对待“弱映射”中键的方式。
const wm = new WeakMap();
弱映射中的键只能是 Object 或者继承自 Object 的类型,尝试使用非对象设置键会抛出TypeError。值的类型没有限制。
其他方法与Map类似
# 弱键
WeakMap 中“weak”表示弱映射的键是“弱弱地拿着”的。意思就是,这些键不属于正式的引用,不会阻止垃圾回收。但要注意的是,弱映射中值的引用可不是“弱弱地拿着”的。只要键存在,键/值对就会存在于映射中,并被当作对值的引用,因此就不会被当作垃圾回收。
const vm = new WeakMap().set({},"abc")
set()方法初始化了一个新对象并将它用作一个字符串的键。因为没有指向这个对象的其他引用,所以当这行代码执行完成后,这个对象键就会被当作垃圾回收。然后,这个键/值对就从弱映射中消失了,使其成为一个空映射。在这个例子中,因为值也没有被引用,所以这对键/值被破坏以后,值本也会成为垃圾回收的目标。
const vm = new WeakMap().set({},"abc")
const obj = {
key: {}
}
const vm2 = new WeakMap().set(obj.key, "abc")
function removeKey() {
obj.key = null
}
2
3
4
5
6
7
8
9
10
obj 对象维护着一个对弱映射键的引用,因此这个对象键不会成为垃圾回收的目标。不过,如果调用了 removeKey(),就会摧毁键对象的最后一个引用,垃圾回收程序就可以把这个键/值对清理掉。
# 不可迭代键
因为 WeakMap 中的键/值对任何时候都可能被销毁,所以没必要提供迭代其键/值对的能力。当然,也用不着像 clear()这样一次性销毁所有键/值的方法。WeakMap 确实没有这个方法。因为不可能迭代,所以也不可能在不知道对象引用的情况下从弱映射中取得值。即便代码可以访问 WeakMap 实例,也没办法看到其中的内容。
WeakMap 实例之所以限制只能用对象作为键,是为了保证只有通过键对象的引用才能取得值。如果允许原始值,那就没办法区分初始化时使用的字符串字面量和初始化之后使用的一个相等的字符串了。
# Set
# 基本 API
// 使用 new 关键字和 Set 构造函数可以创建一个空集合
const m = new Set()
// 使用数组初始化集合
const m1 = new Set(['val1', 'val2', 'val3', 'val1'])
console.log(m1.size) // 3
// 使用自定义迭代器初始化集合
const m2 = new Set({
[Symbol.iterator]: function*() {
yield "val1";
yield "val2";
yield "val3";
yield "val1";
}
})
console.log(m2.size) // 3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# add,has,delete,clear
console.log(m1.has('val1')) // true
m1.add('val4').add('val5')
console.log(m1.has('val4')) // true
console.log(m1.delete('val4')) // true
console.log(m1.has('val4')) // false
m1.clear()
console.log(m1.size) // 0
2
3
4
5
6
7
与 Map 类似,Set 可以包含任何 JavaScript 数据类型作为值。集合也使用 SameValueZero 操作(ECMAScript 内部定义,无法在语言中使用),基本上相当于使用严格对象相等的标准来检查值的匹配性。
与严格相等一样,用作值的对象和其他“集合”类型在自己的内容或属性被修改时也不会改变
add()和 delete()操作是幂等的。delete()返回一个布尔值,表示集合中是否存在要删除的值
# 顺序与迭代
Set 会维护值插入时的顺序,因此支持按顺序迭代。
const s = new Set(['val1', 'val2'])
console.log(s.values == s[Symbol.iterator]) // true
console.log(s.keys == s[Symbol.iterator]) // true
for(let val of s.values()) {
console.log(val)
}
for(let val of s.keys()) {
console.log(val)
}
for(let val of s[Symbol.iterator]()) {
console.log(val)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
因为 values()是默认迭代器,所以可以直接对集合实例使用扩展操作,把集合转换为数组
console.log([...s]) // ['val1', 'val2']
集合的 entries()方法返回一个迭代器,可以按照插入顺序产生包含两个元素的数组,这两个元素是集合中每个值的重复出现
const s = new Set(['val1', 'val2'])
for(let temp of s.entries()) {
console.log(temp)
}
// ['val1', 'val1']
// ['val2', 'val2']
2
3
4
5
6
如果不使用迭代器,而是使用回调方式,则可以调用集合的 forEach()方法并传入回调,依次迭代每个键/值对。传入的回调接收可选的第二个参数,这个参数用于重写回调内部 this 的值
const obj = {a: 1}
s.forEach((item) => {
console.log(this) // windows
console.log(item)
}, obj)
s.forEach(function(item) {
console.log(this) // {a: 1}
console.log(item)
}, obj)
2
3
4
5
6
7
8
9
# 总结
Array、所有定型数组、Map、Set有 4 种原生集合类型定义了默认迭代器,这意味着上述所有类型都支持顺序迭代,都可以传入 for-of 循环。这些类型都兼容扩展操作符。扩展操作符在对可迭代对象执行浅复制
# 迭代器和生成器
# 迭代器
开发者无须事先知道如何迭代就能实现迭代操作。这个解决方案就是迭代器模式
在 ECMAScript 中,这意味着必须暴露一个属性作为“默认迭代器”,而且这个属性必须使用特殊的 Symbol.iterator 作为键。这个默认迭代器属性必须引用一个迭代器工厂函数,调用这个工厂函数必须返回一个新迭代器。
字符串、数组 、映射、 集合、 arguments 对象 、NodeList 等 DOM 集合类型内置类型都实现了 Iterable 接口
检查是否存在默认迭代器属性可以暴露这个工厂函数
let num = 1
let obj = {}
// 这两种类型没有实现迭代器工厂属性
console.log(num[Symbol.iterator]) // undefined
console.log(obj[Symbol.iterator]) // undefined
let str = 'abc';
let arr = ['a', 'b', 'c'];
let map = new Map().set('a', 1).set('b', 2).set('c', 3);
let set = new Set().add('a').add('b').add('c');
let els = document.querySelectorAll('div');
console.log(str[Symbol.iterator]) // ƒ [Symbol.iterator]() { [native code] }
console.log(arr[Symbol.iterator]) // ƒ values() { [native code] }
console.log(map[Symbol.iterator]) // ƒ entries() { [native code] }
console.log(set[Symbol.iterator]) // ƒ values() { [native code] }
console.log(els[Symbol.iterator]) // ƒ values() { [native code] }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
调用这个工厂函数会生成一个迭代器
console.log(str[Symbol.iterator]()) // StringIterator {}
console.log(arr[Symbol.iterator]()) // Array Iterator {}
console.log(map[Symbol.iterator]()) // MapIterator {'a' => 1, 'b' => 2, 'c' => 3}
console.log(set[Symbol.iterator]()) // SetIterator {'a', 'b', 'c'}
console.log(els[Symbol.iterator]()) // Array Iterator {}
2
3
4
5
实际写代码过程中,不需要显式调用这个工厂函数来生成迭代器。实现可迭代协议的所有类型都会自动兼容接收可迭代对象的任何语言特性。
for-of 循环
数组解构
扩展操作符
Array.from()
创建集合
创建映射
Promise.all()接收由期约组成的可迭代对象
Promise.race()接收由期约组成的可迭代对象
yield*操作符,在生成器中使用
如果对象原型链上的父类实现了 Iterable 接口,那这个对象也就实现了这个接口
class ziArray extends Array{}
let arr2 = new ziArray('a', 'b', 'c')
for(let item of arr2) {
console.log(item)
}
2
3
4
5
# 迭代器协议
迭代器 API 使用 next()方法在可迭代对象中遍历数据。每次成功调用 next(),都会返回一个 IteratorResult对象,其中包含迭代器返回的下一个值。若不调用 next(),则无法知道迭代器的当前位置。
next()方法返回的迭代器对象 IteratorResult 包含两个属性:done 和 value。done 是一个布尔值,表示是否还可以再次调用 next()取得下一个值;value 包含可迭代对象的下一个值(done 为false),或者 undefined(done 为 true)。done: true 状态称为“耗尽”。
let arr = [1,2,3]
let iterator = arr[Symbol.iterator]()
let next = iterator.next()
while(!next.done) {
console.log(next.value)
next = iterator.next()
}
2
3
4
5
6
7
迭代器维护着一个指向可迭代对象的引用,因此迭代器会阻止垃圾回收程序回收可迭代对象。
# 自定义迭代器
class Counter {
constructor(limit) {
this.limit = limit
}
[Symbol.iterator]() {
let count = 1, limit = this.limit
return {
next() {
if (count <= limit) {
return {done: false, value: count++}
} else {
return {done: true, value: undefined}
}
}
}
}
}
let count = new Counter(3)
for(let i of count) {
console.log(i)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
let arr2 = ['a', 'b', 'c']
let iter1 = arr[Symbol.iterator]()
console.log(iter1[Symbol.iterator]() === iter1) // true
2
3
# 提前终止迭代器
可选的 return()方法用于指定在迭代器提前关闭时执行的逻辑。
for-of 循环通过 break、continue、return 或 throw 提前退出;
解构操作并未消费所有值。
return()方法必须返回一个有效的 IteratorResult 对象。简单情况下,可以只返回{ done: true }。
// 自定义迭代器
class Counter {
constructor(limit) {
this.limit = limit
}
[Symbol.iterator]() {
let count = 1, limit = this.limit
return {
next() {
if (count <= limit) {
return {done: false, value: count++}
} else {
return {done: true, value: undefined}
}
},
` return() {
console.log('提前退出')
return {done: true}
}`
}
}
}
let count = new Counter(3)
index = 0
try {
for(let i of count) {
index++
if (index > 2) {
// break
throw 'err'
}
console.log(i)
}
}catch(e) {}
// 1
// 2
// 提前退出
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
如果迭代器没有关闭,则还可以继续从上次离开的地方继续迭代。比如,数组的迭代器就是不能关闭的:
let arr2 = ['a', 'b', 'c']
let index1 = 0
let iter2 = arr2[Symbol.iterator]()
for(let val of iter2) {
index1++
console.log(val)
if (index1 >= 2) {
console.log('我提前结束了,但我下次还是会继续上次的内容')
break
}
}
for(let val of iter2) {
console.log(val)
}
// a
// b
// 我提前结束了,但我下次还是会继续上次的内容
// c
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
因为 return()方法是可选的,所以并非所有迭代器都是可关闭的。要知道某个迭代器是否可关闭,可以测试这个迭代器实例的 return 属性是不是函数对象。。不过,仅仅给一个不可关闭的迭代器增加这个方法并不能让它变成可关闭的。这是因为调用 return()不会强制迭代器进入关闭状态。即便如此,return()方法还是会被调用。
let arr2 = ['a', 'b', 'c']
// let iter1 = arr[Symbol.iterator]()
// console.log(iter1[Symbol.iterator]() === iter1) // true
let index1 = 0
let iter2 = arr2[Symbol.iterator]()
` iter2.return = function() {
console.log('自己写return方法')
return {done: true}
}`
for(let val of iter2) {
index1++
console.log(val)
if (index1 >= 2) {
break
}
}
for(let val of iter2) {
console.log(val)
}
// a
// b
// 自己写return方法
// c
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 生成器
生成器是 ECMAScript 6 新增的一个极为灵活的结构,拥有在一个函数块内暂停和恢复代码执行的能力。
生成器的形式是一个函数,函数名称前面加一个星号(*)表示它是一个生成器。只要是可以定义函数的地方,就可以定义生成器。
// 生成器函数声明
function* generateFn()
// 生成器函数表达式
let gene = function* () {}
// 作为对象字面量的生成器函数
let obj = {
* generateFn() {}
}
// 作为类实例方法的生成器函数
class Foo {
* generateFn() {}
}
// 作为类静态方法的生成器函数
class Bar {
static* generateFn() {}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
箭头函数不能用来定义生成器函数。
标识生成器函数的星号不受两侧空格的影响
调用生成器函数会产生一个生成器对象。生成器对象一开始处于暂停执行(suspended)的状态。与迭代器相似,生成器对象也实现了Iterator 接口,因此具有 next()方法。调用这个方法会让生成器开始或恢复执行。
function* generateFn() {}
const generate = generateFn()
console.log(generate) // generateFn
console.log(generate.next()) // {done: true, value: undefined}
// value 属性是生成器函数的返回值,默认值为 undefined,可以通过生成器函数的返回值指定:
function * gengrateFun() {
return 'aaa'
}
console.log(gengrateFun().next()) // {value: 'aaa', done: true}
2
3
4
5
6
7
8
9
10
生成器函数只会在初次调用 next()方法后开始执行
function * gengrateFun() {
console.log('我只有在调用next方法才会执行')
}
let gene1 = gengrateFun() // 什么也不会输出
console.log(gene1.next()) // 我只有在调用next方法才会执行 {value: undefined, done: true}
2
3
4
5
生成器对象实现了 Iterable 接口,它们默认的迭代器是自引用的
console.log(gene1 == gene1[Symbol.iterator]()) // true